summary
Following the above – introduction, this article explains the implementation of Transport layer.
The following parameters of the NewRaft function are implemented in the form of interface except the Config structure.
In the next few articles, we will analyze these five types of interfaces in detail.
func NewRaft(conf *Config, fsm FSM, logs LogStore, stable StableStore, snaps SnapshotStore, trans Transport) (*Raft, error) {
......
}
What files are involved in the transport layer
-
transport.go: define the transport layer interface, the Transport Interface object in the figure below.
-
inmem_transport.go: implement the Transport interface in memory for testing.
-
net_transport.go: implement the Transport interface in network mode.
-
tcp_transport.go: the SteamLayer required by NetworkTransport is implemented in the way of TCP.
-
command.go: this file defines the structures of various RPC request s and response s, eg: AppendEntriesRequest and AppendEntriesResponse
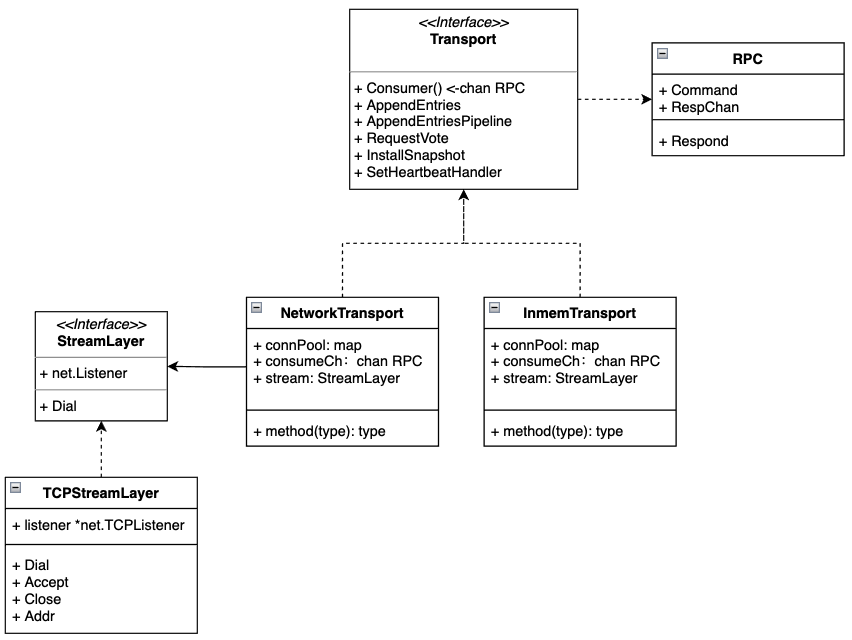
In summary, NetworkTransport and immemtransport are specific implementations of the Transport layer. Next, we will analyze NetworkTransport in detail.
How is the transport layer implemented?
From test case TestNetworkTransport_AppendEntries start
Test cases can generally tell us how to play, and AppendEntries sending logs is the most commonly used function. So let's start here.
-
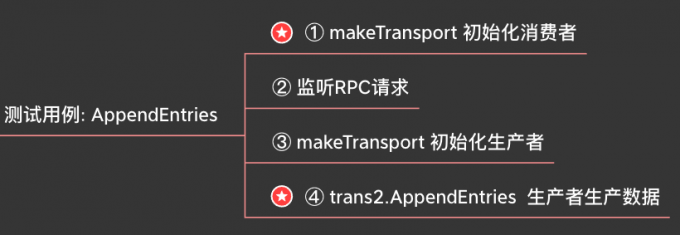
Initialize the consumer (trans1). We will look at this step in detail later, so we mark the star.
-
Start the consumer and listen to rpcCh, that is, the read-only channel returned by Consumer(). 🤔: rpc. The response function just adds an element to respCh. Who will consume this element?
-
Initialize the producer (trans2), also implemented using newTCPTransport.
-
The AppendEntries message is called to the consumer trans1, where it is directly obtained and returned. Why does it look like synchronous return? Normally, network calls are generally returned asynchronously. We'll analyze this step in detail later.
func TestNetworkTransport_AppendEntries(t *testing.T) {
for _, useAddrProvider := range []bool{true, false} {
// ① Initialize trans1 -- consumer
trans1, err := makeTransport(t, useAddrProvider, "localhost:0")
rpcCh := trans1.Consumer()
// Define the RPC request used by the test
args := AppendEntriesRequest{
...
