Special invited author of enjoy learning class: Lao Gu
Reprint, please state the source
preface
I believe many friends have heard of gray release, but they don't necessarily know how to realize it? Today we will introduce the basic principle and provide code implementation to our partners.
Gray concept
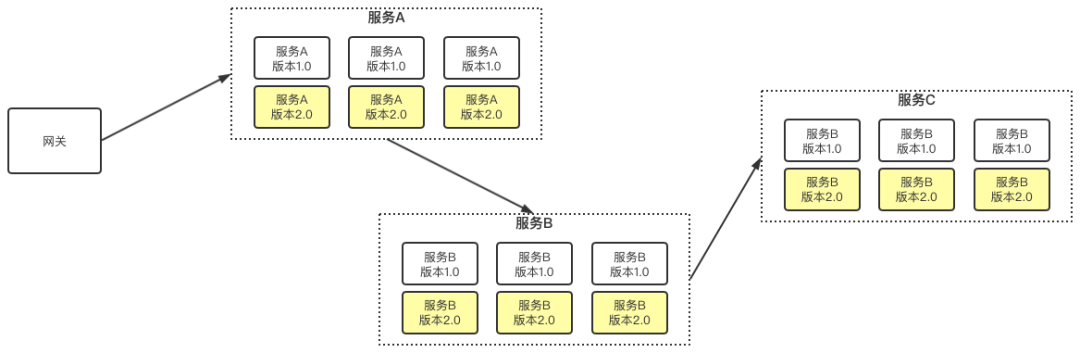
That is, the original production environment is version 1.0. Now we need to upgrade to version 2.0, but we need to verify that version 2.0 can be completely switched to version 2.0 only after the production environment is free from problems and stable.
Small partners will ask, version 2.0 should be tested by our testers. There must be no problem. Upgrade to 2.0, just upgrade directly.
This is wrong, because there are many scenarios unique to the production environment, such as user traffic, data volume, etc. Therefore, the stability of 2.0 must be verified; The upgrade steps are as follows:
1)100%User traffic hit 1.0 Version above; However, the tester can specify online 2 through the test tool.0 Version, that is, what the tester requested is 2.0 edition. 2)After the preliminary verification of the test, it can be divided into five parts%User traffic to 2.0 Version, 95%User traffic is still at 1.0 edition 3)View 2.0 The stable situation of user traffic is distributed in stages 4)Finish switching to 2.0 Version, offline 1.0 edition; Offline 1.0 In the version, different schemes will encounter different pits
Implementation principle I
Lao Gu's gray-scale framework is based on the springcloud alibaba ecosystem, and nacos is used in the registration center and configuration center; Let's take a look at the whole system architecture and the upgrade status:
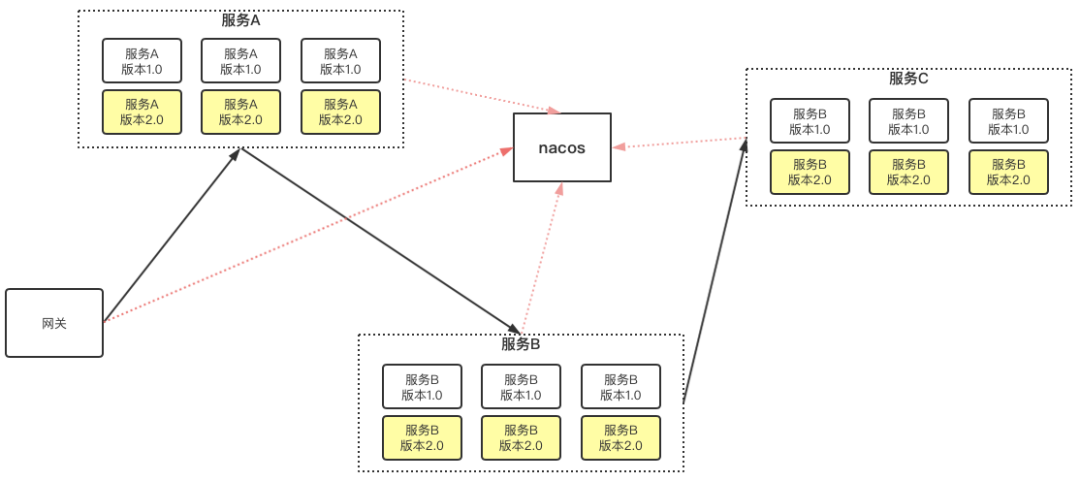
In spring cloud, how does the gateway know which service A is available, regardless of the entire request from gateway - > service A - > Service B - > Service C? How does service A know which service B is available? What service C does service B have?
This is because all our services are registered in the nacos registry, and then each service instance will request nacos through a 5-second heartbeat to obtain the registration information in nacos.
