0x0. preface
I answered the question about how to contribute to PyTorch before. See the original post: https://www.zhihu.com/question/502301777/answer/2248950419 . The answer mentioned that when some operators were developed in OneFlow last year, some bug s of PyTorch operators were found based on the operator AutoTest framework, and feedback or repair were made to PyTorch. But this answer does not introduce what the AutoTest framework looks like and the principle behind it. Therefore, this article is used to introduce the operator AutoTest framework of OneFlow and see how the OneFlow deep learning framework gracefully performs the operator alignment task in the operator development process (developed by @ Big missing string, and then expanded and enriched by me and other colleagues to form today's form). This AutoTest framework can also be easily transplanted to other in-depth learning and training frameworks. The code is implemented in https://github.com/Oneflow-Inc/oneflow/blob/v0.6.0/python/oneflow/test_utils/automated_test_util/torch_flow_dual_object.py .
0x1. Traditional operator alignment
Not limited to OneFlow, any deep learning training framework written by an organization or individual needs to verify the correctness of the implementation of the operator. Then, what is the general method to verify the correctness of operators in the deep learning framework? Taking Baidu's PaddlePaddle as an example, when validating the correctness of the operator, the result is usually obtained by calling other standard libraries (for example, the convolution of the convolution operator calls the convolution of cudnn, the verification of erf operator calls the implementation of scipy), or the result of numpy simulation is used to do no validation (for example, the verification of full operator is numpy simulation). There is also a way to hard code some test samples in the test samples of PyTorch, that is, compare the standard answers of the fixed input samples with the results of the operator output, so as to judge the correctness of the operator.
There are no problems with these methods, but it takes a lot of manpower to write tests, and some corner case s may be unexpected in the early stage of operator development. Take OneFlow as an example. Since the behavior of the operator is to align PyTorch, what kind of test code can be fully verified if the correctness of transpose convolution Op is to be verified in various cases? One way is to enumerate each parameter:
import torch
import numpy as np
import oneflow as flow
for N in range(1, 5):
for C_in in range(1, 10):
for L_in in range(1, 10):
for H_in in range(1, 10):
for C_out in range(1, 10):
for Ksize in range(1, 10):
for Pad in range(1, 10):
for Dilation in range(1, 10):
for Stride in range(1, min(L_in, H_in)):
for OutPad in range(1, min(Dilation, Stride)):
try:
torch_input = torch.randn(N, C_in, L_in, H_in)
flow_input = flow.tensor(torch_input.numpy())
torch_input.requires_grad = True
flow_input.requires_grad = True
torch_m = torch.nn.ConvTranspose2d(in_channels=C_in, out_channels=C_out, kernel_size=Ksize, padding=Pad, stride=Stride,
output_padding=(OutPad), dilation=Dilation, bias=False)
flow_m = flow.nn.ConvTranspose2d(in_channels=C_in, out_channels=C_out, kernel_size=Ksize, padding=Pad, stride=Stride,
output_padding=(OutPad), dilation=Dilation, bias=False)
flow_m.weight.data = flow.tensor(torch_m.weight.data.detach().numpy(), requires_grad=True)
torch_out = torch_m(torch_input)
flow_out = flow_m(flow_input)
torch_out = torch_out.sum()
flow_out = flow_out.sum()
assert(np.allclose(torch_out.detach().numpy(), flow_out.detach().numpy(), 1e-06, 1e-06)), "forward not equal"
torch_out.backward()
flow_out.backward()
print(torch_input.grad.detach().numpy())
print(flow_input.grad.detach()[:N, :C_in, :L_in, :H_in].numpy())
assert(np.allclose(torch_input.grad.detach().numpy(), flow_input.grad.detach()[:N, :C_in, :L_in, :H_in].numpy(), 1e-03, 1e-03)), "backward not equal"
except Exception as e:
print('Input Param Error')
However, although this approach has been verified comprehensively, it also has disadvantages. First, how to determine the upper bound of enumeration? If a large upper bound is given, the verification time of this operator will be very long, which is not conducive to use in CI processes. If the upper bound is very small, some corner case s may be ignored, resulting in incomplete testing and increasing the risk of operator bug s.
