Problem Description
Message middleware is a component commonly used in distributed systems and is widely used in asynchronization, decoupling and peak-clipping of systems.Message middleware is generally considered a reliable component, that is, messages are not lost as long as they are delivered to the message middleware.
Therefore, it can be thought that the message will ensure that the message can be consumed successfully at least once, which is one of the most basic characteristics of message middleware.This is AL LEAST ONCE, meaning that the message will be "consumed successfully" at least once.
However, when consumer A is consumed in general, the program restarts, and the message is not marked as successful, so the message will continue to be delivered to the consumer until it is consumed successfully, and then the message middleware will stop delivering.As a result, this reliable feature can cause messages to be consumed many times.
In short, program A receives the message M and finishes the consumption logic. After the program restarts, it cannot tell the message middleware "Successful consumption".For messaging middleware, this message is not consumed successfully and will be delivered again.In the RocketMQ scenario, consumers with the same Message ID are repeatedly posted.
Because reliable message-based delivery (without losing messages) is of higher priority, the task of not repeating consumption is realized by the program itself, which is also the so-called consumption logic that needs to realize idempotency by itself.The logic behind this is that no loss and no duplication are contradictory (in a distributed scenario), but relatively message duplication is a solution, while consumption loss is relatively cumbersome.
As a result, RocketMQ officially lists three scenarios for duplicate messages:
1. Duplicate consumption when sending
When a message has been successfully sent to the server and persisted, a network crash or client downtime occurs, causing the server to fail to respond to the client.If the producer realizes that the message failed and tries to send the message again, the consumer will receive two subsequent messages with the same content and the same Message ID.
2. Duplicate message on delivery
In the scenario where the message is consumed, the message is delivered to the consumer and the business process is completed, and the network is interrupted when the client responds to the server's feedback.To ensure that the message is consumed at least once, the server of the message queue RockeetMQ version will try to deliver the previously processed message again after network recovery. Consumers will then receive two messages with the same content and the same Message ID.
3. Duplicate messages when load balancing
This scenario includes, but is not limited to, network jitter, broker restart, and consumer app restart.Rebalance starts when the message queue RocketMQ version of Broker or the client restarts, expands, or shrinks, and consumers may receive duplicate messages.
Based on these three scenarios, the solution is as follows:
Option 1: Simple message deduplication solution
Suppose the message consumption logic of the business is to insert data from an order table and then update the inventory.
insert into my_order values ...... update my_inv set count = count-1 where good_id = 'good_123456';
To achieve idempotency of the message, you can change the SQL as follows:
select * from my_order where order_no = "order123"
if(order != null){
return; //Duplicate message, return directly
}
The scheme works well in many cases, but there are still problems in concurrent scenarios.
Option 2: Concurrent duplicate messages
If all the code for this consumption takes a total of one second, duplicate messages arrive within that second (assuming 100 milliseconds).For example, producer quick resend, Broker restart, etc.For scenario 1, the data is still empty because the last message has not been consumed and the order status has not been successfully updated.
Two threads execute this logic at very short intervals or even at the same time:
select * from my_order where order_no = "order123"
Then it finds that no data has been found and goes into the following logic:
if(order != null){
return; //Duplicate message, return directly
}
Then it will penetrate the checking baffle, causing duplicate message consumption logic to enter non-power secure business code, which will lead to the problem of duplicate consumption.For example, a primary key conflict throws an exception, inventory is repeatedly deducted without being released, etc.
To solve the problem of message idempotency in such a concurrent scenario, one possible solution is to open a transaction, change select to select for update statement, and lock records:
select * from my_order where order_no = 'THIS_ORDER_NO' for update //Open Transaction
if(order.status != null){
return; //Duplicate message, return directly
}
However, the logic of such consumption may lead to a longer overall message consumption and a lower degree of progress due to the introduction of transactional packages.
Other, more advanced scenarios, such as updating order status with an optimistic lock and message re-consumption if the update fails.However, more specific scenarios require more complex and detailed code development and library table design for specific business scenarios, which are discussed in other blogs.But whether it's select for update or optimistic locking, it's all based on the business table itself, which undoubtedly increases the complexity of business development.
