1. Data skew definition
The uneven distribution of data causes a large amount of data to be concentrated at one point, resulting in data hotspots.
2. Performance of data skew
When executing the task, the task progress is maintained at about 99% for a long time;
When viewing the execution status of the stage, the card is stuck in the last 1-2 tasks for a long time. When viewing the task monitoring page, it is found that the running time of one or two or three tasks is far greater than that of other tasks, and the amount of data processed by these tasks is far greater than that of other tasks.
Note: the running time of a spark task is determined by the last task successfully executed. If a task has data skew, it will slow down the execution efficiency of the whole spark task. Even if other tasks without skew have been executed, it will even lead to OOM
3. View data skew method
Check whether data skew is generated in the yarn interface:
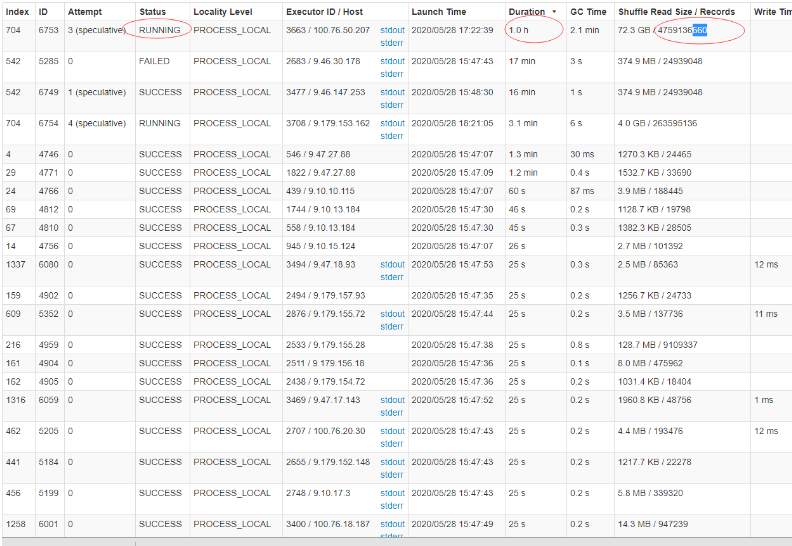
The above figure shows the monitoring page of tasks on the yarn interface. It can be seen from the above figure that the execution time of most tasks is 25s, and the number of processing records ranges from tens of thousands to hundreds of thousands (most of the processed data is a few megabytes to tens of megabytes). However, one task has a processing time of 1 hour, and the processed data is up to 72G, which has not been executed yet. At this time, it can be inferred that the data is skewed, The tilt key can be found by group by or sampling.
4. Data skew condition
A shuffle occurs during data calculation, that is, the data is repartitioned.
| key word | situation | consequence |
|---|---|---|
| join | One or more keys are concentrated, or there are a large number of null key s | The data distributed to one or several Reduce is much higher than the average |
| group by | The dimension is too small and the quantity of a value is too large | A certain dimension or several dimensions, and the data volume of these dimensions is particularly large, which are concentrated in one reduce |
5. Data skew solution
5.1 handling of special circumstances
① Data skew caused by association with data type
-
Situation: for example, user in the user table_ The ID field is int, and the user in the log table_ ID field string type. When according to user_id when joining two tables.
-
Solution: convert numeric type to string type
select * from users a left outer join logs b on a.usr_id = cast(b.user_id as string)
② null key does not participate in association
select
a.*
from(
select
*
from log
where user_id is not null
) a
join
users b on a.user_id = b.user_id
union all
select
*
from log where user_id is null
③ Data salting: assign null value to random value
1. select *
2. from log a
3. left outer join users b
4. on case when a.user_id is null then concat('hive',rand() ) else a.user_id end = b.user_id;
- Comparison of advantages and disadvantages of the two methods
Method 2 is more efficient than method 1 io Less, and less homework. In solution 1 log Read twice, jobs It's 2. Solution 2 job The number is 1 ; This optimization is not valid id (such as -99 , '', null etc.) The resulting tilt problem. Put the null value key By adding a random number to a string, the skewed data can be divided into different groups reduce upper ,Solve the problem of data skew.
④ Improve reduce parallelism
Set the number of reduce: set mapred reduce. Tasks = 15, you can improve the parallelism of the reduce end by changing the parameters, so as to alleviate the data skew.
1> Before optimization, assume that the data volume of key1, key2, key3 and key4 is 50w and that of key5 is 10w. At this time, key1 and key3suffle arrive at a reduce, and key2 and key4shuffle arrive at a reduce. As a result, two reduce task s need to process 100w data, while one task only needs to process 10w data. At this time, the data is tilted 10 times.