}
resp := AppendEntriesResponse{
...
}
// ② Start consumer monitoring
go func() {
select {
case rpc := <-rpcCh:
// Get the message and return it. Note that the response function only adds a value to the RespChan of the RPC object. Who will consume this and chan
rpc.Respond(&resp, nil)
...
}
}()
// ③ Initialize producer trans2
trans2, err := makeTransport(t, useAddrProvider, string(trans1.LocalAddr()))
// ④ Send the AppendEntries message to trans1, where you can get and return it directly. Why does it look like synchronous return
if err := trans2.AppendEntries("id1", trans1.LocalAddr(), &args, &out); err != nil {
t.Fatalf("err: %v", err)
}
}
}
Analysis of makeTransport implementation
-
First look at the function call relationship
newTCPTransport: the tcp port binding generates tcpstreamlayer (it is known in the class diagram above that it is a required member of the NetworkTransport structure)
NewNetworkTransportWithConfig: creates a NetworkTransport object
makeTransport -> NewTCPTransportWithConfig -> newTCPTransport // It is responsible for binding tcp ports and generating TCPStreamLayer -> NewNetworkTransportWithConfig // Really create NetworkTransport object
-
newTCPTransport
The following is the implementation of newTCPTransport. Finally, the transportCreator is the creator of the network layer
// ① Call net library to bind tcp listening port list, err := net.Listen("tcp", bindAddr) // ② Set tcplistener - > tcpstreamlayer (in the class diagram above, NetworkTransport needs to implement the StreamLayer interface) stream := &TCPStreamLayer{ advertise: advertise, listener: list.(*net.TCPListener), } // ③ Set tcpstreamlayer - > networktransport above and call NewNetworkTransportWithConfig trans := transportCreator(stream) -
newNetworkTransport
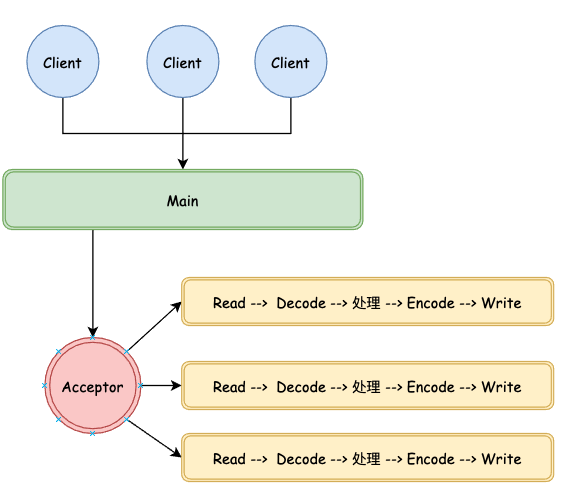
The following is the code for creating the network layer. An Acceptor is specially used for Acceptor connections. Each new connection will create a collaboration process for processing.
-
The Main thread calls trans Listen() starts the listening process
// ① Inject the above config, mainly Stream trans := &NetworkTransport{ connPool: make(map[ServerAddress][]*netConn), consumeCh: make(chan RPC), logger: config.Logger, maxPool: config.MaxPool, shutdownCh: make(chan struct{}), stream: config.Stream, timeout: config.Timeout, TimeoutScale: DefaultTimeoutScale, serverAddressProvider: config.ServerAddressProvider, } // ② Set Stream context trans.setupStreamContext() // ③ Start a background thread to handle the connection go trans.listen() -
The Acceptor listens for new connections and starts the processing process
func (n *NetworkTransport) listen() { for { // ① Receive new connections. The underlying layer is the epoll implementation, conn, err := n.stream.Accept() // ② Start processing process go n.handleConn(n.getStreamContext(), conn) } } -
