1. Nagging
- On the interpretation of HashMap source code, check a lot online
- Although they are similar, as a rookie, I'm always afraid that if I don't pay attention to any knowledge point, I'll miss 100 million 😂
- At the same time, I also need to screen, identify and integrate these knowledge
- If you want to have the confidence to say that this place is not written correctly, you should study the source code more
- Starting from JDK 1.8, the underlying structure of HashMap has changed from bucket array + linked list to bucket array + linked list + red black tree to solve the degradation of search efficiency caused by too long linked list
O
(
n
)
O(n)
O(n) problem
1.1 methods for handling hash conflicts
-
HashMap is implemented based on hash table. The number of entries increases and hash calculation is uneven. Hash conflict is inevitable
-
HashMap uses the zipper method to solve hash conflicts, that is, entries with the same hash value are placed in the same bucket and connected in the form of a linked list
-
In the hash table, the bucket is actually a position in the array; The essence of hash table is array, also known as bucket array
Classic interview question: when hash conflicts, is the entry inserted into the head or tail of the linked list?
-
Before JDK 1.8, header insertion was used: the original linked list was directly used as the next of the new entry
// JDK 1.6 void addEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<K,V>(hash, key, value, e); // e is assigned to the next of the new nentry if (size++ >= threshold) resize(2 * table.length); } -
In JDK 1.8, the tail interpolation method is used: in the putVal() method, when p is the end node of the linked list, the new entry is taken as its next
if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } -
Thanks for the blog: Is HashMap inserted into the head or tail of the linked list
In addition to the zipper method, there are three ways to deal with hash conflicts
- Re hashing: in case of hash conflict, use more hash functions to calculate the address until there is no conflict
- Open addressing method: used in case of hash conflict
(
h
a
s
h
(
k
e
y
)
+
d
i
)
%
m
(hash(key) + di) \% m
(hash(key)+di)%m calculate the new address until there is no conflict
(1) Linear detection: di = 1, 2, 3, 4,..., m - 1
(2) Square detection: di= 1 2 1^2 12, − 1 2 - 1^2 −12, 2 2 2^2 22, − 2 2 - 2^2 −22, ... , k 2 k^2 k2, − k 2 - k^2 −k2
(3) Random detection: di is a set of pseudo-random numbers - Establish a public overflow area: the hash table is divided into a basic table and an overflow table. Any conflict with the basic table is recorded in the overflow table (the online explanations are almost conceptual, and the specific implementation needs in-depth study)
1.2 features of HashMap
- Before, we learned that almost all of a class is to search the detailed explanation of this class on the Internet, and then see whether it meets the needs
- When learning HashMap, I was pleasantly surprised to find that if I want to understand a class, it is a very good way to read more class annotations
The class annotation of HashMap contains the following information:
- HashMap implements the Map interface and allows the key or value to be null (at most one key is null, and multiple values can be null)
- HashMap does not guarantee the order of entries (such as the insertion order or the natural order of key s). On the contrary, the order of entries may change over a period of time (rehash is required during capacity expansion)
rehash is actually the operation of recalculating the hash to update the location after the hash table is resize d. rehash can be equivalent to capacity expansion
- HashMap is non thread safe:
(1) For use under multithreading, either select a thread safe compatible class, such as ConcurrentHashMap
(2) Either convert it to a thread safe class through Collections.synchronizedMap(), and it is better to convert it at the time of creation to avoid unexpected asynchronous access
(3) Difference from HashTable: HashTable is thread safe, but it does not allow key or value to be null - HashMap uses a fail fast iterator: once an iterator is created, unless the iterator's remove method is used, any other method that changes the HashMap structure will cause the iterator to throw a ConcurrentModificationException
- Impact of initial capacity, load factor and threshold on HashMap
(1) Capacity, capacity, the number of buckets in the hash table; Initial capacity, initial capacity, capacity when creating hash table (DEFAULT_INITIAL_CAPACITY is 16)
(2) loadFactor: load factor, the proportion that the hash table can use, that is, the full degree of the hash table (DEFAULT_LOAD_FACTOR is 0.75 by default)
(3) Threshold: when the number of entries in the HashMap exceeds the threshold, the hash table will be expanded to twice the current number of buckets
(4) threshold = capacity * loadFactor. Note: when the hash table has not allocated memory, the initial capacity is stored in threshold, as shown below
(5) Try to set the initial capacity of HashMap to a large value to avoid frequent resize (capacity expansion) when the amount of data is large; Alibaba's Java development manual stipulates that initialCapacity = (number of elements to be stored / load factor) + 1 to avoid resize
(6) The iterative operation time is related to the size of the bucket array and the number of entries. You cannot set the capacity too high (the hash table occupies more storage space) or the loadFactor too low (it is easy to trigger rehash)
(7) Setting loadFactor to 0.75 has a good tradeoff between time and space: the higher the loadFactor, the lower the space overhead, but the higher the search cost.The higher the loadFactor, the less likely it is to trigger the capacity expansion operation, and the smaller the length of the hash table; However, hash conflicts are more likely to occur, and the lookup operation is more time-consuming
- Hashcodes for different keys should be as different as possible: this can reduce hash conflicts and reduce the length of the linked list; If the length of the linked list is too large, you should consider using the comparison order to organize keys with the same hashCode (linked list to red black tree)
Reference link:
- Source code analysis: HashMap 1.8
- HashMap source code analysis (JDK 1.8)
- You initialized the capacity of HashMap, but made the performance worse?
