
Foreword
I believe everyone has heard of the index, but how many people can really use it? When writing SQL at ordinary times, you will really consider how this SQL can use the index and improve the execution efficiency?
This article describes several principles of index optimization in detail. As long as they can be applied at any time in work, I believe the SQL you write must be the most efficient and powerful.
The brain map of the article is as follows:
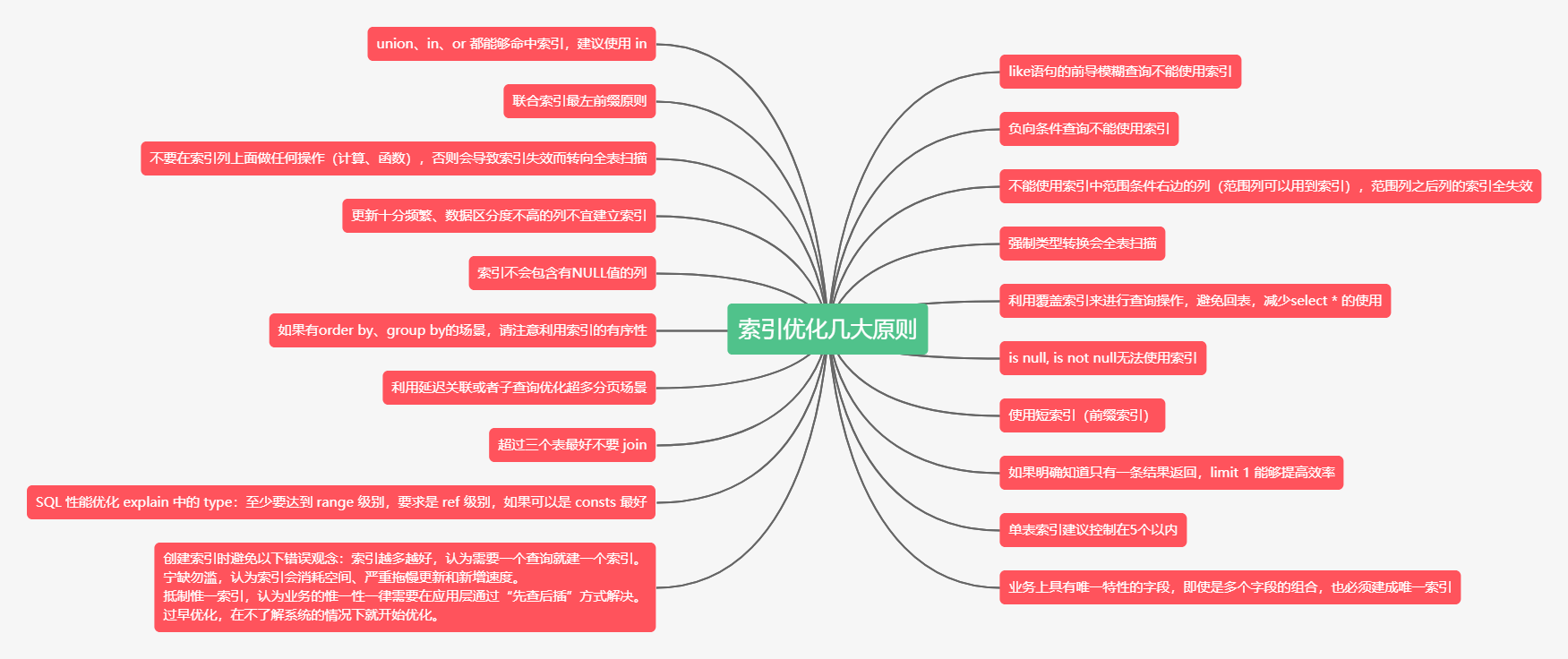
Index optimization rules
1. A leading fuzzy query of a like statement cannot use an index
select * from doc where title like '%XX'; --Cannot use index select * from doc where title like 'XX%'; --Non leading fuzzy query, index can be used
- 1.
- 2.
Because the page search is strictly prohibited from left blur or full blur, you can use the search engine to solve it if necessary.
