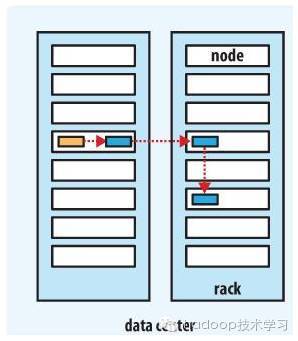
Rack awareness
Usually, large Hadoop clusters are distributed on many racks. In this case,
- It is hoped that the communication between different nodes can occur within the same rack rather than across racks.
- In order to improve fault tolerance, the name node will place copies of data blocks on multiple racks as much as possible.
Considering these two points, Hadoop designs the rack sensing function
External scripts for rack awareness
HDFS cannot automatically judge the network topology of each DataNode in the cluster. This rack awareness requires an executable file (or script) defined by the net.topology.script.file.name attribute. The file provides the mapping relationship between the IP address of the DataNode and the rack rackid. Through this mapping relationship, NameNode obtains the rack rackids of each DataNode machine in the cluster. If topology.script.file.name is not set, the IP address of each DataNode will be mapped to default rack by default, that is, the same rack.
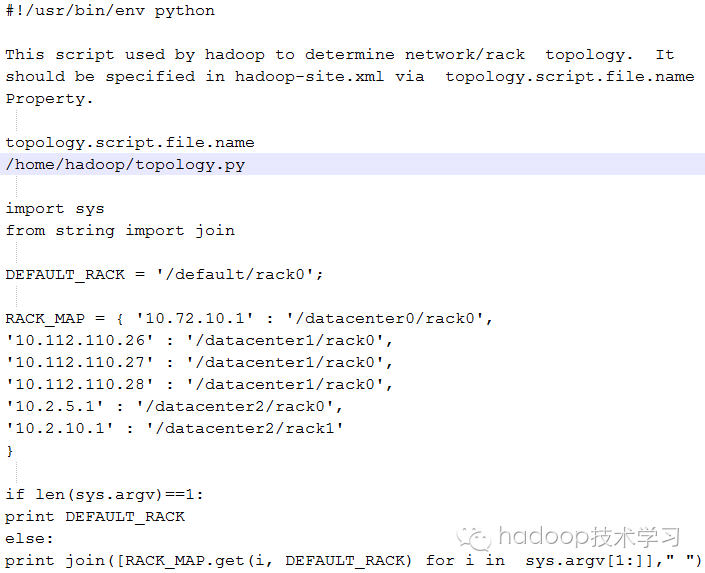
In order to obtain the rack rack rack ID, you can write a small script to define the IP address (or DNS domain name) of the DataNode, and print the desired rack rack rack ID to the standard output stdout
The script must be specified in the configuration file hadoop-site.xml through the attribute 'net.topology.script.file.name'.
<property>
<name>net.topology.script.file.name</name>
<value>/root/apps/hadoop-3.2.1/topology.py</value>
</property>
Examples of scripts written in Python language:
The internal Java class implements rack awareness
Here, the configuration topology.node.switch.mapping.impl is used to realize rack awareness. The following configuration items need to be added to the core-site.xml configuration file:
<property> <name>topology.node.switch.mapping.impl</name> <value>com.dmp.hadoop.cluster.topology.JavaTestBasedMapping</value> </property>
You also need to write a JAVA class. An example is as follows:
public class JavaTestBasedMapping implements DNSToSwitchMapping {
//key:ip value:rack
private staticConcurrentHashMap<String,String> cache = new ConcurrentHashMap<String,String>();
static {
//rack0 16
cache.put("192.168.5.116","/ht_dc/rack0");
cache.put("192.168.5.117","/ht_dc/rack0");
cache.put("192.168.5.118","/ht_dc/rack0");
cache.put("192.168.5.120","/ht_dc/rack0");
cache.put("192.168.5.121","/ht_dc/rack0");
cache.put("host116","/ht_dc/rack0");
cache.put("host117","/ht_dc/rack0");
cache.put("host118","/ht_dc/rack0");
cache.put("host120","/ht_dc/rack0");
cache.put("host121","/ht_dc/rack0");
}
@Override
publicList<String> resolve(List<String> names) {
List<String>m = new ArrayList<String>();
if (names ==null || names.size() == 0) {
m.add("/default-rack");
return m;
}
for (Stringname : names) {
Stringrack = cache.get(name);
if (rack!= null) {
m.add(rack);
}
}
return m;
}
}
Print the above Java classes into jar packages and add execution permissions; Then put it in $Hadoop_ Run in the home / lib directory.
Network topology
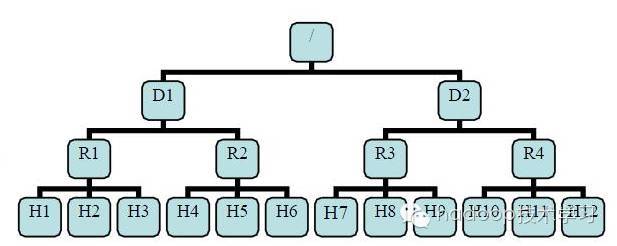
With rack awareness, NameNode can draw the DataNode network topology diagram shown in the above figure. D1 and R1 are switches, and the bottom layer is DataNode. Then the rackid of H1 = / D1 / R1 / H1, the parent of H1 is R1, and the parent of R1 is D1. These rack rackid information can be configured through net.topology.script.file.name. With these rack rackid information, you can calculate the distance between any two datanodes.
distance(/D1/R1/H1,/D1/R1/H1)=0 same datanode distance(/D1/R1/H1,/D1/R1/H2)=2 same rack Different under datanode distance(/D1/R1/H1,/D1/R1/H4)=4 same IDC Different under datanode distance(/D1/R1/H1,/D2/R3/H7)=6 Different IDC Lower datanode
Replica placement policy (BPP:blockplacement policy)
- The first block copy is placed in the node where the client is located (if the client is not in the cluster, the first node is randomly selected. Of course, the system will try not to select nodes that are too full or too busy).
- The second replica is placed in a node in a rack different from the first node (randomly selected).
- The third copy and the second copy are in the same rack and randomly placed in different node s.
If there are more copies, they will be placed randomly subject to the following restrictions.
- One node can place up to one copy
- If the number of replicas is less than 2 times the number of racks, you cannot place more than 2 replicas in the same rack
When data reading occurs, the NameNode node first checks whether the client is located in the cluster. If so, you can determine which DataNode node sends the data blocks it needs to the client according to the near to far priority. In other words, for nodes with the same data block copy, the nodes close to the client in the network topology will respond first.
Hadoop's replica placement strategy makes a good balance between reliability (block s in different racks) and bandwidth (a pipeline only needs to cross one network node).
The following figure shows the distribution of three datanodes of a pipeline when the number of replicas is 3