Chapter 3 HBase Shell operations
3.1 Basic Operations
1. Enter the HBase client command line
[lxl@hadoop102 hbase]$ bin/hbase shell
2. View Help Commands
hbase(main):001:0> help
3. See which tables are in the current database
hbase(main):001:0> list TABLE 0 row(s) in 0.2530 seconds => []
Operation of Table 3.2
1. Create tables
hbase(main):003:0> create 'student','info' 0 row(s) in 1.3670 seconds => Hbase::Table - student
2. Insert data into tables
hbase(main):003:0> put 'student','1001','info:sex','male' hbase(main):004:0> put 'student','1001','info:age','18' hbase(main):005:0> put 'student','1002','info:name','Janna' hbase(main):006:0> put 'student','1002','info:sex','female' hbase(main):007:0> put 'student','1002','info:age','20'
3. Scanning View Table Data
hbase(main):010:0> scan 'student' ROW COLUMN+CELL 1001 column=info:name, timestamp=1560293882038, value=xiannv 1001 column=info:sex, timestamp=1560293938473, value=female 1002 column=info:name, timestamp=1560293958558, value=xiantong 1002 column=info:sex, timestamp=1560293983958, value=male
hbase(main):014:0> scan 'student',{STARTROW=>'1001',STOPROW=>'1003'} ROW COLUMN+CELL 1001 column=info:name, timestamp=1560293882038, value=xiannv 1001 column=info:sex, timestamp=1560293938473, value=female 1002 column=info:name, timestamp=1560293958558, value=xiantong 1002 column=info:sex, timestamp=1560293983958, value=male
hbase(main):015:0> scan 'student',{STARTROW => '1001'} ROW COLUMN+CELL 1001 column=info:name, timestamp=1560293882038, value=xiannv 1001 column=info:sex, timestamp=1560293938473, value=female 1002 column=info:name, timestamp=1560293958558, value=xiantong 1002 column=info:sex, timestamp=1560293983958, value=male 1003 column=info:sex, timestamp=1560294341536, value=male
4. View table structure
hbase(main):016:0> describe 'student' Table student is ENABLED student COLUMN FAMILIES DESCRIPTION {NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCA CHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
5. Update data for specified fields
hbase(main):012:0> put 'student','1001','info:name','Nick' hbase(main):013:0> put 'student','1001','info:age','100'
6. View data for "Specified rows" or "Specified column families: columns"
hbase(main):011:0> get 'student','1001' COLUMN CELL info:name timestamp=1560293882038, value=xiannv info:sex timestamp=1560293938473, value=female
hbase(main):012:0> get 'student','1001','info:name' COLUMN CELL info:name timestamp=1560293882038, value=xiannv
7. Number of rows in statistical tables
hbase(main):021:0> count 'student'
8. Delete data
Delete all data of a rowkey:
hbase(main):016:0> deleteall 'student','1001'
Delete a column of data for a rowkey:
hbase(main):017:0> delete 'student','1002','info:sex'
9. Empty table data
hbase(main):018:0> truncate 'student'
Tip: The order of emptying the table is disable first, then truncate.
10. Delete tables
First, you need to make the table disable:
hbase(main):019:0> disable 'student'
Then drop the table:
hbase(main):020:0> drop 'student'
Tip: If you drop the table directly, you will report an error: ERROR: Table student is enabled. Disable it first.
