Article source| Hengyuan cloud community
Original address| Dataset practice
Original author | Mathor
To tell you the truth, Xiaobian, I admire Mathor, the big man in the platform community! No, today I'll share with you the notes of the big man's paper. Let's see if the next content has the knowledge you need!
Start of text:
If you don't know ResNet, you can read my blog first ResNet paper reading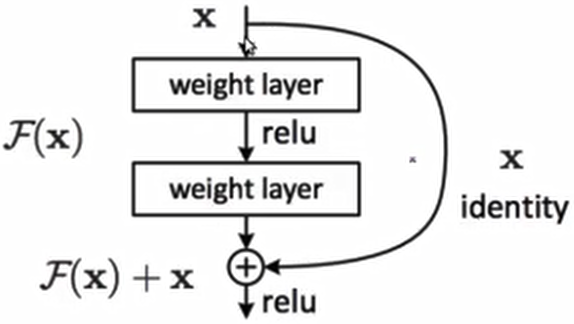
First, implement a Residual Block
import torch
from torch import nn
from torch.nn import functional as F
class ResBlk(nn.Module):
def __init__(self, ch_in, ch_out, stride=1):
super(ResBlk, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
if ch_out == ch_in:
self.extra = nn.Sequential()
else:
self.extra = nn.Sequential(
# one × The convolution function of 1 is to modify the channel of input x
# [b, ch_in, h, w] => [b, ch_out, h, w]
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out),
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# short cut
out = self.extra(x) + out
out = F.relu(out)
return outBlock is regularized to make the train process faster and more stable. At the same time, if the ch of two elements_ In and Ch_ If out does not match, an error will be reported when adding, so you need to judge. If you don't want to wait, use 1 × Adjust the convolution of 1
Test it
blk = ResBlk(64, 128, stride=2) tmp = torch.randn(2, 64, 32, 32) out = blk(tmp) print(out.shape)
The output shape size is torch.Size([2, 128, 16, 16])
Here's an explanation of why some layers need to set stripe specifically. Regardless of other layers, for a Residual block, the channel increases from 64 to 128. If all stripes are 1 and padding is 1, the w and h of the picture will not change, but the channel increases, which will increase the parameters of the whole network. This is only one Block, not to mention the following FC and more blocks, so the stripe cannot be set to 1. Do not increase the network parameters all the time
Then we built the complete ResNet-18
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(64),
)
# followed 4 blocks
# [b, 64, h, w] => [b, 128, h, w]
self.blk1 = ResBlk(64, 128, stride=2)
# [b, 128, h, w] => [b, 256, h, w]
self.blk2 = ResBlk(128, 256, stride=2)
# [b, 256, h, w] => [b, 512, h, w]
self.blk3 = ResBlk(256, 512, stride=2)
# [b, 512, h, w] => [b, 512, h, w]
self.blk4 = ResBlk(512, 512, stride=2)
self.outlayer = nn.Linear(512*1*1, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
# After four Blks, [b, 64, h, w] = > [b, 512, h, w]
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
x = self.outlayer(x)
return xTest it
x = torch.randn(2, 3, 32, 32)
model = ResNet18()
out = model(x)
print("ResNet:", out.shape)The result is an error. The error information is as follows
size mismatch, m1: [2048 x 2], m2: [512 x 10] at /pytorch/aten/src/TH/generic/THTensorMath.cpp:961
The problem is that we finally define the input dimension of the linear layer, which does not match the output dimension of the Block of the previous layer. After the last Block of ResNet18 runs, print the shape of the current x, and the result is torch.Size([2, 512, 2, 2])
There are many solutions. You can modify the input of the linear layer to match, or you can perform some operations after the last layer Block to match 512
First give the modified code for explanation
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(64),
)
# followed 4 blocks
# [b, 64, h, w] => [b, 128, h, w]
self.blk1 = ResBlk(64, 128, stride=2)
# [b, 128, h, w] => [b, 256, h, w]
self.blk2 = ResBlk(128, 256, stride=2)
# [b, 256, h, w] => [b, 512, h, w]
self.blk3 = ResBlk(256, 512, stride=2)
# [b, 512, h, w] => [b, 512, h, w]
self.blk4 = ResBlk(512, 512, stride=2)
self.outlayer = nn.Linear(512*1*1, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
# After four Blks, [b, 64, h, w] = > [b, 512, h, w]
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
# print("after conv:", x.shape) # [b, 512, 2, 2]
# [b, 512, h, w] => [b, 512, 1, 1]
x = F.adaptive_avg_pool2d(x, [1, 1])