This is A very important point, the synchronization of service information; We can rewrite each service instance to do some filtering when pulling service information. For example, how can we ensure that service A (1.0) only accesses service B (1.0).
When calling service B, service A (1.0) needs to pull the service instance information of service B. when we find that there is version 2.0 in service B, we will filter it directly; 1.0 to synchronize to the local cache; This principle ensures that service A (1.0) instances can only access service B (1.0)
How to rewrite the pull service? It is to inherit the nacoserverlist, rewrite the getInitialListOfServers and getUpdatedListOfServers methods, and directly access the source code.

Second principle of realization
It is not enough to filter out unwanted versions only; Because we have another demand, that is, traffic weight; That is, service A can access service B (1.0), that is, service B (2.0); Only the proportion of flow weight is different; So how?
Then we need to use the rabion component of our client. This component is mainly used to call service instances, but can realize load balancing; Then we can rewrite the load balancing algorithm to meet the requirement of custom traffic weight.
The specific implementation is to inherit ZoneAvoidanceRule
**Rewrite Server choose(Object key), * * directly add the code
public class ZoneAvoidanceRuleDecorator extends ZoneAvoidanceRule {
. . . . . .
@Override
public Server choose(Object key) {
//todo selection logic
}
}
After knowing the basic principle, you can write directly.
Implementation principle III
Another requirement is that we need to consider changing the gray routing rules dynamically online, instead of restarting the service every time the rules are changed. This is wrong.
The implementation of this can consider using the functions of nacos itself. Subscribe to the changes of nacos configuration center, so as to achieve dynamic update.
case
Because of space, Gu here only introduces some principles and specific source code, which can be obtained from git. Give it to a star.
https://gitee.com/gujiachun/gray
Introduce dependency
1. The gray plugin framework starter service project needs to be introduced into the microservice project.
<dependency> <groupId>com.rainbow.gray</groupId> <artifactId>gray-plugin-framework-starter-service</artifactId> <version>1.0.0-SNAPSHOT</version> </dependency>
2. The gateway project needs to introduce the gray plugin framework starter Gateway project.
<dependency> <groupId>com.rainbow.gray</groupId> <artifactId>gray-plugin-framework-starter-gateway</artifactId> <version>1.0.0-SNAPSHOT</version> </dependency>
3. This component recommends using the remote configuration method to configure rule rules. Now it only supports the nacos configuration center.