Process connections
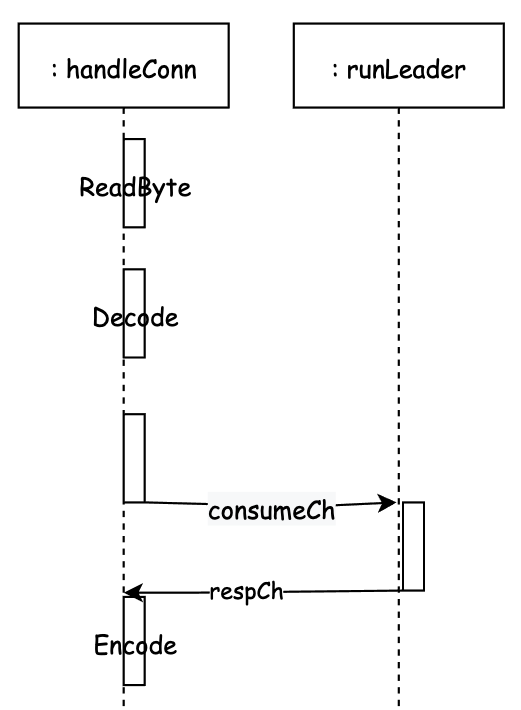
func (n *NetworkTransport) handleConn(connCtx context.Context, conn net.Conn) { r := bufio.NewReaderSize(conn, connReceiveBufferSize) w := bufio.NewWriter(conn) dec := codec.NewDecoder(r, &codec.MsgpackHandle{}) enc := codec.NewEncoder(w, &codec.MsgpackHandle{}) for { // ① Read data -- decode -- Process -- encode if err := n.handleCommand(r, dec, enc); err != nil { ... } // ② Return if err := w.Flush(); err != nil { ... } } }handleCommand is the core processing logic. Here, users feel synchronized when using it through chan.
-
Get the type ReadByte, contract the RPC type represented by the first bit, eg:AppendEntries RequestVote
-
Define respCh.
-
Decode different types of requests.
-
Put the decoded RPC message into the consumption channel
-
Wait for respCh to return the processed structure
-
Encode the structure.
The following is the way to interact with other processes. In fact, the processing logic is outsourced for processing.
func (n *NetworkTransport) handleCommand(r *bufio.Reader, dec *codec.Decoder, enc *codec.Encoder) error { getTypeStart := time.Now() // ① Get the type, contract the RPC type represented by the first bit, eg:AppendEntries RequestVote rpcType, err := r.ReadByte() // ② Define respCh respCh := make(chan RPCResponse, 1) rpc := RPC{ RespChan: respCh, } // ③ Decode different types of requests switch rpcType { case rpcAppendEntries: var req AppendEntriesRequest if err := dec.Decode(&req); err != nil { return err } rpc.Command = &req case rpcRequestVote: var req RequestVoteRequest if err := dec.Decode(&req); err != nil { return err } rpc.Command = &req ... } // ④ Pour the decoded into raft consumeCh select { case n.consumeCh <- rpc: ... } // ⑤ As a result, after the above consumeCh is processed by other collaborations such as Raft's runLeader, the result will be pushed to respCh. RESP: select { case resp := <-respCh: // ⑥ Encode the results if err := enc.Encode(resp.Response); err != nil { return err } } return nil } -
-
AppendEntries implementation analysis
The above transport layer has created the connected processor (consumer). Now it needs the message producer, and AppendEntries can play this role.
RequestVote, AppendEntries and TimeoutNow that require network interaction are implemented by calling genericrc, which is the function that actually executes the request.
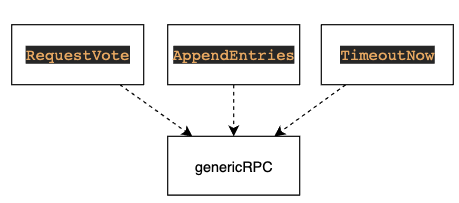
The following is a generic RPC process:
① Get connection objects from the connection pool and simply maintain a connection pool.
② Send RPC requests on the connection.
③ Decode the Response and return conn to the connection pool if possible.
