Lesson 69 search algorithm
1. Static search and dynamic search
Static lookup:
The data set is stable, and there is no need to add or delete elements.
Dynamic lookup:
In the process of finding data sets, you need to add or delete elements at the same time.
2. Search structure
For static lookups:
We might as well organize the data with linear table structure, so we can use sequential search algorithm.
If we sort the keywords again, we can use half search algorithm or Fibonacci search algorithm to improve the efficiency of search.
For dynamic lookup:
We can consider using the search technology of binary sort tree. In addition, we can also use hash structure to solve some search problems.
These technologies will be introduced to you in this part of the tutorial.
3. Sequential search
Sequential search, also known as linear search, is the most basic search technology. Its search process is:
Starting from the first (or last) record, compare the keyword of the record with the given value one by one. If the keyword of a record is equal to the given value, the search is successful.
If all records are searched and no keyword equal to the given value is found, the search is unsuccessful.
Sequential search algorithm code:
// Sequential search optimization scheme: a is the array to be searched, n is the length of the array to be searched, and key is the keyword to be searched
int Sq_Search(int *a, int n, int key)
{
int i = n;
a[0] = key
while( a[i] != key )
{
i--;
}
return i;
}
Optimization code:
// Sequential search: a is the array to be searched, n is the length of the array to be searched, and key is the keyword to be searched
int Sq_Search(int *a, int n, int key)
{
int i;
for( i=1; i <= n; i++ )
{
if( a[i] == key )
{
return i;
}
}
return 0;
}
Homework after class
Suppose that one of the following structures stores student records, and each record includes:
Student number, name and grade.
 Please write a program to output 0002 number and the specific information of Kang xiaopao.
Please write a program to output 0002 number and the specific information of Kang xiaopao.
code:
#include <stdio.h>
typedef struct student
{
int id;
char name[10];
float score;
}Student;
float search(Student stu[], int n, int key)
{
int i;
for( i=0; i < n; i++ )
{
if( stu[i].id == key )
{
return i.score;
}
}
return -1;
}
int main()
{
Student stu[4] = {
{0000, "Small turtle", 100},
{0001, "Wind medium", 99},
{0002, "Kang xiaopao", 101},
{0003, "No two", 33}
};
float score;
score = search(stu, 4, 0002);
printf("0002 The achievements of sister Kang xiaopao are:%f", score);
return 0;
}
Lesson 70 interpolation search | [search by proportion]
1. Interpolation search (search by scale)
If you forget the fish oil and "find it in half", please review it first:

Half search, also known as binary search, is an efficient search algorithm.
Interpolation search evolved from binary search.
Compared with binary search (halving), the algorithm considers how much to fold each time, that is, it is not necessarily 1 / 2;
For example, find the word "fishc" in a dictionary.
When we operate by ourselves, we must first turn to the small part at the beginning of the dictionary, rather than half searching from the middle of the dictionary.
