Tell me about the internal data structure of HashMap?
JDK1.8 version, internal use of array + linked list / red black tree.
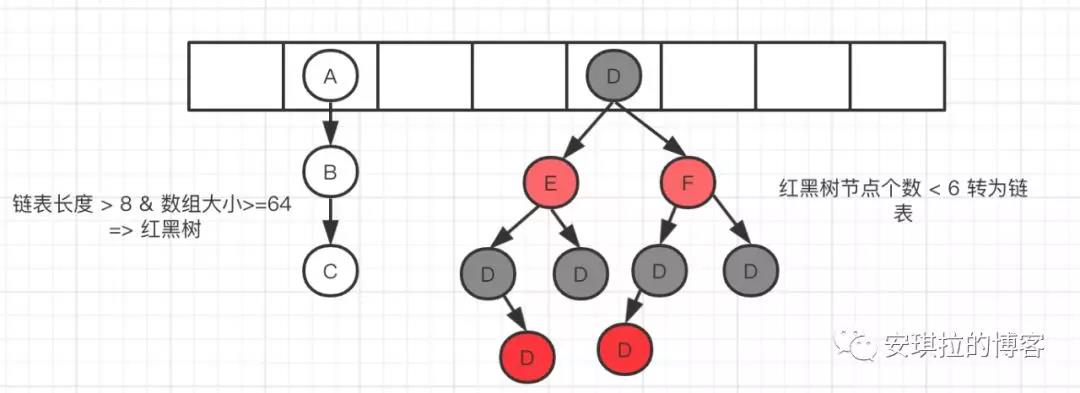
Data structure diagram of HashMap
Insertion principle of HashMap
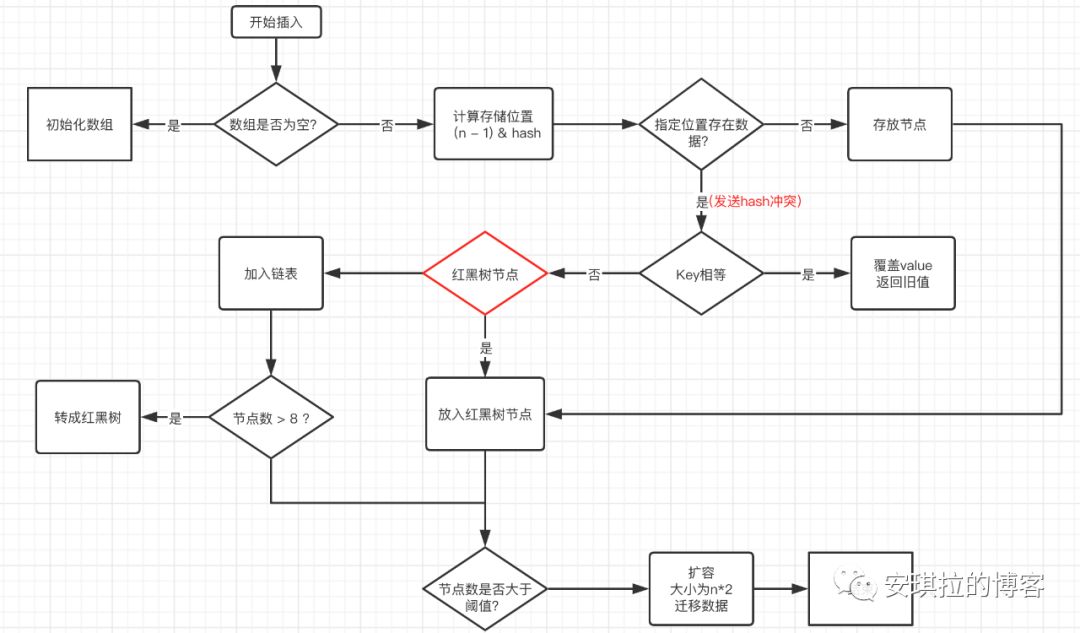
- Judge whether the array is empty and initialize if it is empty;
- If it is not empty, calculate the hash value of k, and calculate the subscript index that should be stored in the array through (n - 1) & hash;
- Check whether there is data in table[index]. If there is no data, construct a Node and store it in table[index];
- If there is data, it indicates that there is a hash conflict. Continue to judge whether the key s are equal. If they are equal, replace the original data with a new value (onlyIfAbsent is false);
- If not, judge whether the current node type is a tree node. If it is a tree node, create a tree node and insert it into the red black tree;
- If it is not a tree Node, create an ordinary Node and add it to the linked list; Judge whether the length of the linked list is greater than 8. If it is greater than 8, the linked list will be converted into a red black tree;
- After the insertion is completed, judge whether the current number of nodes is greater than the threshold value. If it is greater than the threshold value, expand the capacity to twice the original array.