11. Change Table Information
Store the data in the info column family in three versions:
hbase(main):022:0> alter 'student',{NAME=>'info',VERSIONS=>3} hbase(main):022:0> get 'student','1001',{COLUMN=>'info:name',VERSIONS=>3}
Operation:
hbase(main):018:0> alter 'student', {NAME=>'info',VERSIONS=>3} Updating all regions with the new schema... 1/1 regions updated. Done. 0 row(s) in 1.9710 seconds hbase(main):019:0> describe 'student' Table student is ENABLED student COLUMN FAMILIES DESCRIPTION {NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '3', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCA CHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'} 1 row(s) in 0.0150 seconds hbase(main):020:0> put 'student','1001','info:name','guangshen' 0 row(s) in 0.0080 seconds hbase(main):021:0> get 'student','1001','info:name' COLUMN CELL info:name timestamp=1560295375184, value=guangshen 1 row(s) in 0.0170 seconds hbase(main):022:0> get 'student','1001',{COLUMN=>'info:name',VERSIONS=>3} COLUMN CELL info:name timestamp=1560295375184, value=guangshen info:name timestamp=1560293882038, value=xiannv 1 row(s) in 0.0480 seconds hbase(main):023:0> put 'student','1001','info:name','chunlei' 0 row(s) in 0.0080 seconds hbase(main):024:0> get 'student','1001',{COLUMN=>'info:name',VERSIONS=>3} COLUMN CELL info:name timestamp=1560295467589, value=chunlei info:name timestamp=1560295375184, value=guangshen info:name timestamp=1560293882038, value=xiannv 1 row(s) in 0.0090 seconds hbase(main):025:0> put 'student','1001','info:name','wangjun' 0 row(s) in 0.0080 seconds hbase(main):026:0> get 'student','1001',{COLUMN=>'info:name',VERSIONS=>3} COLUMN CELL info:name timestamp=1560295506023, value=wangjun info:name timestamp=1560295467589, value=chunlei info:name timestamp=1560295375184, value=guangshen 1 row(s) in 0.0080 seconds
Chapter 4 HBase Data Structure
4.1 RowKey
Like nosql databases, RowKey is the primary key used to retrieve records. There are only three ways to access rows in HBASE table:
1. Access through a single RowKey
2. Through RowKey's range (regular)
3. Full table scanning
RowKey can be an arbitrary string (the maximum length is 64KB, the actual length is usually 10-100 bytes), within HBASE.
RowKey is saved as an array of bytes. When stored, data is stored in RowKey's byte order. When designing RowKey, you need to fully sort and store this feature by putting together rows that are often read together. (Location dependence)
4.2 Column Family
Column family: Each column in the HBASE table belongs to a column family. Column families are part of the schema of tables (columns are not), and must be defined before using tables. Names are prefixed by clans. For example, courses:history, courses:math belong to courses.
4.3 Cell
Units uniquely determined by {rowkey, column Family:columu, version}. There are no types of data in a cell, all of which are stored in bytecode form.
Keyword: Untyped, bytecode
4.4 Time Stamp
In HBASE, a storage unit determined by rowkey and columns is called cell. Each cell holds multiple versions of the same data. Versions are indexed by a timestamp. The type of timestamp is 64-bit integer. The timestamp can be assigned by HBASE (automatically when data is written), at which point the timestamp is the current system time accurate to milliseconds. Timestamps can also be explicitly assigned by customers. If an application wants to avoid data version conflicts, it must generate its own unique timestamp. In each cell, different versions of data are sorted in reverse chronological order, i.e. the latest data ranks first.
To avoid the burden of management (including storage and indexing) caused by too many versions of data, HBASE provides two ways of data version recovery. One is to save the last n versions of the data, and the other is to save the most recent versions (for example, the last seven days). Users can set it for each column family.
4.5 Namespaces
Namespace structure:
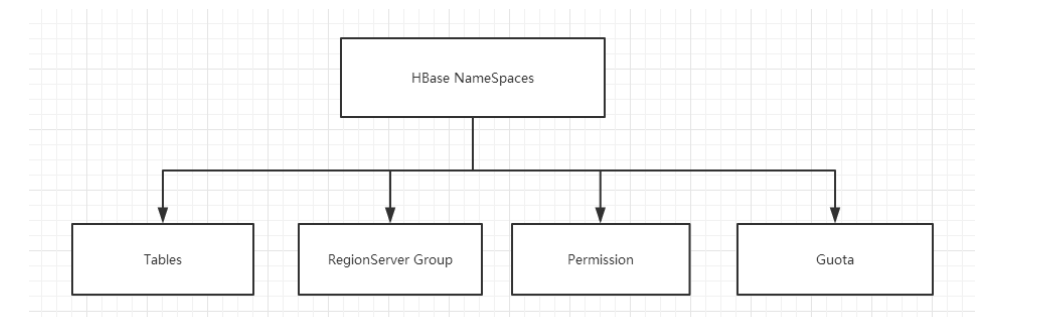
1) Table: Tables, all tables are members of the namespace, that is, tables must belong to a namespace, if not specified, in the default default namespace.
2) RegionServer group: A namespace contains the default RegionServer Group.
3) Permission: Permissions, namespaces allow us to define access control lists (ACL s). For example, create tables, read tables, delete, update and so on.
4) Quota: Quota: Limits that force the number of region s that a namespace can contain.
Chapter 5 Principles of HBase
5.1 Reading process
The process of HBase reading data is shown in Figure 3.