In binary search, mid = (low + high) / 2 = Low + 1 / 2 * (high low).
Interpolation search is to 1 / 2, which is actually to calculate the linear scale.
(coefficient, or ratio), which changes 1 / 2 to (key - array[low])/(array[high] - array[low])
Because interpolation search depends on linear proportion, if the current array distribution is not uniform, then the algorithm is not suitable.
Code implementation:
#include <stdio.h>
int bin_search( int str[], int n, int key )
{
int low, high, mid;
low = 0;
high = n-1;
while( low <= high )
{
mid = low + (key-a[low]/a[high]-a[low])*(high-low); // The only difference between interpolation and lookup
if( str[mid] == key )
{
return mid;
}
if( str[mid] < key )
{
low = mid + 1;
}
if( str[mid] > key )
{
high = mid - 1;
}
}
return -1;
}
int main()
{
int str[11] = {1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89};
int n, addr;
printf("Please enter the keyword to be found: ");
scanf("%d", &n);
addr = bin_search(str, 11, n);
if( -1 != addr )
{
printf("Find success, Congratulations, Coca Cola! keyword %d The location is: %d\n", n, addr);
}
else
{
printf("Search failed!\n");
}
return 0;
}
Lesson 71 Fibonacci search [golden section search]
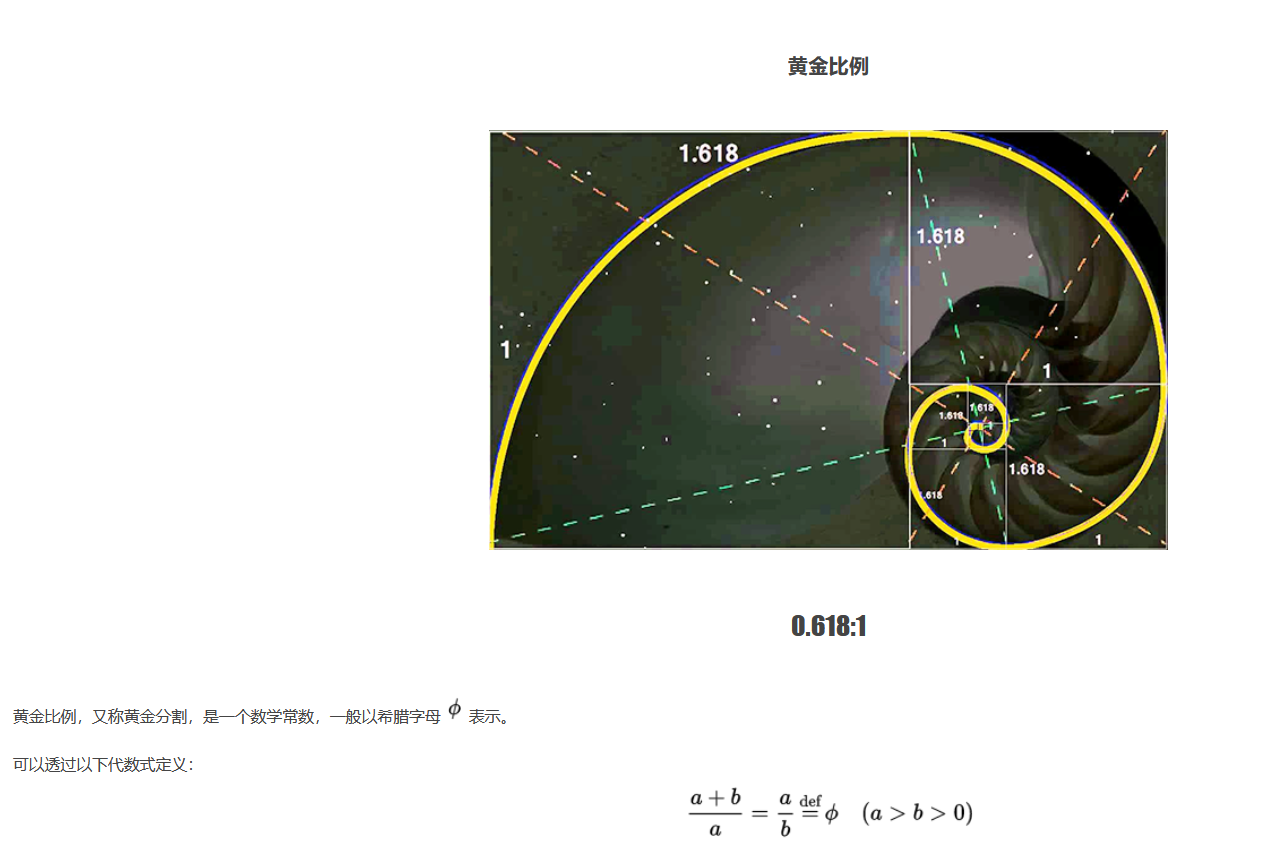
1. Gold ratio
2. Fibonacci search
Fibonacci sequence (the sum of the first two terms is equal to the third term, starting from 1,1. F[k]):
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89......
With the increase of the number series, the ratio of the two numbers is closer and closer to the gold ratio of 0.618.
For example, think of 89 here as the number of elements in the whole ordered table, and 89 is the sum of the first two Fibonacci numbers 34 and 55.
in other words:
The ordered table with 89 elements is divided into the first half composed of the first 55 data elements and the second half composed of the last 34 data elements.
Then the ratio of the number of elements in the first half to the length of the whole ordered table is close to the gold ratio of 0.618.
If the element to be searched is in the first half, continue to look at it according to the Fibonacci sequence:
55 = 34 + 21
Therefore, continue to divide the first half into the first half of the first 34 data elements and the second half of the last 21 elements.
Continue to search and repeat until the search succeeds or fails. In this way, the Fibonacci sequence is applied to the search algorithm.
As shown below:
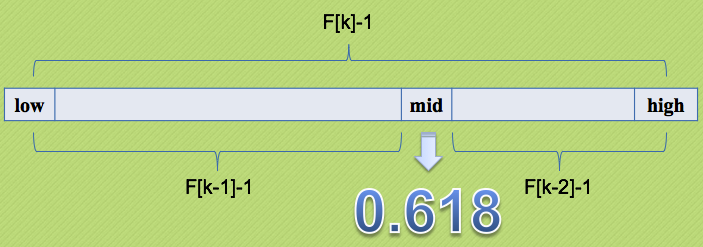
It can be seen from the figure that when the number of elements in the ordered table is not a number in the Fibonacci sequence, the length of the number of elements in the ordered table needs to be supplemented.
Let it become a value in Fibonacci sequence. Of course, it is impossible to truncate the original sequence table. Otherwise, how can we find it.
Then, the figure indicates that - 1 operation will be performed every time a value in Fibonacci sequence is taken (F[k]).
This is because the bit order of the ordered table array starts from 0, which is purely to cater to the bit order starting from 0.