2. HashMap overview
2.1 class diagram
-
The declaration of HashMap class is as follows:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable -
Class diagram, as shown in the figure below
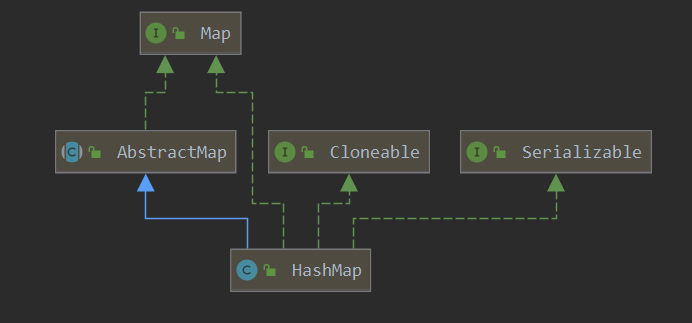
Interpretation of HashMap from class diagram
- Intuitively, HashMap inherits the AbstractMap abstract class and implements the Map, Cloneable and Serializable interfaces
- AbstractMap abstract class: it implements the Map interface and implements the Map interface at the skeleton level, which greatly reduces the workload required to implement the Map interface
- Map interface: it is the basic interface of the map system, defines various methods related to map operation, and replaces the completely abstract class of Dictionary
- Clonable interface: description HashMap supports clone operation
- Serializable interface: description HashMap supports serialization and deserialization
Question: why do you need to implement the Map interface after inheriting the AbstractMap class?
-
From the class diagram, we can see that the AbstractMap class itself implements the Map interface.
-
HashMap not only inherits the AbstractMap class, but also implements the Map interface, which is superfluous
-
Reason 1: there is a reason why the JDK source code is written like this. For example, the Map interface can be obtained directly through the getInterfaces() method in the launch
-
Reason 2: This is a mistake of the author Josh Bloch at that time
- At first, he thought it might be valuable in some places until he realized he was wrong
- JDK maintainers didn't think this small error was worth modifying, so they kept it all the time
- In fact, without the Map interface, the whole HashMap can still run normally
-
Reference link:
- Why does LinkedHashSet extend HashSet and implement Set (it is from the answer to this question that we know that this is a mistake of the author)
- Since HashMap inherits AbstractMap, why should HashMap be implemented (English translation of the above Q & A)
- Why does HashMap inherit AbstractMap and implement the Map interface (two reasons are proposed)
- Evidence of incorrect writing: Why does HashMap inherit AbstractMap and implement Map interface?
