1. Background
We usually use three crawler libraries when crawling web pages: requests, scratch and selenium. Requests are generally used for small crawlers, while scratch is used to build large crawler projects, while selenium is mainly used to deal with responsible pages (complex js rendered pages, requests are very difficult to construct, or the construction method often changes).
When we are faced with large crawler projects, we will certainly choose the scratch framework for development, but it is troublesome to parse complex JS rendered pages. Although it is convenient to use selenium browser rendering to capture such a page, in this way, we do not need to care about what kind of requests occur in the background of the page, nor do we need to analyze the rendering process of the whole page. We only need to care about the final result of the page, which can be seen and crawled, but the efficiency of selenium is too low.
Therefore, if selenium can be integrated into the script and let selenium be responsible for crawling complex pages, such crawlers will be invincible and can crawl any website.
- environment
python 3.6.1
System: win7
IDE: pycharm
Installed chrome browser
Configure the chromedriver (set the environment variable)
selenium 3.7.0
scrapy 1.4.0
3. Principle analysis
3.1. Analyze the process of request
First, let's take a look at the latest architecture diagram of graph: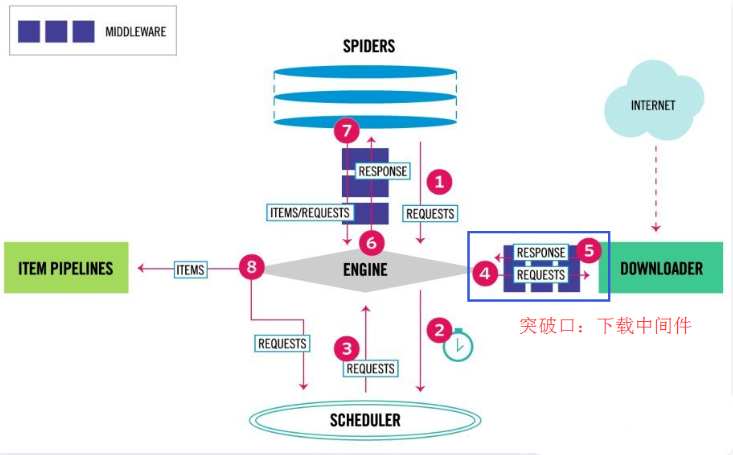
Some processes:
First: the crawler engine generates requests, sends them to the scheduler scheduling module, enters the waiting queue and waits for scheduling.
Second: the scheduler module starts to schedule these requests, get out of the queue and send them to the crawler engine.
Third: the crawler engine sends these requests to the download middleware (multiple, such as adding header s, agents, customization, etc.) for processing.
Fourth: after processing, send it to the Downloader module for download.
From this processing process, the breakthrough is to download the middleware and directly process the request with selenium.
3.2. Source code analysis of requests and response intermediate processing pieces
Relevant code location:
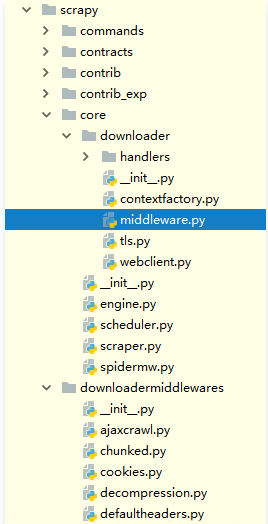
Source code analysis:
# File: e: \ miniconda \ lib \ site packages \ scratch \ core \ downloader \ middleware py
"""
Downloader Middleware manager
See documentation in docs/topics/downloader-middleware.rst
"""
import six
from twisted.internet import defer
from scrapy.http import Request, Response
from scrapy.middleware import MiddlewareManager
from scrapy.utils.defer import mustbe_deferred
from scrapy.utils.conf import build_component_list
class DownloaderMiddlewareManager(MiddlewareManager):
component_name = 'downloader middleware'
@classmethod
def _get_mwlist_from_settings(cls, settings):
# From settings Py or custom_ Get the customized Middleware in setting
'''
'DOWNLOADER_MIDDLEWARES': {
'mySpider.middlewares.ProxiesMiddleware': 400,
# SeleniumMiddleware
'mySpider.middlewares.SeleniumMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
},
'''
return build_component_list(
settings.getwithbase('DOWNLOADER_MIDDLEWARES'))
# Add the processing functions of all custom Middleware middleware to the corresponding methods list
def _add_middleware(self, mw):
if hasattr(mw, 'process_request'):