Algorithm implementation:
#include <stdio.h>
#define MAXSIZE 20
void fibonacci(int *f)
{
int i;
f[0] = 1;
f[1] = 1;
for(i=2; i < MAXSIZE; ++i)
{
f[i] = f[i-2] + f[i-1];
}
}
int fibonacci_search(int *a,int key,int n)
{
int low = 0;
int high = n - 1;
int mid = 0;
int k = 0;
int F[MAXSIZE];
int i;
fibonacci(F);
while( n > F[k]-1 )
{
++k;
}
for( i=n; i < F[k]-1; ++i)
{
a[i] = a[high];
}
while( low <= high )
{
mid = low + F[k-1] - 1;
if( a[mid] > key )
{
high = mid - 1;
k = k - 1;
}
else if( a[mid] < key )
{
low = mid + 1;
k = k - 2;
}
else
{
if( mid <= high )
{
return mid;
}
else
{
return high;
}
}
}
return -1;
}
int main()
{
int a[MAXSIZE] = {1, 5, 15, 22, 25, 31, 39, 42, 47, 49, 59, 68, 88};
int key;
int pos;
printf("Please enter the number you want to find:");
scanf("%d", &key);
pos = fibonacci_search(a, key, 13);
if( pos != -1 )
{
printf("\n Find success, Congratulations, Coca Cola! keyword %d The location is: %d\n\n", key, pos);
}
else
{
printf("\nO~No~~Small work is weak, and the element is not found in the array:%d\n\n", key);
}
return 0;
}
Lesson 72 linear index search | [dense, block, inverted]
1. Dense index
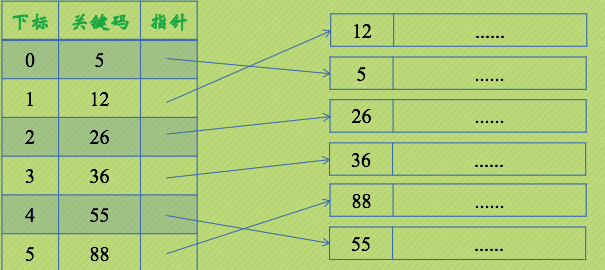
If the records are ordered, we can build a dense index on the records. It is a series of storage blocks:
Only the key of the record and the pointer to the record itself are stored in the block. The pointer is an address pointing to the record or storage block.
The index blocks in the dense index file keep the order of keys consistent with the sort order in the file.
Since we assume that the storage space occupied by the search key and pointer is much smaller than the record itself, we can think that the storage blocks required to store the index file are much less than those required to store the data file.
When the memory can not hold data files, but can hold index files, the advantage of index is particularly obvious.
At this time, by using the index file, we only use one query at a time I/O Operation can find the record of the given key value.
2. Block index
Block search:
Block search, also known as index sequential search, is an improved method of sequential search.
Method description:
take n Data elements are divided into "ordered by block" m Block( m<=n). The data elements in each block need not be ordered, but the blocks must be "ordered by block", that is, the keyword of any element in the first block must be less than that of any element in the second block;
And any element in block 2 is smaller than any element in block 3
The block diagram is as follows:
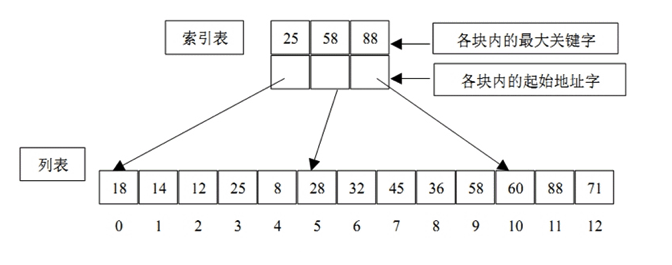 Operation steps:
Operation steps:
1,First, select the largest keyword in each cache to form an index table
2,The search is divided into two parts:
First, binary search or sequential search is carried out on the index table to determine which block the records to be checked are in;
Then, the sequence method is used to search in the determined fast.
Average search length of block search:
Set the length to n The table is divided evenly b Blocks, each containing s Records, then:
b=n/s
Find the block in sequence. The average search length of block search is:
(b+1)/2 + (s+1)/2 = (n/s+s)/2+1
The average search length of the block where the half search is located is:
log2(n/s+1)+s/2
3. Inverted index
Inverted index is an index method, which is used to store the mapping of the storage location of a word in a document or a group of documents under full-text search.
It is the most commonly used data structure in document retrieval system.
There are two different forms of reverse indexing:
The horizontal reverse index (or reverse archive index) of a record contains a list of documents for each referenced word.
The horizontal reverse index (or full reverse index) of a word contains the position of each word in a document.
The latter form provides more compatibility (such as phrase search), but requires more time and space to create.
