Before reading this article, it is recommended to read the blogger's article on HashMap:
HashMap source code analysis + interview questions
HashSet source code analysis
1, Basic introduction
-
The underlying implementation is based on HashMap, so it is not guaranteed to iterate according to the insertion order or other order
-
The time-consuming performance of add, remove, continins, size and other methods will not increase with the increase of the amount of data. This is mainly related to the underlying data structure of HashMap. No matter how large the amount of data is and regardless of hash conflict, the time complexity is O (1)
-
Thread unsafe, null value allowed
-
During the iteration, if the data structure is changed, it will fail quickly and throw a ConcurrentModificationException
-
Inheritance system
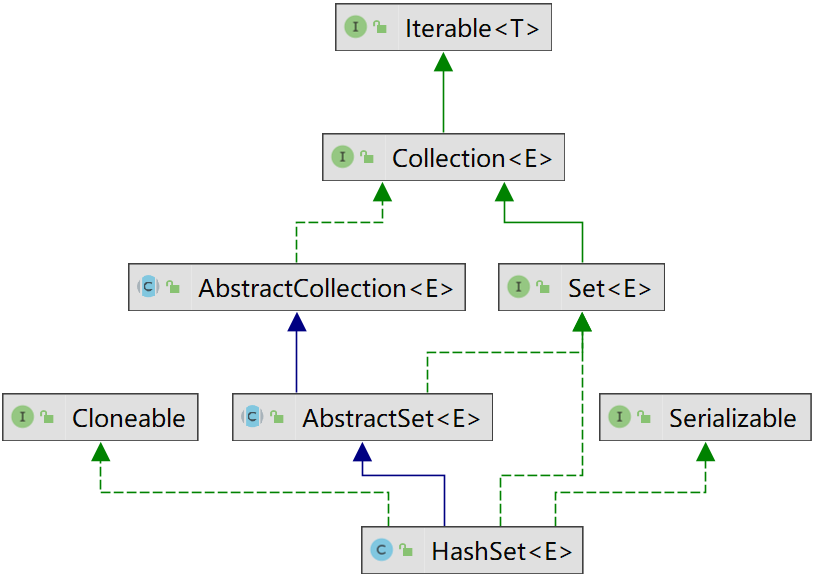
HashSet does not inherit HashMap, so HashSet uses HashMap by calling the method of HashMap. The advantages of this combination method without inheritance are as follows:
- Inheritance means that the parent and child classes are the same thing, while Set and Map are two things, so inheritance is inappropriate. Moreover, Java syntax restricts the child class to inherit only one parent class, which is difficult to expand later
- The combination is more flexible. The existing basic classes can be combined arbitrarily, and can be extended and arranged based on the basic class methods. Moreover, the method name can be named arbitrarily without being consistent with the method name of the basic class
2, Source code analysis
1. Member variables
//Combine HashMap. Key is the key of Hashset and value is the following PRESENT private transient HashMap<E,Object> map; //Virtual value in HashMap private static final Object PRESENT = new Object();
By observing the above source code, we can draw the following conclusions:
- When using HashSet, such as the add method, there is only one input parameter, but the add method of the combined Map has two input parameters: key and Value. The key of the Map is the input parameter of add, and Value is the second attribute PRESENT in the above code. The design here is very clever. A default Value PRESENT is used to replace the Value of the Map
- That is to say, all value s in this map are the same
- When multiple threads access the HashSet, there will be a thread safety problem, because there is no lock in all subsequent operations
2. Construction method
//The constructor of the underlying call HashMap
public HashSet() {
map = new HashMap<>();
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
/**
* If the initial capacity of a given parameter set is less than 16, it can be initialized according to the default 16 of HashMap
* If it is greater than 16, it will be initialized according to the specified value
* The specified value = parameter set capacity / 0.75 + 1, which can make the expected value exactly 1 larger than the capacity expansion threshold, so the capacity will not be expanded. It conforms to the HashMap capacity expansion formula, which can reduce the number of capacity expansion and improve efficiency
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
//In the future development process, if you want to copy the set in HashMap, the initialization size of HashMap can learn from this writing method
//It is not public and can only be called by the same package. This is the exclusive constructor of LinkedHashSet
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
//LinkedHashMap is created, not HashMap
}
3. Adding method
The source code of the add (E) method is as follows:
public boolean add(E e) {
//Directly call the put() method of HashMap, take the element itself as the key and PRESENT as the value
return map.put(e, PRESENT)==null;
}
4. Deletion method
The source code of the remove(Object o) method is as follows:
public boolean remove(Object o) {
//Directly call the remove() method of HashMap
return map.remove(o)==PRESENT;
}
Note that the remove method of Map returns the value of the deleted element, while the remove method of Set returns the boolean type. If it is null, it means that there is no element. If it is not null, it must be equal to PRESENT
5. Query method
The source code of the contains(Object o) method is as follows:
public boolean contains(Object o) {
//Call the containsKey() method of map
return map.containsKey(o);
}
6. Traversal method
The source code of iterator() method is as follows:
public Iterator<E> iterator() {
//Iterator calling keySet of map
return map.keySet().iterator();
}
3, Summary
(1) HashSet internally uses the key of HashMap to store elements, so as to ensure that elements are not repeated
(2) HashSet is unordered because the key of HashMap is unordered
(3) Elements with null values are allowed in HashSet because HashMap allows null key s
(4) HashSet is non thread safe
(5) HashSet has no get() method, and the query method is the contains() method