Source: Hengyuan cloud community( Hengyuan cloud, a shared computing platform focusing on AI industry)
Original address| Text data enhancement
Original author Jiao Hui
Recently, I was doing news headline classification and found an article with data enhancement to learn:
One is enough! Overview of data enhancement methods
This paper implements EDA (simple data enhancement) and back translation:
I EDA
1.1 random replacement

import random
import jieba
import numpy as np
import paddle
from paddlenlp.embeddings import TokenEmbedding
# Find the topk synonym of a word from the word vector according to the cosine similarity
def get_similar_tokens_raw(query_token, k, token_embedding):
W = np.asarray(token_embedding.weight.numpy())
x = np.asarray(token_embedding.search(query_token).reshape(-1))
cos = np.dot(W, x) / np.sqrt(np.sum(W * W, axis=1) * np.sum(x * x) + 1e-9)
flat = cos.flatten()
# argpartition places the k-th largest index in K positions. The left is smaller than it and the right is larger than it. The complexity is only o(n)
# Take - k, and the one on the right of - k and him is topk. Just rearrange them
indices = np.argpartition(flat, -k)[-k:]
indices = indices[np.argsort(-flat[indices])] # Take the negative row from large to small
return token_embedding.vocab.to_tokens(indices)
# Random substitution
def random_replace(words,token_embedding,prob=0.1,max_change=3):
change_num=0
for idx in range(len(words)):
prob_i=prob*(len(words[idx])-0.5) # -0.5 makes the probability of words with length 1 multiplied by 2, which is not easy to select
if random.uniform(0,1)<prob_i: # The longer the word, the easier it is to be replaced
sim_words=get_similar_tokens_raw(words[idx],k=5,token_embedding=token_embedding)
words[idx]=random.choice(sim_words)
change_num+=1
if change_num>=max_change:
break
return words
Due to get_similar_tokens_raw can only take the synonym of one word at a time, so it is changed to take the synonym of multiple words at a time. The effect is as follows: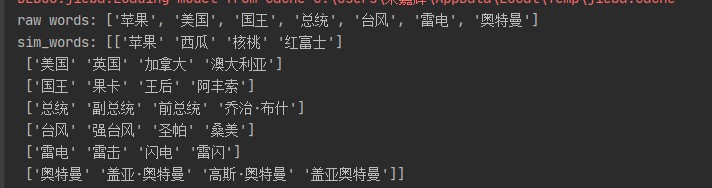
# Query topk synonyms of multiple words
def get_similar_tokens_multi(query_tokens, k, token_embedding):
n_tokens=len(query_tokens)
W = paddle.to_tensor(token_embedding.weight.detach(),dtype='float16')
q_idx=token_embedding.search(query_tokens)
x = paddle.to_tensor(q_idx,dtype='float16').transpose((1,0))
cos = paddle.matmul(W, x) / paddle.sqrt(paddle.sum(W * W, axis=1,keepdim=True) * paddle.sum(x * x,keepdim=True) + 1e-9)
def sort_row_by_idx(input, indices):
assert input.shape == indices.shape
row, col = input.shape
indices = indices * col + np.arange(0, col)
indices = indices.reshape(-1)
input = input.reshape(-1)[indices].reshape(row, -1)
return input
part_indices = np.argpartition(cos.numpy(), -k, axis=0)
out = sort_row_by_idx(cos.numpy(), part_indices)[-k:, :]
new_idx = np.argsort(-out, axis=0)
# Sort the index of the old part with the new index
indices = sort_row_by_idx(part_indices[-k:, :], new_idx).reshape(-1)
sim_tokens=token_embedding.vocab.to_tokens(indices)
sim_tokens=np.array(sim_tokens).reshape(k,n_tokens)
if k>=2:sim_tokens=sim_tokens[:-1,:]
return sim_tokens.transpose()
# Corresponding random substitution (this function will return multiple synonym lists for random insertion)
def random_replace(words,token_embedding,prob=0.1,max_change=3):
words=np.array(words)
probs=np.random.uniform(0,1,(len(words),))
words_len=np.array([len(word) for word in words])-0.5 # Penalty 1
probs=probs/words_len
mask=probs<prob
if sum(mask)>1:
replace_words=words[mask].tolist()
sim_words=get_similar_tokens_multi(query_tokens=replace_words,k=5,token_embedding=token_embedding)
choosed=[]
for row in sim_words:
choosed.append(np.random.choice(row))
words[mask]=np.array(choosed)
return words.tolist(),sim_words.flatten().tolist()
return words.tolist(),[]
if __name__ == '__main__':
token_embedding=TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")
# Synonym search
words=['Apple','U.S.A','king','president','typhoon','thunder','Ultraman']