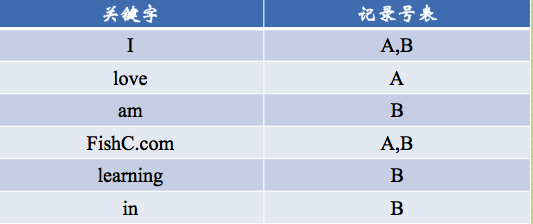
Now there are two arrays: A and B
A:
I love FishC.com
B:
I am learning in FishC.com
Lesson 73 binary sort tree [understanding]
1. Binary sort tree
Binary sort tree is also called "binary search tree" and "binary search tree".
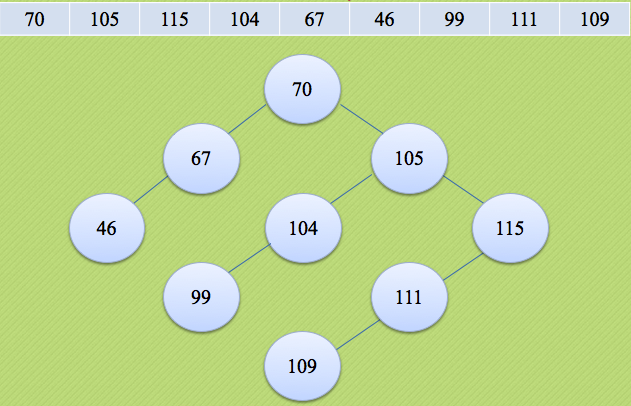
Binary sort tree has the following properties:
1. If its left subtree is not empty, the values of all nodes on the left subtree are less than the values of its root node; 2. If its right subtree is not empty, the value of all nodes on the right subtree is greater than that of its root node; 3. Its left and right subtrees are also binary sort trees.
Binary sort tree usually uses binary linked list as storage structure.
Traversing the binary sort tree in middle order can get an ordered sequence according to keywords. An unordered sequence can be transformed into an ordered sequence by constructing a binary sort tree.
The process of constructing a tree is the process of sorting unordered sequences.
Each new node inserted is a new leaf node on the binary sort tree.
During the insertion operation, there is no need to move other nodes, just change the pointer of a node from null to non null.
Lesson 74 binary sort tree [find, insert]

The above is a binary sort tree with the following properties:
1,That is, if its left subtree is not empty, the values of all nodes on the left subtree are less than the values of its root node;
2,If its right subtree is not empty, the values of all nodes on the right subtree are greater than those of its root node.
3,The key value of any node must be greater than that of each node in its left subtree and less than that of each node in its right subtree.
1. Binary sort tree search
It is very simple to find the largest and smallest elements in the binary tree.
Go from the root node to the left until there is no way to go to get the minimum value;
Go right from the root node until there is no way to go, and you can get the maximum value.
code:
// Definition of binary linked list node structure of binary tree
typedef struct BiTNode
{
int data;
struct BiTNode *lchild, *rchild;
}BiTNode, *BiTree;
// Recursively find out whether there is a key in the binary sort tree T
// Pointer f points to the parent of T, whose initial value is NULL
// If the search is successful, the pointer p points to the data element node and returns TRUE
// Otherwise, the pointer p points to the last node accessed on the lookup path and returns FALSE
Status SearchBST(BiTree T, int key, BiTree f, BiTree *p)
{
if( !T ) // The search was unsuccessful
{
*p = f;
return FALSE;
}
else if( key == T->data ) // Search succeeded
{
*p = T;
return TRUE;
}
else if( key < T->data )
{
return SearchBST( T->lchild, key, T, p ); // Continue searching in the left subtree
}
else
{
return SearchBST( T->rchild, key, T, p ); // Continue searching in the right subtree
}
}
2. Binary sort tree insertion
When inserting a new element, you can start from the root node and turn left in case of a larger key value.
If the key value is small, it will go to the right until the end, which is the insertion point.
code:
// When there is no data element with keyword equal to key in binary sort tree T,
// Insert the key and return TRUE, otherwise return FALSE
Status InsertBST(BiTree *T, int key)
{
BiTree p, s;
if( !SearchBST(*T, key, NULL, &p) )
{
s = (BiTree)malloc(sizeof(BiTNode));
s->data = key;
s->lchild = s->rchild = NULL;
if( !p )
{
*T = s; // Insert s as the new root node
}
else if( key < p->data )
{
p->lchild = s; // Insert s as left child
}
else
{
p->rchild = s; // Insert s as right child
}
return TRUE;
}
else
{
return FALSE; // A node with the same keyword already exists in the tree and will not be inserted
}
}
Lesson 75 binary sort tree | [delete]
1. Delete binary sort tree
For a general binary tree, deleting a node in the tree is meaningless because:
It will turn the subtree with the deleted node as the root into a forest and destroy the structure of the whole tree
However, for a binary sort tree, deleting a node on the tree is equivalent to deleting a record in an ordered sequence.
