HashedWheelTimer introduced in this article is a tool class from Netty, which is in the Netty common package. It is used to implement delayed tasks. In addition, the content described below has nothing to do with Netty.
If you have seen Dubbo's source code, you will see it in many places. It is a very convenient and easy-to-use tool in the scenario of failure retry.
This article will introduce the use of HashedWheelTimer and analyze its source code implementation in the second half.
Interface Overview
Before introducing its use, first understand its interface definition and its related classes.
HashedWheelTimer is the interface io netty. util. For the implementation of Timer, from the perspective of interface oriented programming, we don't need to care about HashedWheelTimer, just about the interface class Timer. This Timer interface has only two methods:
public interface Timer {
// Create a scheduled task
Timeout newTimeout(TimerTask task, long delay, TimeUnit unit);
// Stop all scheduled tasks that have not yet been executed
Set<Timeout> stop();
}
Timer is the task scheduler we want to use. We can see from the method that it submits a task TimerTask and returns a Timeout instance. Therefore, the relationship between these three classes is probably as follows:
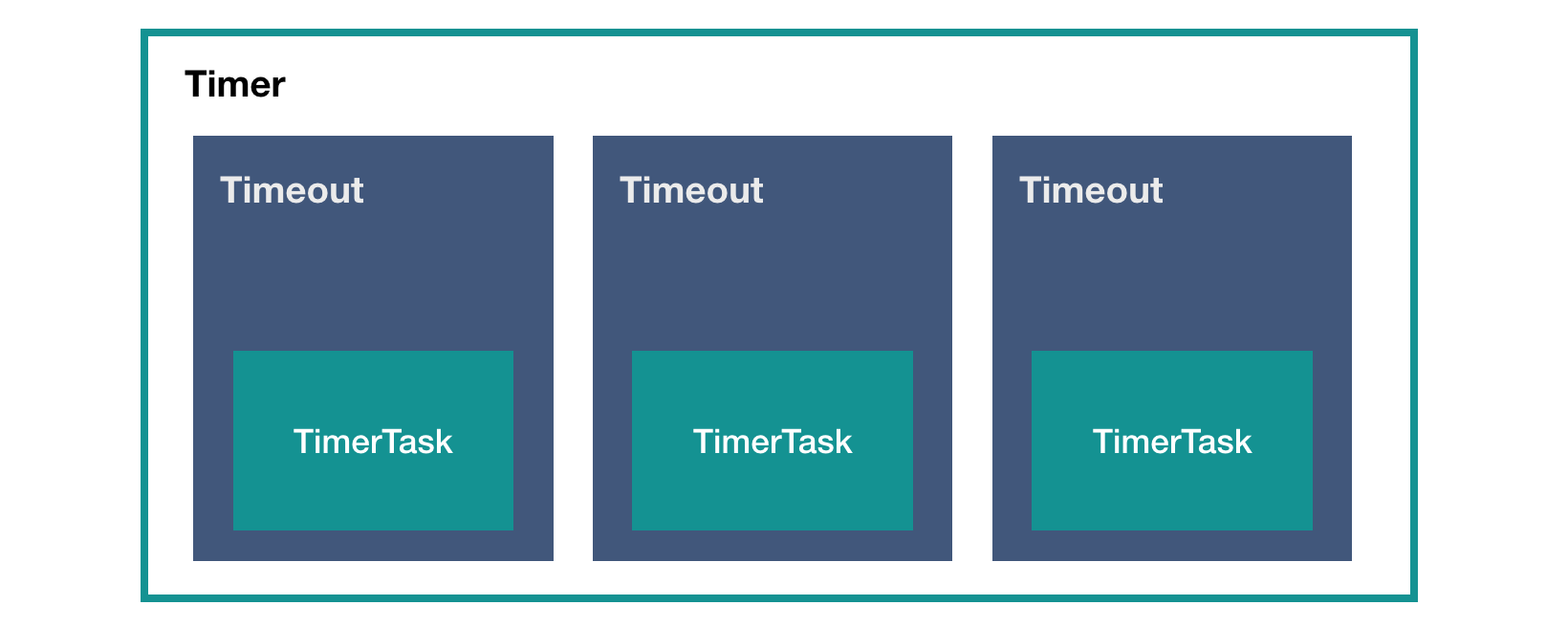
TimerTask is very simple, just a run() method:
public interface TimerTask {
void run(Timeout timeout) throws Exception;
}
Of course, what's interesting here is that it also transmits the instance of Timeout. Our usual code habits are one-way dependencies.