Initialization of HashMap. How does HashMap set the initial capacity?
Generally, if new HashMap() does not pass the value, the default size is 16 and the load factor is 0.75. If you pass in the initial size k, the initial size is an integer power greater than 2 of K. for example, if you pass in 10, the size is 16. (supplementary note: the implementation code is as follows)
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
When it comes to hash function, do you know how to design the hash function of HashMap? Why is it so designed?
The hash function first obtains the hashcode passing through the key, which is a 32-bit int value, and then makes the high 16 bits and low 16 bits of the hashcode XOR.
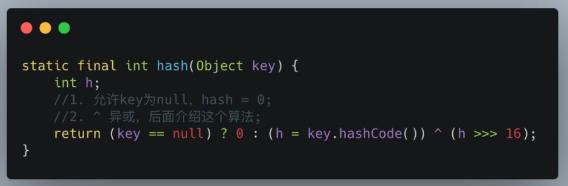
hash function is also called disturbance function. There are two reasons for this design:
- The hash collision must be reduced as much as possible, and the more dispersed, the better;
- The algorithm must be as efficient as possible because it is a high-frequency operation, so bit operation is adopted.
Why can the high 16 bit and low 16 bit XOR of hashcode reduce hash collision? Can the hash function directly use the hashcode of the key?
Because key The hashcode() function calls the hash function of the key value type and returns the int type hash value. The int value range is - 2147483648 ~ 2147483647, which adds up to about 4 billion mapping space. As long as the hash function is mapped evenly and loosely, it is difficult to collide in general applications. But the problem is that an array with a length of 4 billion can't fit into memory. You think, if the initial size of the HashMap array is only 16, you need to modulo the length of the array before using it, and the remainder can be used to access the array subscript.
The modular operation in the source code is to do an "and" operation on the hash value and array length - 1. The bit operation is faster than the% operation.
bucketIndex = indexFor(hash, table.length);
static int indexFor(int h, int length) {
return h & (length-1);
}
This also explains why the array length of HashMap should take an integer power of 2. Because this (array length - 1) is exactly equivalent to a "low mask". The result of the and operation is that all the high bits of the hash value return to zero, and only the low bits are reserved for array subscript access. Take the initial length 16 as an example, 16-1 = 15. Binary means 00000000 00000000 00001111. And a hash value. The result is to intercept the lowest four digit value.
JDK1.8 optimized the hash function. Is there any other optimization in 1.8?
1.8 there are three main optimizations:
- Array + linked list is changed to array + linked list or red black tree;
- The insertion method of the linked list is changed from the head insertion method to the tail insertion method. In short, when inserting, if there are elements in the array position, 1.7 put the new elements into the array, the original node as the successor node of the new node, 1.8 traverse the linked list and place the elements at the end of the linked list;
- During capacity expansion, 1.7 needs to re hash the elements in the original array to the position of the new array. 1.8 uses simpler judgment logic, with the position unchanged or the index + the size of the old capacity;
- When inserting, 1.7 first judges whether the capacity needs to be expanded and then inserts. 1.8 first inserts and then judges whether the capacity needs to be expanded after the insertion is completed.
Tell me why we should do these optimizations?