sim_words=get_similar_tokens_multi(query_tokens=words,k=5,token_embedding=token_embedding)
print('raw words:',words)
print('sim_words:',sim_words)
1.2 random insertion
Randomly insert n words into the statement (sample from the list of synonyms returned by random replacement. If sim_words=None, sample randomly from the original sentence)
def random_insertion(words,sim_words=None,n=3):
new_words = words.copy()
for _ in range(n):
add_word(new_words,sim_words)
return new_words
def add_word(new_words,sim_words=None):
random_synonym = random.choice(sim_words) if sim_words else random.choice(new_words)
random_idx = random.randint(0, len(new_words) - 1)
new_words.insert(random_idx, random_synonym) # Random insertion
1.3 random deletion
Each word in the sentence is randomly deleted according to the probability p. here, it is weighted according to the word length. The longer it is, the harder it is to be deleted. The code is as follows:


def random_deletion(words,prob=0.1):
probs=np.random.uniform(0,1,(len(words),))
words_len=np.array([len(word) for word in words])
# Increase the weight of long words to prevent important words from being deleted
probs=probs*words_len
mask=probs>prob
return np.array(words)[mask].tolist()
1.4 random replacement of adjacent words
When reading a sentence, people often type the order randomly, but they can also reason the sentence and interpret the meaning. If you don't believe it, go back and read it again. Ha ha, the code is as follows:
# First obtain the word retrieval index, and then add a noise ∈ [0, n] to a word. Generally, n (window_size) is 3, and then
# Reordering will achieve the goal
def random_permute(words,window_size):
noise=np.random.uniform(0,window_size,size=(len(words),))
idx=np.arange(0,len(words))
new_idx=np.argsort(noise+idx)
return np.array(words)[new_idx].tolist()
II Back translation
Back translation is a commonly used method to enhance monolingual corpus in machine translation: for the target monolingual corpus T, the reverse translation model (tgt2src) is used to generate the source pseudo data s', so that the forward src2tgt translation model can continue training using pseudo parallel corpus (s', t).
This paper uses the pre trained mbart50(50 languages) for back translation, which can translate the original corpus zh in the following directions:
Chinese - > French - > XXXX - > English - > Chinese. For simplicity, this paper will carry out Chinese-English back translation:
Back translation example: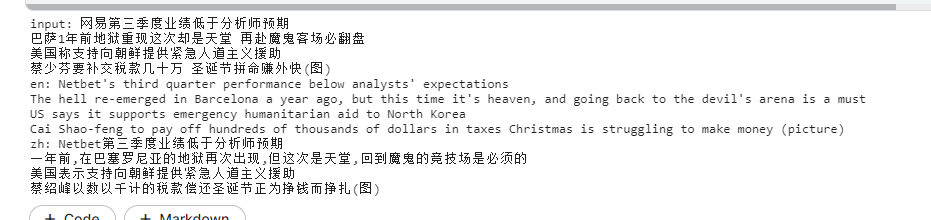
import torch
from transformers import MBartForConditionalGeneration,MBart50TokenizerFast
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
model.eval()
batch_sentences=['Netease's third quarter results were lower than analysts' expectations',
'Barcelona's hell reappeared a year ago, but this time it is heaven. It will turn over when they go to the devil's away game again',
'The United States says it supports emergency humanitarian assistance to North Korea',
'Cai Shaofen has to pay hundreds of thousands of taxes to earn extra money at Christmas(chart)']
print('input:','\n'.join(batch_sentences))
# Chinese - > English
tokenizer.src_lang='zh_CN' # Set input to Chinese
batch_tokenized = tokenizer.batch_encode_plus(batch_sentences, add_special_tokens=True,padding=True, pad_to_max_length=True)
input_dict = {'input_ids':torch.LongTensor(batch_tokenized['input_ids']).to(device),
"attention_mask":torch.LongTensor(batch_tokenized['attention_mask']).to(device)}
batch_tokens=model.generate(**input_dict,forced_bos_token_id=tokenizer.lang_code_to_id['en_XX']) # Output in English
en_sent=tokenizer.batch_decode(batch_tokens, skip_special_tokens=True)
print('en:','\n'.join(en_sent))
# English - > Chinese
tokenizer.src_lang='en_XX' # Set input to English
batch_tokenized = tokenizer.batch_encode_plus(en_sent, add_special_tokens=True,padding=True, pad_to_max_length=True)
input_dict = {'input_ids':torch.LongTensor(batch_tokenized['input_ids']).to(device),
"attention_mask":torch.LongTensor(batch_tokenized['attention_mask']).to(device)}