Note: after the request is sent here, the Response is obtained synchronously. If it's a short link, you won't wait for results here for efficiency.
func (n *NetworkTransport) genericRPC(id ServerID, target ServerAddress, rpcType uint8, args interface{}, resp interface{}) error {
// ① Get connections from the connection pool. NetworkTransport maintains a connection pool
conn, err := n.getConnFromAddressProvider(id, target)
// ② Send RPC request
if err = sendRPC(conn, rpcType, args); err != nil {
return err
}
// ③ Decode the Response and return the connection. Note: after the request is sent here, the Response will be decoded immediately. Think about our mysql client (sending messages and other results). You can't send messages without receiving them all the time.
canReturn, err := decodeResponse(conn, resp)
if canReturn {
n.returnConn(conn)
}
return err
}
Let's compare inmemtransport The makerpc method is used to realize the difference. The results obtained here need to be read from respCh. So, who inserted the Response into respCh? After all, we just got it.
func (i *InmemTransport) makeRPC(target ServerAddress, args interface{}, r io.Reader, timeout time.Duration) (rpcResp RPCResponse, err error) {
// Define RPC objects for interaction
req := RPC{
Command: args,
Reader: r,
RespChan: respCh,
}
// Send a message and directly pour the constructed req into peer Consumerch consumes channel s, which are objects in memory.
select {
case peer.consumerCh <- req:
...
}
// Wait for the respCh result, and the consumption Association will take out the RPC - process - and plug the result back to respCh.
select {
case rpcResp = <-respCh:
if rpcResp.Error != nil {
err = rpcResp.Error
}
....
}
reflection:
1. The above implementation is one by one. In fact, we often batch process for efficiency.
2. If RequestVote wants to send voting messages to multiple objects, it will certainly not send a message and other results, but send them in groups, and then process the structure.
AppendEntriesPipeline implementation
Similarly, let's start with test cases and see how batch processing plays. Mainly look at the difference between batch processing and single processing.
// Initialize the AppendEntriesPipeline object and start the collaborative process inprogressch - > donech
pipeline, err := trans2.AppendEntriesPipeline("id1", trans1.LocalAddr())
// Send 10 messages and add RPC to inprogressCh
for i := 0; i < 10; i++ {
out := new(AppendEntriesResponse)
if _, err := pipeline.AppendEntries(&args, out); err != nil {
t.Fatalf("err: %v", err)
}
}
// Consumer() will return doneCh, get data from doneCh and send 10 messages, so you need to get the results 10 times
respCh := pipeline.Consumer()
for i := 0; i < 10; i++ {
select {
case ready := <-respCh:
...
}
}
The following is the difference between non pipeline and pipeline when sending messages
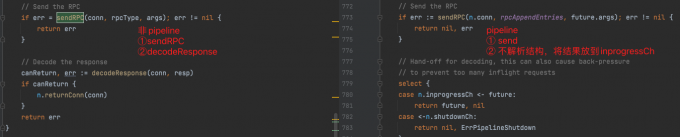
The following is the difference between non pipeline and pipeline when decoding messages. The coderesponses method of pipeline is a process started when initializing the AppendEntriesPipeline object.
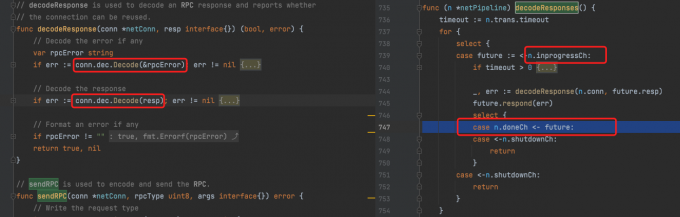
Here's one ❓ Question about net Conn's a - > b - > A. can both sides of the network send data at the same time? Why is the non pipeline mode above? You can decode the message immediately after sending. What does conn do for us here.
The overall implementation of batch processing is to start a collaborative process monitoring inprogress task. Then develop batch messages, such as sending 10 messages at a time, and then the inprogress process is activated to start processing. Put the processing results into doneCh, and finally the user can get the message from doneCh.
RequestVote process
Above, we analyzed one-to-one pipeline sending messages. Next, let's take a look at 1:N, sending messages to everyone in the cluster and processing structure
func (r *Raft) electSelf() <-chan *voteResult {
// ① Create a respCh containing the number of peers
respCh := make(chan *voteResult, len(r.configurations.latest.Servers))
// ② Send messages concurrently, and then pour the results back to respCh. Later, you can get the voting results from respCh for processing.
askPeer := func(peer Server) {
r.goFunc(func() {
resp := &voteResult{voterID: peer.ID}
err := r.trans.RequestVote(peer.ID, peer.Address, req, &resp.RequestVoteResponse)
...
respCh <- resp
})
}
return respCh
}
summary 🤔
Network is a very complex module. You can see the implementation of classic Redis and Nginx in the future.