A large part of request processing in a business system relies on MQ, which increases the workload of programmers if each consumption logic itself needs to be developed based on the business itself.Therefore, our goal is to find a common method of message idempotency processing so that we can abstract certain tool classes to suit a variety of business scenarios.
Option 3: Exactly Once
In message middleware, there is a concept of delivery semantics in which there is an Exactly Once meaning that messages are bound to be consumed successfully and only once.For Exactly Once, the official explanation is as follows:
Exactly-Once A message sent to a message system can only be processed by the consumer side and only once, even if the production side retries the message sending and causes a message to be delivered repeatedly, the message will only be consumed once by the consumer side.
In the field of idempotent processing of business messages, it can be considered Exactly Once if the code of the business message is guaranteed to be executed and executed only once.In distributed scenarios, however, it is almost impossible to find a common solution.But if it's for database-based transaction-based consumer logic, it's actually possible.
Additionally, other things about Exactly-One are as follows:
- Exactly-One semantics are ideal for message flow in messaging and streaming computing systems, but there are not many ideal implementations in the industry.
- Exactly-One in its true sense relies on the coordination of the three states of the messaging system's server, the messaging system's client and the user's consumption logic. For example, when the consumer completes a message's consumption processing, an abnormal downtime occurs. When the consumer restarts, the message may be consumed repeatedly because the consumption location is not synchronized to the messaging system's server.
- In fact, the Exactly-One semantics implementation for a particular scenario is not very complex, just because it usually does not accurately describe the nature of the problem.
- If the consumption result of a message can only take effect once in the business system, the only problem to be solved is how to guarantee the consumption power of the same message.
- The Exactly-One semantics of the RocketMQ version of Message Queuing is designed to solve the problem that the consumer result of one of the most common messages in a business (the result of a message being computed and processed on the consumer side) has only one effect in a database system.
Scenario 4: Insert message tables based on relational database transactions
Suppose the message consumption logic for the business is to update the status of an order table in the MySQL database:
update my_order set status = 'SUCCESS' where order_no = '0rder1234';
To implement Exactly-Once, where messages are consumed only once (and are guaranteed to be consumed once), you can do this by adding a message consumption log table to the database, inserting the message into the table, and submitting the original order update together with the inserted action in the same transaction.The specific process is as follows:
-
- Open Transaction
-
- Insert message table (handle primary key conflicts)
-
- Update Order Table (Original Consumption Logic)
-
- Submit Transaction
At this point, if the message consumption is successful and the transaction is committed, the message table is inserted successfully.At this time, even if RocketMQ has not received the update of consumer sites, and then re-delivers, it will insert the failure as if it has been consumed, and then directly update the consumer sites.This ensures that our consumer code will only be executed once.
If the service hangs up before the transaction commits (for example, a restart), then the local transaction is not executed, so the order is not updated and the message table is not inserted successfully.For the RocketMQ server, the consumer site has not been updated, so the message will continue to be delivered, which found that the message inserted into the message table was also successful, so you can continue to consume.This ensures that the message is not lost.
In fact, the implementation of Exactly-One semantics for RicketMQ in Ali Cloud is based on the transactional nature of the data frame.
- Step 1: Add Dependencies
- Step 2: Create a table of consumer transactions
- Step 3: Open Exactly-One Delivery Semantics on the production side
- Step 4: Consumer Opens Exactly-One Delivery Semantics
The solution based on this approach can really be extended to different scenarios because its implementation is independent of the business itself - it depends on a message table.However, there are limitations: the consuming logic of messages must depend on relational database transactions.
The consumption of this message also involves modifications to other data, such as Redis, a data source that does not support transactional attributes, which cannot be rolled back.In addition, the data of the database must be in one library, cross-library cannot be resolved.It is important to note that in business, the involvement of message tables should not be identified by message ID s, but by business primary keys of the business, which is more reasonable in response to producer resends.