2.2 member variables
-
There are many static final member variables (class constants) in HashMap. These class constants are related to HashMap capacity expansion, tree (to red black tree), etc
// The capacity / length (bucket size) of the hash table must be a power of 2, and the default value is 16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 // max capacity of hash table, 2 ^ 30 static final int MAXIMUM_CAPACITY = 1 << 30; // Load factor, default 0.75 static final float DEFAULT_LOAD_FACTOR = 0.75f; // In a single bucket, the threshold value of the linked list to the red black tree is greater than 8, and the linked list to the red black tree static final int TREEIFY_THRESHOLD = 8; // In a single bucket, the threshold value for the red black tree to return to the linked list is less than or equal to 6 static final int UNTREEIFY_THRESHOLD = 6; // Threshold value of hash table to red black tree, greater than 64 static final int MIN_TREEIFY_CAPACITY = 64;
-
Instance variable
// Bucket array, the size is always a power of 2 // Memory is not allocated when it is created, but when it is first used transient Node<K,V>[] table; // Cached entrySet transient Set<Map.Entry<K,V>> entrySet; // The number of entries in the hash table transient int size; // The number of times that the HashMap structure has been modified, such as put and remove, is used to implement the fail fast iteration transient int modCount; // The capacity expansion threshold = capacity * loadFactor. If it is greater than the threshold, the capacity will be expanded; initial capacity may be stored int threshold; // Load factor, full degree of hash table final float loadFactor;
2.3 constructor
-
The constructor of HashMap is as follows:
public HashMap(int initialCapacity, float loadFactor) { // Input parameter verification if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; // The initialCapacity entered will be converted to the power of the smallest 2 greater than this value (referred to in this article as the power of the last 2) this.threshold = tableSizeFor(initialCapacity); } /** * Build a HashMap with the specified initial capacity, and the loadFactor will use the default value of 0.75 */ public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } // HashMap, initial capacity and loadFactor that do not specify any parameters will use the default values public HashMap() { // When used for the first time, the bucket array size is 16 this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted } // Build a HashMap from the existing map, and the loadFactor uses the default value public HashMap(Map<? extends K, ? extends V> m) { this.loadFactor = DEFAULT_LOAD_FACTOR; putMapEntries(m, false); }
Question 1: how does the tableSizeFor() method calculate the power of the nearest 2 of a number?
-
The code of the tableSizeFor() method is as follows:
static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; } -
In the code, the calculation of signed right shift and XOR is carried out continuously to calculate the mask of cap
-
After the mask is calculated, + 1 is the power of the last 2 of cap
