HashMap is a frequently asked question in the interview, whether it is primary, intermediate or advanced, but the depth is different. Today, we will analyze the source code of HashMap in detail. In order to finish reading it in time, we will analyze it in multiple articles, starting with version 1.7 JDK,
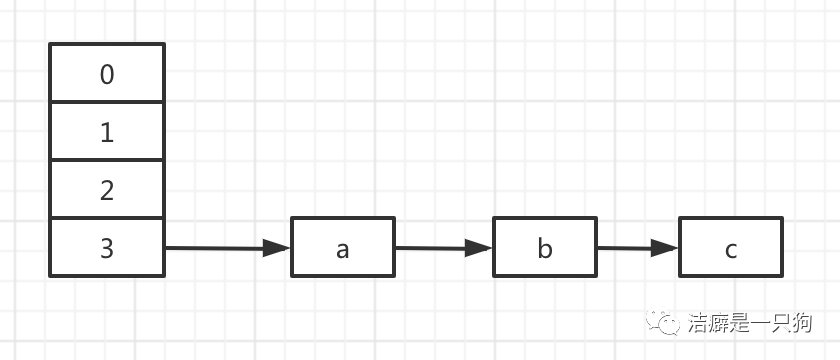
I think we all know the basic concept, so let's start with the source code of 1.7 JDK. The following figure is the HashMap data structure
put method
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null) //1. Processing when the key is null
return putForNullKey(value);
int hash = hash(key); //2. Calculate hash value
int i = indexFor(hash, table.length);//3. Find the following table of the array
for (Entry<K,V> e = table[i]; e != null; e = e.next) { //4. Traverse the linked list to find the corresponding value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
//5. If the corresponding key is found, the value will be overwritten and the old value oldValue will be returned
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//6. If it cannot be found, add an Entry node
modCount++;
addEntry(hash, key, value, i);
return null;
}
- First, handle the case where key=null
- If it is not equal to null, the hash value of the key will be calculated
- Index of array found
- Traverse the linked list according to the subscript loop
- If the corresponding key is found, the value will be overwritten
- If it is not found, an Entry node will be added
Then let's take a look at the important logical methods in put. First, let's take a look
putForNullKey
private V putForNullKey(V value) {
//1. The values with key=null are put into table[0]
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
//2. If the key is found to be null, the old value will be replaced, and then the old value
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//3. If it is not found in table[0], create a new entry with key=null
addEntry(0, null, value, 0);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
//4. If the size exceeds the threshold and the table[0] is not null,
if ((size >= threshold) && (null != table[bucketIndex])) {
//5. Capacity expansion
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
//6. Recalculate subscript
bucketIndex = indexFor(hash, table.length);
}
//7. Add new nodes using header insertion method
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}putForNullKey logic is relatively simple. First select the linked list at table[0], then traverse the linked list to find the node with key=null, replace the old value with the new value, and then add an Entry node with null key if it is not found
The logic of addEntry is to add an entry. It is also responsible for the capacity expansion mechanism. After the capacity expansion, the data will be migrated, that is, the linked list of the old array will be transferred to the new array, the subscript will be recalculated, and then the header insertion method will be used to add nodes
hash method and indexFor method
//The perturbation function is to reduce hash conflicts
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
//The performance will be better if the and operation is used here, and the length of the hashMap is a power of 2
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}Here, the hash function is to distribute evenly as much as possible and reduce hash conflicts. It is to retain the high and low bits, and then conduct and operation on the high and low bits. indexFor is to calculate the array subscript, that is, the actual storage location. The and bit operation is used for higher performance
Here, why must the length of HashMap be a power of 2
- Reduce the probability of collision and make the hash more uniform,
- If the length is a power of 2, the last binary bit of length-1 must be 1. When the hash value performs and operation, the last bit may be 1 or 0, that is, it is either even or odd. However, if length is not a power of 2, length-1 is an even number. Therefore, h& (length-1) can only be odd, which will waste half of the space
get method
public V get(Object key) {
if (key == null)
//1. If key=null, traverse the table[0] of the array to get the corresponding value, otherwise null is returned
return getForNullKey();
//2.key!=null, call the following method to get
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
private V getForNullKey() {
if (size == 0) {
return null;
}
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
final Entry<K,V> getEntry(Object key) {
//3. If size=0, null will be returned
if (size == 0) {
return null;
}
//4. Calculate the hash value of the key
int hash = (key == null) ? 0 : hash(key);
//5. Calculate the subscript according to the hash value, and then cycle through the linked list to obtain the corresponding value
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
The get method is relatively simple. If key=null, get the corresponding value in the table[0] linked list. If key=null, calculate the hash value of the key, calculate the subscript position, and then traverse the corresponding linked list to find the corresponding value. Otherwise, null is returned