self.methods['process_request'].append(mw.process_request)
if hasattr(mw, 'process_response'):
self.methods['process_response'].insert(0, mw.process_response)
if hasattr(mw, 'process_exception'):
self.methods['process_exception'].insert(0, mw.process_exception)
# The whole download process
def download(self, download_func, request, spider):
@defer.inlineCallbacks
def process_request(request):
# The request is processed through the process of each custom Middleware_ The request method is added to the list
for method in self.methods['process_request']:
response = yield method(request=request, spider=spider)
assert response is None or isinstance(response, (Response, Request)), \
'Middleware %s.process_request must return None, Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, response.__class__.__name__)
# This is the key
# If in the process of a Middleware_ After the request is processed, a response object is generated
# Then it will return the response directly, jump out of the loop and no longer process other processes_ request
# Previously, our header and proxy middleware only added a user agent and a proxy without any return value
# It should also be noted that the return must be a Response object
# The HtmlResponse constructed later is the subclass object of the Response
if response:
defer.returnValue(response)
# If all processes above_ If no Response object is returned in the request
# Finally, the processed Request will be sent to download_func to download and return a Response object
# Then it passes through the process of each Middleware in turn_ The response method is processed as follows
defer.returnValue((yield download_func(request=request,spider=spider)))
@defer.inlineCallbacks
def process_response(response):
assert response is not None, 'Received None in process_response'
if isinstance(response, Request):
defer.returnValue(response)
for method in self.methods['process_response']:
response = yield method(request=request, response=response,
spider=spider)
assert isinstance(response, (Response, Request)), \
'Middleware %s.process_response must return Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, type(response))
if isinstance(response, Request):
defer.returnValue(response)
defer.returnValue(response)
@defer.inlineCallbacks
def process_exception(_failure):
exception = _failure.value
for method in self.methods['process_exception']:
response = yield method(request=request, exception=exception,
spider=spider)
assert response is None or isinstance(response, (Response, Request)), \
'Middleware %s.process_exception must return None, Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, type(response))
if response:
defer.returnValue(response)
defer.returnValue(_failure)
deferred = mustbe_deferred(process_request, request)
deferred.addErrback(process_exception)
deferred.addCallback(process_response)
return deferred
- code
In settings Py, configure selenium parameters:
#File settings In PY
# --------- selenium parameter configuration-------------
SELENIUM_ Timeout = timeout of 25 # selenium browser, in seconds
LOAD_IMAGE = True # do you want to download the picture
WINDOW_HEIGHT = 900 # browser window size
WINDOW_WIDTH = 900
In the spider, when generating a request, mark which requests need to be downloaded through selenium:
# File myspider In PY
class mySpider(CrawlSpider):