This also has the advantage that you can do other things through the timeout instance during task execution.
Timeout is also an interface class:
public interface Timeout {
Timer timer();
TimerTask task();
boolean isExpired();
boolean isCancelled();
boolean cancel();
}
It holds the upper Timer instance and the lower TimerTask instance, and then cancels the task.
HashedWheelTimer use
With the interface information introduced in the first section, we can use it easily. Let's write a few lines at will:
// Construct a Timer instance
Timer timer = new HashedWheelTimer();
// Submit a task and let it execute after 5s
Timeout timeout1 = timer.newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) {
System.out.println("5s Execute the task after");
}
}, 5, TimeUnit.SECONDS);
// Submit another task and let it execute in 10s
Timeout timeout2 = timer.newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) {
System.out.println("10s Execute the task after");
}
}, 10, TimeUnit.SECONDS);
// Cancel the task to be executed after 5s
if (!timeout1.isExpired()) {
timeout1.cancel();
}
// The original task executed after 5s has been cancelled. Here we go back on our word. We want this task to be executed in 3s
// We said that timeout holds upper and lower level instances, so the following timer can also be written as timeout1 timer()
timer.newTimeout(timeout1.task(), 3, TimeUnit.SECONDS);
Through these lines of code, you can be very familiar with the use of these classes, because they are really simple.
Let's take a look at an example from Dubbo.
The following code is modified from Dubbo's cluster call policy FailbackClusterInvoker:
After calling the provider fails, it returns a null result to the consumer, and then the background thread executes a scheduled task to retry. It is mostly used for message notification.
public class Application {
public static void main(String[] args) {
Application app = new Application();
app.invoke();
}
private static final Logger log = LoggerFactory.getLogger(Application.class);
private volatile Timer failTimer = null;
public void invoke() {
try {
doInvoke();
} catch (Throwable e) {
log.error("call doInvoke Method failed, 5 s After that, it will enter the automatic retry in the background, with exception information: ", e);
addFailed(() -> doInvoke());
}
}
// Actual business realization
private void doInvoke() {
// Here, let this method deliberately fail
throw new RuntimeException("Deliberately throw an exception");
}
private void addFailed(Runnable task) {
// Delay initialization
if (failTimer == null) {
synchronized (this) {
if (failTimer == null) {
failTimer = new HashedWheelTimer();
}
}
}
RetryTimerTask retryTimerTask = new RetryTimerTask(task, 3, 5);
try {
// Execute the first retry after 5s
failTimer.newTimeout(retryTimerTask, 5, TimeUnit.SECONDS);
} catch (Throwable e) {
log.error("Failed to submit scheduled task, exception: ", e);
}
}
}
The following is the RetryTimerTask class used in it. Of course, you can also choose to write it as an internal class:
public class RetryTimerTask implements TimerTask {
private static final Logger log = LoggerFactory.getLogger(RetryTimerTask.class);
// Every few seconds
private final long tick;
// max retries
private final int retries;
private int retryTimes = 0;
private Runnable task;
public RetryTimerTask(Runnable task, long tick, int retries) {
this.tick = tick;
this.retries = retries;
this.task = task;
}
@Override
public void run(Timeout timeout) {
try {
task.run();
} catch (Throwable e) {
if ((++retryTimes) >= retries) {
// The number of retries exceeded the set value
log.error("The number of failed retries exceeds the threshold: {},Don't try again", retries);
} else {
log.error("Retry failed, continue to retry");
rePut(timeout);
}
}
}
// Get the timer instance through timeout and resubmit a scheduled task
private void rePut(Timeout timeout) {
if (timeout == null) {
return;
}
Timer timer = timeout.timer();
if (timeout.isCancelled()) {
return;
}
timer.newTimeout(timeout.task(), tick, TimeUnit.SECONDS);
}
}
The above code is also very simple. After calling doInvoke() method fails, submit a scheduled task and retry after 5s. If it still fails, retry every 3s, up to 5 times. If all 5 retries fail, record the error log and don't retry again.