More complex business scenarios
As mentioned earlier, the implementation of Exactly-One semantics has many limitations, which make the scheme using Exactly-One have little broad application value.Also, transaction-based performance problems can result in long lock table times, and so on.An example of a more common message about an order request may be divided into the following steps:
- Check Inventory (RPC)
- Lock Stock (RPC)
- Open transaction, insert order table (MySQL)
- Invoke some other downstream service (RPC)
- Update Order Status
- commit transaction (MySQL)
In this case, if the message table + local transaction is implemented, there are many sub-processes in the message consumption process that do not support rollback, that is, the operation behind them is not atomic even if transactions are added.For example, it is possible that the first message is that the service restarts after the second lock on the inventory, when the inventory is actually locked in another service and cannot be rolled back.
Of course, the message will be delivered again, to ensure that the message can be consumed at least all, that is, the RPC interface of Lockucun itself still supports "power".Additionally, adding a transactional package in this time-consuming long chain scenario will significantly reduce system concurrency.
So in general, the way to handle message de-duplication in this scenario is to use the business you started with to implement de-duplication logic on its own, such as selecting for update before, or using an optimistic lock.
So is there a way to extract a public solution that can take into account weight removal, versatility and high performance?Here, we first parse the execution of the message. One idea is to break up the above steps into several different sub-messages, for example:
- Inventory System Message A: Check inventory and lock inventory, send message B to order service
- Order System Consumption Message B: Insert Order Table (MySQL), Send Message C to Consume for Yourself (Downstream System)
- Downstream System Consumption Message C: Processing Partial Logic, Sending Message D to Order System
- Order System Consumption Message D: Update Order Status
The above steps need to ensure that the local transaction and the message are transactional (at least ultimately consistent), involving topics related to distributed transaction messages.You can see that this approach makes each step of the operation atomic, which means small transactions, which means that the scheme using Message Table + Transaction is feasible.But that's too complicated.It is better to split one originally related code logic into multiple systems and interact with messages multiple times than to lock the implementation at the business code level.
A more general solution
The limitations and concurrency of the above message table + local transaction scenario are due to its dependency on relational database transactions and the need to wrap transactions around the entire message consumption segment.If the message can be de-duplicated without relying on transactions, the scenario can be extended to more complex scenarios, such as RPC, cross-library, and so on.
For example, can we still use message tables, but instead of relying on transactions, we increase consumption on them? Can we solve the problem?
Next comes the non-transactional scheme based on the message idempotent table.
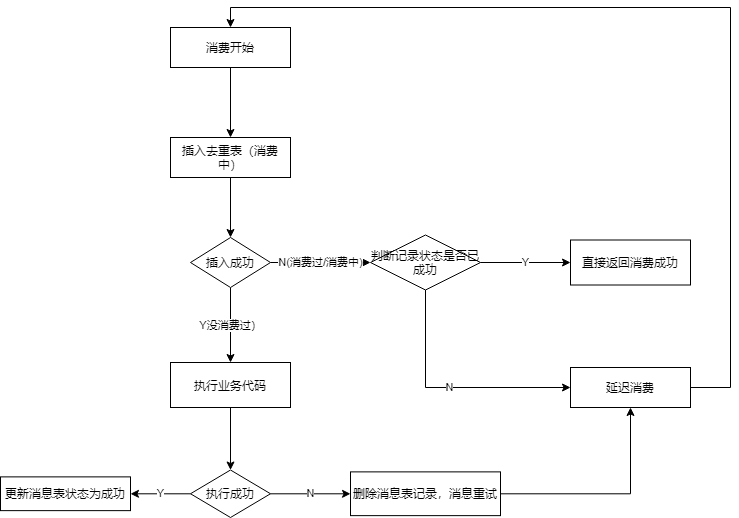
The above is the flow of the de-transacted message idempotency scheme, which you can see is non-transactional.The key is the status of the data, and the message table itself distinguishes the status: consumption is in progress and consumption is complete.Only messages that are consumed are processed idempotently.For messages in existing consumption, repeated messages can trigger delayed consumption, for example, in the case of RocketMQ, sent to RETRY TOPIC.