Based on these problems of operator testing, my colleague @ Big missing string developed an operator AutoTest framework to solve the alignment problem of OneFlow operator and PyTorch operator. Later, on this basis, I enriched some other functions of this AutoTest framework. I feel that it has been relatively easy to use. Next, I will give a comprehensive introduction.
The entire AutoTest framework has only two Python files, namely: https://github.com/Oneflow-Inc/oneflow/blob/v0.6.0/python/oneflow/test_utils/automated_test_util/torch_flow_dual_object.py And https://github.com/Oneflow-Inc/oneflow/blob/v0.6.0/python/oneflow/test_utils/automated_test_util/generators.py . And this AutoTest framework can be easily transplanted to any other deep learning framework to do operator alignment tasks.
0x2. Operator AutoTest framework usage
Before introducing the principle, let's take a look at the usage of the AutoTest framework. Take the deconvolution integrator above as an example. After using the AutoTest framework, you can complete the operator alignment test with the following code:
@autotest()
def test_deconv2d_with_random_data(test_case):
channels = random(1, 6)
m = torch.nn.ConvTranspose2d(
in_channels=channels,
out_channels=random(1, 20),
kernel_size=random(1, 4),
stride=random() | nothing(),
padding=random(1, 3).to(int) | nothing(),
dilation=random(1, 5) | nothing(),
groups=random(1, 5) | nothing(),
padding_mode=constant("zeros") | nothing(),
)
m.train(random())
device = random_device()
m.to(device)
x = random_pytorch_tensor(ndim=4, dim1=channels).to(device)
y = m(x)
return y
Friends familiar with PyTorch can find that the operator test code is basically the same as the code style of PyTorch. Indeed, the AutoTest framework is equivalent to a high-level PyTorch. Its interface is the same as that of PyTorch, but for a given input, it will run with OneFlow and PyTorch respectively, record the values of each tensor and corresponding gradient tensor obtained during the operation, and then check whether the numerical shapes of the tensors generated by OneFlow and PyTorch are exactly the same, To complete the automatic test, we will talk about it in detail later.
We can take another example to test the matmul operator:
@autotest()
def test_flow_matmul_with_random_data(test_case):
k = random(1, 6)
x = random_pytorch_tensor(ndim=2, dim1=k)
y = random_pytorch_tensor(ndim=2, dim0=k)
z = torch.matmul(x, y)
return z
We are based on random_ pytorch_ The tensor method constructs two random tensors X and y, whose dimensions are [m, k] and [k, n], and the values of these dimensions are randomly generated.
Executing the above two test examples, the automatic test framework will automatically help us randomly select OPS composed of various legal parameters, and run the codes of PyTorch and OneFlow respectively based on the input Tensor (PyTorch and OneFlow have one copy each) with exactly the same value and type, and complete the automatic test of the operator. Since the usage of the automatic test framework aligns with the PyTorch usage, it will be very simple for us to write test samples after developing operators. There is no need to introduce other standard libraries or use Numpy to simulate the forward and reverse calculation process of operators, which liberates the productivity.
In addition, as long as the number of tests is enough, some examples that OneFlow operator and PyTorch operator cannot be aligned can be covered with a high probability. At this time, if we can get the corresponding reproduction examples, it can help us determine whether there are problems in the implementation of OneFlow operator.
0x3. Implementation of operator AutoTest framework
After knowing how to use the AutoTest framework, let's explain the implementation idea of the AutoTest framework. It can be guessed from the above usage that the AutoTest framework will be divided into two parts during implementation. One part is how to generate random data, and the other part is to run the program of the AutoTest part and record and compare the shapes and values of the intermediate tensor and the corresponding gradient tensor.
0x3.1 how to generate random data?
The random data mentioned here not only refers to the random input tensor, but also contains the attribute parameters of Op, such as the kernel in the deconvolution Op test example above_ Size = random (1, 4) implements the specified kernel_size will be taken in [1,4).