name = "mySpiderAmazon"
allowed_domains = ['amazon.com']
custom_settings = {
'LOG_LEVEL':'INFO',
'DOWNLOAD_DELAY': 0,
'COOKIES_ENABLED': False, # enabled by default
'DOWNLOADER_MIDDLEWARES': {
# Agent middleware
'mySpider.middlewares.ProxiesMiddleware': 400,
# Selenium Middleware
'mySpider.middlewares.SeleniumMiddleware': 543,
# Turn off the default user agent middleware of the sweep
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
},
#..................... Gorgeous dividing line
# When generating a request, put the flag of whether to use selenium download into meta
yield Request(
url = "https://www.amazon.com/",
meta = {'usedSelenium': True, 'dont_redirect': True},
callback = self.parseIndexPage,
errback = self.error
)
Downloading Middleware middlewares.py In, use selenium Grab page (core part)
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
from scrapy.http import HtmlResponse
from logging import getLogger
import time
class SeleniumMiddleware():
# It is often necessary to obtain the properties of settings in pipeline or middleware, which can be obtained through scratch crawler. Crawler. Settings property
@classmethod
def from_crawler(cls, crawler):
# From settings Py, extract selenium setting parameters and initialize classes
return cls(timeout=crawler.settings.get('SELENIUM_TIMEOUT'),
isLoadImage=crawler.settings.get('LOAD_IMAGE'),
windowHeight=crawler.settings.get('WINDOW_HEIGHT'),
windowWidth=crawler.settings.get('WINDOW_WIDTH')
)
def __init__(self, timeout=30, isLoadImage=True, windowHeight=None, windowWidth=None):
self.logger = getLogger(__name__)
self.timeout = timeout
self.isLoadImage = isLoadImage
# Define a browser belonging to this class to prevent a new chrome browser from opening every time a page is requested
# In this way, all requests processed by this class can use only this browser
self.browser = webdriver.Chrome()
if windowHeight and windowWidth:
self.browser.set_window_size(900, 900)
self.browser.set_page_load_timeout(self.timeout) # Page load timeout
self.wait = WebDriverWait(self.browser, 25) # Specifies the element load timeout
def process_request(self, request, spider):
'''
use chrome Grab page
:param request: Request Request object
:param spider: Spider object
:return: HtmlResponse response
'''
# self.logger.debug('chrome is getting page')
print(f"chrome is getting page")
# It depends on the tags in meta to determine whether selenium is needed to crawl
usedSelenium = request.meta.get('usedSelenium', False)
if usedSelenium:
try:
self.browser.get(request.url)
# Does the search box appear
input = self.wait.until(
EC.presence_of_element_located((By.XPATH, "//div[@class='nav-search-field ']/input"))
)
time.sleep(2)
input.clear()
input.send_keys("iphone 7s")
# Press enter to search
input.send_keys(Keys.RETURN)
# See if the search results appear
searchRes = self.wait.until(
EC.presence_of_element_located((By.XPATH, "//div[@id='resultsCol']"))
)
except Exception as e:
# self.logger.debug(f'chrome getting page error, Exception = {e}')
print(f"chrome getting page error, Exception = {e}")
return HtmlResponse(url=request.url, status=500, request=request)
else:
time.sleep(3)
return HtmlResponse(url=request.url,
body=self.browser.page_source,
request=request,
# Best according to the specific coding of the web page
encoding='utf-8',
status=200)
