What is BERT?
BERT (Bidirectional Encoder Representations from Transformers) provides cutting-edge results in various natural language processing tasks, causing a sensation in the deep learning community. Devlin et al. In 2018, BERT was developed in Google using English Wikipedia and BookCorpus. Since then, similar architectures have been modified and used in various NLP applications. XL.net is one of the examples based on BERT. It performs better than BERT on 20 different tasks. Before understanding the different models built based on BERT, we need to better understand Transformer and attention model.
The basic technical breakthrough of BERT is to use the Transformer and attention model of two-way training to perform language modeling. Compared with the early research on text sequences combined with left to right or two-way training, the findings of BERT paper show that the language model of two-way training can better understand the language context.
BERT uses the attention mechanism and the transformer to learn the contextual relationship between words. Transformer consists of two independent parts - encoder and decoder. The encoder reads the input text and the decoder generates a prediction for the task. Compared with the traditional orientation model of sequential reading of input text, transformer's encoder reads the whole word sequence at one time. Due to this special structure of BERT, it can be used in many text classification tasks, topic modeling, text summarization and question answering.
In this paper, we will try to fine tune the BERT model for text classification and detect the emotion of movie reviews using IMDB movie review dataset.
Two variants of BERT are currently available:
- BERT Base: 12 layers, 12 attention heads, 768 hidden and 110M parameters
- BERT Large: 24 layers, 16 attention heads, 1024 hidden and 340M parameters
The following is the BERT architecture diagram of Devlin et al.
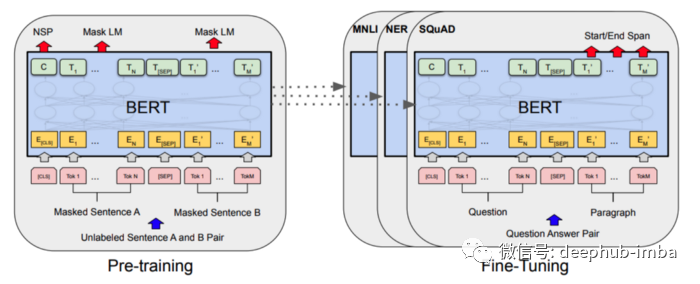
Now that we have a quick understanding of what BERT is, let's fine tune the BERT model for emotion analysis. We will use the IMDB movie review dataset to accomplish this task.
Preparation before fine tuning
First, we need to install the Transformer library from the Hugging Face.
pip install transformers
Now let's import all the libraries we need throughout the implementation.
from transformers import BertTokenizer, TFBertForSequenceClassification from transformers import InputExample, InputFeatures import numpy as np import pandas as pd import tensorflow as tf import os import shutil
We need to import BERT's pre training word segmentation, sequence classifier and input module.
model = TFBertForSequenceClassification.from_pretrained("bert-base-uncased")
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")There are many methods to vectorize text sequences, such as word bag (BoW), TF-IDF, Keras Tokenizers, etc. In this implementation, we will use the pre - trained "bert-base-uncase" marker class
Let's see how the word splitter works.
example = 'This is a blog post on how to do sentiment analysis with BERT' tokens = tokenizer.tokenize(example) token_ids = tokenizer.convert_tokens_to_ids(tokens) print(tokens) print(token_ids) --Output-- ['this', 'is', 'a', 'blog', 'post', 'on', 'how', 'to', 'do', 'sentiment', 'analysis', 'with', 'bert'] [2023, 2003, 1037, 9927, 2695, 2006, 2129, 2000, 2079, 15792, 4106, 2007, 14324]
Since the size of the BERT vocabulary is fixed at 30K tags, words that do not exist in the vocabulary are represented as subwords and characters. The word splitter checks the input sentence and decides whether to keep each word as a complete word, split it into sub words or break it into individual characters as a supplement. A word can always be represented as a set of its constituent characters through a word splitter.
We will use the pre trained "Bert base uncased" model and sequence classifier for fine tuning. For a better understanding, let's look at how the model is built.
model.summary() --Output-- Model: "tf_bert_for_sequence_classification" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= bert (TFBertMainLayer) multiple 109482240 _________________________________________________________________ dropout_37 (Dropout) multiple 0 _________________________________________________________________ classifier (Dense) multiple 1538 ================================================================= Total params: 109,483,778 Trainable params: 109,483,778 Non-trainable params: 0
Our main BERT model consists of a dropout layer for preventing over fitting and a dense layer for realizing classification tasks.
Read data
dataset = pd.read_csv("IMDB Dataset.csv")
dataset.head()
--Output--
review | sentiment
0 |One of the other reviewers has mentioned that ... | positive
1 |A wonderful little production. <br /><br />The... | positive
2 |I thought this was a wonderful way to spend ti... | positive
3 |Basically there's a family where a little boy ... | negative
4 |Petter Mattei's "Love in the Time of Money" is... | positiveAs can be seen from the above output, the emotions of the data set are annotated with positive and negative labels. Therefore, we need to change the label to a numeric value.
def convert2num(value):
if value=='positive':
return 1
else:
return 0
df['sentiment'] = df['sentiment'].apply(convert2num)
train = df[:45000]
test = df[45000:]Data preprocessing
When using the BERT training model, some additional preprocessing tasks need to be completed.