This part is implemented in https://github.com/Oneflow-Inc/oneflow/blob/v0.6.0/python/oneflow/test_utils/automated_test_util/generators.py In this document. First, let's take a look at the interfaces exported from this file:
__all__ = [
"random_tensor",
"random_bool",
"random_device",
"random",
"random_or_nothing",
"oneof",
"constant",
"nothing"
]
These interfaces are classes that inherit the generator base class to generate random data structures. The data structures here can be either built-in types such as int or user-defined data types such as tensor. The randomness of all parameters of the AutoTest framework is based on these methods. Let's take a look at the implementation of the generator base class:
class generator:
def __init__(self, children):
self.children = children
self._value = None
def _init(self):
self._value = None
for x in self.children:
x._init()
def eval(self):
self._init()
return self.value()
def _calc_value(self):
raise NotImplementedError()
def value(self):
if self._value is None:
self._value = self._calc_value()
return self._value
def size(self):
return 1
def __or__(self, other):
other = pack(other)
return oneof(
self, other, possibility=self.size() / (self.size() + other.size())
)
def __ror__(self, other):
return self | other
def __add__(self, other):
return add(self, other)
def __radd__(self, other):
return self + other
def __sub__(self, other):
return self + neg(other)
def __rsub__(self, other):
return neg(self - other)
def __mul__(self, other):
return mul(self, other)
def __rmul__(self, other):
return self * other
def to(self, annotation):
self._to(annotation)
for x in self.children:
x.to(annotation)
return self
def _to(self, annotation):
pass
This class not only holds_ calc_value, value, eval and other functions related to value also hold the function of size, which reflects the number of data generated. In addition, it also holds a series of magic functions, so that different generator subclasses can be combined with each other, which improves the flexibility of automatic test framework writing. Finally, there is a to member function, which is overridden by the class inheriting the generator base class to determine the numerical type of the random data structure.
All generator derived classes inherit the generator base class and override the__ init__,__ calc_value,size,_ to and other member functions. For example, nothing generator is directly rewritten_ calc_value function and returns the entity of a class that does nothing.
class Nothing:
pass
class nothing(generator):
def __init__(self):
super().__init__([])
def _calc_value(self):
return Nothing()
For another example, the definition of the derived class of random generator is as follows:
class random(generator):
def __init__(self, low=1, high=6):
self.low = pack(low)
self.high = pack(high)
super().__init__([self.low, self.high])
self.annotation = None
def _to(self, annotation):
if self.annotation is not None:
return
if hasattr(annotation, "__origin__"):
# PyTorch _size_2_t and similar types are defined by type variables,
# leading to unexpected __args__ and __origin__
#
# >>> _size_2_t = Union[T, Tuple[T, T]][int]
# >>> _size_2_t.__origin__
# typing.Union[~T, typing.Tuple[~T, ~T]]
#
# So recreate a new annotation object by repr and eval
#
# >>> _size_2_t
# typing.Union[int, typing.Tuple[int, int]]
# >>> _size_2_t_new = eval(repr(annotation))
# >>> _size_2_t_new.__origin__
# typing.Union
annotation = eval(repr(annotation))
self.annotation = annotation
def _generate(self, annotation):
if hasattr(annotation, "__origin__"):
if annotation.__origin__ is Union:
x = random_util.choice(annotation.__args__)
return self._generate(x)
if annotation.__origin__ is Tuple or annotation.__origin__ is py_tuple:
return [self._generate(x) for x in annotation.__args__]
else:
raise NotImplementedError(
f"Not implemented annotation {annotation} in random, type(annotation.__origin__) is {type(annotation.__origin__)}"
)
low, high = self.low.value(), self.high.value()
if annotation == int:
val = int(rng.integers(low, high))
elif annotation == float:
val = float(rng.random() * (high - low) + low)
elif annotation == bool:
val = random_util.choice([True, False])
else:
raise NotImplementedError(
f"Not implemented annotation {annotation} in random"
)
return val
def _calc_value(self):
return self._generate(self.annotation)
def random_or_nothing(low, high):
return oneof(random(low, high), nothing(), possibility=2 / 3)
One thing to note here is that the generator derived class that holds the annotation attribute can update the annotation attribute (such as the random class) through to, or ignore this parameter and directly_ calc_value constructs a random result of the corresponding type (such as the random_device class).
