summary
The purpose of hash function is to calculate a hash code according to a given object, so that the object can be randomly and randomly placed in the hash table after hash code mapping, so as to avoid hash collision as much as possible.
The version of the hash function provided in the C + + standard library is as follows (partial specialization is used. For numerical data, the hash code obtained by the hash function is the original value, and a special hash expression is provided for the string):
template<class key> struct hash{};//generalization
//Partial specialization
template<> struct hash<char>{size_t operator()(char x)const{return x;}};
template<> struct hash<short>{size_t operator()(shortx)const{return x;}};
template<> struct hash<int>{size_t operator()(int x)const{return x;}};
......
template<> struct hash<long>{size_t operator()(longx)const{return x;}};
......
template<> struct hash<char*>{size_t operator()(char* s)const{return _stl_hash_string(s);}};
size_t _stl_hash_string(const char* s)
{
unsigned long h=0;
for(;*s;++s)h=5*h+*s;
return size_t(s);
}
As we all know, in the STL of C + +, unordered_set,unordered_multiset,unordered_map,unordered_ The underlying data structure of Multimap is hash table. For the underlying principle of hash table, please see my last blog. For our common data types such as int, double, char, char *, string, etc., STL experts have helped write the hash function, so it can be used directly. With unordered_set as an example, as a template class, the specific form is as follows:
unordered_set<typename _Kty,typename _Hasher=hash<_Kty>,typename _Keyeq=equal_to<_Kty>,typename _Allocator<_Kty>>
You can see unordered from above_ Set has four template parameters. The first template parameter is unordered_ The second template parameter is the hash function, the third parameter object is the criterion for the equality of two objects (it should be noted here that for set and map containers, there needs to be a mechanism to judge whether the two objects inserted are equal, and then decide whether to insert and where to insert). The fourth template parameter is the allocator. Obviously, the last three template parameters have default values (they are overloaded () classes, which can easily create function objects for easy calling).
For existing data types in the C + + standard library, unordered_set is very convenient to use:
unordered_set<int> uset1; unordered_set<string> uset2;//The default hash function is provided for string only after C++11
For custom data types, use unordered_set, you need to customize the hash operation. There are three ways:
Use the hash function provided by the standard library
Method 1: use imitation function
#include<iostream>
#include<unordered_set>
using namespace std;
class Person {
private:
string firstname;
string lastname;
int age;
friend class Hasher;
//friend class Equal;
friend void operator<<(ostream& os, const Person& p);
public:
Person() {}
Person(string fn, string ln, int a) :firstname(fn), lastname(ln), age(a) {}
//Overload = = operator
bool operator==(const Person& p)const {
return (firstname == p.firstname)&&(lastname == p.lastname)&&(age == p.age);
}
};
void operator<<(ostream& os, const Person& p)//Output operator overload
{
os << p.firstname << " " << p.lastname << " " << p.age << endl;
}
class Hasher {//Hash function to get hash code
public:
size_t operator()(const Person& p)const{
return hash<string>()(p.firstname) + hash<string>()(p.lastname) + hash<int>()(p.age);
}
};
//class Equal {/ / judge whether two objects are equal
//public:
// bool operator()(const Person& p1, const Person& p2)const {
// return (p1.firstname == p2.firstname) && (p1.lastname == p2.lastname) && (p1.age == p2.age);
// }
//};
void main()
{
//unordered_set<Person,Hasher,Equal> uset;
unordered_set<Person,Hasher> uset;
uset.insert(Person("a", "a", 10));
uset.insert(Person("b", "b", 11));
uset.insert(Person("c", "c", 12));
uset.insert(Person("d", "d", 13));
uset.insert(Person("e", "e", 14));
for (Person p : uset) {
cout << p;
}
}
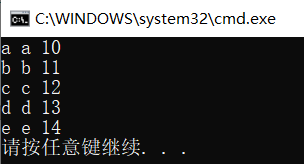
There are two concerns in the example:
① Create an imitation function to convert custom data into hash code
② There are two ways to judge whether two objects are equal for a user-defined type: the first is to overload the = = operator in the class, and the second is to create an imitation function that implements the object comparison function and pass it to unordered_set as a template parameter.
Method 2: use global function
This method is similar to method 1. The only difference is that the imitation function is replaced by a global function, and the address of the global function is passed to unordered_set as a template parameter.
#include<iostream>
#include<unordered_set>
using namespace std;
class Person {
private:
string firstname;
string lastname;
int age;
friend size_t hasher(const Person& p);
public:
Person() {}
Person(string fn, string ln, int a) :firstname(fn), lastname(ln), age(a) {}
//Overload = = operator
bool operator==(const Person& p)const {
return (firstname == p.firstname) && (lastname == p.lastname) && (age == p.age);
}
};
size_t hasher(const Person& p) {//Hash function to get hash code
return hash<string>()(p.firstname) + hash<string>()(p.lastname) + hash<int>()(p.age);
}
void main()
{
unordered_set<Person, size_t(*)(const Person&)> uset(3,hasher);//3 is the number of initialization elements
uset.insert(Person("a", "a", 10));
uset.insert(Person("a", "a", 10));
uset.insert(Person("c", "c", 12));
uset.insert(Person("d", "d", 13));
uset.insert(Person("e", "e", 14));
for (int i = 0; i < uset.bucket_count(); i++) {
cout << "bucket " << i << " has " << uset.bucket_size(i) << " elements" << endl;
}
}
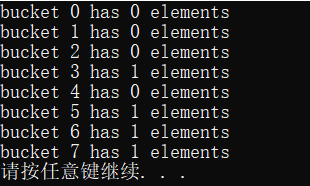
The third method uses partial specialization to realize hash function
Because the C + + standard library has provided the class template of hash and partial specialized versions such as int, string and char, you can directly make a partial specialized version of user-defined types here.
