How does the partner system allocate memory
Partner system
The partner system is derived from the Solaris Operating System of Sun company. It is an excellent physical memory page management algorithm on the Solaris Operating System. However, good things are always easy to be stolen or imitated by others, and the partner system has also become the physical memory management algorithm of Linux.
How to represent a page
Linux also uses paging mechanism to manage physical memory, that is, Linux divides physical memory into 4KB pages for management. What kind of data structure does Linux use to represent a page? In the early days, Linux used bitmap and later byte array, but now Linux defines a page structure to represent a page. The code is as follows.
struct page {
//The flag of the page structure, which determines the state of the page
unsigned long flags;
union {
struct {
//Mount the linked list of the parent structure
struct list_head lru;
//For file system, address_ The space structure describes which memory pages the file occupies
struct address_space *mapping;
pgoff_t index;
unsigned long private;
};
//Address of DMA device
struct {
dma_addr_t dma_addr;
};
//When a page is used for a memory object, it points to the relevant data structure
struct {
union {
struct list_head slab_list;
struct {
struct page *next;
#ifdef CONFIG_64BIT
int pages;
int pobjects;
#else
short int pages;
short int pobjects;
#endif
};
};
//Points to the structure kmem of the management SLAB_ cache
struct kmem_cache *slab_cache;
//The first object that points to the SLA
void *freelist;
union {
void *s_mem;
unsigned long counters;
struct {
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
};
//Used for fields related to page table mapping
struct {
unsigned long _pt_pad_1;
pgtable_t pmd_huge_pte;
unsigned long _pt_pad_2;
union {
struct mm_struct *pt_mm;
atomic_t pt_frag_refcount;
};
//Spin lock
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endif
};
//For device mapping
struct {
struct dev_pagemap *pgmap;
void *zone_device_data;
};
struct rcu_head rcu_head;
};
//Page reference count
atomic_t _refcount;
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
} _struct_page_alignment;
This page structure looks very huge and contains a lot of information, but it actually occupies very little memory. According to different Linux kernel configuration options, it occupies 20 ~ 40 bytes. The page structure uses a lot of C language Union Union Union to define the structure field. The size of the union should be determined according to the variable that occupies the largest memory in it.
It is not difficult to guess that in the process of use, the page structure indicates its state through flags, and uses the data information represented by the variables of the union consortium according to different states. If the page is idle, it will use the lru field in the Union Union to mount to the corresponding idle linked list.
A "page" is a barrier, but there is no Taishan. Here we don't need to know all the details of the page structure. We just need to know that in the Linux kernel, a page structure represents a physical memory page.
How to represent an area
The Linux kernel also has the logical concept of a zone. Due to the limitation of hardware, the Linux kernel cannot treat all physical memory pages uniformly, so the physical memory pages with the same attributes are attributed to a zone.
Different hardware platforms have different partitions. For example, in the 32-bit x86 platform, some devices using DMA can only access 0~16MB of physical space, so 0~16MB is divided into DMA areas.
High memory area is applicable to the case that the physical address space to be accessed is larger than the virtual address space, and the Linux kernel cannot establish direct mapping. Apart from these two memory areas, the remaining pages in physical memory are divided into regular memory areas. Some platforms do not have DMA areas, while 64 bit x86 platforms do not have high memory areas.
In Linux, you can view the memory area on your machine. The instructions are shown in the figure below.
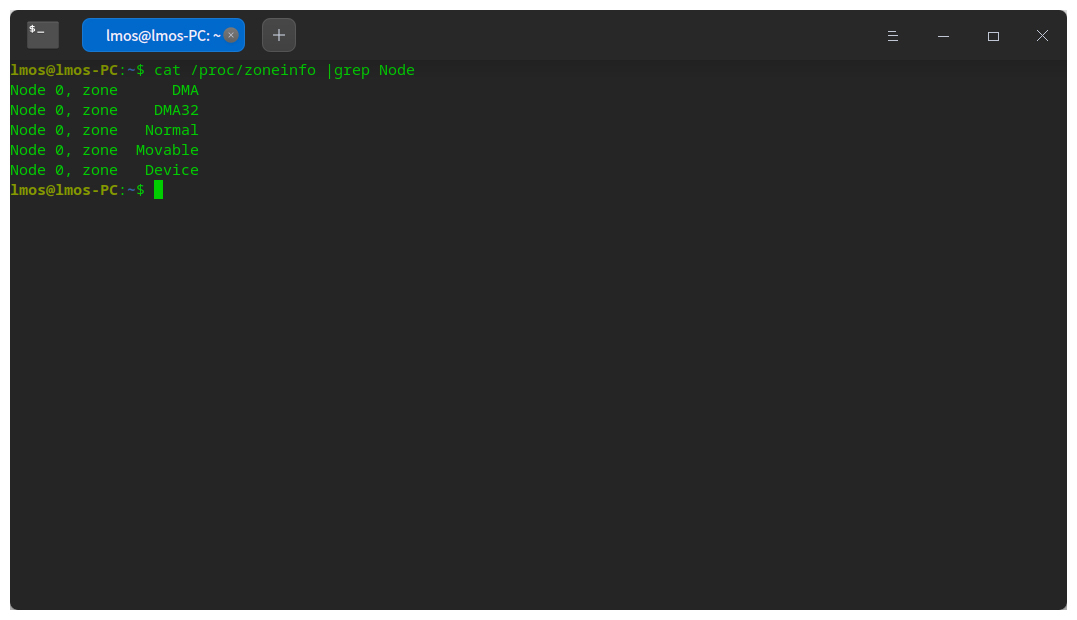
The Linux kernel uses the zone data structure to represent a zone, and the code is as follows.