0x3.2 AutoTest core implementation
The core implementation of AutoTest framework is https://github.com/Oneflow-Inc/oneflow/blob/v0.6.0/python/oneflow/test_utils/automated_test_util/torch_flow_dual_object.py This file. The last two lines of code in this file are:
torch = GetDualObject("", torch_original, flow)
__all__ = ["autotest", "random_pytorch_tensor"]
This line of code Torch = torch in GetDualObject ("", torch_original, flow)_ Original represents the original PyTorch framework, while the torch representation obtained using GetDualObject encapsulates the original PyTorch and OneFlow into a high-level PyTorch. Therefore, the key implementation here is the GetDualObject function. We don't focus on what this function is doing, but what it returns. Looking at the code, we can find that this function returns a DualObject class object. Let's study this class first:
class DualObject:
def __init__(self, name, pytorch, oneflow):
self.name = name
self.pytorch = pytorch
self.oneflow = oneflow
if isinstance(pytorch, torch_original.nn.Module):
state_dict = pytorch.state_dict()
state_dict = {k: v.detach().cpu().numpy() for (k, v) in state_dict.items()}
oneflow.load_state_dict(state_dict, strict=False)
if testing:
dual_modules_to_test.append(self)
if isinstance(pytorch, torch_original.Tensor):
if testing:
dual_objects_to_test.append(self)
def __repr__(self):
return f"PyTorch object:\n{self.pytorch}\n\nOneFlow object:\n{self.oneflow}"
def __getattr__(self, key):
pytorch_attr = getattr(self.pytorch, key)
oneflow_attr = getattr(self.oneflow, key)
new_name = f"{self.name}.{key}"
global call_pytorch
call_pytorch = self.pytorch
return GetDualObject(new_name, pytorch_attr, oneflow_attr)
In__ init__ Class object name and pytorch/oneflow objects are passed in. Torch is passed in when exporting PyTorch of high level_ Original and flow, while random is exported_ PyTorch_ PyTorch is passed in when using the tensor API_ Tensor and oneflow_tensor. Let's take a look at random first_ PyTorch_ Implementation of tensor function:
def random_pytorch_tensor(
ndim=None,
dim0=1,
dim1=None,
dim2=None,
dim3=None,
dim4=None,
low=0,
high=1,
dtype=float,
requires_grad=True,
):
if isinstance(requires_grad, generator):
requires_grad = requires_grad.value()
pytorch_tensor = (
random_tensor(ndim, dim0, dim1, dim2, dim3, dim4, low, high, dtype)
.value()
.requires_grad_(requires_grad and dtype != int)
)
flow_tensor = flow.tensor(
pytorch_tensor.detach().cpu().numpy(),
requires_grad=(requires_grad and dtype != int),
)
return GetDualObject("unused", pytorch_tensor, flow_tensor)
You can see that, like the implementation of exporting high level PyTorch, it also obtains an object by calling GetDualObject. Returning to the implementation of DualObject class, you can find that dual is used here_ modules_ to_ Test and dual_objects_to_test these two list s to record the NN of OneFlow and PyTorch respectively Module and tensor objects. In addition, the DualObject class overrides__ getattr__ This magic method takes Flatten as an example to see that this magic method obtains those attributes in the AutoTest program:
def __getattr__(self, key):
pytorch_attr = getattr(self.pytorch, key)
oneflow_attr = getattr(self.oneflow, key)
print(key)
# print(pytorch_attr)
# print(oneflow_attr)
new_name = f"{self.name}.{key}"
return GetDualObject(new_name, pytorch_attr, oneflow_attr)
# flatten's AutoTest program
@autotest(auto_backward=False)
def test_against_pytorch(test_case):
m = torch.nn.Flatten(
start_dim=random(1, 6) | nothing(), end_dim=random(1, 6) | nothing()
)
m.train(random())
device = random_device()
m.to(device)
x = random_pytorch_tensor().to(device)
y = m(x)
return y
Then take a look__ getattr__ Print results of key in:
nn Flatten train to to
You can see PyTorch or NN of OneFlow in the test program modified by the autotest() decorator Module or other functions have overridden this method, which takes these NN Take out the parameters and properties of module or other functions and use GetDualObject to return a new DualObject. We can print the NN of Flatten What is the DualObject object corresponding to the module
PyTorch object: <bound method Module.train of Flatten(start_dim=1, end_dim=-1)> OneFlow object: <bound method Module.train of Flatten(start_dim=1, end_dim=-1)>
The GetDualObject function generates a DualObject object based on the passed in Python and OneFlow objects and their names. GetDualObject function will override the original pytorch and OneFlow objects passed in for pytorch of high level__ call__ Magic function, and finally return a DualObject object. This process also includes skipping some magic functions that do not need attention, and checking whether the attributes of the incoming object are legal and based on NN The types of Module and other API default parameters bind specific types of random data generated by the generator inheritance class (completed in the get_args function). There is also a special judgment on Tensor method, because the calling method of Tensor method (through getattr) is different from other modules and functions (through _call).
