Stream is a new key abstraction in Java SE 8 class library. It is defined in Java util. Stream (there are several stream types in this package: stream < T > represents object reference stream. In addition, there are a series of specialized streams, such as IntStream, LongStream, DoubleStream, etc.
The Stream introduced by Java 8 is mainly used to replace some Collection operations. Each Stream represents a value sequence. The Stream provides a series of common aggregation operations, which can be used for various operations conveniently. The Collection class library also provides a convenient way for us to use collections, arrays and other data structures in the way of operation flow;
Operation type of stream
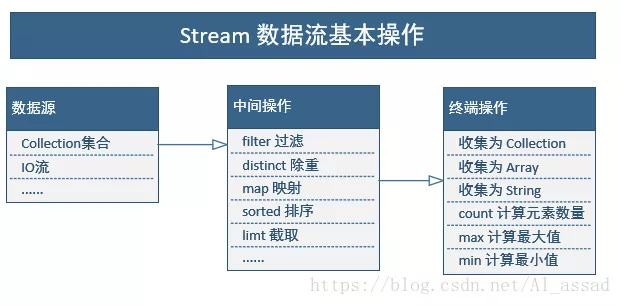
① Intermediate operation
- When the data in the data source is pipelined, all operations on the data in this process are called "intermediate operations";
- Intermediate operations will still return a stream object, so multiple intermediate operations can be connected in series to form a pipeline;
- stream provides various types of intermediate operations, such as filter, distinct, map, sorted, etc;
② Terminal operation
- When all intermediate operations are completed, if you want to take the data off the pipeline, you need to perform terminal operations;
- For terminal operation, stream can directly provide the result of an intermediate operation, or convert the result into a specific collection, array, String, etc;
Characteristics of stream
① You can only traverse once:
The of the data stream is to obtain the data source from one end and operate the elements successively on the pipeline. When the elements pass through the pipeline, they can no longer operate on them. You can obtain a new data stream from the data source for operation again;
② Internal iteration is adopted:
Generally, the Iterator traversal method is used to process the Collection, which is an external iteration;
For processing Stream, as long as the processing method is stated, the processing process is completed by the Stream object itself. This is an internal iteration. For the iterative processing of a large amount of data, the internal iteration is more efficient than the external iteration;
Advantages of stream over Collection
- No storage: the stream does not store values; The elements of the stream come from the data source (may be a data structure, generating function or I/O channel, etc.) and are obtained through a series of calculation steps;
- Functional style: the operation of convection will produce a result, but the data source of the stream will not be modified;
- Lazy evaluation: most flow operations (including filtering, mapping, sorting, and de duplication) can be implemented in an inert manner. This allows us to complete the whole pipeline operation with one-time traversal, and provide a more efficient implementation with short-circuit operation;
- No upper bound: many problems can be expressed as infinite stream: the user keeps reading the stream until a satisfactory result appears (for example, the operation of enumerating perfect numbers can be expressed as filtering on all integers); The set is limited, but the stream can be expressed as a wireless stream;
- Concise code: for some collection iterative processing operations, using stream can be very concise. If using traditional collection iterative operations, the code may be very verbose and the readability will be poor;
Comparison of iteration efficiency between stream and iterator
Well, there are so many advantages of the above stream, and the writing method of stream function is very comfortable. How about the efficiency of stream?
