Linux TCP congestion state machine core function tcp_fastretrans_alert is too aggressive.
After detecting whether the packet loss is true or false, the congestion control algorithm can do very little. Even if the congestion control algorithm determines that this is a packet loss unrelated to congestion or even no packet loss at all, the congestion state machine still needs to take back the control right, and the congestion control algorithm can only wait for undo.
Why can't the congestion control algorithm take over all TCP congestion state machine transitions including retransmission? There is no reason. Maybe this code has become a piece of shit and no one can change it. This may not be the case for other systems other than Linux, or even completely ignore congestion control.
For Linux TCP, no matter how intelligent the congestion control algorithm is, things are always possible in TCP_ fastretrans_ The alert function logic is in disorder. It is suddenly blocked, the window is discounted, and there is no need to play with congestion control.
A few years ago, I tried to reconstruct the transformation logic of TCP congestion state machine, but failed. The code is too coupled and adheres everywhere. I just want to smash the computer. Nowadays, in the face of frequent Caton scenes of live video streaming, even if it is not completely rewritten, this thing still needs to be done in another way.
Still Saturday, write some ideas.
Before the introduction of fast recovery, TCP retransmission completely relies on timeout retransmission. Even after the introduction of fast recovery, when it cannot be triggered, loss recovery still exists as a bottom-up strategy.
Depending on the timeout, there is no problem with retransmission, but there will be a RTO delay before triggering the timeout retransmission. This empty window period will lead to stall, and the efficiency of the timeout retransmission process is very low, which introduces serious Caton. For the live broadcast scene, this experience is very poor.
The fundamental to suppress jamming is to have messages to send at all times. Whether it is a new message or a retransmission message marked lost, it must be sent continuously. It cannot be stopped, and it will stall as soon as it stops. Under what circumstances will it stall and fall into RTO timeout?
With the support of TLP and Early Retransmit, it is assumed that once a packet loss occurs, it will always enter the fast recovery logic. The question is, under what circumstances will fast recovery stop and then fall into timeout?
In the process of fast recovery, it is considered that two messages with large sequence number span are sacked by ACK twice in reverse order, which will increase the reordering and prevent the message from being marked as lost, which means that there may be no message to be retransmitted. As shown in the figure below:
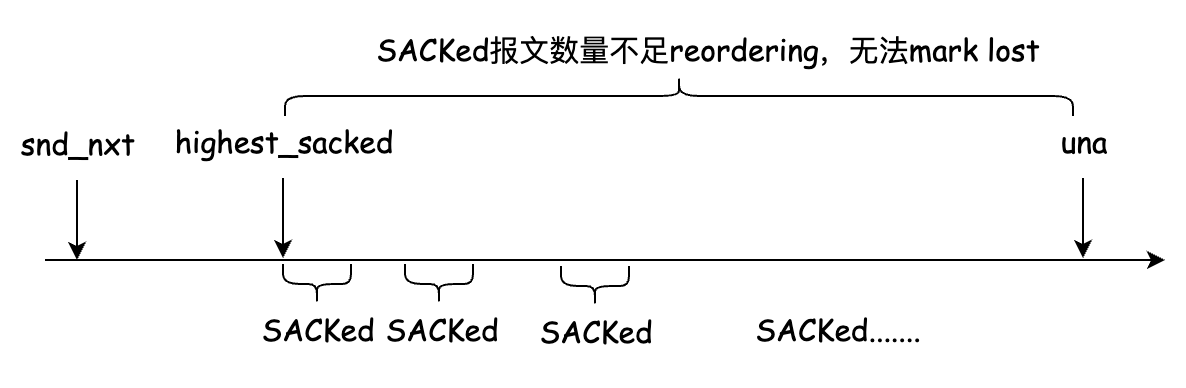
In addition, it is loss retransmission, that is, although the message is retransmitted, the retransmitted message is lost, and TCP cannot detect this situation relatively accurately.
There is a low comparison strategy to detect loss retransmission, which is not affected by reordering. When a SACK is received, the message retransmitted before the current highest SACK message will be re marked as lost. See TCP for details_ mark_ lost_ Retrans function. However, this mechanism will lead to misjudgment introduced by reordering and increase the retransmission rate. The root of the problem is that SACK cannot distinguish between normal transmission and retransmission of the same message.