enum migratetype {
MIGRATE_UNMOVABLE, //Immovable
MIGRATE_MOVABLE, //Movable and
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, //Belonging to pcp list
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
MIGRATE_CMA, //Belonging to CMA area
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE,
#endif
MIGRATE_TYPES
};
//Page idle chain header
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
struct zone {
unsigned long _watermark[NR_WMARK];
unsigned long watermark_boost;
//Number of memory pages reserved
unsigned long nr_reserved_highatomic;
//Which memory node does the memory area belong to
#ifdef CONFIG_NUMA
int node;
#endif
struct pglist_data *zone_pgdat;
//The start index of the page structure array at the beginning of the memory area
unsigned long zone_start_pfn;
atomic_long_t managed_pages;
//Total number of pages in memory area
unsigned long spanned_pages;
//Number of pages in memory area
unsigned long present_pages;
//Memory area name
const char *name;
//Linked list of page structure of Mount page
struct free_area free_area[MAX_ORDER];
//Flag of memory area
unsigned long flags;
/*Protect free_ Spin lock of area*/
spinlock_t lock;
};
In order to save your time, I only listed the fields that need our attention. Among them_ watermark indicates that the water mark of the total number of memory pages has three states: min, low and high, which can be used as the judgment standard for starting memory page recycling. spanned_pages is the total number of pages in the memory area.
Why have a present_ Does the pages field mean that the page really exists? That is because there are memory holes in some memory areas, and the page structure corresponding to the holes cannot be used. You can make a comparison. Our Cosmos does not create msadsc for memory holes_ t. Avoid wasting memory.
In the zone structure, what we really want to focus on is free_ An array of area structure, which is used to implement the partner system. Where Max_ The default value of order is 11, which indicates that the number of page structures with continuous mounting addresses is 1, 2, 4, 8, 16, 32... And the maximum is 1024.
And free_ There is another list in the area structure_ Head linked list array, which groups page structures with the same migration type as much as possible. Some pages can be migrated and some cannot be migrated. All page structures of the same order of the same type form a group of page structure blocks.
During allocation, it will first find the corresponding page structure block according to the requested migratetype. If it is unsuccessful, it will be allocated from the page structure block of other migratetypes. This is to make memory page migration more efficient and reduce memory fragmentation.
There is also a pointer in the zone structure to pglist_data structure, which is also very important. Let's study it together.
How to represent a memory node
Before understanding the data structure of Linux memory nodes, we should first understand NUMA. On many servers and mainframe computers, if the physical memory is distributed and composed of multiple computing nodes, each CPU core will have its own local memory. The CPU accesses its local memory faster and accesses the memory of other CPU cores slower. This architecture is called non uniform memory access (NUMA). The logic is shown in the figure below.
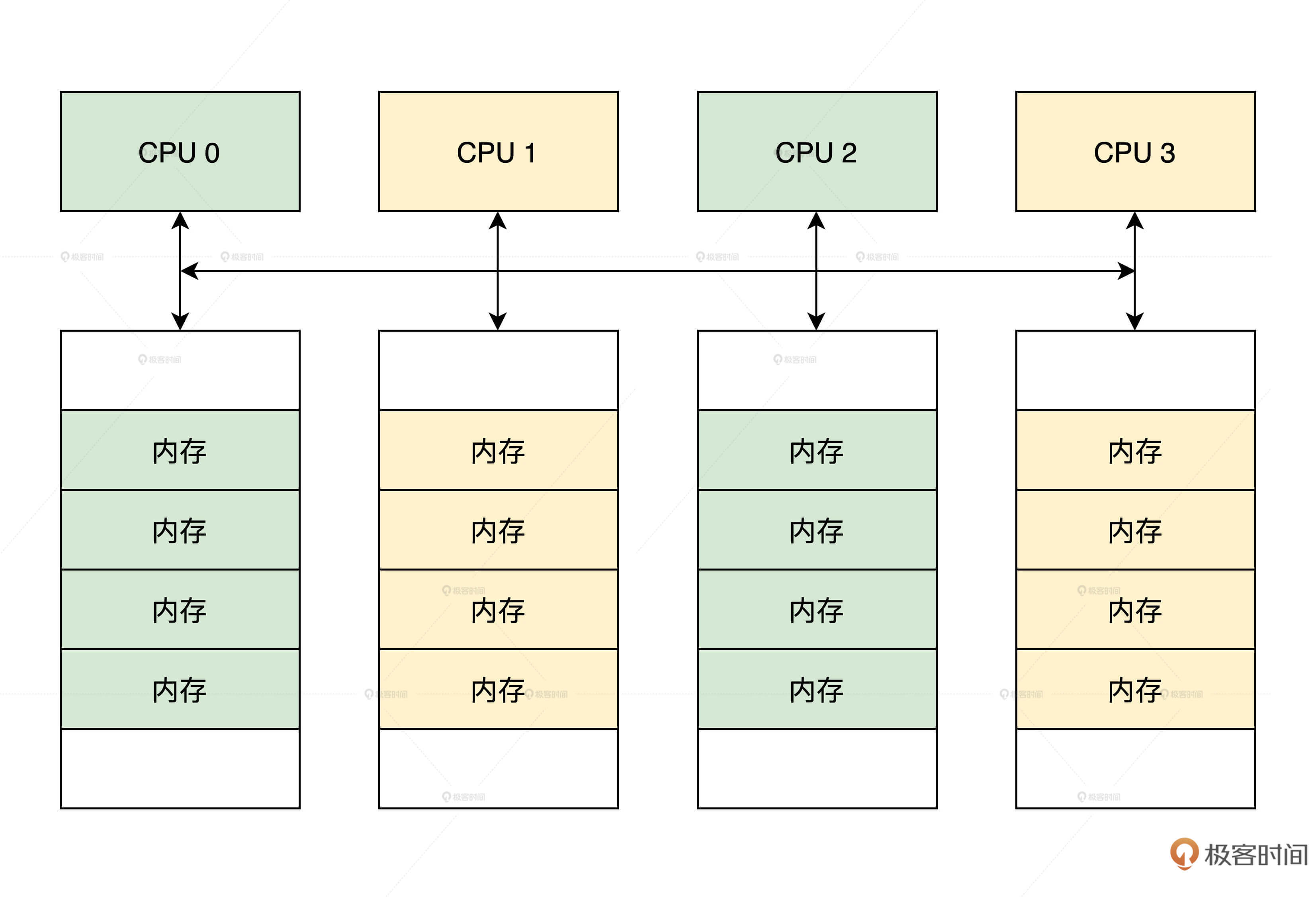
Linux abstracts NUMA. It can divide a whole block of continuous physical memory into several memory nodes, or treat non continuous physical memory as real NUMA. So what data structure does Linux use to represent a memory node? Look at the code, as shown below.