- results of enforcement
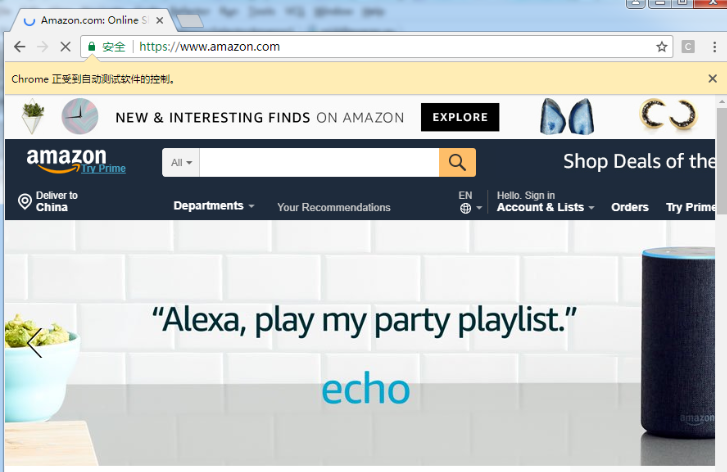
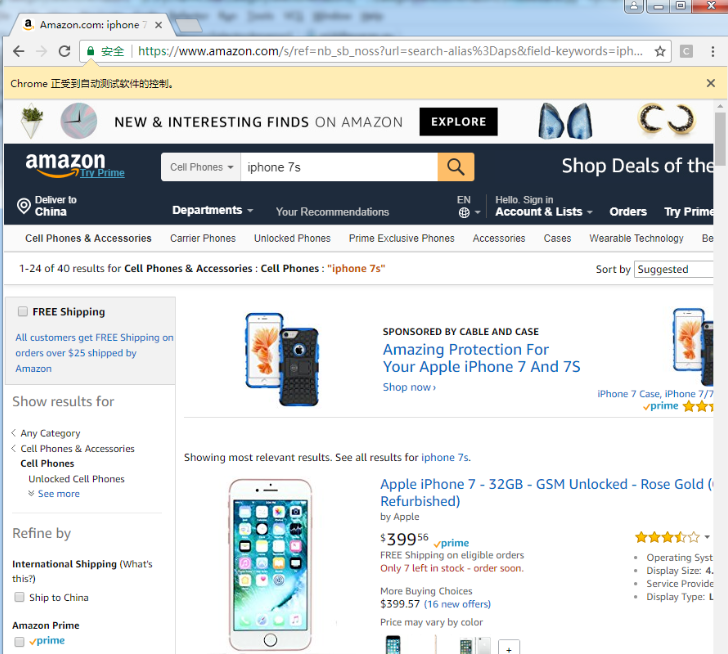
6. Existing problems
6.1. Spider closed and chrome did not exit.
2018-04-04 09:26:18 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/response_bytes': 2092766,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 4, 4, 1, 26, 16, 763602),
'log_count/INFO': 7,
'request_depth_max': 1,
'response_received_count': 2,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2018, 4, 4, 1, 25, 48, 301602)}
2018-04-04 09:26:18 [scrapy.core.engine] INFO: Spider closed (finished)
Above, we put the browser object into the Middleware and can only do process_request and process_response does not describe how to call the close method of the scratch in the Middleware.
Solution: use the semaphore method when the spider is received_ When the closed signal, call browser quit()
6.2. When a project starts multiple spider s at the same time, it will share the selenium in Middleware, which is not conducive to concurrency.
Because only some or even a small number of pages use chrome in the way of scratch + selenium. Since there are so many restrictions on putting chrome into Middleware, why not put chrome into spider. The advantage of this is that each spider has its own chrome, so when multiple spiders are started, there will be multiple chrome. Not all spiders share one chrome, which is good for our concurrency.
Solution: put the initialization of chrome into the spider, and each spider has its own chrome
- Improved code
In settings Py, configure selenium parameters:
# File settings In PY # -----------selenium parameter configuration------------- SELENIUM_TIMEOUT = 25 # Timeout of selenium browser, in seconds LOAD_IMAGE = True # Download picture WINDOW_HEIGHT = 900 # Browser window size WINDOW_WIDTH = 900
In the spider, when generating a request, mark which requests need to be downloaded through selenium:
# File myspider In PY
# selenium related Library
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
# Sweep signal correlation Library
from scrapy.utils.project import get_project_settings
# The following method will be abandoned, so it is not necessary
# from scrapy.xlib.pydispatch import dispatcher
from scrapy import signals
# The latest scheme adopted by scratch
from pydispatch import dispatcher
class mySpider(CrawlSpider):
name = "mySpiderAmazon"
allowed_domains = ['amazon.com']
custom_settings = {
'LOG_LEVEL':'INFO',
'DOWNLOAD_DELAY': 0,
'COOKIES_ENABLED': False, # enabled by default
'DOWNLOADER_MIDDLEWARES': {
# Agent middleware
'mySpider.middlewares.ProxiesMiddleware': 400,
# Selenium Middleware
'mySpider.middlewares.SeleniumMiddleware': 543,
# Turn off the default user agent middleware of the sweep
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
},
# Put the chrome initialization into the spider and become an element in the spider
def __init__(self, timeout=30, isLoadImage=True, windowHeight=None, windowWidth=None):
# From settings PY
self.mySetting = get_project_settings()
self.timeout = self.mySetting['SELENIUM_TIMEOUT']
self.isLoadImage = self.mySetting['LOAD_IMAGE']
self.windowHeight = self.mySetting['WINDOW_HEIGHT']
self.windowWidth = self.mySetting['windowWidth']
# Initializing chrome objects
self.browser = webdriver.Chrome()
if self.windowHeight and self.windowWidth:
self.browser.set_window_size(900, 900)
self.browser.set_page_load_timeout(self.timeout) # Page load timeout
self.wait = WebDriverWait(self.browser, 25) # Specifies the element load timeout
super(mySpider, self).__init__()
# Set the semaphore when the spider is received_ When the closed signal, call the mySpiderCloseHandle method to close chrome
dispatcher.connect(receiver = self.mySpiderCloseHandle,