As long as the characteristics of binary sort tree are not changed after deleting a node.
The algorithm for deleting a node in the binary sort tree is as follows:
btree * DeleteBST(btree *b, ElemType x)
{
if (b)
{
if (b->data == x)
b = DelNode(b);
else if (b->data > x)
b->lchild = DeleteBST(b->lchild, x);
else
b->rchild = DeleteBST(b->rchild, x);
}
return b;
}
2. Deletion process
There are two ways to delete the process.
The first process is as follows:
1,if p If there is a left subtree, find the rightmost leaf node of its left subtree r,Use this leaf node r To replace p,hold r Left child as r My father's right child.
2,if p No left subtree, use directly p The right child replaces it.
code:
btree * DelNode(btree *p)
{
if (p->lchild)
{
btree *r = p->lchild; //r points to its left subtree;
while(r->rchild != NULL)//Search the rightmost leaf node r of the left subtree
{
r = r->rchild;
}
r->rchild = p->rchild;
btree *q = p->lchild; //q points to its left subtree;
free(p);
return q;
}
else
{
btree *q = p->rchild; //q points to its right subtree;
free(p);
return q;
}
}
The second process is as follows:
1,if p There is a left subtree, with p The left child replaces it; Find the rightmost leaf node of its left subtree r,hold p Right subtree as r Right subtree of.
2,if p No left subtree, use directly p The right child replaces it.
code:
btree * DelNode(btree *p)
{
if (p->lchild)
{
btree *r = p->lchild; //r points to its left subtree;
btree *prer = p->lchild; //prer points to its left subtree;
while(r->rchild != NULL)//Search the rightmost leaf node r of the left subtree
{
prer = r;
r = r->rchild;
}
if(prer != r)//If r is not p's left child, take r's left child as r's father's right child
{
prer->rchild = r->lchild;
r->lchild = p->lchild; //The left subtree of the deleted node p is the left subtree of r
}
r->rchild = p->rchild; //The right subtree of the deleted node p is the right subtree of r
free(p);
return r;
}
else
{
btree *q = p->rchild; //q points to its right subtree;
free(p);
return q;
}
}
comment:
The two methods have their own advantages and disadvantages. The first one is a little simpler, but the balance is not as good as the second one, because it will be the node p All the right subtrees have moved to the left.
But the first way is to r Moving around is easy to make mistakes. In fact, what we delete here is p Instead of its address, there is no need to move the pointer at all.
3. Algorithm implementation
Observe carefully:
We found that the address we deleted is actually p The rightmost leaf node of the left subtree of r Your address.
So we just fill the data of r into p and delete r.
The algorithm is as follows:
btree * DelNode(btree *p)
{
if (p->lchild)
{
btree *r = p->lchild; //r points to its left subtree;
btree *prer = p->lchild; //prer points to its left subtree;
while(r->rchild != NULL)//Search the rightmost leaf node r of the left subtree
{
prer = r;
r = r->rchild;
}
p->data = r->data;
if(prer != r)//If r is not p's left child, take r's left child as r's father's right child
prer->rchild = r->lchild;
else
p->lchild = r->lchild; //Otherwise, the left subtree of node p points to the left subtree of r
free(r);
return p;
}
else
{
btree *q = p->rchild; //q points to its right subtree;
free(p);
return q;
}
}
Lesson 76 balanced binary tree [AVL]
1. Balanced binary sort tree
The binary search tree is not a strict O(logN), which makes it useless in the real scene, and no one wants O(N) to happen,
When a lot of data is poured into my tree, I will certainly hope that it is best displayed in the form of "complete binary tree".
In this way, I can achieve that the "search" is strictly O(logN). For example, adjust this "tree" to the following structure:
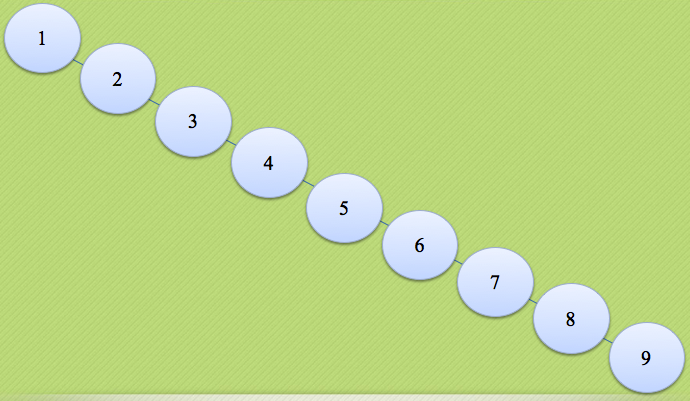
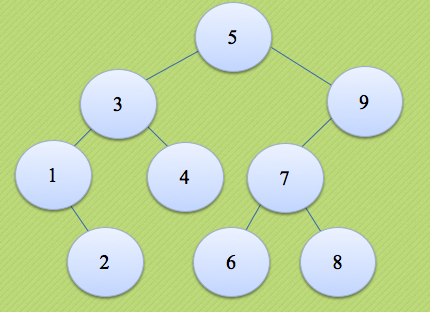
This involves the rotation of "tree nodes" and the focus of this lecture.