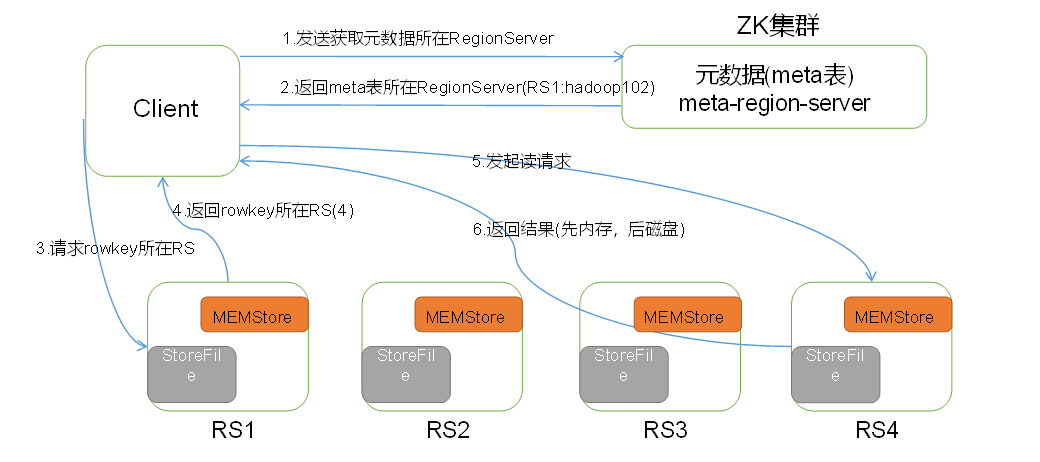
The HBase read data flow shown in Figure 3
1) Client first accesses zookeeper, reads the location of the region from the meta table, and then reads the data in the meta table. The region information of user table is stored in meta.
2) Find the corresponding region information in meta-table according to namespace, table name and rowkey.
3) Find the region server corresponding to this region;
4) Find the corresponding region;
5) Find data from MemStore first, and if not, read it in BlockCache.
6) BlockCache is not yet available, then read it on StoreFile (for efficiency of reading);
7) If the data is read from StoreFile, it is not directly returned to the client, but first written to BlockCache, and then returned to the client.
5.2 Writing process
The Hbase writing process is shown in Figure 2.
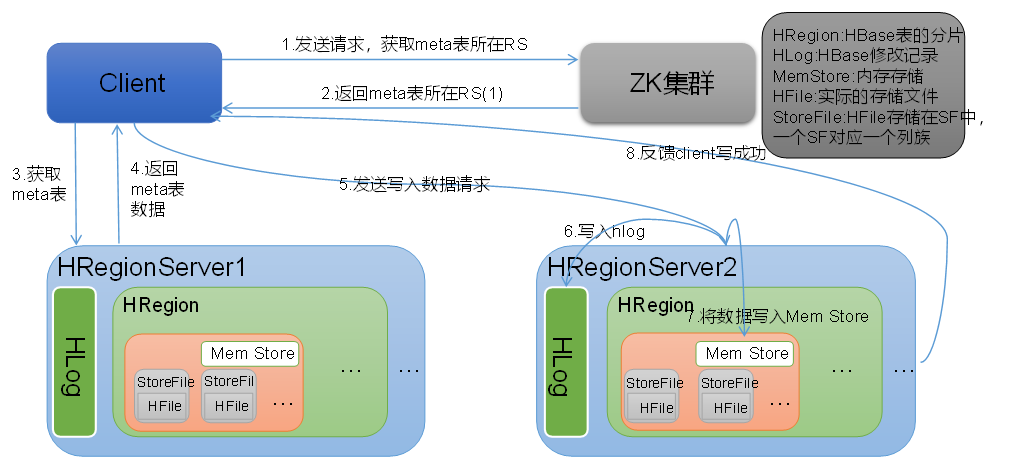
Figure 2. HBase Writing Data Flow
1) Client sends write request to Hregion Server;
2) Hregion Server writes data to HLog (write ahead log). For data persistence and recovery;
3) Hregion Server writes data to memory (MemStore);
4) Feedback Client to write successfully.
5.3 Data Flush Process
1) When the MemStore data reaches the threshold (default is 128M, the old version is 64M), the data is brushed to the hard disk, the data in memory is deleted, and the historical data in HLog is deleted.
2) Store data in HDFS;
3) Make marker points in HLog.
5.4 Data merging process
1) When the data block reaches 4 blocks, Hmaster triggers the merge operation, and Region loads the data block locally to merge.
2) When the merged data exceeds 256M, the split Region is allocated to different HregionServer management.
3) When the HregionServer goes down, the hlog on the HregionServer is split up and then assigned to different HregionServer loads to modify. META.
4) Note: HLog will synchronize to HDFS.