-
Prevent hash conflicts, the length of the linked list is too long, and reduce the time complexity from O(n) to O(logn);
-
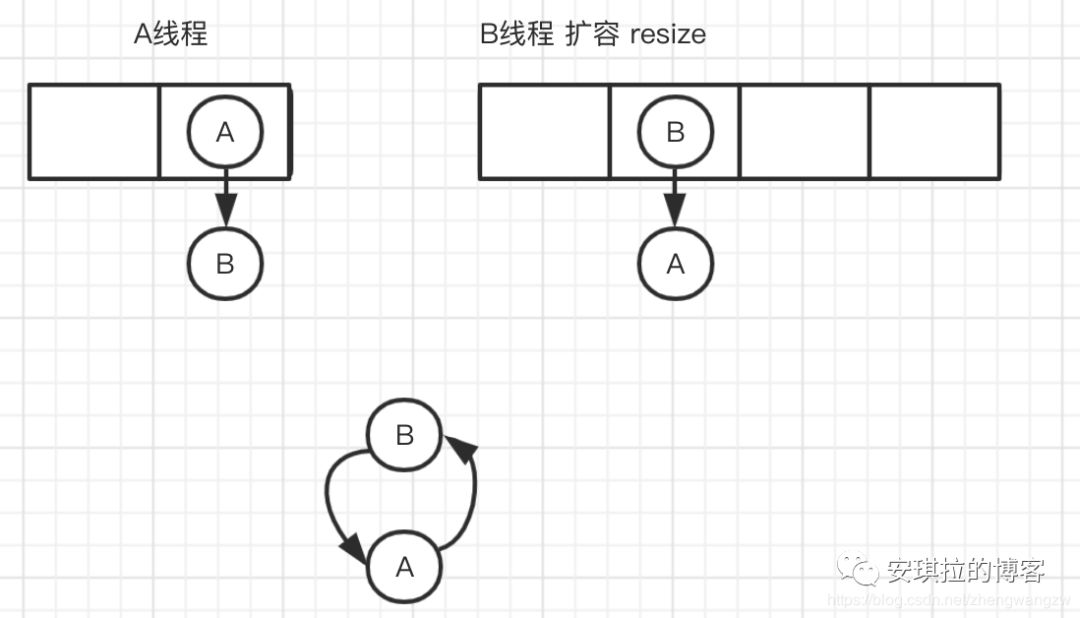
Because 1.7 when expanding the capacity of the head insertion method, the head insertion method will reverse the linked list and generate rings in the multithreaded environment;
Thread A is inserting into node B, and thread B is also inserting. When the capacity is insufficient, start to expand the capacity, re hash, place the elements, and use the header insertion method. After traversing node B, put the header, forming A ring, as shown in the following figure:
1.7 call the transfer code for capacity expansion, as shown below:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; //If the execution of thread A is suspended at this line, thread B starts to expand the capacity
newTable[i] = e;
e = next;
}
}
}
-
Why can 1.8 directly locate the location of the original node in the new data without re hash ing during capacity expansion?
This is because the capacity expansion is twice the size of the original array, and the mask used to calculate the array position is only one higher bit. For example:
The length before capacity expansion is 16, and the binary n - 1 used to calculate (n-1) & hash is 0000 1111,
After the capacity expansion is 32, the binary bit is 1 more than the high bit, ==================> is 0001 1111.
Because it is & operation, 1 and any number & are itself, it can be divided into two cases, as shown in the following figure: the case where the high-order bit 4 of the original data hashcode is 0 and the high-order bit is 1;
The high order of the fourth bit is 0, the rehash value remains unchanged, and the fourth bit is 1. The rehash value is 16 larger than the original (the capacity of the old array).

Is HashMap thread safe?
No, in a multithreaded environment, 1.7 will have problems of life and death cycle, data loss and data coverage, and 1.8 will have problems of data coverage.
Take 1.8 as an example. When thread A executes to line 6 of the following code and determines that the index position is empty, it just hangs. Thread B starts to execute line 7 and write node data to the index position. At this time, thread A recovers the site and performs the assignment operation to overwrite the data of thread A.