enum {
ZONELIST_FALLBACK,
#ifdef CONFIG_NUMA
ZONELIST_NOFALLBACK,
#endif
MAX_ZONELISTS
};
struct zoneref {
struct zone *zone;//Memory area pointer
int zone_idx; //Index corresponding to memory area
};
struct zonelist {
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
};
//The zone enumeration type starts at 0
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
//Define MAX_NR_ZONES is__ MAX_NR_ZONES max. 6
DEFINE(MAX_NR_ZONES, __MAX_NR_ZONES);
//Memory node
typedef struct pglist_data {
//Set a memory area array with a maximum of 6 zone elements
struct zone node_zones[MAX_NR_ZONES];
//Two zonelist s, one pointing to the memory area of the node, and the other pointing to the optional standby memory area when the node cannot allocate memory.
struct zonelist node_zonelists[MAX_ZONELISTS];
//How many memory areas does this node have
int nr_zones;
//page index number at the beginning of this node
unsigned long node_start_pfn;
//How many pages are available in this node
unsigned long node_present_pages;
//How many available pages in this node contain memory holes
unsigned long node_spanned_pages;
//Node id
int node_id;
//Swap memory page related fields
wait_queue_head_t kswapd_wait;
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd;
//Memory pages reserved by this node
unsigned long totalreserve_pages;
//Spin lock
spinlock_t lru_lock;
} pg_data_t;
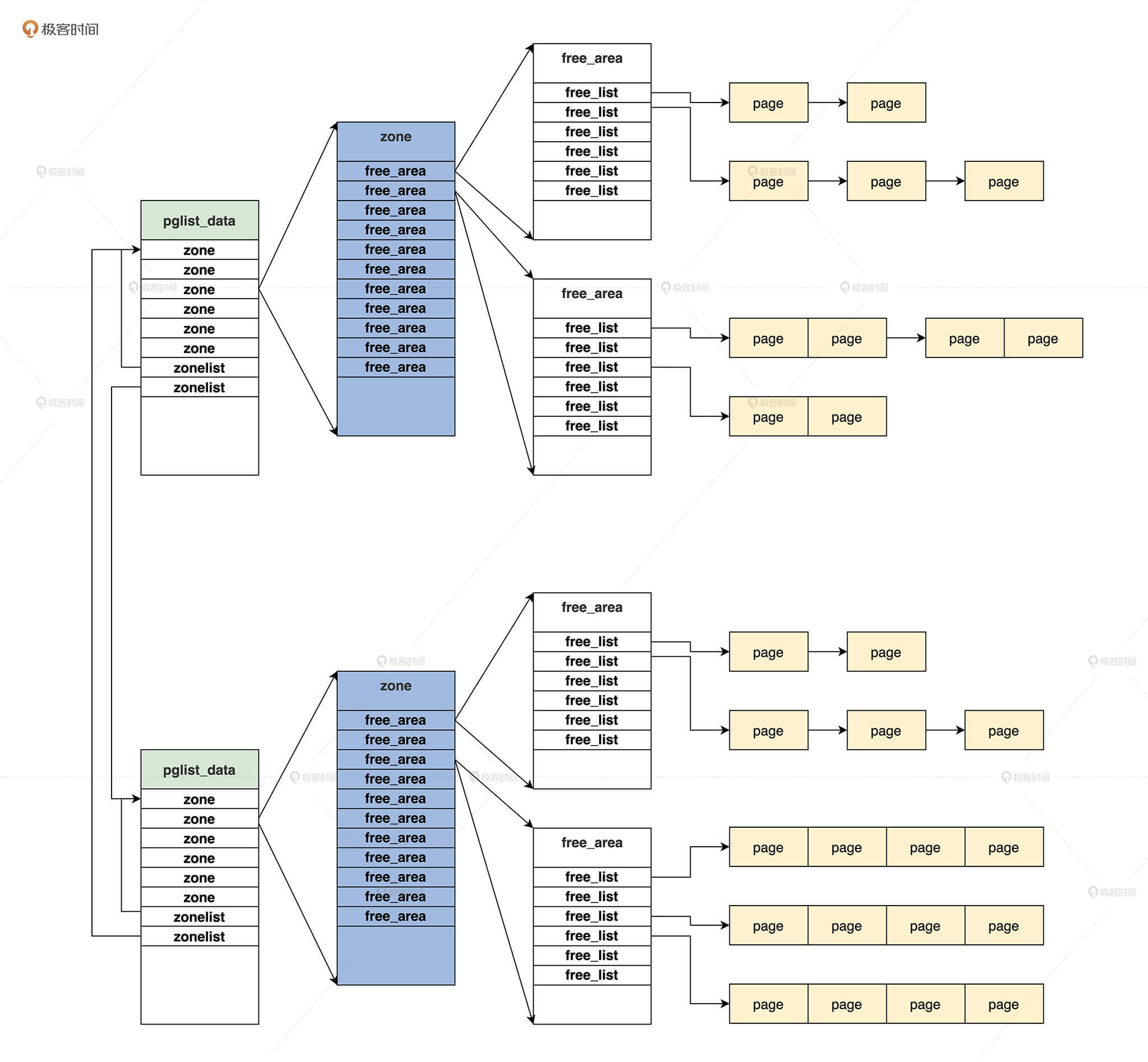