x = x.view(x.size(0), -1) # [b, 512, 1, 1] => [b, 512*1*1]
x = self.outlayer(x)
return xHere, I use the second method. After the end of the last Block, an adaptive pooling layer is connected. The function of this pooling is to output a tensor whose width and height are 1 regardless of the input width and height, and other dimensions remain unchanged. Then do a reshape operation, and change [batchsize, 512, 1, 1]reshape into a tensor of [batchsize, 512*1*1], so that it is aligned with the next linear layer. The input size of the linear layer is 512 and the output is 10. Therefore, the final output shape of the whole network is [batchsize, 10]
Finally, we copy the code that trained LeNet5 before, and change the model=LeNet5() to model=ResNet18(). The complete code is as follows
import torch
from torch import nn, optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
batch_size=32
cifar_train = datasets.CIFAR10(root='cifar', train=True, transform=transforms.Compose([
transforms.Resize([32, 32]),
transforms.ToTensor(),
]), download=True)
cifar_train = DataLoader(cifar_train, batch_size=batch_size, shuffle=True)
cifar_test = datasets.CIFAR10(root='cifar', train=False, transform=transforms.Compose([
transforms.Resize([32, 32]),
transforms.ToTensor(),
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batch_size, shuffle=True)
class ResBlk(nn.Module):
def __init__(self, ch_in, ch_out, stride=1):
super(ResBlk, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
if ch_out == ch_in:
self.extra = nn.Sequential()
else:
self.extra = nn.Sequential(
# one × The convolution function of 1 is to modify the channel of input x
# [b, ch_in, h, w] => [b, ch_out, h, w]
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out),
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# short cut
out = self.extra(x) + out
out = F.relu(out)
return out
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(64),
)
# followed 4 blocks
# [b, 64, h, w] => [b, 128, h, w]
self.blk1 = ResBlk(64, 128, stride=2)
# [b, 128, h, w] => [b, 256, h, w]
self.blk2 = ResBlk(128, 256, stride=2)
# [b, 256, h, w] => [b, 512, h, w]
self.blk3 = ResBlk(256, 512, stride=2)
# [b, 512, h, w] => [b, 512, h, w]
self.blk4 = ResBlk(512, 512, stride=2)
self.outlayer = nn.Linear(512*1*1, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
# After four Blks, [b, 64, h, w] = > [b, 512, h, w]
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
# print("after conv:", x.shape) # [b, 512, 2, 2]
# [b, 512, h, w] => [b, 512, 1, 1]
x = F.adaptive_avg_pool2d(x, [1, 1])
x = x.view(x.size(0), -1) # [b, 512, 1, 1] => [b, 512*1*1]
x = self.outlayer(x)
return x
def main():
########## train ##########
#device = torch.device('cuda')
#model = ResNet18().to(device)
criteon = nn.CrossEntropyLoss()
model = ResNet18()
optimizer = optim.Adam(model.parameters(), 1e-3)
for epoch in range(1000):
model.train()
for batchidx, (x, label) in enumerate(cifar_train):
#x, label = x.to(device), label.to(device)
logits = model(x)
# logits: [b, 10]
# label: [b]
loss = criteon(logits, label)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('train:', epoch, loss.item())
########## test ##########
model.eval()
with torch.no_grad():
total_correct = 0
total_num = 0
for x, label in cifar_test:
# x, label = x.to(device), label.to(device)
# [b]
logits = model(x)
# [b]
pred = logits.argmax(dim=1)
# [b] vs [b]
total_correct += torch.eq(pred, label).float().sum().item()
total_num += x.size(0)
acc = total_correct / total_num
print('test:', epoch, acc)
if __name__ == '__main__':
main()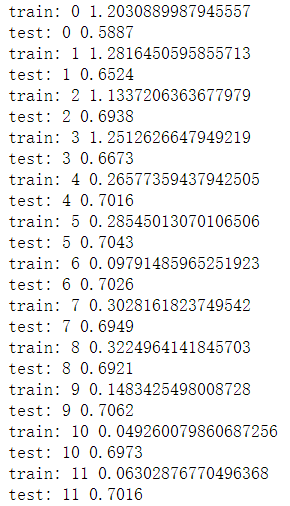
Compared with LeNet, the accuracy of ResNet improves rapidly, but the increase in the number of layers will inevitably lead to an increase in the running time. If there is no GPU, it will take about 15 minutes to run an epoch. Readers can also modify the network structure on this basis and use some tricks, such as normalizing the picture at the beginning