2. union, in and or can hit the index. It is recommended to use in
union can hit the index, and MySQL consumes the least CPU.
select * from doc where status=1 union all select * from doc where status=2;
- 1.
- 2.
- 3.
in can hit the index. Query optimization consumes more CPU than union all, but it can be ignored. in is generally recommended.
select * from doc where status in (1, 2);
- 1.
Or new version of MySQL can hit the index. Query optimization consumes more CPU than in. It is not recommended to use or frequently.
select * from doc where status = 1 or status = 2
- 1.
Add: some places say that using or in the where condition will invalidate the index and cause full table scanning. This is a misunderstanding:
- ① It is required that all fields used in the where clause must be indexed;
- ② If the amount of data is too small, mysql finds that the full table scan is faster than the index search when making the execution plan, so the index will not be used;
- ③ Ensure that mysql version is above 5.0 and that the query optimizer has index enabled_ merge_ Union = on, that is, the variable optimizer_ Index exists in switch_ merge_ Union and is on.
3. Negative conditional queries cannot use indexes
- Negative conditions are:! =, < > not in, not exists, not like, etc.
- For example, the following SQL statement:
select * from doc where status != 1 and status != 2;
- 1.
Can be optimized as in query:
select * from doc where status in (0,3,4);
- 1.
4. Union index leftmost prefix principle
- If you create a joint index on three fields (a,b,c), it will automatically create a| (a,b) | (a,b,c) group index.
- Log in to the business requirements. The SQL statement is as follows:
select uid, login_time from user where login_name=? andpasswd=?
- 1.
- A federated index of (login_name, passwd) can be established. Because there is almost no single condition query requirement of passwd in the business, there are many logins_ Name, so you can create a joint index of (login_name, passwd) instead of (passwd, login_name).
- When establishing a joint index, the most distinguished field is on the left
- When there are mixed judgment conditions of non equal sign and equal sign, the column of equal sign condition shall be preceded when establishing the index. Such as where a >? and b=?, Then even if a has a higher degree of discrimination, B must be placed at the top of the index.
- When querying with the leftmost prefix, it does not mean that the where order of SQL statements should be consistent with the joint index.
- The following SQL statement can also hit the joint index (login_name, passwd):
select uid, login_time from user where passwd=? andlogin_name=?
- 1.
- However, it is recommended that the order after where is consistent with the joint index and form a good habit.
If index(a,b,c), where a=3 and b like 'abc%' and c=4, a can be used, b can be used, and C cannot be used.
5. The column on the right of the range condition in the index cannot be used (the range column can use the index). The indexes of the columns after the range column are invalid
- Range conditions include: <, < =, >, > =, between, etc.
- The index can be used for one range column at most. If there are two range columns in the query criteria, the index cannot be used completely.
- If there is a union index (empno, title, from date), EMP in the following SQL_ No can use index, while title and from_date does not use the index.
select * from employees.titles where emp_no < 10010' and title='Senior Engineer'and from_date between '1986-01-01' and '1986-12-31'
- 1.
6. Do not perform any operation (calculation, function) on the index column, otherwise the index will become invalid and turn to full table scanning
For example, the following SQL statement will scan the whole table even if the index is established on date:
select * from doc where YEAR(create_time) <= '2016';
- 1.
The optimization value can be calculated as follows:
select * from doc where create_time <= '2016-01-01';
- 1.
For example, the following SQL statement:
select * from order where date < = CURDATE();
- 1.
Can be optimized as:
select * from order where date < = '2018-01-2412:00:00';
- 1.
7. Cast type will scan the whole table
If the string type is not quoted, the index will be invalid, because mysql will perform type conversion by itself, which is equivalent to an operation on the index column.
If the phone field is of varchar type, the following SQL cannot hit the index.
select * from user where phone=13800001234
- 1.
Can be optimized as:
select * from user where phone='13800001234';
- 1.
8. It is not suitable to establish an index for columns with frequent updates and low data discrimination
- Updating will change the B + tree, and indexing the frequently updated fields will greatly reduce the database performance.
- "Gender" is an attribute with little differentiation. It is meaningless to establish an index. It can not effectively filter data. Its performance is similar to that of full table scanning.