As you can see, pglist_ The data structure contains a zonelist array. The first element of zonelist type points to the zone array in this node, the second element of zonelist type points to the zone array of other nodes, and free in a zone structure_ The page structure is mounted in the area array. In this way, when memory pages cannot be allocated in this node, memory pages will be allocated in other nodes. When the computer is not NUMA, Linux creates only one node.
Relationship between data structures
Now we know pglist_data, zonelist, zone and page are the core contents of these data structures. With these necessary knowledge accumulation, I will take you to sort out the relationship between these structures from a macro perspective. Only by understanding the relationship between them can you understand the implementation of the core algorithm of the partner system. According to the previous description, let's draw a picture.
What is a partner
In Linux physical memory page management, continuous pages of the same size can be represented as partners. For example, page 0 and page 1 are partners, but they are not partners with page 2, and page 2 and page 3 are partners. At the same time, the 0th page and the 1st page are connected as a whole page, which is connected with the 2nd page and the 3rd page as a whole page. They are partners, and so on. Let's draw a picture, as shown below.
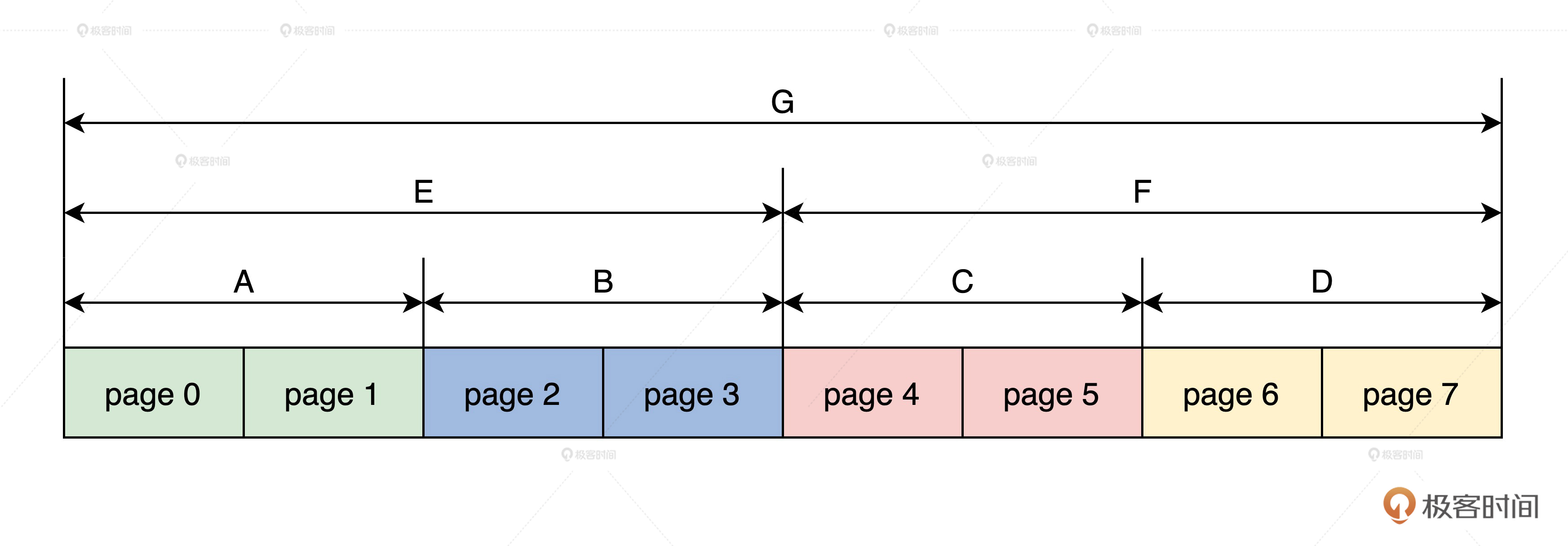
In the above figure, the smallest page (0,1) is A partner, page (2,3) is A partner, page (4,5) is A partner, page (6,7) is A partner, then A and B are partners, C and D are partners, and finally E and F are partners.