The reason for triggering delayed consumption is to control concurrent scenarios in which the second message delays consumption rather than directly exponentially controlling the message not to be lost while the first message is incomplete.
If it is directly idempotent, then the same message id or business unique identity will lose the message, because if the previous message was not consumed and the second message already tells the broker that it was successful, then the first message failed and the broker will not be re-delivered.Here we will look again to see if the problem we are trying to solve at the beginning has been solved:
- Question 1: Messages have been consumed successfully, and the second message will be directly idempotent (consumed successfully)
- Question 2: Messages in concurrent scenarios can still satisfy the problem that no message duplication occurs, that is, penetrating the idempotent baffle.
- Question 3: Support for upstream business producers to resend message power, etc.
The first problem has been solved in the description above.So how to solve the second problem?Mainly controlled by inserting a message table. Assuming that we use MySQL as the storage medium of the message table and set the unique ID of the message as the primary key, only one message will be inserted successfully.Later message insertions fail due to a primary key conflict, move to the branch of delayed consumption, and later become the problem in the first scenario above when delayed consumption occurs.For the third question, as long as we refer to the message of weightlessness, see the primary key that enables it to support business (e.g. Dongdan, Request Streaming Number, etc.), not just messageId.So it's not a problem either.
So is there a risk of message loss in this scenario?In fact, there is a logical loophole here, which is Question 2.In concurrent scenarios, depending on the state of the message is to make concurrency control so that messages with duplicate messages in the second message can continue to delay consumption, that is, retry.However, if the first message at this time is also due to some abnormal reasons, such as restart of the machine, external abnormalities leading to consumption failure, did not the consumption succeed?
That is to say, at this time, delayed consumption actually sees the state of consumption each time it comes, and the final consumption will be regarded as a consumption failure and delivered to the dead letter Topic, for example, RocketMQ can repeat consumption 16 times by default.For this problem, our solution is to insert a message table with a maximum consumption expiration time, such as 10 minutes.This means that if a message is consumed for more than 10 minutes, it needs to be deleted from the message table, which requires the program to implement itself.
So the flow of the final message is as follows:
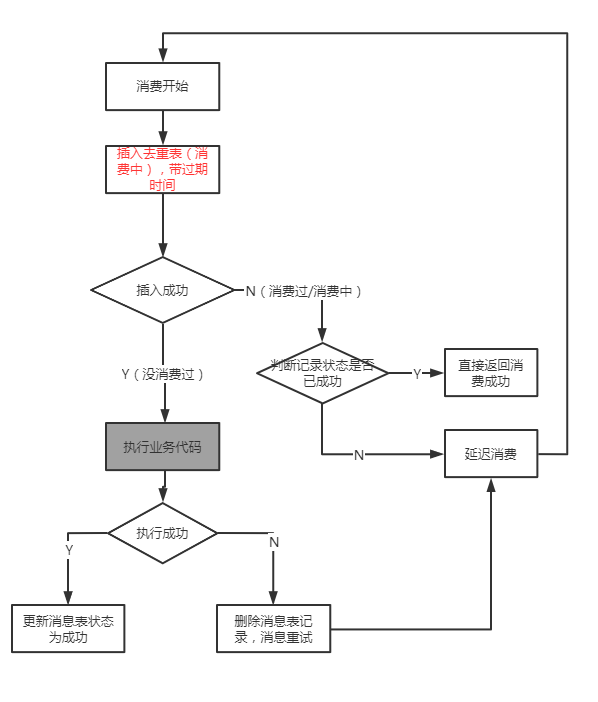
This scenario is virtually non-transactional and requires only a central medium for storage, so you can naturally choose a more flexible storage medium, such as Redis.There are two advantages to using Redis here:
- Low loss in performance
- Timeout can be achieved directly using Redis's own ttl
There are also drawbacks to using Redis: data is less reliable and consistent than MySQL, requiring users to make their own choices.
Show Me Code
The following is a sample application of Redis de-weighting to illustrate how a message de-weighting equal operation is added to a business using this f-scheme:
(1) Inherit the DedupForConcurrentListener class to implement consumer callbacks and setup callbacks to remove duplicate keys.