-
Do not delve into the specific mathematical principles. If you want to verify your ideas, you can find a number to calculate, or check the blog: Detailed analysis of HashMap source code (JDK1.8)
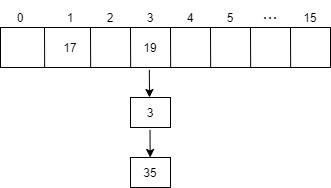
Question 2: why is the first constructor assigned to threshold after initial capacity becomes a power of 2?
- According to the previous learning, threshold represents the capacity expansion threshold of HashMap, not the capacity of hash table
- After the initialCapacity is converted to the power of the smallest 2 greater than the value, it is assigned to the variable threshold, which seems that the code is not written correctly 😂
- Check the resizing method resize(). It is found that the HashMap created through this constructor is resized for the first time
- oldCap = 0, oldthreshold = threshold, assumed to be 32
- At this time, in case 2 of condition judgment, oldThr will be assigned to newCap
- That is, the value of newCap will become the initial value of threshold, 32
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { // Case 1 // ... } else if (oldThr > 0) // Case 2 // The table is not initialized, but the threshold is greater than 0, indicating that the initial capacity is stored in the threshold newCap = oldThr; else { // Case 3 // The corresponding constructor, public HashMap(), has a threshold of 0, and the default values of newCap and newThr are used newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } // ... }
- Why is it so troublesome? Later, there was a reason
- In HashMap, initialCapacity has no corresponding instance variable, but only one class variable, default_ INITIAL_ Capability to record its default value
- The author skillfully realizes the storage of initialCapacity and the judgment of various initialization conditions with the help of threshold
2.4 determining bucket subscript
-
To find, add or delete an entry, you need to determine the bucket subscript of the entry first
-
The position of entry in the hash table depends on the hash value of the key. The hash value of the key should be calculated before calculating the bucket subscript
-
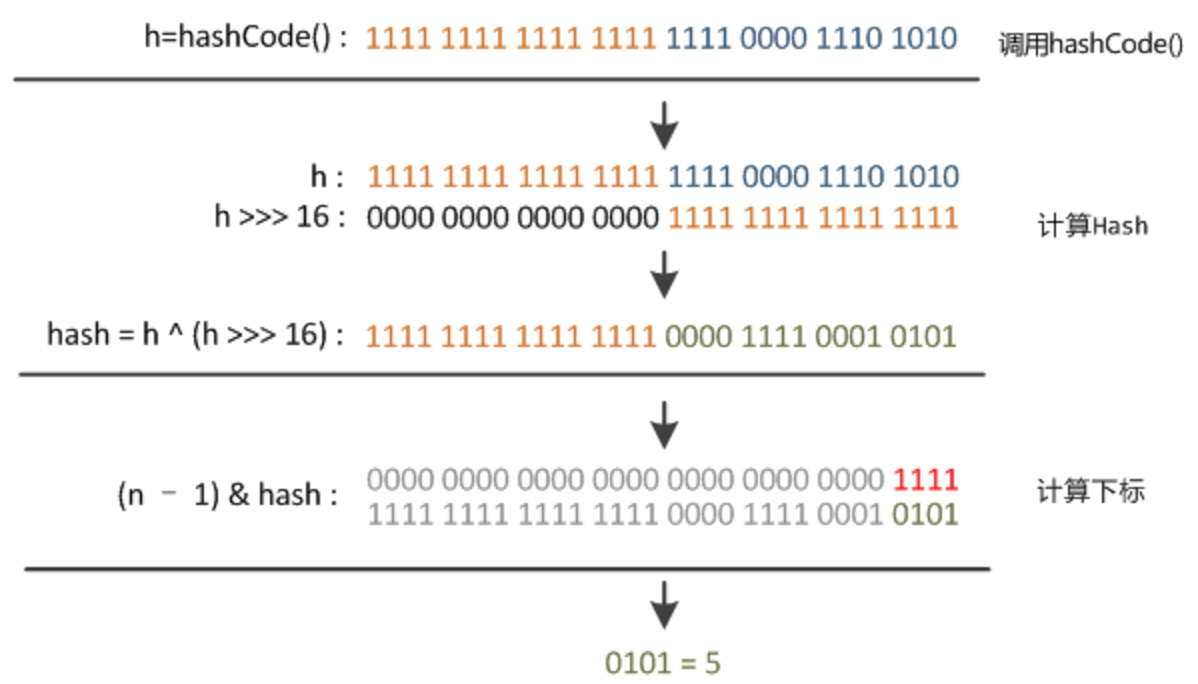
In HashMap, the hash value is calculated as follows:
(1) If the key is null, 0 is returned directly, that is, the null hash value is 0 by default;
(2) If the key is not null, first obtain the hashCode of the key, and then move the hashCode 16 bits to the right without sign on the XORstatic final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } -
Calculation of bucket subscript:
// n is the capacity of the bucket array (n - 1) & hash
Question 1: why not use hash% n directly to calculate bucket subscript?
-
Hash% N and (n - 1) & the results of hash are the same. Between bit operation and mathematical operation, bit operation with congenital advantage must be selected
-
For example, n = 16, hash = 18, direct% calculation, bucket subscript 2; The result of the bit operation is also 2:
hash : 0001 0010 n - 1 : 0000 1111 (n - 1) & hash: 0000 0010
Question 2: why not use the hashCode of the key directly?