definition:
The height difference between the left subtree and the right subtree of the parent node cannot be greater than 1, that is, it cannot be higher than 1 layer, otherwise the tree will be unbalanced. At this time, rotate the node and When coding, we can record the height of the current node. For example, the empty node is-1,Leaf node is 0, non leaf node height Increment to root node
For example, in the following figure, we think the height of the tree is h=2:
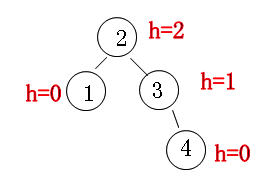
Four rotation conditions
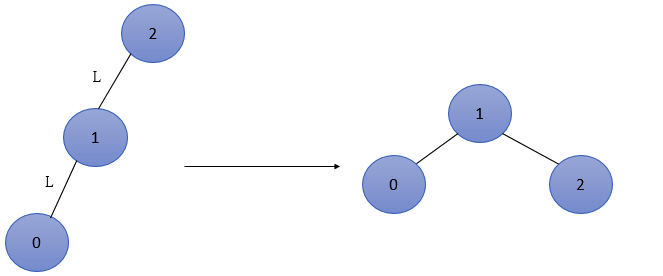
① Left case (left node of left subtree):
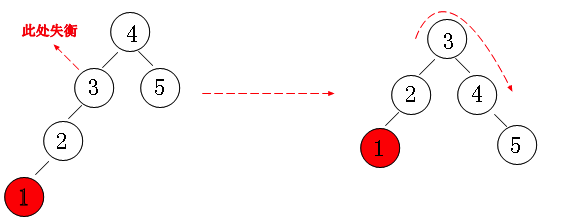
We can see that when adding "node 1" to the tree, according to the definition, we know that this will lead to the imbalance of "node 3".
To meet the "left left situation", we can think like this. Compare this tree to a gear. We pull the gear down one position at "node 5".
It has become the form of "balance" in the back. If you use animation to explain it, you'd better understand it.
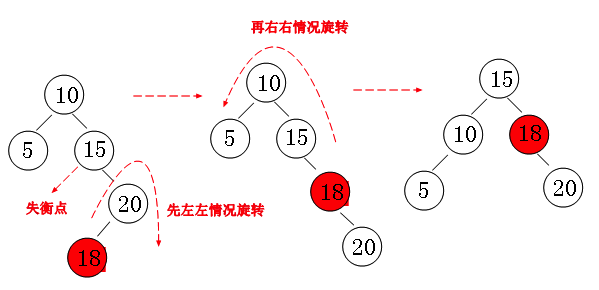
② Right case (right node of right subtree):
 Similarly, "node 5" satisfies the "right case". In fact, we also see that these two cases are a kind of mirror image.
Similarly, "node 5" satisfies the "right case". In fact, we also see that these two cases are a kind of mirror image.
Of course, the operation mode is also similar. We pull the tree down one place at "node 1", and finally form the balance effect we want.
③ Left and right (right node of left subtree):
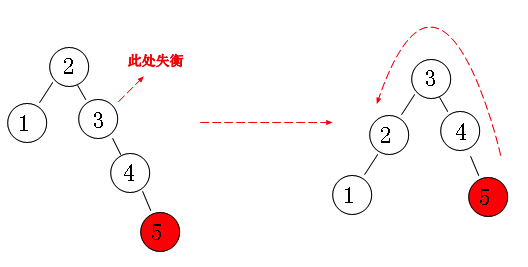
From the figure, we can see that when we insert "node 3", there is an imbalance at "node 5".
Note that it is very important to find the "imbalance point".
When facing the "left-right situation", we rotate the left subtree of the imbalance point to the "right situation".
Then carry out "left rotation", and after such two rotations, it is OK.
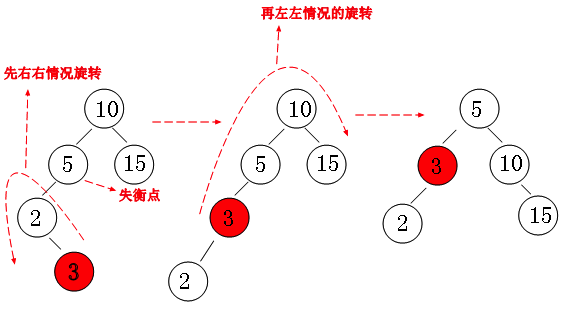
④ Right left case (left node of right subtree):
This situation is also a mirror relationship with "scenario 3", which is very simple.
We found that "node 15" is the imbalance point, and then we rotate the right subtree of "node 15" in the "left left case",
Then "right rotation" is carried out, and finally we get a satisfactory balance.