In addition, line 38 + + size will also cause problems such as simultaneous capacity expansion of multiple threads.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) //Multithreaded execution ends here
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold) // When multiple threads come here, they may repeat resize()
resize();
afterNodeInsertion(evict);
return null;
}
How do you usually solve this thread unsafe problem?
There are hashtables and collections in Java Synchronized Map and concurrent HashMap can realize thread safe Map.
- HashTable directly adds the synchronized keyword to the operation method to lock the entire array, with large granularity;
- Collections.synchronizedMap is an internal class using the collections collection tool. It encapsulates a SynchronizedMap object through the incoming Map, defines an object lock internally, and is implemented through the object lock in the method;
- Concurrent HashMap uses segmented locks, which reduces the lock granularity and greatly improves the concurrency.
Do you know the implementation principle of segment lock of ConcurrentHashMap?
The ConcurrentHashMap member variable is decorated with volatile to avoid instruction reordering and ensure memory visibility. In addition, CAS operation and synchronized are used to realize assignment operation. Multithreading operation will only lock the node of the current operation index.
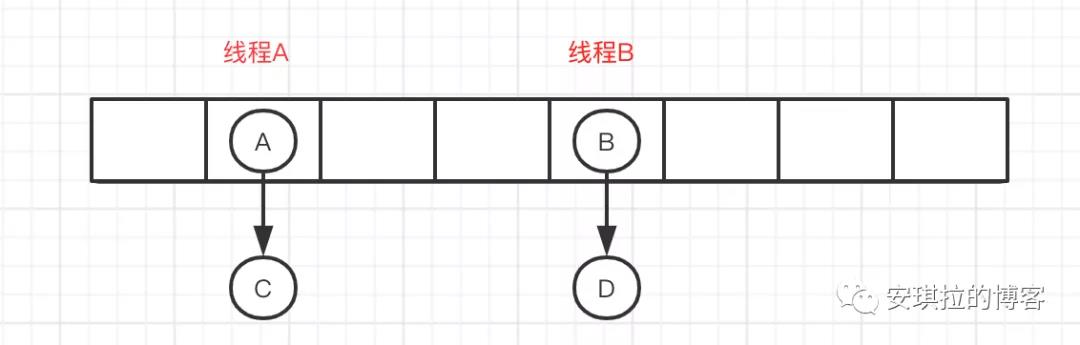
As shown in the following figure, thread A locks the linked list where node A is located, and thread B locks the linked list where node B is located. The operations do not interfere with each other.
The linked list to red black tree is that the length of the linked list reaches the threshold. What is the threshold?
The threshold is 8 and the red black tree to linked list threshold is 6.
Why 8, not 16, 32 or even 7? Why is the threshold of red black tree to linked list 6, not 8?
Because the author designed it like this, oh, no, because after calculation, under the condition of reasonable hash function design, the probability of 8 hash collisions is 6 parts per million.. Because 8 is enough. As for why it turns back to 6, if the number of hash collisions hovers around 8, the conversion of linked list and red black tree will always occur. In order to prevent this from happening.
Are the internal nodes of HashMap orderly? Is there an orderly Map?
HashMap is unordered and inserted randomly according to the hash value. LinkedHashMap and TreeMap are ordered maps
How does LinkedHashMap achieve order?
LinkedHashMap internally maintains a single linked list with head and tail nodes. At the same time, LinkedHashMap Node Entry not only inherits the Node attribute of HashMap, but also before and after are used to identify the pre Node and post Node. You can sort by insertion order or access order.
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
//Link the newly added p node to the back end of the linked list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
//Node class of LinkedHashMap
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
Tell me about how TreeMap realizes order?
TreeMap is sorted according to the natural order of keys or the order of comprators. It is internally implemented through red black trees. Therefore, either the class to which the key belongs implements the Comparable interface, or customize a Comparator that implements the Comparator interface and pass it to the TreeMap user for key comparison.