The log printed is as follows:
15:47:36.232 [main] ERROR c.j.n.timer.Application - call doInvoke Method failed, 5 s After that, it will enter the automatic retry in the background, with exception information:
java.lang.RuntimeException: Deliberately throw an exception
at com.javadoop.nettylearning.timer.Application.doInvoke(Application.java:36)
at com.javadoop.nettylearning.timer.Application.invoke(Application.java:28)
at com.javadoop.nettylearning.timer.Application.main(Application.java:19)
15:47:41.793 [pool-1-thread-1] ERROR c.j.n.timer.RetryTimerTask - Retry failed, continue to retry
15:47:44.887 [pool-1-thread-1] ERROR c.j.n.timer.RetryTimerTask - Retry failed, continue to retry
15:47:47.986 [pool-1-thread-1] ERROR c.j.n.timer.RetryTimerTask - Retry failed, continue to retry
15:47:51.084 [pool-1-thread-1] ERROR c.j.n.timer.RetryTimerTask - Retry failed, continue to retry
15:47:54.186 [pool-1-thread-1] ERROR c.j.n.timer.RetryTimerTask - The number of failed retries exceeds the threshold: 5,Don't try again
HashedWheelTimer is really easy to use. If you're here to learn how to use it, you can see it here.
Analysis of HashedWheelTimer source code
Everyone must know or have heard that it uses a time wheel( Download algorithm introduction PPT )Let's look at the following diagram:
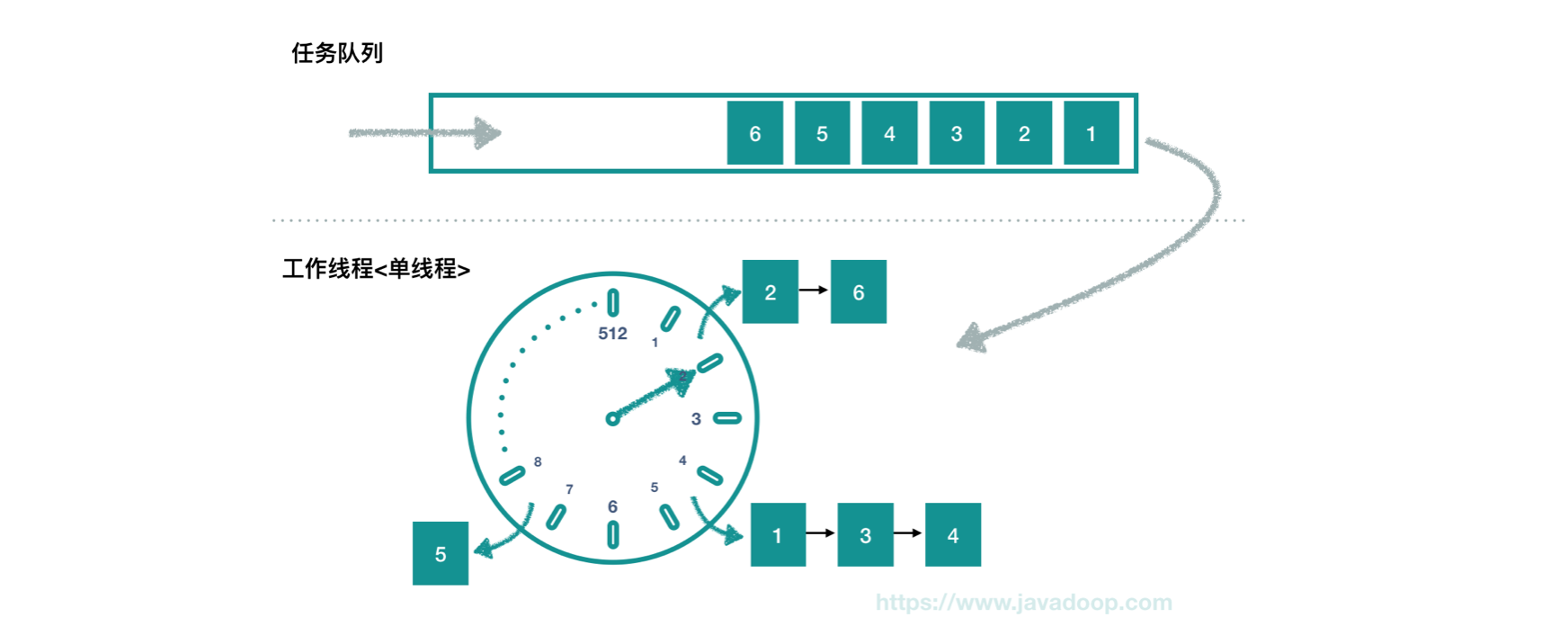
Let me first talk about the general implementation process, and then conduct a detailed source code analysis.
By default, the clock tick s every 100ms, moving forward one grid, a total of 512 grids. After one lap, continue to the next lap. Just think of it as a clock in life.
Internally, an array with a length of 512 is used for storage. The data structure of the array element (bucket) is a linked list. Each element of the linked list represents a task, which is the example of Timeout we introduced earlier.
The thread submitting the task can return as long as it stores the task in the task queue above the dotted line. The worker thread is a single thread. Once it is turned on, it keeps circling around the clock.
Take a closer look at the following introduction:
-