After the introduction of time sequence based rack (refer to RFC8985), this low strategy is not required:
Lost retransmission: Consider a flight of three data segments (P1, P2, P3) that are sent; P1 and P2 are dropped. Suppose the transmission of each segment is at least RACK.reo_wnd after the transmission of the previous segment. When P3 is SACKed, RACK will mark P1 and P2 as lost, and they will be retransmitted as R1 and R2. Suppose R1 is lost again but R2 is SACKed; RACK will mark R1 as lost and trigger retransmission again. Again, neither the conventional three-duplicate ACK threshold approach, nor the loss recovery algorithm [RFC6675], nor the Forward Acknowledgment [FACK] algorithm can detect such losses. And such a lost retransmission can happen when TCP is being rate-limited, particularly by token bucket policers with a large bucket depth and low rate limit; in such cases, retransmissions are often lost repeatedly because standard congestion control requires multiple round trips to reduce the rate below the policed rate.
Obviously, the RACK is smoother to deal with the lost retransmission. Unless the link is completely interrupted or the reorder window of the RACK is as large as an srtt, there will be no packets to send.
We know that the BBR is based on the pacing rate. If the RACK does not provide uninterrupted messages, it will easily stall and the BBR will not live up to its name.
Let's look at another stall scenario. Before some lost messages are marked as lost, the undo logic of DSACK pulls the connection from the fast recovery state to the disorder state, and there is no message to send, as shown in the following figure:
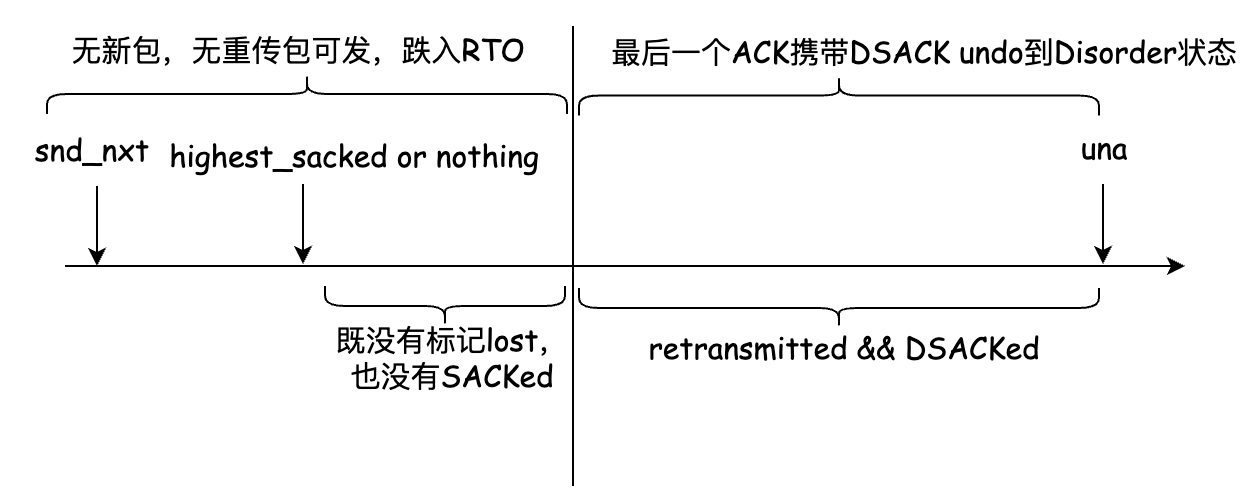
RACK does not seem to be affected by this problem, because every message sent will be included in a time sequence queue, whether it is a new message or a retransmission message. Even if a DSACK causes undo, it will still cause the message sent later to be sacked first and continue to be marked lost by the RACK mechanism to avoid stall. The RACK marks lost continuously in a time sequence. As shown in the figure below:
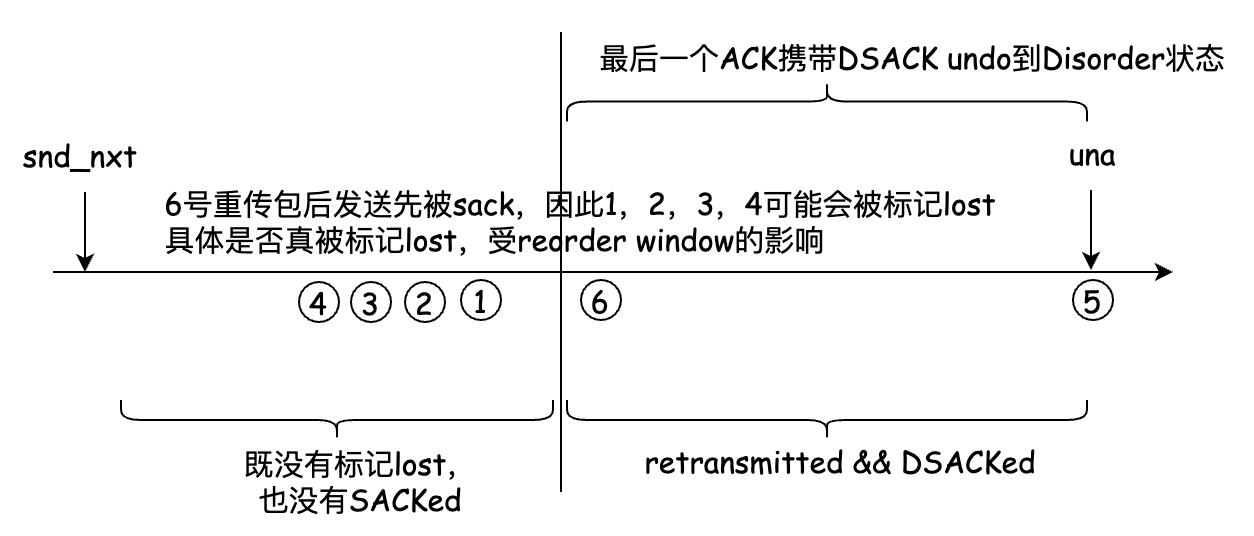
TCP for Linux TCP_ fastretrans_ There is a problem with alert implementation, resulting in incomplete RACK, but this problem has been solved recently:
https://git.kernel.org/pub/scm/linux/kernel/git/netdev/net-next.git/commit/?id=a29cb6914681a55667436a9eb7a42e28da8cf387
The only factor affecting the RACK mechanism to mark lost seems to be that DSACK causes the reorder window of the RACK to become larger, which prevents the message from being marked lost and leads to stall.
To solve this problem, two recent patch es have effectively suppressed this problem:
https://git.kernel.org/pub/scm/linux/kernel/git/netdev/net-next.git/commit/?id=63f367d9de77b30f58722c1be9e334fb0f5f342d
https://git.kernel.org/pub/scm/linux/kernel/git/netdev/net-next.git/commit/?id=a657db0350bb8f568897835b6189c84a89f13292
Back to the initial question, do you really need RTO timeout to reveal the truth? Because the big play in the end-to-end serial number space is extremely complex, no one will expect what will happen. It is still necessary to find out. The problem is, if you have to find out, why not use TLP?
Now that it is in the fast recovery state, the TCP congestion control mechanism has sensed the congestion and responded to alleviate the congestion, such as lowering the window and implementing inflight conservation. This is an even better strategy equal to RTO timeout. Fast recovery finds packet loss in advance and can retransmit faster.
Theoretically, it is reasonable to enable TLP after fast recovery retransmits the last message that can be retransmitted. Assuming that the link is physically disconnected, what can loss recovery do after RTO timeout if fast recovery is powerless?
When there is no packet stall during fast recovery, what is needed is a pacing mechanism rather than a bottom-up strategy. Any TCP implementation requires ack feedback for pacing. If it stalls because it does not receive ACK, pacing is enough. It seems that it is not necessary to enter the loss recovery state after timeout. The cost is too high.
I did a simple experiment to simulate the above TCP pacemaker and ensure the continuity of TCP ACK clock:
- The timer enabled during fast recovery does not use RTO, but uses TLP as timeout.
- When entering RTO timeout processing, if it comes in N times before fast recovery (tentatively n is 1), it will not enter the loss state, but only retransmit the first packet in the retransmission queue, that is, una.