Lesson 77 implementation principle of balanced binary tree
1. Implementation principle of balanced binary tree
Core:
The basic idea of building a balanced binary tree is to insert a node every time in the process of building a binary sort tree. Immediately check whether the balance of the tree is damaged due to the insertion of this node. If so, immediately find the minimum unbalanced subtree. Then it is adjusted through certain laws to make it a new balanced subtree.
What is the adjustment?
namely:
rotate
2. Examples
Select the following 10 data to construct a balanced binary tree:
2,1,0,3,4,5,6,9,8,7
In the following:
L Represents the left node, R Represents the right node.
1. First, the node with data of 2 is inserted as the root node, and then 1 is inserted, which is still balanced.
When 0 is inserted again, the balance factor of 2 becomes 2. At this time, there is an imbalance, so it needs to be adjusted.
The lowest unbalanced node is 2, which belongs to LL type. According to the content of the above website, the adjustment process is as follows:
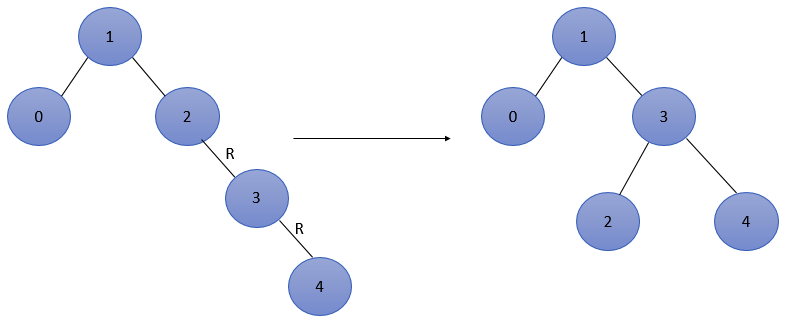
2. Then insert 3, which is balanced, and then insert 4. At this time, there is imbalance.
The balance factors of nodes 1 and 2 are - 2, and node 2 is the lowest unbalanced node, which belongs to RR type. The adjustment process is as follows:
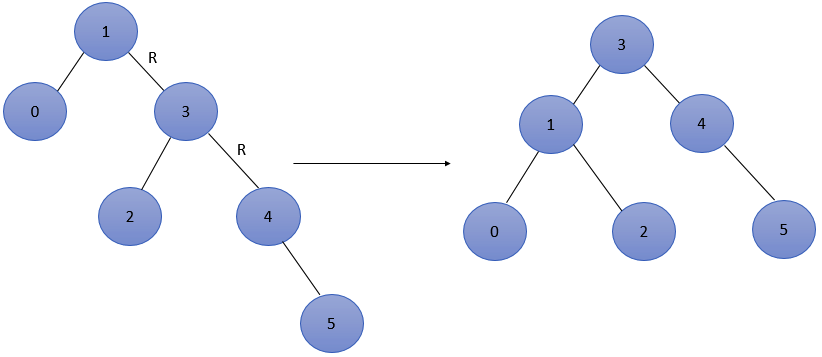
3. Then insert 5. At this time, the balance factor of node 1 is - 2, resulting in imbalance.
The RR adjustment node is the lowest, and the RR adjustment node is as follows:
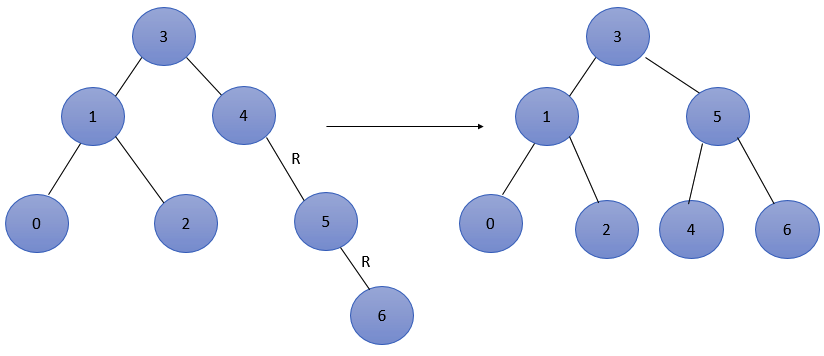
4. Then insert 6. At this time, the balance factor of node 4 is - 2, resulting in imbalance.
Node 4 is the lowest unbalanced node and belongs to RR type. The adjustment is as follows:
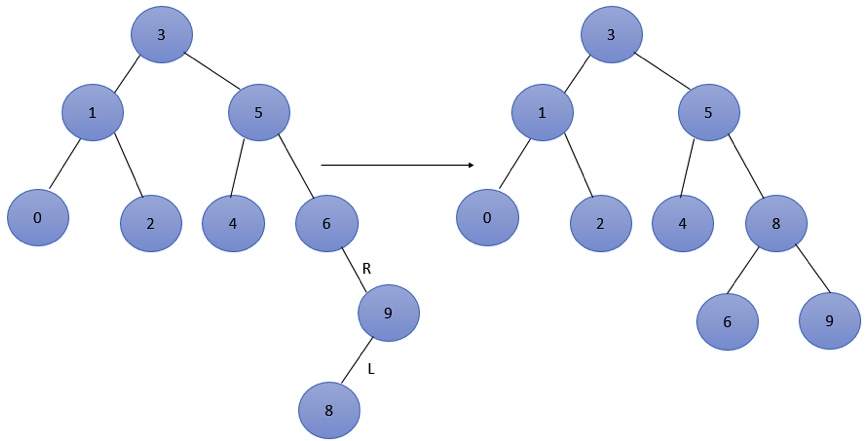
5. Then insert 9, which is balanced, and then insert 8. At this time, the balance factors of nodes 3, 5 and 6 are - 2, resulting in imbalance.
Node 6 is the lowest unbalanced node and belongs to RL type. The adjustment is as follows:
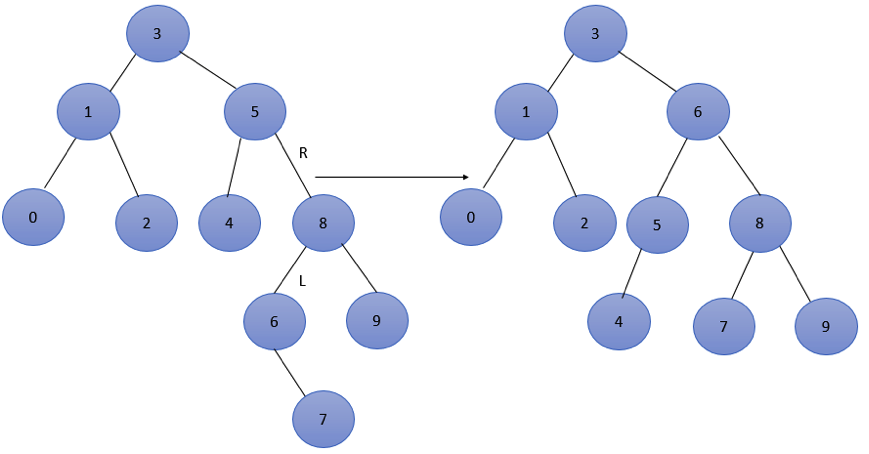
6. Insert 7. At this time, the balance factor of nodes 3 and 5 is - 2, resulting in imbalance.
The minimum unbalance node is 5, which belongs to RL type, and the adjustment is as follows:
Lecture 78 implementation principle of balanced binary tree | [code implementation]
1. Code implementation:
#define LH 1
#define EH 0
#define RH -1
typedef struct BiTNode
{
int data;
int bf;
struct BiTNode *lchild, *rchild;
} BiTNode, *BiTree;
void R_Rotate(BiTree *p)
{
BiTree L;
L = (*p)->lchild;
(*p)->lchild = L->rchild;
L->rchild = (*p);
*p = L;
}
void LeftBalance(BiTree *T)
{
BiTree L, Lr;
L = (*T)->lchild;
switch(L->bf)
{
case LH:
(*T)->bf = L->bf = EH;
R_Rotate(T);
break;
case RH:
Lr = L->rchild;
switch(Lr->bf)
{
case LH:
(*T)->bf = RH;
L->bf = EH;
break
case EH:
(*T)->bf = L->bf = EH;
break;
case RH:
(*T)->bf = EH;
L->bf = LH;
break;
}
Lr->bf = EH;
L_Rotate(&(*T)->lchild);
R_Rotate(T);
}
}
int InsertAVL(BiTree *T, int e, int *taller)
{
if( !*T )
{
*T = (BiTree)malloc(sizeof(BiTNode));
(*T)->data = e;
(*T)->lchild = (*T)->rchild = NULL;
(*T)->bf = EH;
*taller = TRUE;
}
else
{
if(e == (*T)->data)
{
*taller = FALSE;
return FALSE;
}
if(e < (*T)->data)
{
if(!InsertAVL(&(*T)->lchild, e, taller))
{
return FALSE;
}
if(*taller)
{
switch((*T)->bf)
{
case LH:
LeftBalance(T);
*taller = FALSE;
break;
case EH:
(*T)->bf = LH;
*taller = TRUE;
break;
case RH:
(*T)->bf = EH;
*taller = FALSE;
break;
}
}
}
else
{
if(!InsertAVL(&(*T)->rchild, e, taller))
{
return FALSE;
}
if(*taller)
{
switch((*T)->bf)
{
case LH:
(*T)->bf = EH;
*taller = FALSE;
break;
case EH:
(*T)->bf = RH;
*taller = TRUE;
break;
case RH:
RightBalance(T);
*taller = FALSE;
break;
}
}
}
}
}