Allocation page
Next, we begin to study how to allocate physical memory pages under Linux. We have seen the previous data structures and the relationship between them. The process of allocating physical memory pages is very reasoning: first, find the memory node, then find the memory area, then find the appropriate free linked list, and finally find the page structure of the page to complete the allocation of physical memory pages.
Find the memory node through the interface
Let's first understand the interface for allocating memory pages. I use a diagram to represent the interfaces and their calling relationship. I believe that diagrams are the best way to understand interface functions, as shown below.
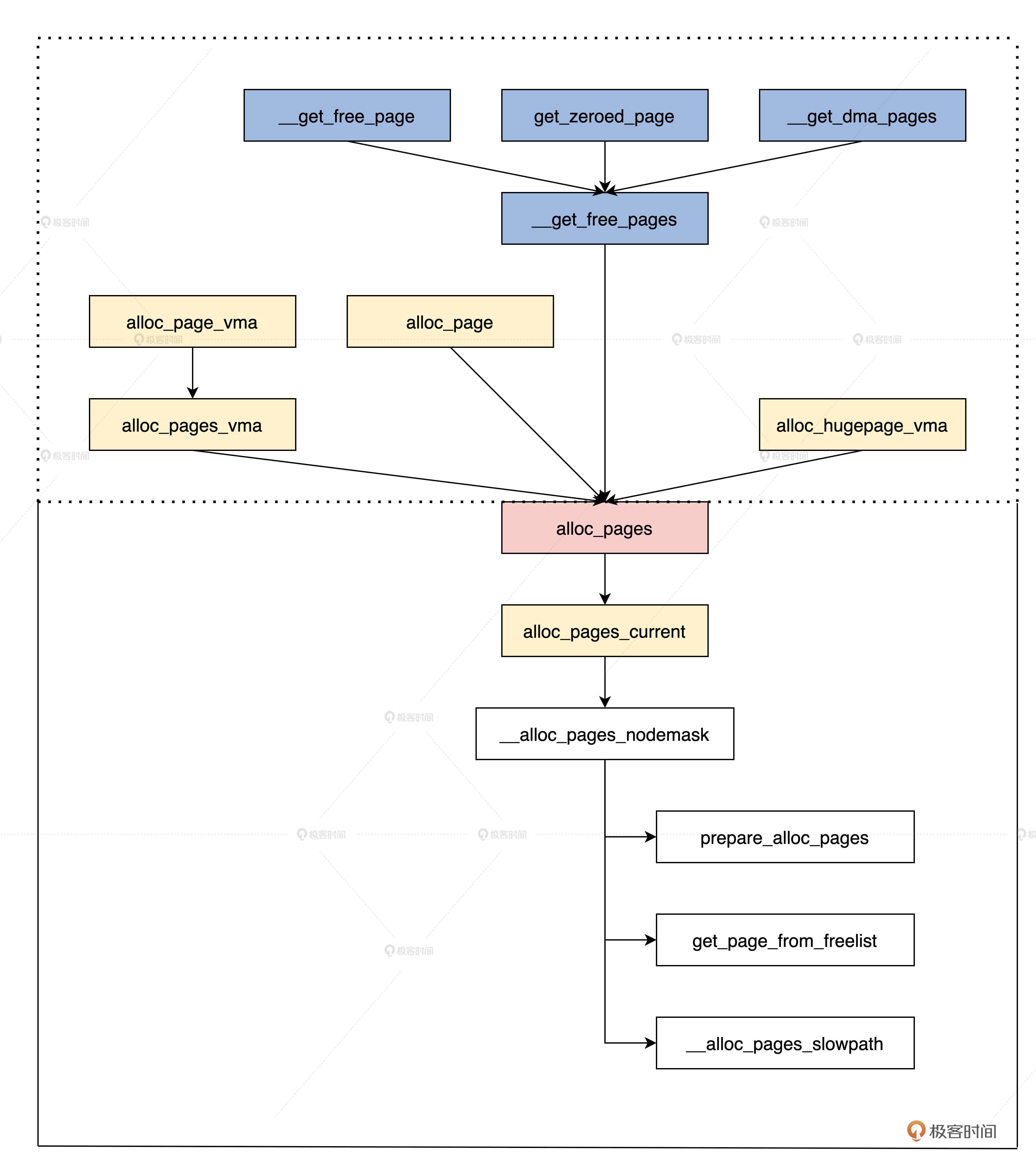
In the figure above, the dashed box is the interface function, and the following is the core implementation of the memory allocation page. All interface functions will be called to alloc_pages function, which will eventually call__ alloc_pages_ The nodemask function allocates memory pages. Let's take a look at alloc_ In the form of pages function, the code is as follows.
struct page *alloc_pages_current(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;
struct page *page;
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));
else
page = __alloc_pages_nodemask(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;
}
static inline struct page * alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
We don't need to focus on alloc here_ pages_ Other details of the current function, as long as you know that it will eventually be called__ alloc_pages_nodemask function, and we also need to find out its parameters. Order is well understood. It means that the request is to allocate 2 pages to the power of order, focusing on GFP_ GFP of type T_ mask. gfp_ The types and values of mask are as follows.