Let's start with the conclusion:
- The performance is higher than that of traditional jd8-loop, especially in the case of small amount of iterative data;
-In the multi-core scenario, for the processing of large amount of data, parallel stream can have higher iterative processing efficiency than iterator;
In the scenario of mapping, filtering, sorting, protocol statistics and string conversion of a random number sequence List (the number is from 10 to 10000000), I made statistics on the operation efficiency realized by stream and iterator, tested the code benchmark and tested the code link
The test environment is as follows:
System: Ubuntu 16.04 xenial
CPU: Intel Core i7-8550U
RAM: 16GB
JDK version: 1.8.0_151
JVM: HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
JVM Settings:
-Xms1024m
-Xmx6144m
-XX:MaxMetaspaceSize=512m
-XX:ReservedCodeCacheSize=1024m
-XX:+UseConcMarkSweepGC
-XX:SoftRefLRUPolicyMSPerMB=1001. Mapping processing test
After each element in a random sequence (list < integer >) is increased by 1, it is reassembled into a new list < integer >, the capacity of the tested random sequence is 10 - 10000000, and the average time is taken for 10 runs;
//stream
List<Integer> result = list.stream()
.mapToInt(x -> x)
.map(x -> ++x)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
List<Integer> result = new ArrayList<>();
for(Integer e : list){
result.add(++e);
}
//parallel stream
List<Integer> result = list.parallelStream()
.mapToInt(x -> x)
.map(x -> ++x)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));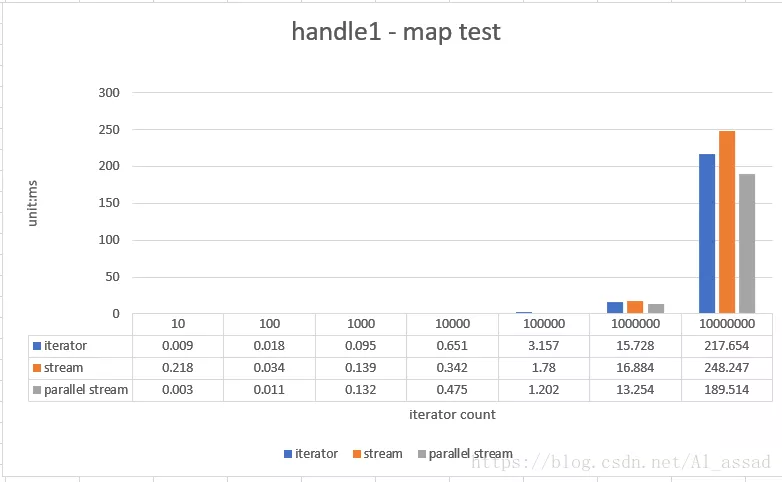
2. Filter treatment test
Take out the elements greater than 200 in a random number sequence (list < integer >) and assemble it into a new list < integer >. The capacity of the tested random number sequence ranges from 10 - 10000000, run 10 times and take the average time;
//stream
List<Integer> result = list.stream()
.mapToInt(x -> x)
.filter(x -> x > 200)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
List<Integer> result = new ArrayList<>(list.size());
for(Integer e : list){
if(e > 200){
result.add(e);
}
}
//parallel stream
List<Integer> result = list.parallelStream()
.mapToInt(x -> x)
.filter(x -> x > 200)
.boxed()
.collect(Collectors.toCollection(ArrayList::new));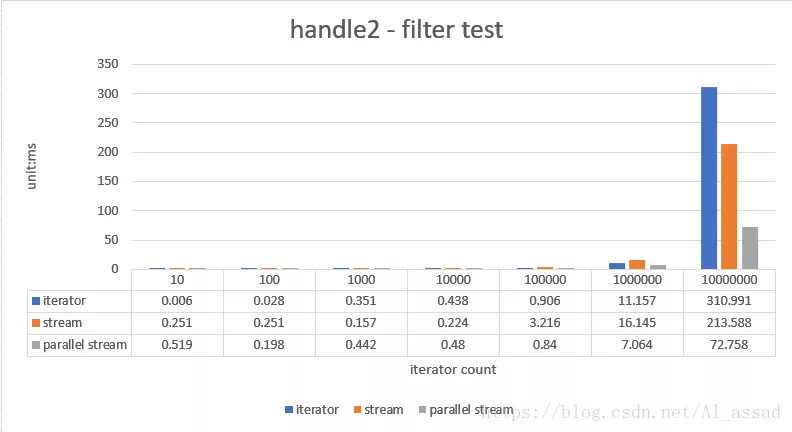
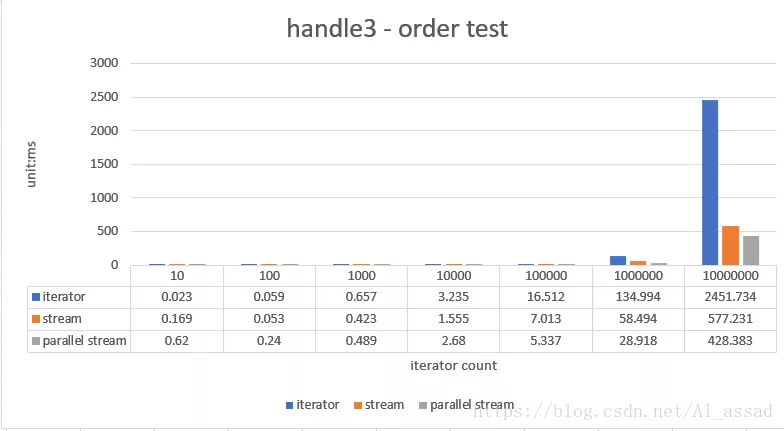
3. Natural sorting test
Naturally sort a random sequence (list < integer >) and assemble it into a new list < integer >. The iterator uses the Collections # sort API (implemented by merging sorting algorithm). The capacity of the tested random sequence ranges from 10 - 10000000, and the average time is taken for 10 runs;