- Generally, the index can be established when the discrimination is more than 80%, and the discrimination can be calculated by count (distinct) (column name)) / count(*).
9. The overlay index is used for query operation to avoid returning to the table and reduce the use of select *
- Overwrite index: the number of columns queried is the same as that of the established index, and the fields are the same.
- The data of the queried column can be obtained from the index instead of from the row locator to the row, that is, "the queried column should be overwritten by the built index", which can accelerate the query speed.
- For example, to log in to business requirements, the SQL statement is as follows.
Select uid, login_time from user where login_name=? and passwd=?
- 1.
- A joint index of (login_name, passwd, login_time) can be established_ Time has been established in the index. The uid and login to be queried_ Time does not need to get data from the row, so as to speed up the query.
10. The index will not contain columns with NULL values
As long as a column contains a null value, it will not be included in the index. As long as a column in a composite index contains a null value, this column is invalid for this composite index. Therefore, we try to use not null constraint and default value in database design.
11. is null, is not null cannot use index
12. If there are order by and group by scenarios, please pay attention to the order of the index
The last field of order by is a part of the composite index and is placed at the end of the index combination order to avoid the occurrence of file_sort affects query performance.
- For example, for the statement where a=? and b=? order by c, you can create a joint index (a,b,c).
If there is range search in the index, the index order cannot be used, such as where a > 10 order by B;, Index (a,b) cannot be sorted.
13. Use short index (prefix index)
- Index columns and specify a prefix length if possible. For example, if there is a CHAR(255) column, if the column is within the first 10 or 20 characters, you can make the discrimination of the prefix index close to the full column index, then do not index the whole column. Because short index can not only improve the query speed, but also save disk space and I/O operations, and reduce the maintenance cost of index files. You can use count (distinct leftindex) / count(*) to calculate the discrimination of the prefix index.
- However, the disadvantage is that it cannot be used for ORDER BY and GROUP BY operations, nor can it be used to overwrite indexes.
- However, in many cases, it is not necessary to establish an index for all fields. The index length can be determined according to the actual text discrimination.
14. Using delayed correlation or subquery to optimize super multi paging scenarios
MySQL does not skip the offset line, but takes the offset+N line, then returns the offset line before abandoning and returns the N line. When the offset is particularly large, the efficiency is very low. Either control the total number of pages returned or SQL rewrite the number of pages exceeding a specific threshold.
The example is as follows. First quickly locate the id segment to be obtained, and then associate it:
selecta.* from Table 1 a,(select id from Table 1 where condition limit100000,20 ) b where a.id=b.id;
15. If you know clearly that only one result is returned, limit 1 can improve efficiency
- For example, the following SQL statement:
select * from user where login_name=?;
- Can be optimized as:
select * from user where login_name=? limit 1 .
I know there is only one result, but the database doesn't know it. Tell it clearly and let it actively stop cursor movement.
16. It is better not to join more than three tables
- The data types of the fields that need to be join ed must be consistent. When querying multiple tables, ensure that the associated fields need to have indexes.
- For example, the left join is determined by the left. There must be all the data on the left, so the right is our key point, and the index should be built on the right. Of course, if the index is on the left, you can use right join.
17. It is recommended to control the single table index within 5
18. type in SQL performance optimization explain: at least reach the range level. It is required to be ref level. If it can be consts, it is best
- consts: there is at most one matching row (primary key or unique index) in a single table, and the data can be read in the optimization stage.
- ref: use normal index.
- Range: retrieve the range of the index.
- When type=index, the index physical files are scanned completely, and the speed is very slow.
19. For fields with unique business characteristics, even if they are a combination of multiple fields, a unique index must be built
Don't think that the unique index affects the insert speed. This speed loss can be ignored, but it is obvious to improve the search speed. In addition, even if a very perfect verification control is made in the application layer, as long as there is no unique index, according to Murphy's law, there must be dirty data.
20. Avoid the following misconceptions when creating an index
The more indexes, the better. If you think you need a query, you can build an index.
It is better to be deficient than excessive. It is believed that the index will consume space and seriously slow down the update and addition speed.