(2) Start RocketMQ consumers
package com.example.demo.rocketmq;
import com.example.demo.rocketmq.core.DedupConfig;
import com.example.demo.rocketmq.core.DedupForConcurrentListener;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.message.MessageExt;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.jdbc.core.JdbcTemplate;
@Slf4j
public class MonitorListener extends DedupForConcurrentListener {
public MonitorListener(DedupConfig dedupConfig) {
super(dedupConfig);
}
//Conditional message deduplication allows each type of message to be different and respects the value returned by this method before deduplication
@Override
protected String dedupMessageKey(MessageExt messageExt) {
// For simplicity, use the message body directly as the de-key
if ("TEST-TOPIC".equals(messageExt.getTopic())) {
return new String(messageExt.getTopic());
} else {
// Other uses default configuration (message id)
return super.dedupMessageKey(messageExt);
}
}
@Override
protected boolean doHandleMsg(MessageExt messageExt) {
switch (messageExt.getTopic()) {
case "TEST-TOPIC":
log.info("Pretend to spend a lot....{} {}", new String(messageExt.getBody()), messageExt);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
}
}
return true;
}
public static void main(String[] args) throws MQClientException {
// Use Redis to do idempotent operations
{
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("TEST-APP1");
consumer.subscribe("TEST-TOPIC", "*");
String appName = consumer.getConsumerGroup();
StringRedisTemplate stringRedisTemplate = null; // Omit the process of getting StringRedisTemplate
DedupConfig dedupConfig = DedupConfig.enableDedupConsumeConfig(appName, stringRedisTemplate);
DedupForConcurrentListener messageListener = new MonitorListener(dedupConfig);
consumer.registerMessageListener(messageListener);
consumer.start();
}
// Making Idempotent Tables with MySQL
{
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("TEST-API");
consumer.subscribe("TEST-TOPIC", "*");
String appName = consumer.getConsumerGroup();
JdbcTemplate jdbcTemplate = null;
DedupConfig dedupConfig = DedupConfig.enableDedupConsumeConfig(appName, jdbcTemplate);
DedupForConcurrentListener messageListener = new MonitorListener(dedupConfig);
consumer.registerMessageListener(messageListener);
consumer.start();
}
}
}
The only thing that needs to be modified is to create a DedupForConcurrentListener example that specifies custom consumer logic and weighted business keys, where messageId is the default.
package com.example.demo.rocketmq.core;
import com.example.demo.rocketmq.strategy.ConsumeStrategy;
import com.example.demo.rocketmq.strategy.DedupConsumeStrategy;
import com.example.demo.rocketmq.strategy.NormalConsumeStrategy;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyContext;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.common.message.MessageClientIDSetter;
import org.apache.rocketmq.common.message.MessageExt;
import java.util.List;
import java.util.function.Function;
/**
* Adding a message consumer abstract class for de-duplicate logic, instances of which need to implement doHandleMsg
* This abstract class supports strategies for message idempotency
*/
@Slf4j
public abstract class DedupForConcurrentListener implements MessageListenerConcurrently {
//Default No Weighting
private DedupConfig dedupConfig = DedupConfig.disableDupConsumeConfig("NOT-SET-CONSUMER-GROUP");
/**
* Default No Weighting
*/
public DedupForConcurrentListener() {
log.info("Construct QBConcurrentRMQListener with default {}", dedupConfig);
}
/**
* Set the Reduplication Policy
*
* @param dedupConfig
*/
public DedupForConcurrentListener(DedupConfig dedupConfig) {
this.dedupConfig = dedupConfig;
log.info("Construct QBConcurrentRMQListener with dedupConfig {}", dedupConfig);
}
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
boolean hasConsumeFail = false;
int ackIndexIfFail = -1;
for (int i = 0; i < msgs.size(); i++) {
MessageExt msg = msgs.get(i);
try {
hasConsumeFail = !handleMsgInner(msg);
} catch (Exception ex) {
log.warn("Throw Exception when consume {}, ex", msg, ex);
hasConsumeFail = true;
}
//If the previous consumption fails, the latter does not need to consume, because it will be re-issued
if (hasConsumeFail) {
break;
} else {
//Successful consumption to date