4. The component supports global subscription or local subscription.
Global subscription: DataId = group1, Group=group1; That is, the DataId is also the group name, so that each micro service and gateway only subscribe to the same rule rule.
Local subscription: DataID = service name, Group=group1; That is, DataID is the service name, that is, only this service subscribes to rule rules; Other services are not applicable.
(Global subscription is recommended, because gray-scale publishing is generally effective for all services, and the rules of each service can be detailed in the rules)
Rule description
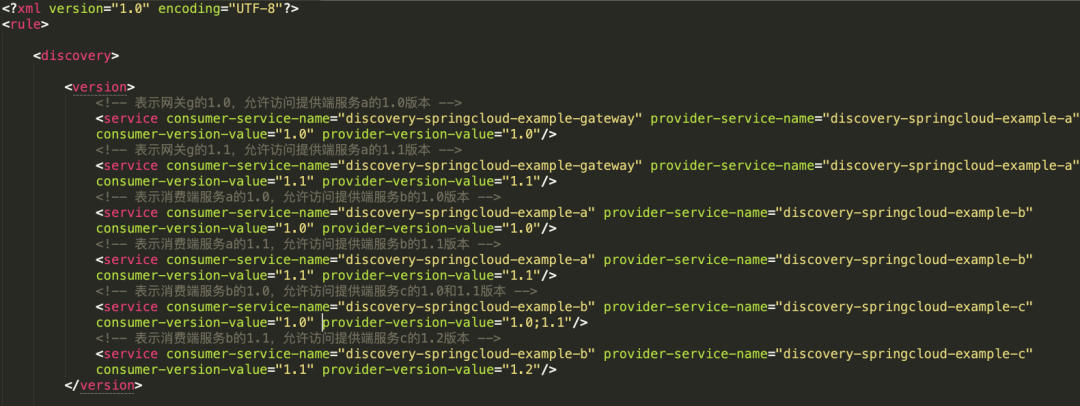
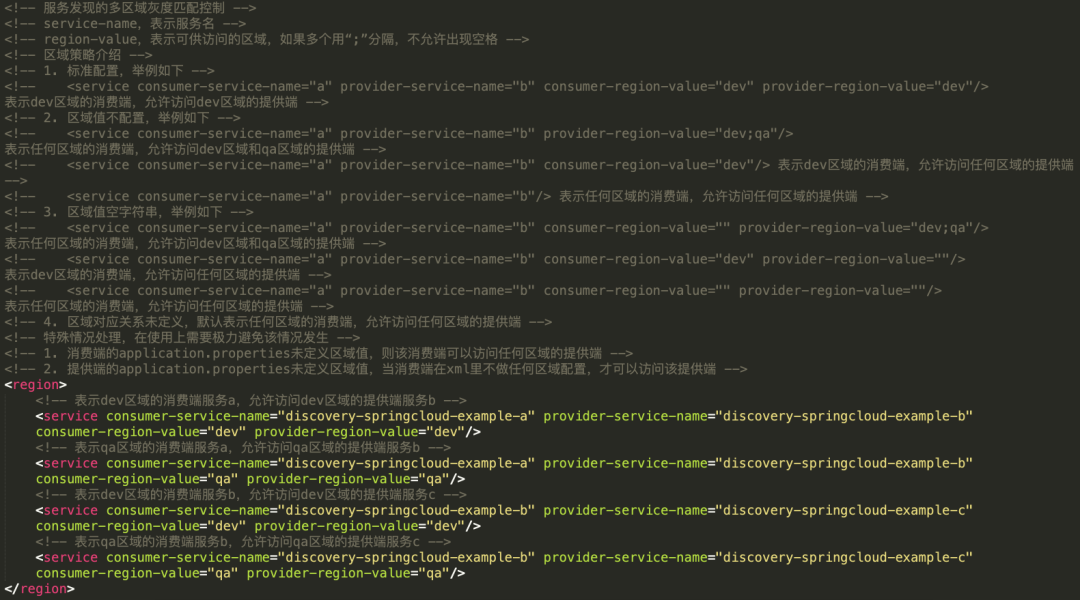


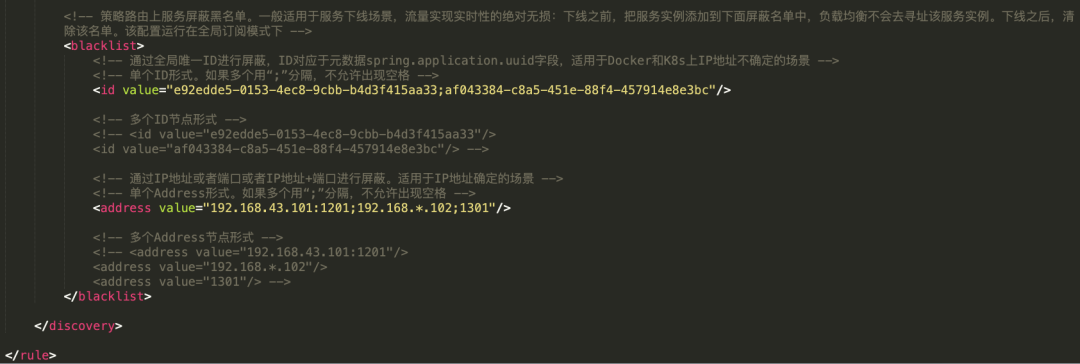
instructions
1. Configure nacos in bootstrap Configure the nacos registry in properties.
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848 spring.cloud.nacos.discovery.username=nacos spring.cloud.nacos.discovery.password=nacos spring.cloud.nacos.discovery.namespace=sit
2. In bootstrap The configuration required by the component in properties.
nacos.server-addr=${spring.cloud.nacos.discovery.server-addr}
nacos.username=${spring.cloud.nacos.discovery.username}
nacos.password=${spring.cloud.nacos.discovery.password}
nacos.plugin.namespace=${spring.cloud.nacos.discovery.namespace}
3. In application Properties configuration metadata is very important. This is the configuration related to different versions of each service, such as version, region, environment env and zone.
spring.cloud.nacos.discovery.metadata.group=example-service-group spring.cloud.nacos.discovery.metadata.version=1.0 spring.cloud.nacos.discovery.metadata.region=dev spring.cloud.nacos.discovery.metadata.env=env1 spring.cloud.nacos.discovery.metadata.zone=zone1
4. Affinity
Start and turn off the affinity of the availability zone, that is, the services of the same availability zone can be called. The condition of the same availability zone is that the Metadata zone configuration values of the calling end instance and the providing end instance must be equal. If it is missing, it defaults to false
spring.application.zone.affinity.enabled=true
The route after starting and closing the affinity failure of the availability zone, that is, when the caller instance does not find the provider instance of the same availability zone, when the switch is turned on, it can be routed to other availability zones or does not belong to any availability zone. When the switch is turned off, the direct call fails. If it is missing, it defaults to true
spring.application.zone.route.enabled=true
External parameter Header
The gray-scale routing strategy is introduced through the front-end (Postman) mode to replace the configuration center mode and transfer the whole link routing strategy. In this way, the tester can choose which path to take.