- reset reordering and reorder window steps of RACK in RTO timeout processing function.
diff --git a/include/net/inet_connection_sock.h b/include/net/inet_connection_sock.h
index 3c8c59471bc1..51448607ecd4 100644
--- a/include/net/inet_connection_sock.h
+++ b/include/net/inet_connection_sock.h
@@ -102,6 +102,7 @@ struct inet_connection_sock {
icsk_ca_initialized:1,
icsk_ca_setsockopt:1,
icsk_ca_dst_locked:1;
+ __u8 icsk_ca_pacemaking_cnt;
__u8 icsk_retransmits;
__u8 icsk_pending;
__u8 icsk_backoff;
diff --git a/net/ipv4/tcp_input.c b/net/ipv4/tcp_input.c
index 69a545db80d2..326957f7939a 100644
--- a/net/ipv4/tcp_input.c
+++ b/net/ipv4/tcp_input.c
@@ -2740,6 +2740,7 @@ EXPORT_SYMBOL(tcp_simple_retransmit);
void tcp_enter_recovery(struct sock *sk, bool ece_ack)
{
struct tcp_sock *tp = tcp_sk(sk);
+ struct inet_connection_sock *icsk = inet_csk(sk);
int mib_idx;
if (tcp_is_reno(tp))
@@ -2757,6 +2758,7 @@ void tcp_enter_recovery(struct sock *sk, bool ece_ack)
tp->prior_ssthresh = tcp_current_ssthresh(sk);
tcp_init_cwnd_reduction(sk);
}
+ icsk->icsk_ca_pacemaking_cnt = 0;
tcp_set_ca_state(sk, TCP_CA_Recovery);
}
@@ -2940,6 +2942,7 @@ static void tcp_fastretrans_alert(struct sock *sk, const u32 prior_snd_una,
/* E. Process state. */
switch (icsk->icsk_ca_state) {
case TCP_CA_Recovery:
+ icsk->icsk_ca_pacemaking_cnt = 0;
if (!(flag & FLAG_SND_UNA_ADVANCED)) {
if (tcp_is_reno(tp))
tcp_add_reno_sack(sk, num_dupack, ece_ack);
diff --git a/net/ipv4/tcp_output.c b/net/ipv4/tcp_output.c
index fbf140a770d8..3300f1720742 100644
--- a/net/ipv4/tcp_output.c
+++ b/net/ipv4/tcp_output.c
@@ -3352,10 +3352,27 @@ void tcp_xmit_retransmit_queue(struct sock *sk)
rearm_timer = true;
}
- if (rearm_timer)
+ if (rearm_timer) {
+ u32 timeout, rto_delta_us;
+
+ if (tp->srtt_us) {
+ timeout = usecs_to_jiffies(tp->srtt_us >> 2);
+ if (tp->packets_out == 1)
+ timeout += TCP_RTO_MIN;
+ else
+ timeout += TCP_TIMEOUT_MIN;
+ } else {
+ timeout = TCP_TIMEOUT_INIT;
+ }
+
+ rto_delta_us = tcp_rto_delta_us(sk); /* How far in future is RTO? */
+ if (rto_delta_us > 0)
+ timeout = min_t(u32, timeout, usecs_to_jiffies(rto_delta_us));
+
tcp_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
- inet_csk(sk)->icsk_rto,
+ timeout,
TCP_RTO_MAX);
+ }
}
/* We allow to exceed memory limits for FIN packets to expedite
diff --git a/net/ipv4/tcp_timer.c b/net/ipv4/tcp_timer.c
index 4ef08079ccfa..2da62f0ea21c 100644
--- a/net/ipv4/tcp_timer.c
+++ b/net/ipv4/tcp_timer.c
@@ -533,7 +533,14 @@ void tcp_retransmit_timer(struct sock *sk)
__NET_INC_STATS(sock_net(sk), mib_idx);
}
- tcp_enter_loss(sk);
+ if (icsk->icsk_ca_state != TCP_CA_Recovery || icsk->icsk_ca_pacemaking_cnt)
+ tcp_enter_loss(sk);
+ else {
+ tp->reordering = min_t(unsigned int, tp->reordering,
+ net->ipv4.sysctl_tcp_reordering);
+ tp->rack.reo_wnd_steps = 1;
+ icsk->icsk_ca_pacemaking_cnt ++;
+ }
icsk->icsk_retransmits++;
if (tcp_retransmit_skb(sk, tcp_rtx_queue_head(sk), 1) > 0) {
If pacing fails after the timeout of TLP, it may not be saved after the timeout of RTO. What else can be done at this time? The most pleasant way is not to expect overtime retransmission. Instead of dead retransmission, it's better to simply disconnect the TCP connection and reconnect. Unless all accessible routes fail or the network cable is disconnected, things will probably get better.
Shoes in Wenzhou, Zhejiang Province are wet. They won't get fat when it rains.