ackIndexIfFail = i;
}
}
// Successful Total Consumption
if (!hasConsumeFail) {
log.info("consume [{}] msg(s) all successfully", msgs.size());
} else { // Failed
context.setAckIndex(ackIndexIfFail); // Mark the success position, which will be replayed later to re-consume, and will not be replayed before this position
log.warn("consume [{}] msg(s) fails, ackIndex = [{}] ", msgs.size(), context.getAckIndex());
}
// Will come back in the end anyway
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
/**
* Subclasses implement this method to actually process messages
*
* @param messageExt
* @return
*/
protected abstract boolean doHandleMsg(final MessageExt messageExt);
/**
* Default uniqkey as de-weighting identifier
*/
protected String dedupMessageKey(final MessageExt messageExt) {
String uniqID = MessageClientIDSetter.getUniqID(messageExt);
if (uniqID == null) {
return messageExt.getMsgId();
} else {
return uniqID;
}
}
/**
* Consumer messages, logic with weight
*
* @param messageExt
* @return
*/
private boolean handleMsgInner(final MessageExt messageExt) {
ConsumeStrategy strategy = new NormalConsumeStrategy();
Function<MessageExt, String> dedupKeyFunction = messageExt1 -> dedupMessageKey(messageExt);
if (dedupConfig.getDedupStrategy() == DedupConfig.DEDUP_STRTEGY_CONSUME_LATER) {
strategy = new DedupConsumeStrategy(dedupConfig, dedupKeyFunction);
}
// Call the corresponding policy
return strategy.invoke(DedupForConcurrentListener.this::doHandleMsg, messageExt);
}
}
Then the question arises: can such a solution perfectly accomplish all the tasks of weight removal?The answer is No.Because to ensure that messages are consumed at least once successfully, there is a chance that messages will fail to trigger message retries halfway through consumption. Take the order process above for example:
- Check Inventory (RPC)
- Lock Stock (RPC)
- Open transaction, insert order table (MySQL)
- Invoke some other downstream service (RPC)
- Update Order Status
- COMMIT Transaction (MySQL)
Here, when the message is consumed to step 3, assume the MySQL exception causes the failure, and the message retries.Because we delete the records of the idempotent table before retrying, the message will be re-entered into the consumer code when retrying, and steps 1 and 2 will be re-executed.If step 2 itself is not idempotent, then this business message consumption is still not fully idempotent.
So what is the value of this approach?Although this is not a silver bullet for message power, it can solve the following problems in a convenient way:
-
- Various duplicate issues of message delivery due to Broker, load balancing, etc.
-
- Business-level message duplication problems caused by various upstream producers
-
- The control window problem of concurrent consumption of duplicate messages, even if duplicated, duplicates cannot enter the consumption logic at the same time.
Other news to rebuild the proposal
Using the above methods can ensure normal consumption logic scenarios (no abnormality, no abnormal exit), and all the power work of the message can be solved, whether it is business duplication or duplication caused by the RocketMQ feature.Moreover, this has solved 99% of message duplication problems.If you want to be able to handle idempotent problems well in exceptional scenarios, consider the following scenarios:
-
- Message consumption failure does rollback processing.If message consumption failures are inherently rollback mechanisms, then message retries are naturally no problem
-
- Consumers do a good job of graceful exit processing.This is to minimize message consumption until half of the program exits message retries.
-
- If you really can't do the same thing, at least stop spending and warn.For example, the operation of lock inventory, if the unified business flow locks successfully once the inventory, and then locks the inventory, if the power processing cannot be done, at least do the message consumption trigger exception (such as primary key pupil causing consumption exception).
In addition, on the premise of requiring 3 to do a good job, do a good job of monitoring the consumption of messages, and find that when message retries fail continuously, do a good job of rolling back 1 manually to make the next retry of consumption successful.