Add special token:
[SEP] - mark the end of the sentence
[CLS] - in order for BERT to understand that we are making a classification, we add this tag at the beginning of each sentence
[PAD] - special marking for filling
[UNK] - when the word separator cannot understand the word represented in the sentence, we will include this tag instead of the word
Introducing filling equal length transfer sequence
Create an array of attention masks - 1 (real tag) and 0 (fill tag)
Fine tuning model
Create input sequence
Using the InputExample function, we can convert df into an object suitable for the BERT model. To do this, I'll create two functions. One function takes the training and test data set as input and converts each row into an InputExample object, and the other function marks the InputExample object.
def convert2inputexamples(train, test, review, sentiment):
trainexamples = train.apply(lambda x:InputExample(
guid=None, text_a = x[review],
label = x[sentiment]), axis = 1) validexamples = test.apply(lambda x: InputExample(
guid=None, text_a = x[review],
label = x[sentiment]), axis = 1)
return trainexamples, validexamplestrainexamples, validexamples = convert2inputexamples(train, test, 'review', 'sentiment')As can be seen from the above function, it takes the training and test data set as input and converts each row of the data set into InputExamples.
def convertexamples2tf(examples, tokenizer, max_length=128):
features = []
for i in tqdm(examples):
input_dict = tokenizer.encode_plus(
i.text_a,
add_special_tokens=True, # Add 'CLS' and 'SEP'
max_length=max_length, # truncates if len(s) > max_length
return_token_type_ids=True,
return_attention_mask=True,
pad_to_max_length=True, # pads to the right by default # CHECK THIS for pad_to_max_length
truncation=True
)
input_ids, token_type_ids, attention_mask = (input_dict["input_ids"],input_dict["token_type_ids"], input_dict['attention_mask'])
features.append(InputFeatures( input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, label=i.label) )
def generate():
for f in features:
yield (
{
"input_ids": f.input_ids,
"attention_mask": f.attention_mask,
"token_type_ids": f.token_type_ids,
},
f.label,
)
return tf.data.Dataset.from_generator(
generate,
({"input_ids": tf.int32, "attention_mask": tf.int32, "token_type_ids": tf.int32}, tf.int64),
(
{
"input_ids": tf.TensorShape([None]),
"attention_mask": tf.TensorShape([None]),
"token_type_ids": tf.TensorShape([None]),
},
tf.TensorShape([]),
),
)
DATA_COLUMN = 'review'
LABEL_COLUMN = 'sentiment'The above function takes the converted input Example object as input, which tokenizes and reformats the input to fit the model.
train_data = convertexamples2tf(list(trainexamples), tokenizer) train_data = train_data.shuffle(100).batch(32).repeat(2) validation_data = convertexamples2tf(list(validexamples), tokenizer) validation_data = validation_data.batch(32)
The above code slice has passed the converted InputExample to the function we created earlier. This process may take up to 2-3 minutes.
Now our data set is processed into input sequences, and we can use the processed data to provide our model.
Training fine tuning BERT model
Before starting the training model, ensure that GPU runtime acceleration is enabled. Otherwise, the training model may take some time.
model.compile(optimizer=tf.keras.optimizers.Adam(
learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0), loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=[tf.keras.metrics.SparseCategoricalAccuracy('accuracy')])
model.fit(train_data, epochs=2, validation_data=validation_data)The above code uses Adam as the optimizer and category cross entropy as the loss function, because we only have two labels, and this function can quantify the difference between the two probability distributions, and use sparse classification accuracy to calculate the accuracy of the model.
After the training, we can continue to predict the mood of film reviews.
Predict emotions
I created a list of two comments, one positive and the second negative.
sentences = ['This was a good movie. I would watch it again', 'I cannot believe I have wasted time on this movie, it is the worst movie I have ever seen']
Before we apply the above sentence list to the model, we need to mark the comments with BERT Tokenizer. After segmenting the sentence list, we input the model and run softmax to predict emotion. To determine the polarity of predicted emotions, we will use the argmax function to correctly classify emotions as "negative" or "positive" labels.
tokenized_sentences = tokenizer(sentences, max_length=128, padding=True, truncation=True, return_tensors='tf')
outputs = model(tokenized_sentences)
predictions = tf.nn.softmax(outputs[0], axis=-1)
labels = ['Negative','Positive']
label = tf.argmax(predictions, axis=1)
label = label.numpy()
for i in range(len(sentences)):
print(sentences[i], ": ", labels[label[i]])
--Output--
This was a good movie. I would watch it again : Positive
I cannot believe I have wasted time on this movie, it is the worst movie I have ever seen : NegativeAs can be seen from the above prediction, we have successfully fine tuned the Transformer based pre training BERT model to predict the mood of film reviews.
summary
This is the whole content of this article about using IMDB movie review data set to fine tune the pre training BERT model to predict the emotion of a given review. If you are interested in other tuning techniques, please refer to the BERT documentation of Hugging Face.
Source code of this article: https://gist.github.com/ravindu9701/1a5451fd79f633727ac1c636cb415892#file-bert-sentiment-analysis-ipynb
Author: Ashish Kumar Singh