When the worker thread reaches each hour, it starts working. In HashedWheelTimer, time is relative time. The start time of the worker thread is defined as the 0 value of time. Because a tick is 100ms (the default), 100ms, 200ms, 300ms That's what I said.
-
As shown in the figure above, when the time reaches 200ms, it is found that there are tasks in the task queue, and all tasks are taken out.
-
Allocate the task to the corresponding bucket according to the execution time specified by the task. As shown in the figure above, the time specified by tasks 2 and 6 is 100ms~200ms, which is assigned to the second bucket to form a linked list. The same is true for other tasks.
There is also the concept of round here, but don't worry. For example, the time specified by task 6 may be 150ms + (512*100ms). It will also fall in this bucket, but it can only be executed in the next round.
-
After the task is assigned to the bucket, execute the real task of the tick, that is, task 2 and task 6 in the second bucket.
-
Assuming that it takes 50ms to execute these two tasks and reaches the time point of 250ms, the working thread will sleep for 50ms and wait for 300ms.
What if the execution time of these two tasks exceeds 100ms? This question depends on the source code to answer.
Start source code analysis. We start with its default constructor and go step by step to the last and most complex constructor:
public HashedWheelTimer(
ThreadFactory threadFactory,
long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection,
long maxPendingTimeouts) {
......
}
Briefly describe the parameters:
- threadFactory: scheduled tasks are background tasks and need to start threads. We usually name threads by customizing threadFactory. If it's too troublesome, we use {executors defaultThreadFactory().
- tickDuration and timeUnit define the time length of one grid. The default is 100ms.
- ticksPerWheel defines how many grids there are in a circle. The default is 512;
- leakDetection: it is used to track memory leakage. It will not be introduced in this article. Interested readers should understand it by themselves.