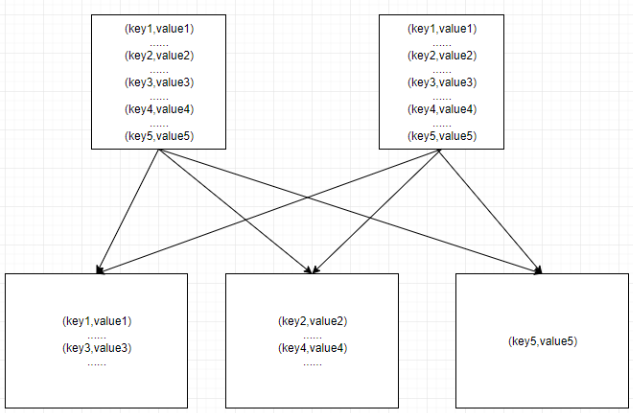
2> After optimization, as shown in the figure, in order to reduce the parallelism to 3 before optimization, the maximum amount of data processed by a single task is 100w. Now the parallelism is increased to 5, and the maximum amount of data processed by a single task is 50w, which alleviates the inclination by 5 times compared with before. This scheme is suitable for the degree of tilt is not very serious, and more than two tilt key s to shuffle to the same reduce.
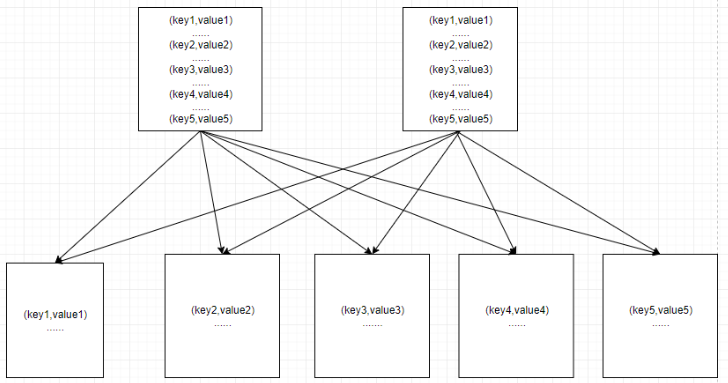
5.2 data skew caused by group by
① Turn on load balancing
② group by double aggregation
When using group by for aggregation statistics, if one or more keys are skewed, it will cause a skewed key to be shuffled to a reduce.
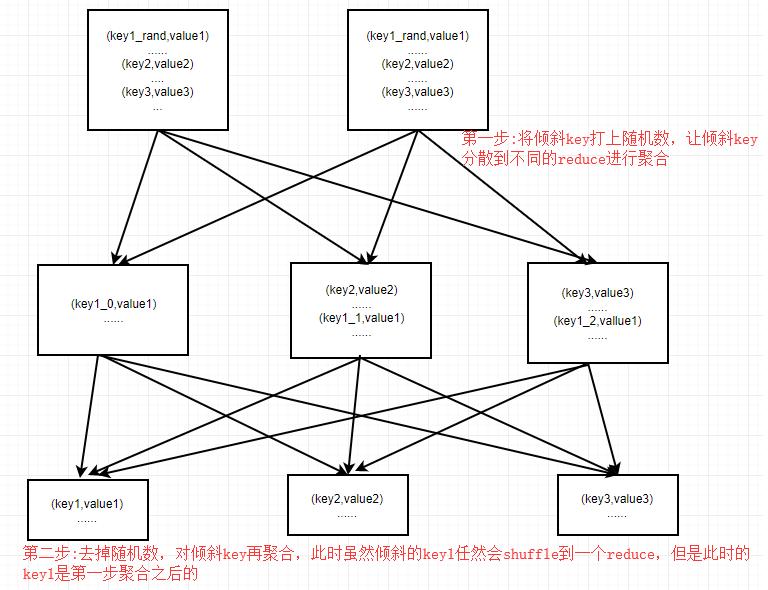
select
split(sp_app_id,'_')[0] sp_app_id
,sum(pv)
from
(
select
sp_app_id||'_'||CAST(CAST(MOD(rand() * 10000,10) AS BIGINT) AS STRING) sp_app_id
,sum(nvl(op_cnt, 1)) pv
from t1
group by sp_app_id||'_'||CAST(CAST(MOD(rand() * 10000,10) AS BIGINT) AS STRING)
) group by split(sp_app_id,'_')[0]
5.3 data skew caused by join
① Convert reduce join into map join (this scheme is suitable for small table join and large table join)
select /*+ mapjoin(t2)*/ column from table
② Filter the tilt join and join separately
Therefore, if you filter out the inclined key and join it separately, the inclined key will be scattered to multiple task s for join operation, and finally union all.
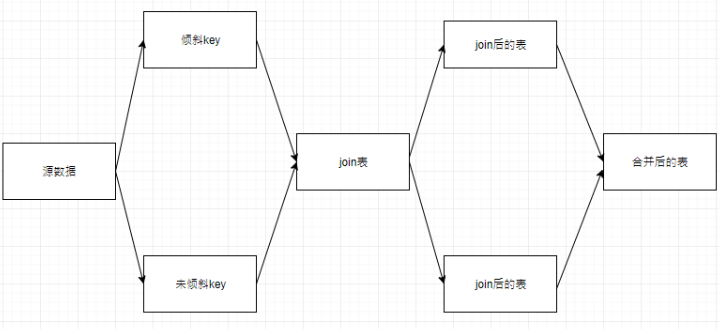
select
*
from
(
select
*
from t1
where rowkey <> '123456789'
) a1 join a2 on a1.rowkey = a2.rowkey
union all
select
*
from
(
select
*
from t1
where rowkey = '123456789'
)a1 join a2 on a1.rowkey = a2.rowkey