typedef unsigned int __bitwise gfp_t; #define ___GFP_DMA 0x01u #define ___GFP_HIGHMEM 0x02u #define ___GFP_DMA32 0x04u #define ___GFP_MOVABLE 0x08u #define ___GFP_RECLAIMABLE 0x10u #define ___GFP_HIGH 0x20u #define ___GFP_IO 0x40u #define ___GFP_FS 0x80u #define ___GFP_ZERO 0x100u #define ___GFP_ATOMIC 0x200u #define ___GFP_DIRECT_RECLAIM 0x400u #define ___GFP_KSWAPD_RECLAIM 0x800u #define ___GFP_WRITE 0x1000u #define ___GFP_NOWARN 0x2000u #define ___GFP_RETRY_MAYFAIL 0x4000u #define ___GFP_NOFAIL 0x8000u #define ___GFP_NORETRY 0x10000u #define ___GFP_MEMALLOC 0x20000u #define ___GFP_COMP 0x40000u #define ___GFP_NOMEMALLOC 0x80000u #define ___GFP_HARDWALL 0x100000u #define ___GFP_THISNODE 0x200000u #define ___GFP_ACCOUNT 0x400000u //Atomic allocation of memory is required and the requester must not go to sleep #define GFP_ATOMIC (__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM) //Allocate memory for the kernel's own use, and there can be IO and file system related operations #define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS) #define GFP_KERNEL_ACCOUNT (GFP_KERNEL | __GFP_ACCOUNT) //Allocated memory cannot sleep, and there cannot be I/O and file system related operations #define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM) #define GFP_NOIO (__GFP_RECLAIM) #define GFP_NOFS (__GFP_RECLAIM | __GFP_IO) //Allocate memory for user processes #define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL) //Memory for DMA devices #define GFP_DMA __GFP_DMA #define GFP_DMA32 __GFP_DMA32 //Allocate the memory of the high-end memory area to the user process #define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM) #define GFP_HIGHUSER_MOVABLE (GFP_HIGHUSER | __GFP_MOVABLE) #define GFP_TRANSHUGE_LIGHT ((GFP_HIGHUSER_MOVABLE | __GFP_COMP | \__GFP_NOMEMALLOC | __GFP_NOWARN) & ~__GFP_RECLAIM) #define GFP_TRANSHUGE (GFP_TRANSHUGE_LIGHT | __GFP_DIRECT_RECLAIM)
Not hard to find, gfp_t type is an int type. The state of its middle bit indicates the memory pages requesting to allocate different memory areas and the different ways of allocating memory pages.
Start allocation
We have made clear the parameters of the memory page allocation interface. Now let's enter the main function of the memory allocation page, this__ alloc_ pages_ The nodemask function mainly does three things.
-
Prepare the parameters of the allocation page;
-
Enter the fast allocation path;
-
If the fast allocation path is not allocated to the page, enter the slow allocation path.
struct page *__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask) { struct page *page; unsigned int alloc_flags = ALLOC_WMARK_LOW; gfp_t alloc_mask; struct alloc_context ac = { }; //If the order of the allocation page is greater than or equal to the maximum order, NULL will be returned directly if (unlikely(order >= MAX_ORDER)) { WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN)); return NULL; } gfp_mask &= gfp_allowed_mask; alloc_mask = gfp_mask; //The parameters of the ready allocation page are placed in the ac variable if (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask, &ac, &alloc_mask, &alloc_flags)) return NULL; alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp_mask); //Enter fast allocation path page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac); if (likely(page)) goto out; alloc_mask = current_gfp_context(gfp_mask); ac.spread_dirty_pages = false; ac.nodemask = nodemask; //Enter slow allocation path page = __alloc_pages_slowpath(alloc_mask, order, &ac); out: return page; }
Prepare parameters for allocation page
I think you are__ alloc_ pages_ In the nodemask function, you must see that the variable ac is alloc_context type, as the name suggests, the allocation parameters are saved in the variable of ac this allocation context. prepare_ alloc_ The pages function will further process the ac variable according to the parameters passed in. The code is as follows.
struct alloc_context {
struct zonelist *zonelist;
nodemask_t *nodemask;
struct zoneref *preferred_zoneref;
int migratetype;
enum zone_type highest_zoneidx;
bool spread_dirty_pages;
};
static inline bool prepare_alloc_pages(gfp_t gfp_mask, unsigned int order,
int preferred_nid, nodemask_t *nodemask,
struct alloc_context *ac, gfp_t *alloc_mask,
unsigned int *alloc_flags)
{
//From which memory area is memory allocated
ac->highest_zoneidx = gfp_zone(gfp_mask);
//Calculate the pointer of the zone according to the node id
ac->zonelist = node_zonelist(preferred_nid, gfp_mask);
ac->nodemask = nodemask;
//Calculate free_ The migratetype value in area. For example, the assigned mask is GFP_KERNEL, then its type is MIGRATE_UNMOVABLE;
ac->migratetype = gfp_migratetype(gfp_mask);
//Handling CMA related allocation options
*alloc_flags = current_alloc_flags(gfp_mask, *alloc_flags);
ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE);
//Search the available zones in the node represented by nodemask and save them in preferred_zoneref
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->highest_zoneidx, ac->nodemask);
return true;
}
As you can see, prepare_ alloc_ According to the parameters passed in, the pages function can find out the migratetype types of the memory area to be allocated, the candidate memory area and the empty free linked list of the memory area. It collects all these into the ac structure. As long as it returns true, it indicates that the parameters of the allocated memory page are ready.
Fast allocation path
In order to optimize the allocation performance of memory pages, you can enter the fast allocation path under certain circumstances. Please note that the fast allocation path will not deal with memory page merging and recycling. Let's take a look at the code, as shown below.