- maxPendingTimeouts: the maximum number of Timeout instances allowed to wait, that is, we can set not to allow too many tasks to wait. If the number of unexecuted tasks reaches the threshold, a RejectedExecutionException exception will be thrown when the task is submitted again. No limit by default.
Initialize HashedWheelTimer
public HashedWheelTimer(
ThreadFactory threadFactory,
long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection,
long maxPendingTimeouts) {
// ...... Parameter check
// Initialize the time wheel. Here, we make an upward "rounding" to keep the length of the array to the nth power of 2
wheel = createWheel(ticksPerWheel);
// Mask, used to take module
mask = wheel.length - 1;
// 100ms to nanosecond 100 * 10 ^ 6
this.tickDuration = unit.toNanos(tickDuration);
// Prevent overflow
if (this.tickDuration >= Long.MAX_VALUE / wheel.length) {
throw new IllegalArgumentException(String.format(
"tickDuration: %d (expected: 0 < tickDuration in nanos < %d",
tickDuration, Long.MAX_VALUE / wheel.length));
}
// Create a worker thread. There is no starting thread here. As you will see later, the thread will be started when the task is submitted for the first time
workerThread = threadFactory.newThread(worker);
leak = leakDetection || !workerThread.isDaemon() ? leakDetector.track(this) : null;
// Assign the maximum number of tasks allowed to wait
this.maxPendingTimeouts = maxPendingTimeouts;
// If there are more than 64 HashedWheelTimer instances, it will print an error log to remind you
// Netty is really in place. I'm afraid you'll use the wrong tool and instantiate it everywhere. And it only reports an error once.
if (INSTANCE_COUNTER.incrementAndGet() > INSTANCE_COUNT_LIMIT &&
WARNED_TOO_MANY_INSTANCES.compareAndSet(false, true)) {
reportTooManyInstances();
}
}
Above, HashedWheelTimer has completed the initialization and initialized the time wheel array HashedWheelBucket []. Take a look at the internal class HashedWheelBucket and you can see that it is a linked list structure. This is easy to understand, because each grid may have multiple tasks.
Submit the first task
@Override
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
if (task == null) {
throw new NullPointerException("task");
}
if (unit == null) {
throw new NullPointerException("unit");
}
// Verify whether the number of waiting tasks reaches the threshold maxPendingTimeouts
long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();
if (maxPendingTimeouts > 0 && pendingTimeoutsCount > maxPendingTimeouts) {
pendingTimeouts.decrementAndGet();
throw new RejectedExecutionException("Number of pending timeouts ("
+ pendingTimeoutsCount + ") is greater than or equal to maximum allowed pending "
+ "timeouts (" + maxPendingTimeouts + ")");
}
// If the worker thread is not started, it is responsible for starting it
start();
/** The following code builds a Timeout instance and puts it in the task queue**/
// deadline is a relative time, relative to the start time of HashedWheelTimer
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
// Guard against overflow.
if (delay > 0 && deadline < 0) {
deadline = Long.MAX_VALUE;
}
// For the timeout instance, one upper layer depends on timer, one lower layer depends on task, and the other is the task expiration time
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
// Put it in the timeouts queue
timeouts.add(timeout);
return timeout;
}
The operation of submitting a task is very simple. Instantiate the Timeout and put it into the task queue.
We can see that the priority queue used here is an MPSC (Multiple Producer Single Consumer) queue, which is just suitable for the scenario of multiple production threads and single consumption threads here. In Dubbo, the queue used is LinkedBlockingQueue, which is a thread safe queue organized in a linked list.
In addition, pay attention to the start() method called here. If the task is the first submitted task, it will be responsible for the start of the worker thread.