The implementation idea of GetDualObject is basically like this. The code is relatively long and will not be posted here. If you are interested, you can check it here: https://github.com/Oneflow-Inc/oneflow/blob/v0.6.0/python/oneflow/test_utils/automated_test_util/torch_flow_dual_object.py#L195-L401 .
Finally, let's take a look at the implementation of the autotest() decorator:
def autotest(
n=20,
auto_backward=True,
rtol=0.0001,
atol=1e-05,
check_graph=True,
check_allclose=True,
):
verbose = os.getenv("ONEFLOW_TEST_VERBOSE") is not None
def deco(f):
@functools.wraps(f)
def new_f(test_case):
nonlocal n
loop_limit = n * 20
loop = 0
while n > 0:
clear_note_fake_program()
if loop > loop_limit:
raise ValueError("autotest stuck in an endless loop!")
dual_modules_to_test.clear()
dual_objects_to_test.clear()
try:
global testing
testing = True
global testing_graph
if check_graph:
testing_graph = True
res = f(test_case)
testing = False
testing_graph = False
except (PyTorchDoesNotSupportError, BothDoNotSupportError) as e:
if verbose:
print(f"{f.__name__}")
print(e)
loop += 1
continue
if res is not None:
if not isinstance(res, collections.abc.Sequence):
res = [res]
func_outputs = res
for x in res:
if auto_backward:
if isinstance(x.pytorch, torch_original.Tensor):
call_tensor_id.append(id(x.pytorch))
x.sum().backward()
dual_objects_to_test.append(x)
for x in dual_modules_to_test:
for key in x.pytorch.state_dict().keys():
if key not in x.oneflow.state_dict().keys():
warnings.warn(f"oneflow module don't have `{key}`")
continue
vis_parameters[key] = x.pytorch.state_dict()[key]
dual_objects_to_test.append(
GetDualObject(
"unused",
getattr(x.pytorch, key),
getattr(x.oneflow, key),
)
)
call_tensor_id.append(id(getattr(x.pytorch, key)))
dual_objects_to_test.append(
GetDualObject(
"unused",
getattr(x.pytorch, key).grad,
getattr(x.oneflow, key).grad,
)
)
call_tensor_id.append(id(getattr(x.pytorch, key).grad))
for x in dual_objects_to_test:
if (
isinstance(x.pytorch, torch_original.Tensor)
and id(x.pytorch) not in call_tensor_id
):
vis_tensor.append(x.pytorch)
# check eager
for x in dual_objects_to_test:
if check_allclose:
test_case.assertTrue(check_equality(x, rtol=rtol, atol=atol), x)
if verbose:
print(f"{f.__name__} test eager passed.")
n -= 1
loop += 1
return new_f
return deco
The line res = f(test_case) of the decorator will execute the automatic test program modified by the decorator, run PyTorch and OneFlow programs respectively under the given input, obtain all intermediate output tensors, including the gradient of tensors, and record them to dual_modules_to_test this list. Then traverse each tensor in the list and compare whether the value and shape are exactly the same. The comparison function is implemented in: https://github.com/OneFlow-Inc/OneFlow/blob/v0.6.0/python/OneFlow/test_utils/automated_test_util/torch_flow_dual_object.py#L565 -The principle of l599 is to get the numpy data of tensor for comparison. The autotest() decorator also has several parameters that can be adjusted to control whether the test is executed reversely, the number of executions, and the accuracy threshold of the final result comparison.