It may feel very similar to mode 1, but the principle is different, and it does not need to be passed to the container in the form of template parameters.
#include<unordered_set>
class Person {
private:
string firstname;
string lastname;
int age;
friend class hash<Person>;
public:
Person() {}
Person(string fn, string ln, int a) :firstname(fn), lastname(ln), age(a) {}
//Overload = = operator
bool operator==(const Person& p)const {
return (firstname == p.firstname) && (lastname == p.lastname) && (age == p.age);
}
};
template<>
class hash<Person> {//Partial specialization (the hash partial specialization classes hash < string >, hash < int > () provided by the standard library are used here)
public:
size_t operator()(const Person& p)const {
return hash<string>()(p.firstname)+ hash<string>()(p.lastname)+ hash<int>()(p.age);
}
};
void main()
{
unordered_set<Person> uset;
uset.insert(Person("a", "a", 10));
uset.insert(Person("a", "a", 10));
uset.insert(Person("c", "c", 12));
uset.insert(Person("d", "d", 13));
uset.insert(Person("e", "e", 14));
for (int i = 0; i < uset.bucket_count(); i++) {
cout << "bucket " << i << " has " << uset.bucket_size(i) << " elements" << endl;
}
}
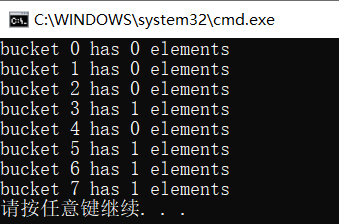
Using custom hash functions
Method 4: use custom hash function
The knowledge of variable templates in generics is used here. When hashing an object, the data members participating in the hash in the object are obtained in turn through steps ①, ② and ③. The idea is very ingenious and needs careful experience.
Although the hash function provided by the standard library is also used to obtain the object hash code here, the difference between method 1 and method 2 is that we finally get the opportunity to define the hash expression ourselves. We can even directly remove the hash function provided by the standard library and completely define the hash expression ourselves here, provided that you have enough confidence to disrupt the hash code.
#include<unordered_set>
class Person {
private:
string firstname;
string lastname;
int age;
friend class Hasher;
public:
Person() {}
Person(string fn, string ln, int a) :firstname(fn), lastname(ln), age(a) {}
//Overload = = operator
bool operator==(const Person& p)const {
return (firstname == p.firstname) && (lastname == p.lastname) && (age == p.age);
}
};
template<typename T>
void hashCombine(size_t& seed, const T& arg)//The real hash is completed here
{
//Although the hash function provided by the standard library is also used here, some data can be added later (even the hash < T > () (ARG) operation can be done by ourselves)
//Different users can have different numbers here, as long as they can disrupt the original data as much as possible
//0x9e3779b9 when it comes to the golden ratio in mathematics, it doesn't really need to be this number
seed ^= hash<T>()(arg) + 0x9e3779b9 + (seed << 6) + (seed >> 2);
}
template<typename T>
void hashValue(size_t& seed, const T& arg)//③ Recursive exit
{
hashCombine(seed, arg);
}
template<typename T1, typename... T2>
void hashValue(size_t& seed,const T1& arg,const T2&... args)//② Here, get all parameters step by step through recursion. When the size of args... Is 1, jump out of the recursion, and then enter ③
{
hashCombine(seed, arg);
hashValue(seed, args...);//recursion
}
template<typename... T>//T is the template parameter package, which can represent any number of types; args is the function parameter package, which can represent any number of function parameters
size_t hashValue(const T&... args)//① Here, complete the first splitting of parameters, and then enter ②
{
size_t seed = 0;//Seeds, passing by reference
hashValue(seed, args...);//args... Is all data members used for hash in T-type objects
return seed;
}
class Hasher {//hash function
public:
size_t operator()(const Person& p)const {
return hashValue(p.firstname,p.lastname,p.age);
}
};
void main()
{
unordered_set<Person, Hasher> uset;
uset.insert(Person("a", "a", 10));
uset.insert(Person("a", "a", 10));
uset.insert(Person("c", "c", 12));
uset.insert(Person("d", "d", 13));
uset.insert(Person("e", "e", 14));
for (int i = 0; i < uset.bucket_count(); i++) {
cout << "bucket " << i << " has " << uset.bucket_size(i) << " elements" << endl;
}
}
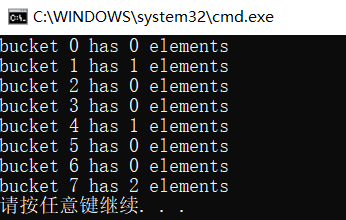
summary
Mode 1, 2 and 3 are relatively simple in form. They basically completely rely on the hash function provided by the C + + standard library, which can be used directly for simple programs. For enterprise programs, they basically build their own hash expressions based on tests, and generally use mode 4.
The above is my basic understanding of C++ hash operation. The source is STL standard library and generic programming by Mr. Hou Jie. I feel it's wonderful, so I've sorted out the following. If you have any errors or opinions, I hope you can give me advice.