The worker thread starts working
In fact, as long as you understand the following lines of code, the source code of HashedWheelTimer is very simple.
private final class Worker implements Runnable {
private final Set<Timeout> unprocessedTimeouts = new HashSet<Timeout>();
// The number of ticks. As mentioned earlier, the clock ticks every 100ms
private long tick;
@Override
public void run() {
// In HashedWheelTimer, the relative time is used, so the starting time is required as the benchmark, and it should be decorated with volatile
startTime = System.nanoTime();
if (startTime == 0) {
// It's not very understandable here Please know that readers do not hesitate to give advice
startTime = 1;
}
// The first thread submitting the task is await. Wake it up
startTimeInitialized.countDown();
// Next, this do while is the place where the task is really executed, which is very important
do {
// Slide down, in the current code block, the penultimate method
// For example, in the figure introduced earlier, the return value deadline is 200ms
final long deadline = waitForNextTick();
if (deadline > 0) {
// This time, the index corresponding to the bucket array
int idx = (int) (tick & mask);
// Handle the cancelled tasks, which can be ignored.
processCancelledTasks();
// bucket
HashedWheelBucket bucket = wheel[idx];
// Transfer all tasks in the queue to the corresponding buckets. Looking down at the details, the next method of this code block.
transferTimeoutsToBuckets();
// Execute the tasks entered into this bucket
bucket.expireTimeouts(deadline);
tick++;
}
} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);
/* Here, it means that the timer will be closed and some cleaning work will be done */
// Add all tasks not executed in the bucket to the HashSet unprocessed timeouts,
// The main purpose is for the return of the stop() method
for (HashedWheelBucket bucket: wheel) {
bucket.clearTimeouts(unprocessedTimeouts);
}
// The tasks in the task queue are also added to unprocessedTimeouts
for (;;) {
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
break;
}
if (!timeout.isCancelled()) {
unprocessedTimeouts.add(timeout);
}
}
processCancelledTasks();
}
private void transferTimeoutsToBuckets() {
// Here is a for loop, which is specially limited to 100000 times. I'm afraid you write the wrong code and keep throwing tasks in it. It may be useless in practice
for (int i = 0; i < 100000; i++) {
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
// There is no task
break;
}
if (timeout.state() == HashedWheelTimeout.ST_CANCELLED) {
// The task has just been cancelled (it has been done once before transfer)
continue;
}
// The following is to put the tasks into the corresponding bucket. Here we also calculate the remainingRounds of each task
long calculated = timeout.deadline / tickDuration;
timeout.remainingRounds = (calculated - tick) / wheel.length;
final long ticks = Math.max(calculated, tick); // Ensure we don't schedule for past.
int stopIndex = (int) (ticks & mask);
HashedWheelBucket bucket = wheel[stopIndex];
// A single bucket is a linked list composed of HashedWheelTimeout instances,
// You can take a look at the code here. Because it is a single thread operation, there is no concurrency, so the code is very simple
bucket.addTimeout(timeout);
}
}
private void processCancelledTasks() {
//... Too simple to ignore
}
/**
* Let's look at the following method several times and pay attention to its return value
* As mentioned earlier, we use relative time, so:
* The first time you come in, the worker thread will return at 100ms, and the return value is 100 * 10 ^ 6
* The second time you come in, the worker thread will return at 200ms, and so on
* In addition, pay attention to extreme situations. For example, when you come in for the second time, it is already 250ms due to being blocked by the previous task,
* Then, as soon as you enter this method, you need to return immediately. The return value is 250ms, not 200ms
* Look at the code for yourself
*/
private long waitForNextTick() {
long deadline = tickDuration * (tick + 1);
// Nested in an endless loop
for (;;) {
final long currentTime = System.nanoTime() - startTime;
long sleepTimeMs = (deadline - currentTime + 999999) / 1000000;
if (sleepTimeMs <= 0) {
if (currentTime == Long.MIN_VALUE) {
// What happens to this branch? I'm not sure
return -Long.MAX_VALUE;
} else {
// This is the exit, so the return value is the current time (relative time)
return currentTime;
}
}
// Check if we run on windows, as if thats the case we will need
// to round the sleepTime as workaround for a bug that only affect
// the JVM if it runs on windows.