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z;
struct zone *zone;
struct pglist_data *last_pgdat_dirty_limit = NULL;
bool no_fallback;
retry:
no_fallback = alloc_flags & ALLOC_NOFRAGMENT;
z = ac->preferred_zoneref;
//Traversal AC - > preferred_ Each memory area in zoneref
for_next_zone_zonelist_nodemask(zone, z, ac->highest_zoneidx,
ac->nodemask) {
struct page *page;
unsigned long mark;
//View memory watermark
mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);
//Check whether the free memory in the memory area is above the watermark
if (!zone_watermark_fast(zone, order, mark,
ac->highest_zoneidx, alloc_flags,
gfp_mask)) {
int ret;
//Does the memory node of the current memory area need to recycle memory
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
switch (ret) {
//The fast allocation path does not handle the problem of page recycling
case NODE_RECLAIM_NOSCAN:
continue;
case NODE_RECLAIM_FULL:
continue;
default:
//Judge whether the water mark of the memory area meets the requirements according to the number of allocated order s
if (zone_watermark_ok(zone, order, mark,
ac->highest_zoneidx, alloc_flags))
//If you can, you can allocate from this memory area
goto try_this_zone;
continue;
}
}
try_this_zone:
//Really allocate memory pages
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
//Clear some flags or set union pages, etc
prep_new_page(page, order, gfp_mask, alloc_flags);
return page;
}
}
if (no_fallback) {
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
return NULL;
}
The logic of this function is to traverse all candidate memory areas, and then check the water mark for each memory area to see if the memory recycling mechanism is executed. When all the checks pass, it starts to call the rmqueue function to allocate memory pages.
Slow allocation path
When the fast allocation path is not allocated to the page, it will enter the slow allocation path. Compared with the fast path, the main difference of the slow path is that it will perform page recycling. After recycling the page, it will be repeatedly allocated until it is finally allocated to the memory page, or the allocation fails. The specific code is as follows.
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM;
const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER;
struct page *page = NULL;
unsigned int alloc_flags;
unsigned long did_some_progress;
enum compact_priority compact_priority;
enum compact_result compact_result;
int compaction_retries;
int no_progress_loops;
unsigned int cpuset_mems_cookie;
int reserve_flags;
retry:
//Wake up all threads that swap memory
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
//Still call the fast allocation path entry function to try to allocate memory pages
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
//Try reclaiming memory directly and reallocating memory pages
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
if (page)
goto got_pg;
//Try to compress memory directly and reallocate memory pages
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
//Check whether it makes sense to retry recycling for a given allocation request
if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags,
did_some_progress > 0, &no_progress_loops))
goto retry;
//Check whether it makes sense to retry compression for a given allocation request
if (did_some_progress > 0 &&
should_compact_retry(ac, order, alloc_flags,
compact_result, &compact_priority,
&compaction_retries))
goto retry;
//Reclaiming and compressing memory has failed. Start trying to kill the process and reclaim memory pages
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
got_pg:
return page;
}
In the above code, the quick allocation path entry function will still be called for allocation. However, the allocation will probably fail here. If the allocation can be successful, it will not enter the__ alloc_ pages_ In the slowpath function__ alloc_ pages_ The slowpath function initially wakes up all threads used for memory exchange recovery_ page_ from_ If the freelist function fails to allocate, memory recycling will be performed. Memory recycling is mainly to release the memory pages occupied by some files. If memory recycling fails, it will enter the memory compression phase.
There is a common misunderstanding here. You should note that memory compression does not mean compressing data in memory, but moving memory pages and defragmenting memory to free up more continuous memory space. If memory defragmentation fails to allocate memory successfully, the process will be killed to free more memory pages. Because the mechanism of memory recycling is not the focus, we mainly focus on the implementation of partner systems. Here, you just need to understand their workflow.
How to allocate memory pages
Regardless of the fast allocation path or the slow allocation path, the final execution of the memory page allocation action is always get_page_from_freelist function, more precisely, the rmqueue function actually completes the assigned task. Only when we understand this function can we really understand the core principle of the partner system. The following paragraph is its code.
static inline struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
{
unsigned long flags;
struct page *page;
if (likely(order == 0)) {
if (!IS_ENABLED(CONFIG_CMA) || alloc_flags & ALLOC_CMA ||
migratetype != MIGRATE_MOVABLE) {
//If order equals 0, it means that a page is allocated, that is, it is allocated from pcplist
page = rmqueue_pcplist(preferred_zone, zone, gfp_flags,
migratetype, alloc_flags);
goto out;
}
}
//Lock and close interrupt
spin_lock_irqsave(&zone->lock, flags);
do {
page = NULL;
if (order > 0 && alloc_flags & ALLOC_HARDER) {
//From free_ Allocation in area
page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);
}
if (!page)
//It is also called in the end__ rmqueue_smallest function
page = __rmqueue(zone, order, migratetype, alloc_flags);
} while (page && check_new_pages(page, order));
spin_unlock(&zone->lock);
zone_statistics(preferred_zone, zone);
local_irq_restore(flags);
out:
return page;
}
In this code, we only need to focus on the two functions rmqueue_pcplist and__ rmqueue_smallest, which is the core function for allocating memory pages.
Let's take a look at rmqueue first_ The pcplist function is used to allocate pages from pcplist when requesting to allocate a page. The so-called pcp means that each CPU has a memory page cache, which is composed of data structures_ cpu_ Pageset description, contained in the memory area.