batch_tokens=model.generate(**input_dict,forced_bos_token_id=tokenizer.lang_code_to_id['zh_CN']) # Output in Chinese
zh_sent=tokenizer.batch_decode(batch_tokens, skip_special_tokens=True)
print('zh:','\n'.join(zh_sent))
'''
mbart50 Cover the following languages:
Arabic (ar_AR), Czech (cs_CZ), German (de_DE), English (en_XX), Spanish (es_XX), Estonian (et_EE), Finnish (fi_FI), French (fr_XX), Gujarati (gu_IN), Hindi (hi_IN), Italian (it_IT), Japanese (ja_XX), Kazakh (kk_KZ), Korean (ko_KR), Lithuanian (lt_LT), Latvian (lv_LV), Burmese (my_MM), Nepali (ne_NP), Dutch (nl_XX), Romanian (ro_RO), Russian (ru_RU), Sinhala (si_LK), Turkish (tr_TR), Vietnamese (vi_VN), Chinese (zh_CN), Afrikaans (af_ZA), Azerbaijani (az_AZ), Bengali (bn_IN), Persian (fa_IR), Hebrew (he_IL), Croatian (hr_HR), Indonesian (id_ID), Georgian (ka_GE), Khmer (km_KH), Macedonian (mk_MK), Malayalam (ml_IN), Mongolian (mn_MN), Marathi (mr_IN), Polish (pl_PL), Pashto (ps_AF), Portuguese (pt_XX), Swedish (sv_SE), Swahili (sw_KE), Tamil (ta_IN), Telugu (te_IN), Thai (th_TH), Tagalog (tl_XX), Ukrainian (uk_UA), Urdu (ur_PK), Xhosa (xh_ZA), Galician (gl_ES), Slovene (sl_SI
'''
# Offline back translation enhancement, back translation of text files by line,
import torch
from functools import partial
from transformers import MBartForConditionalGeneration,MBart50TokenizerFast
from tqdm import tqdm
def get_data_iterator(input_path):
with open(input_path, 'r', encoding="utf-8") as f:
for line in f.readlines():
line=line.strip()
yield line
# Iterator: generates data for a batch
def get_batch_iterator(data_path, batch_size=32,drop_last=False):
keras_bert_iter = get_data_iterator(data_path)
continue_iterator = True
while True:
batch_data = []
for _ in range(batch_size):
try:
data = next(keras_bert_iter)
batch_data.append(data)
except StopIteration:
continue_iterator = False
break
if continue_iterator:# Just a batch
yield batch_data
else: # Less than one batch
if not drop_last:
yield batch_data
return StopIteration
@torch.no_grad()
def batch_translation(batch_sentences,model,tokenizer,src_lang,tgt_lang,max_len=128):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
tokenizer.src_lang=src_lang
# token2id
encoded_inputs=tokenizer.batch_encode_plus(batch_sentences, add_special_tokens=True,
padding=True, pad_to_max_length=True)
# max_length=max_len, pad_to_max_length=True)
# list->tensor
encoded_inputs['input_ids']=torch.LongTensor(encoded_inputs['input_ids']).to(device)
encoded_inputs['attention_mask']=torch.LongTensor(encoded_inputs['attention_mask']).to(device)
# generate
batch_tokens = model.generate(**encoded_inputs, forced_bos_token_id=tokenizer.lang_code_to_id[tgt_lang])
# decode
tgt_sentences = tokenizer.batch_decode(batch_tokens, skip_special_tokens=True)
return tgt_sentences
def translate_file(src_path,tgt_path,src_lang,tgt_lang,batch_size=32,max_len=128):
# data
batch_iter=get_batch_iterator(src_path,batch_size=batch_size)
# model
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
src2tgt_fn = partial(batch_translation, model=model, tokenizer=tokenizer,
src_lang=src_lang, tgt_lang=tgt_lang,max_len=None)
result=[]
i=0
for batch_sentences in tqdm(batch_iter):
tgt_sentences = src2tgt_fn(batch_sentences)
result.extend(tgt_sentences)
if i%100==0:
print(f'src:{batch_sentences[0]}==>tgt:{tgt_sentences[0]}')
i+=1
# write 2 file
with open(tgt_path,'w',encoding='utf-8') as f:
f.write('\n'.join(result))
print(f'write 2 {tgt_path} success.')
if __name__ == '__main__':
src_path='train.txt'
mid_path='train.en'
tgt_path='train_back.txt'
# translate zh to en
translate_file(src_path, mid_path, src_lang='zh_CN', tgt_lang='en_XX', batch_size=16)
# translate en to zh
translate_file(mid_path, tgt_path, src_lang='en_XX', tgt_lang='zh_CN', batch_size=16)
Summary:
Data enhancement is limited. Next, we are ready to continue pre training on relevant task data.
reference resources:
1.One is enough! Overview of data enhancement methods
2.Back translation
3.mbart50
4.Machine translation: Fundamentals and models