//
// See https://github.com/netty/netty/issues/356
if (PlatformDependent.isWindows()) {
sleepTimeMs = sleepTimeMs / 10 * 10;
}
try {
Thread.sleep(sleepTimeMs);
} catch (InterruptedException ignored) {
// If the timer has been shut down, long MIN_ VALUE
if (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_SHUTDOWN) {
return Long.MIN_VALUE;
}
}
}
}
public Set<Timeout> unprocessedTimeouts() {
return Collections.unmodifiableSet(unprocessedTimeouts);
}
}
Next, we should look at how to execute the tasks in the bucket:
/**
* Here, the tasks in the bucket with round 0, that is, the expired tasks, will be executed.
* The input parameter deadline of this method is actually useless, because all rounds with 0 should be executed.
*/
public void expireTimeouts(long deadline) {
HashedWheelTimeout timeout = head;
// Handle all timeout instances on the linked list
while (timeout != null) {
HashedWheelTimeout next = timeout.next;
if (timeout.remainingRounds <= 0) {
next = remove(timeout);
if (timeout.deadline <= deadline) {
// This line of code is responsible for performing specific tasks
timeout.expire();
} else {
// The code comments here also say that it is impossible to enter this branch
// The timeout was placed into a wrong slot. This should never happen.
throw new IllegalStateException(String.format(
"timeout.deadline (%d) > deadline (%d)", timeout.deadline, deadline));
}
} else if (timeout.isCancelled()) {
next = remove(timeout);
} else {
// Round minus 1
timeout.remainingRounds --;
}
timeout = next;
}
}
The source code analysis part has been finished. There are some simple branches, which will not be introduced here.
Worker threads are processed one bucket at a time. Therefore, even if some tasks take more than 100ms to execute and "occupy" the processing time of several buckets, it doesn't matter. These tasks won't be missed. But it may be delayed. After all, the worker thread is a single thread.
Say an interesting point
In the newTimeout method that submits the task, the start() method of the startup thread is invoked. It ensures that after the thread is actually activated and the startTime is assigned, the start() method returns again. Because a correct starttime is required in the second half of the newtimeout method.
Look at the following two code snippets. Thread submitting task:
public void start() {
......
// Wait until the startTime is initialized by the worker.
while (startTime == 0) {
try {
startTimeInitialized.await();
} catch (InterruptedException ignore) {
// Ignore - it will be ready very soon.
}
}
}
Worker thread:
public void run() {
// Initialize startTime
startTime = System.nanoTime();
if (startTime == 0) {
// We use 0 as an indicator for the uninitialized value here, so make sure it's not 0 when initialized.
startTime = 1;
}
// Here, a CountDownLatch instance is used to communicate
startTimeInitialized.countDown();
......
}
Here, startTime is a volatile modified attribute to ensure its visibility.
However, have you found that the CountDownLatch instance startTimeInitialized can ensure the concurrency here.
Here are two points briefly discussed:
1. Is it OK to replace the while in the first code fragment with if?
no way.
The wait/notify in Object has a false wake-up of the operating system, so it is generally in the while loop, but the CountDownLatch here will not, so it seems that the while here is unnecessary. However, CountDownLatch does not provide awaituninterruptible() method, so this is actually dealing with thread interruption.
2. Can the startTime attribute here be modified without volatile?
Personally, I think it's OK.
Because CountDownLatch provides semantics: the operation before countDown() and the operation after happens before await().
If I understand wrong, please correct me.
Summary
HashedWheelTimer's source code is relatively simple, and its algorithm design is more interesting.
I'll put this diagram here again. You can review its workflow carefully.
Of course, the focus of this paper is to analyze the trunk part, but some branches are not analyzed because they are relatively simple.
Transferred from: HashedWheelTimer usage and source code analysis_ Javadoop