0x4. Automatically generate BUG program and data
The principle and usage of the AutoTest framework are introduced above. Here we show how to get the program of reproducible BUG based on the AutoTest framework and the corresponding input tensor and parameters. The principle is very simple. The api used in GetDualObject process is recorded and put together to form a complete program. Here is the effect in CI. https://github.com/Oneflow-Inc/oneflow/runs/4760189461?check_suite_focus=true This example shows the conv of OneFlow in a CI process_ Transpose2d operator and conv of PyTorch_ If the transport2d operator is not aligned in a case, the CI also outputs the corresponding reproduction code and data when reporting this error, which can facilitate the framework developer to locate and judge:
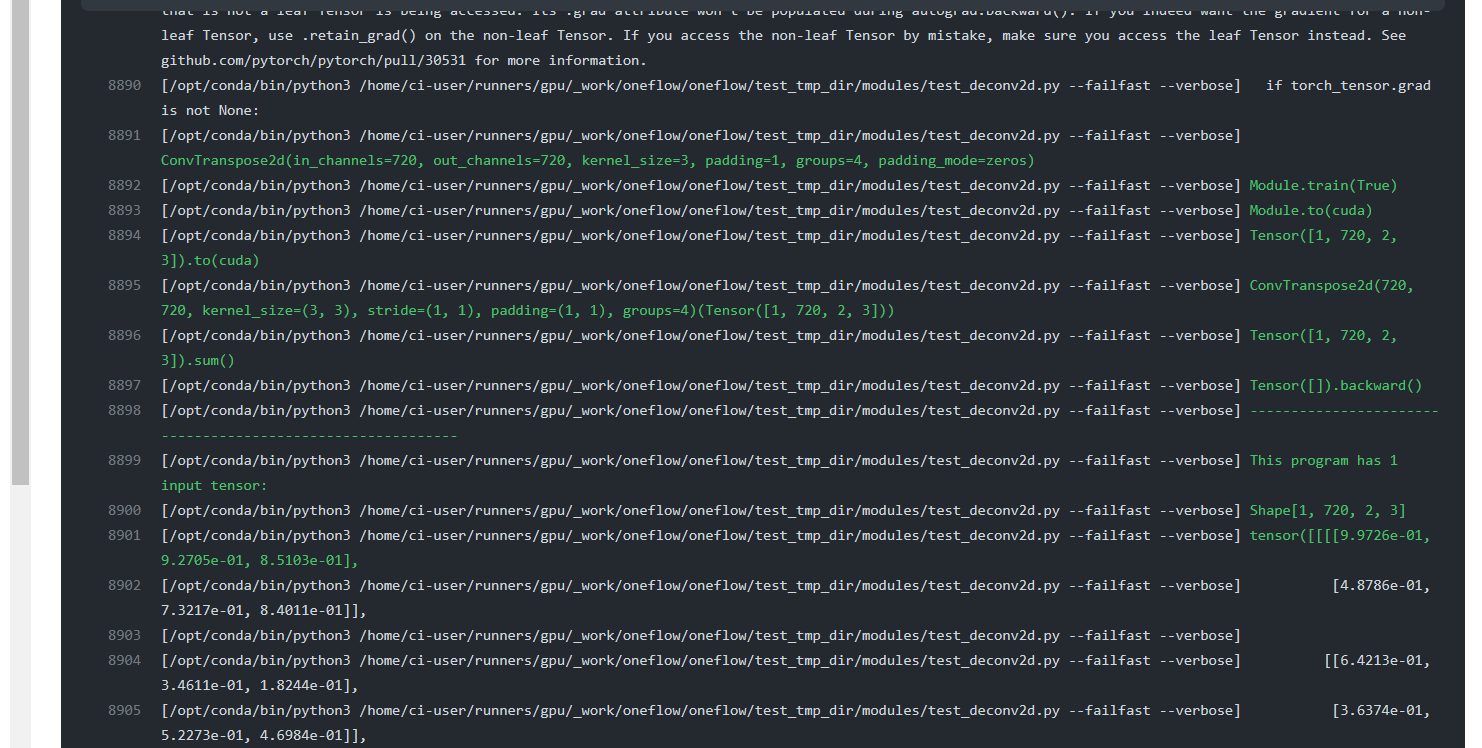
In addition, the AutoTest framework is not only responsible for the test of Eager operator, but also extended to support NN Graph, Eagle consistent and other situations greatly facilitate framework developers.
0x5. summary
This article introduces the operator AutoTest framework of OneFlow, which provides a deep learning and elegant method of operator alignment, so that developers and users can write test programs as easily as PyTorch. AutoTest framework is flexible and easy to use. You are welcome to learn or use it.
0x6. Related links
- https://github.com/Oneflow-Inc/oneflow
- https://github.com/pytorch/pytorch