- hashCode is 32 bits, because the value of n is usually very small (no more than 65536)
- If hashCode & (n - 1) is directly, only the lower 16 bits of hashCode are involved in the calculation
- The calculated hash value has uneven hash
- Therefore, move the hashCode unsigned right by 16 bits, and then XOR the original hashCode, so that the high 16 bits can also participate in the calculation of the hash value
- Thus, the hash of hash value is more uniform, and the probability of hash collision is lower
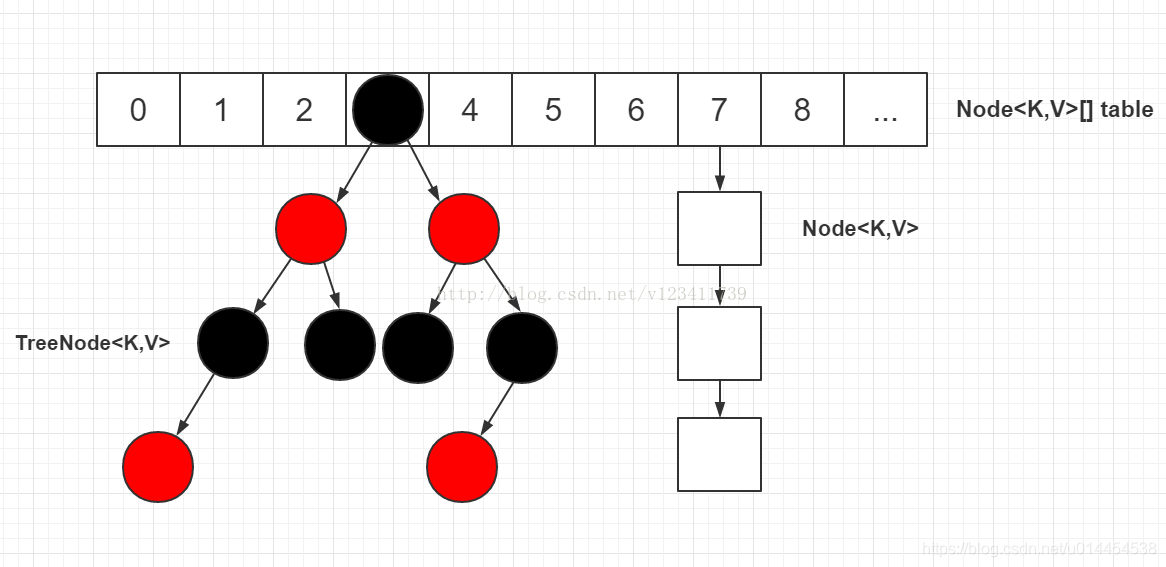
2.5 important data structure
- When learning TreeMap before, the entry of TreeMap (the node of red black tree) is at least called entry
- It's easy for me to learn
static final class Entry<K, V> implements Map.Entry<K, V> { // Code omitted} - The entry in the HashMap corresponds to the Node or the TreeNode that inherits the Node, which makes me uncomfortable all of a sudden
- But think about it, the author's name is also reasonable. This is a linked list Node or tree Node. It's understandable to call it Node
- Node is defined as follows:
- As a node to build a linked list, its value should be: key, value (mapping), and then there is a next reference
- In addition, to avoid using the hash value of the node, the hash value is recalculated every time, and a hash field is added to store the hash value
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } } - TreeNode is defined as follows:
- TreeNode inherits LinkedHashMap.Entry, and LinkedHashMap.Entry inherits HashMap.Node
- It can be said that TreeNode eventually inherits the Node of HashMap itself
- In the TreeNode, in addition to the common parent, left, right and red (color) of red and black trees, there is also a prev reference
- prev and next are used together to retain the node order of the original linked list after tree
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red; TreeNode(int hash, K key, V val, Node<K,V> next) { super(hash, key, val, next); } } static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; // The key to realize bidirectional linked list Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }
- The picture shows the effect of linked list tree (the prev reference is omitted).
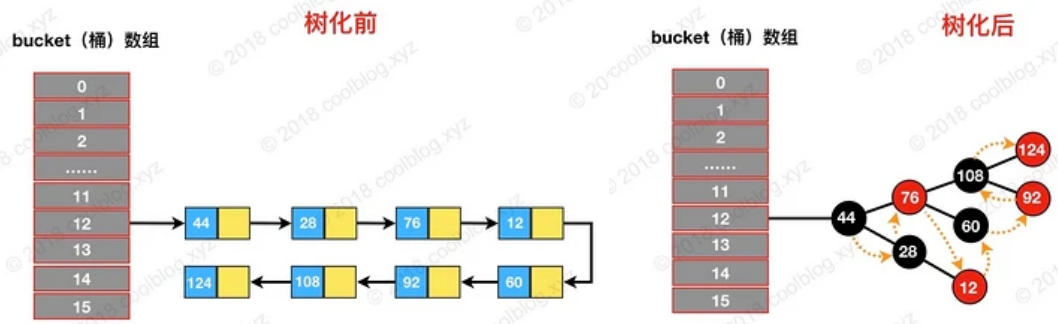
- according to Blog This structure paves the way for traversing nodes in the order of the linked list, dividing the red black tree, and turning the red black tree back to the linked list