signal = signals.spider_closed`Insert the code slice here`
)
# Semaphore handler: close chrome browser
def mySpiderCloseHandle(self, spider):
print(f"mySpiderCloseHandle: enter ")
self.browser.quit()
#..................... Gorgeous dividing line
# When generating a request, put the flag of whether to use selenium download into meta
yield Request(
url = "https://www.amazon.com/",
meta = {'usedSelenium': True, 'dont_redirect': True},
callback = self.parseIndexPage,
errback = self.error
)
Download middleware middleware Py, use selenium to grab the page
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
from scrapy.http import HtmlResponse
from logging import getLogger
import time
class SeleniumMiddleware():
# Middleware will pass in a spider, which is our spider object, from which we can get__ init__ chrome related elements at
def process_request(self, request, spider):
'''
use chrome Grab page
:param request: Request Request object
:param spider: Spider object
:return: HtmlResponse response
'''
print(f"chrome is getting page")
# It depends on the tags in meta to determine whether selenium is needed to crawl
usedSelenium = request.meta.get('usedSelenium', False)
if usedSelenium:
try:
spider.browser.get(request.url)
# Does the search box appear
input = spider.wait.until(
EC.presence_of_element_located((By.XPATH, "//div[@class='nav-search-field ']/input"))
)
time.sleep(2)
input.clear()
input.send_keys("iphone 7s")
# Press enter to search
input.send_keys(Keys.RETURN)
# See if the search results appear
searchRes = spider.wait.until(
EC.presence_of_element_located((By.XPATH, "//div[@id='resultsCol']"))
)
except Exception as e:
print(f"chrome getting page error, Exception = {e}")
return HtmlResponse(url=request.url, status=500, request=request)
else:
time.sleep(3)
# Page crawling succeeds, and a successful Response object is constructed (HtmlResponse is its subclass)
return HtmlResponse(url=request.url,
body=spider.browser.page_source,
request=request,
# Best according to the specific coding of the web page
encoding='utf-8',
status=200)
Running result (after the spider ends, execute mySpiderCloseHandle and close the chrome browser):
['categorySelectorAmazon1.pipelines.MongoPipeline']
2018-04-04 11:56:21 [scrapy.core.engine] INFO: Spider opened
2018-04-04 11:56:21 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
chrome is getting page
parseProductDetail url = https://www.amazon.com/, status = 200, meta = {'usedSelenium': True, 'dont_redirect': True, 'download_timeout': 25.0, 'proxy': 'http://H37XPSB6V57VU96D:CAB31DAEB9313CE5@proxy.abuyun.com:9020', 'depth': 0}
chrome is getting page
2018-04-04 11:56:54 [scrapy.core.engine] INFO: Closing spider (finished)
mySpiderCloseHandle: enter
2018-04-04 11:56:59 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/response_bytes': 1938619,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 4, 4, 3, 56, 54, 301602),
'log_count/INFO': 7,
'request_depth_max': 1,
'response_received_count': 2,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2018, 4, 4, 3, 56, 21, 642602)}
2018-04-04 11:56:59 [scrapy.core.engine] INFO: Spider closed (finished)
Finally: [may give you some help]
These materials should be the most comprehensive and complete preparation warehouse for [software testing] friends. This warehouse also accompanies tens of thousands of test engineers through the most difficult journey. I hope it can also help you!
Pay attention to my WeChat official account [software test dao] free access.
My learning and communication group: 644956177. There are technical cows in the group to communicate and share~
If my blog is helpful to you and you like my blog content, please click "like", "comment" and "collect" for three times!