//stream List<Integer> result = list.stream() .mapToInt(x->x) .sorted() .boxed() .collect(Collectors.toCollection(ArrayList::new)); //iterator List<Integer> result = new ArrayList<>(list); Collections.sort(result); //parallel stream List<Integer> result = list.parallelStream() .mapToInt(x->x) .sorted() .boxed() .collect(Collectors.toCollection(ArrayList::new));
4. Reduction statistical test
Obtain the maximum value of a random sequence (list < integer >), the capacity of the tested random sequence ranges from 10 - 10000000, and run 10 times to take the average time;
//stream
int max = list.stream()
.mapToInt(x -> x)
.max()
.getAsInt();
//iterator
int max = -1;
for(Integer e : list){
if(e > max){
max = e;
}
}
//parallel stream
int max = list.parallelStream()
.mapToInt(x -> x)
.max()
.getAsInt();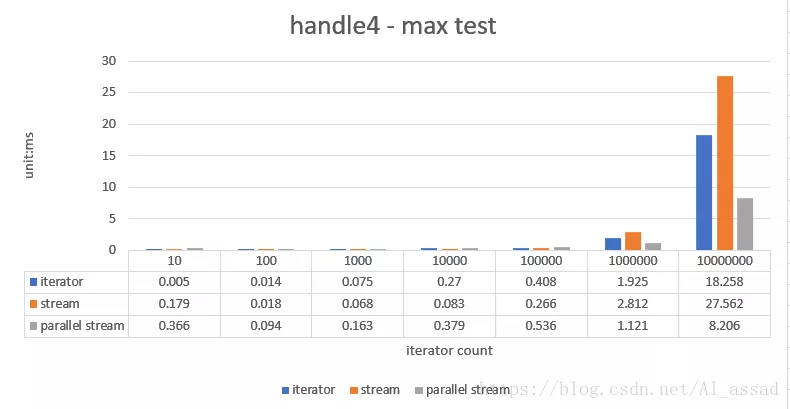
5. String splicing test
Obtain a string separated by "," for each element of a random sequence (list < integer >). The capacity of the tested random sequence ranges from 10 - 10000000, and the average time is taken for 10 runs;
//stream
String result = list.stream().map(String::valueOf).collect(Collectors.joining(","));
//iterator
StringBuilder builder = new StringBuilder();
for(Integer e : list){
builder.append(e).append(",");
}
String result = builder.length() == 0 ? "" : builder.substring(0,builder.length() - 1);
//parallel stream
String result = list.stream().map(String::valueOf).collect(Collectors.joining(","));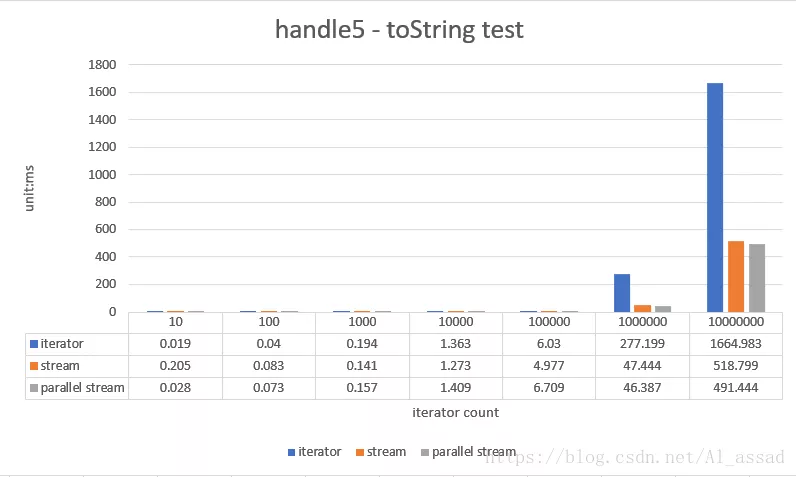
6. Mixed operation test
A random sequence (list < integer >) is de emptied, de duplicated, mapped, filtered, and assembled into a new list < integer >. The capacity of the tested random sequence ranges from 10 - 10000000, and the average time is taken for 10 runs;
//stream
List<Integer> result = list.stream()
.filter(Objects::nonNull)
.mapToInt(x -> x + 1)
.filter(x -> x > 200)
.distinct()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));
//iterator
HashSet<Integer> set = new HashSet<>(list.size());
for(Integer e : list){
if(e != null && e > 200){
set.add(e + 1);
}
}
List<Integer> result = new ArrayList<>(set);
//parallel stream
List<Integer> result = list.parallelStream()
.filter(Objects::nonNull)
.mapToInt(x -> x + 1)
.filter(x -> x > 200)
.distinct()
.boxed()
.collect(Collectors.toCollection(ArrayList::new));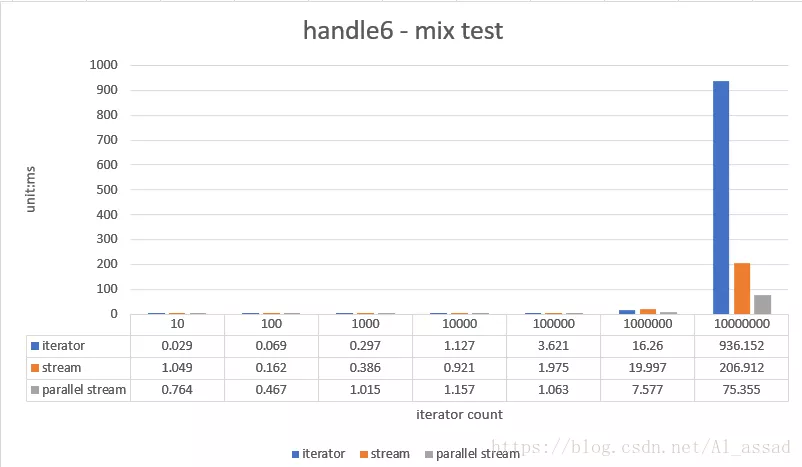
Summary of experimental results
From the above experiments, the following points can be summarized:
- In the processing scenario with a small amount of data (size < = 1000), the processing efficiency of stream is not as fast as that of the traditional iterator external iterator, but in fact, the running time of these processing tasks is less than milliseconds. This efficiency gap has little impact on ordinary business, but stream can make the code more concise;
- When there is a large amount of data (szie > 10000), the processing efficiency of stream is higher than that of iterator, especially when parallel stream is used. Under the condition that the cpu just allocates threads to multiple cores (of course, the ForkJoinPool of JVM is used at the bottom of parallel stream, which is very metaphysical in allocating threads itself), a very high operation efficiency can be achieved, However, the actual general business generally does not need to iterate more than 10000 times;
- Parallel Stream is greatly affected by the cited cpu environment. When it is not allocated to multiple cpu cores and the overhead of referencing forkJoinPool, the operation efficiency may not be as good as that of ordinary Stream;
Suggestions for using Stream
- For simple iterative logic, iterator can be used directly. For iterative logic with multi-step processing, stream can be used, which loses almost no efficiency and is worth the high readability of the code;
- For single core cpu environment, parallel stream is not recommended. Under the condition of multi-core cpu and large amount of data, parallel stream is recommended;
- The stream contains the packing type. Before intermediate operation, it is better to convert to the corresponding numerical flow to reduce the performance loss caused by frequent unpacking and packing;
Finally, I will pay attention to the official account Java technology stack, and reply in the background: interview can get my Java series interview questions and answers, which are very complete.
Original link: https://blog.csdn.net/Al_assad/article/details/82356606
Copyright notice: This article is the original article of CSDN blogger "Al_assad", which follows the CC 4.0 BY-SA copyright agreement. For reprint, please attach the original source link and this notice.
Recent hot article recommendations:
1.600 + Java interview questions and answers (2021 latest edition)
2.Finally got the IntelliJ IDEA activation code through the open source project. It's really fragrant!
3.Ali Mock tools are officially open source and kill all Mock tools on the market!
4.Spring Cloud 2020.0.0 is officially released, a new and subversive version!
5.Java development manual (Songshan version) is the latest release. Download it quickly!
Feel good, don't forget to like + forward!