In the Linux kernel, the system often requests and releases a single page. If a linked list with a single memory page allocated in advance is established for each CPU to meet the single memory request sent by the local CPU, the system performance can be improved. The code is as follows.
struct per_cpu_pages {
int count; //Number of pages in the list
int high; //The number of pages is higher than the water mark and needs to be cleared
int batch; //Number of blocks added / deleted from partner system
//Page list, one for each migration type.
struct list_head lists[MIGRATE_PCPTYPES];
};
struct per_cpu_pageset {
struct per_cpu_pages pcp;
#ifdef CONFIG_NUMA
s8 expire;
u16 vm_numa_stat_diff[NR_VM_NUMA_STAT_ITEMS];
#endif
#ifdef CONFIG_SMP
s8 stat_threshold;
s8 vm_stat_diff[NR_VM_ZONE_STAT_ITEMS];
#endif
};
static struct page *__rmqueue_pcplist(struct zone *zone, int migratetype,unsigned int alloc_flags,struct per_cpu_pages *pcp,
struct list_head *list)
{
struct page *page;
do {
if (list_empty(list)) {
//If the list is empty, allocate some pages from this memory area to pcp
pcp->count += rmqueue_bulk(zone, 0,
pcp->batch, list,
migratetype, alloc_flags);
if (unlikely(list_empty(list)))
return NULL;
}
//Get the first page structure on the list
page = list_first_entry(list, struct page, lru);
//Off chain
list_del(&page->lru);
//Reduce pcp page count
pcp->count--;
} while (check_new_pcp(page));
return page;
}
static struct page *rmqueue_pcplist(struct zone *preferred_zone,
struct zone *zone, gfp_t gfp_flags,int migratetype, unsigned int alloc_flags)
{
struct per_cpu_pages *pcp;
struct list_head *list;
struct page *page;
unsigned long flags;
//Off interrupt
local_irq_save(flags);
//Get pcp under current CPU
pcp = &this_cpu_ptr(zone->pageset)->pcp;
//Get the list list migrated under pcp
list = &pcp->lists[migratetype];
//Extract the page structure on the list
page = __rmqueue_pcplist(zone, migratetype, alloc_flags, pcp, list);
//Open interrupt
local_irq_restore(flags);
return page;
}
The comments of the above code are clear. It mainly optimizes the performance of requesting to allocate a single memory page. However, when multiple memory page allocation requests are encountered, the__ rmqueue_smallest function, from free_area array. Let's have a look__ rmqueue_ Code for the smallest function.
static inline struct page *get_page_from_free_area(struct free_area *area,int migratetype)
{//Return to free_ The first page in list [migratetype] returns NULL if it does not exist
return list_first_entry_or_null(&area->free_list[migratetype],
struct page, lru);
}
static inline void del_page_from_free_list(struct page *page, struct zone *zone,unsigned int order)
{
if (page_reported(page))
__ClearPageReported(page);
//Off chain
list_del(&page->lru);
//Clear the flag of partner system in page
__ClearPageBuddy(page);
set_page_private(page, 0);
//Reduce free_ Page count in area
zone->free_area[order].nr_free--;
}
static inline void add_to_free_list(struct page *page, struct zone *zone,
unsigned int order, int migratetype)
{
struct free_area *area = &zone->free_area[order];
//Add the first page of a group of pages to the corresponding free_ In area
list_add(&page->lru, &area->free_list[migratetype]);
area->nr_free++;
}
//Split a set of pages
static inline void expand(struct zone *zone, struct page *page,
int low, int high, int migratetype)
{
//The number of consecutive page s under the highest order, such as high = 3 and size = 8
unsigned long size = 1 << high;
while (high > low) {
high--;
size >>= 1;//Shift left one bit each cycle 4,2,1
//Marked as a protected page that allows merging when its partners are released
if (set_page_guard(zone, &page[size], high, migratetype))
continue;
//Add the other half of the pages to the corresponding free_ In area
add_to_free_list(&page[size], zone, high, migratetype);
//Set partner
set_buddy_order(&page[size], high);
}
}
static __always_inline struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
//Get current_ Free corresponding to order_ area
area = &(zone->free_area[current_order]);
//Get free_ Free with corresponding migratetype as subscript in area_ page in list
page = get_page_from_free_area(area, migratetype);
if (!page)
continue;
//Off chain page
del_page_from_free_list(page, zone, current_order);
//Split partner
expand(zone, page, order, current_order, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
}
As you can see, in__ rmqueue_ In the smallest function, first obtain current_ Free corresponding to order_ If there is no page in the area area, continue to add current_order up to MAX_ORDER. If you get a set of consecutive page's first addresses, you can detaching them from the chain, then call the expand function to split the partners. It can be said that the expand function is the core of the partner algorithm. Combined with the notes, have you found that it is somewhat similar to our Cosmos physical memory allocation algorithm?
Key review
First, we learned the data structure of the partner system. We started from the page. Linux uses the page structure to represent a physical memory page, and then defines the memory area zone on the upper layer of the page, which is for different address space allocation requirements. Then Linux defines the node pglist in order to support the computer of NUMA system_ Data, each node contains multiple zones. We have clarified the relationship between these data structures together.
Then, we go to the allocation page. In order to understand the principle of memory allocation of the partner system, we study the allocation interface of the partner system, and then focus on its fast allocation path and slow allocation path.
Only after the fast allocation path fails, will it enter the slow allocation path, and the work related to memory recovery will be carried out in the slow allocation path. Finally, we learned how the expand function divides partners to complete page allocation.