Resist the unique index and think that the uniqueness of the business needs to be solved in the application layer by "first check and then insert".
Optimize too early and start optimizing without knowing the system.
Index selectivity and prefix index
- Since the index can speed up the query, is it necessary to build the index as long as the query statement needs it? The answer is No. Although the index speeds up the query speed, the index also has a price: the index file itself consumes storage space, and the index will increase the burden of inserting, deleting and modifying records. In addition, MySQL also consumes resources to maintain the index when running. Therefore, the more indexes, the better. Generally, it is not recommended to build an index in two cases.
- In the first case, there are few table records. For example, for a table with one or two thousand or even only a few hundred records, there is no need to build an index. Just let the query scan the whole table. As for how many records count, this individual has his own view. My personal experience is that 2000 is the dividing line. If the number of records does not exceed 2000, we can consider not building an index, and if the number exceeds 2000, we can consider indexing as appropriate.
- Another situation where indexing is not recommended is the low selectivity of the index. The so-called index selectivity refers to the ratio of the non duplicate index value (also known as Cardinality) to the number of table records (#T):
Index Selectivity = Cardinality / #T
- Obviously, the value range of selectivity is (0,1] ` `. The higher the selectivity, the greater the index value, which is determined by the nature of B+Tree. For example, in the table employees.titles, if the title 'field is often queried separately, whether to build an index or not, let's take a look at its selectivity:
SELECT count(DISTINCT(title))/count(*) AS Selectivity FROM employees.titles; +-------------+ | Selectivity | +-------------+ | 0.0000 | +-------------+
- The selectivity of title is less than 0.0001 (the exact value is 0.00001579), so there is really no need to index it separately.
- An index optimization strategy related to index selectivity is called prefix index, which uses the prefix of the column instead of the whole column as the index key. When the current prefix length is appropriate, it can not only make the selectivity of the prefix index close to the full column index, but also reduce the size of the index file and maintenance overhead because the index key becomes shorter. Below, take employees Taking the employees table as an example, this paper introduces the selection and use of prefix index.
- Suppose the employees table has only one index < EMP_ No >, if we want to search a person by name, we can only scan the whole table:
EXPLAIN SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido'; +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+ | 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 300024 | Using where | +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
- If we search employees by name frequently, it is obviously inefficient, so we can consider building an index. There are two options, build < first_ Name > or
SELECT count(DISTINCT(first_name))/count(*) AS Selectivity FROM employees.employees; +-------------+ | Selectivity | +-------------+ | 0.0042 | +-------------+ SELECT count(DISTINCT(concat(first_name, last_name)))/count(*) AS Selectivity FROM employees.employees; +-------------+ | Selectivity | +-------------+ | 0.9313 | +-------------+
- <first_name > obviously, the selectivity is too low, ` < first_name, last_ Name > good selectivity, but first_name and last_ The total length of name is 30. Is there a way to give consideration to length and selectivity? First can be considered_ Name and last_ Index the first few characters of name, for example < first_name, left (last_name, 3) >, see its selectivity:
SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees.employees; +-------------+ | Selectivity | +-------------+ | 0.7879 | +-------------+
- The selectivity is good, but it's still a little far from 0.9313, so put the last_ Add name prefix to 4:
SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(*) AS Selectivity FROM employees.employees; +-------------+ | Selectivity | +-------------+ | 0.9007 | +-------------+
- At this time, the selectivity is ideal, and the length of this index is only 18, which is shorter than
ALTER TABLE employees.employees ADD INDEX `first_name_last_name4` (first_name, last_name(4));
- At this time, run the query by name again, and compare and analyze the results with those before indexing:
SHOW PROFILES; +----------+------------+---------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+---------------------------------------------------------------------------------+ | 87 | 0.11941700 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' | | 90 | 0.00092400 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' | +----------+------------+---------------------------------------------------------------------------------+
- The performance improvement is significant, and the query speed is increased by more than 120 times.
- Prefix index takes into account both index size and query speed, but its disadvantage is that it can not be used for ORDER BY and GROUP BY operations, nor for covering index (that is, when the index itself contains all the data required for query, the data file itself is no longer accessed).