Note: when both the configuration center and external parameters are configured, the rules in the configuration center will be filtered first, and then the external parameters will be filtered again
-For version matching strategy, the Header format is optional as follows:
n-d-version=1.0
n-d-version={"discovery-guide-service-a":"2.0", "discovery-guide-service-b":"2.0"}
-Version weight policy, Header format: choose one of the following
n-d-version-weight=1.0=90;1.1=10
n-d-version-weight={"discovery-guide-service-a":"1.0=90;1.1=10", "discovery-guide-service-b":"1.0=90;1.1=10"}
-For the region matching policy, choose one of the following Header formats:
n-d-region=qa
n-d-region={"discovery-guide-service-a":"qa", "discovery-guide-service-b":"qa"}
-Region weight policy, Header format: choose one of the following
n-d-region-weight=dev=99;qa=1
n-d-region-weight={"discovery-guide-service-a":"dev=99;qa=1", "discovery-guide-service-b":"dev=99;qa=1"}
-IP address and port matching policy. The Header format is optional as follows
n-d-address={"discovery-guide-service-a":"127.0.0.1:3001", "discovery-guide-service-b":"127.0.0.1:4002"}
n-d-address={"discovery-guide-service-a":"127.0.0.1", "discovery-guide-service-b":"127.0.0.1"}
n-d-address={"discovery-guide-service-a":"3001", "discovery-guide-service-b":"4002"}
-Dynamic environment matching strategy under environment isolation
n-d-env=env1
-The service offline real-time traffic is absolutely lossless, and the global unique ID shielding strategy
n-d-id-blacklist=e92edde5-0153-4ec8-9cbb-b4d3f415aa33;af043384-c8a5-451e-88f4-457914e8e3bc
-The service offline real-time traffic is absolutely lossless, and the IP address and port shielding strategy
n-d-address-blacklist=192.168.43.101:1201;192.168.*.102;1301
When the external value Header is passed, the gateway also sets and passes the Header with the same name. It needs to decide which Header to pass to the subsequent service. It needs to be controlled through the following switches:
# When the external value Header is passed, the gateway also sets and passes the Header with the same name. It needs to decide which Header to pass to the subsequent service. If the following switch is true, the gateway setting takes precedence, otherwise the value transmitted from the outside takes precedence. If it is missing, it defaults to true spring.application.strategy.gateway.header.priority=false # When the gateway is set as the priority, the gateway does not configure the Header, but the external Header is configured, and the external Header is still ignored. If it is missing, it defaults to true spring.application.strategy.gateway.original.header.ignored=true # When the external value Header is passed, the gateway also sets and passes the Header with the same name. It needs to decide which Header to pass to the subsequent service. If the following switch is true, the gateway setting takes precedence, otherwise the value transmitted from the outside takes precedence. If it is missing, it defaults to true spring.application.strategy.zuul.header.priority=false # When the gateway is set as the priority, the gateway does not configure the Header, but the external Header is configured, and the external Header is still ignored. If it is missing, it defaults to true spring.application.strategy.zuul.original.header.ignored=true
summary
last
Why don't I fully advocate self-study?
① Daniel on the platform basically has many years of work experience. Have you ever thought about what the industry threshold was before and what the industry threshold is now? In the past, enterprises didn't have such high requirements for programmers' ability. Even more than a decade ago, you could get started in this industry as long as you could write "Hello World", so you could get started in the past.
② There are also some excellent young cattle. They may be self-taught, but they must have excellent learning ability, excellent self-management ability (time management, meditation, persistence, etc.) and be good at finding and summarizing problems.
If you think your goal is very clear and you can achieve the points mentioned in point ②, you are really suitable for self-study in the current market.
In addition, for the vast majority of people, class registration must be the best way to grow rapidly. But there is a problem. The quality of training institutions in the market is uneven. If you don't find a good training course, it's a waste of energy, time and money. You need to choose by yourself.
I personally suggest that the cost performance of online training is higher than that of offline training. The price of offline training is basically lower than that of 2W. Online education is now relatively mature. During the epidemic, students have basically felt the online learning mode. Compared with offline, the advantages of online are mainly in the following aspects:
① Price: the online price is basically half of the offline price;
② Teacher: relatively speaking, the teachers of online education are stronger and richer than offline education, and the resources are better coordinated;
③ Time: learning time is relatively more free. There is no need to study naked. It is suitable for learning and working while reducing the pressure of life;
④ Course: in terms of course content, it is more in-depth than offline.
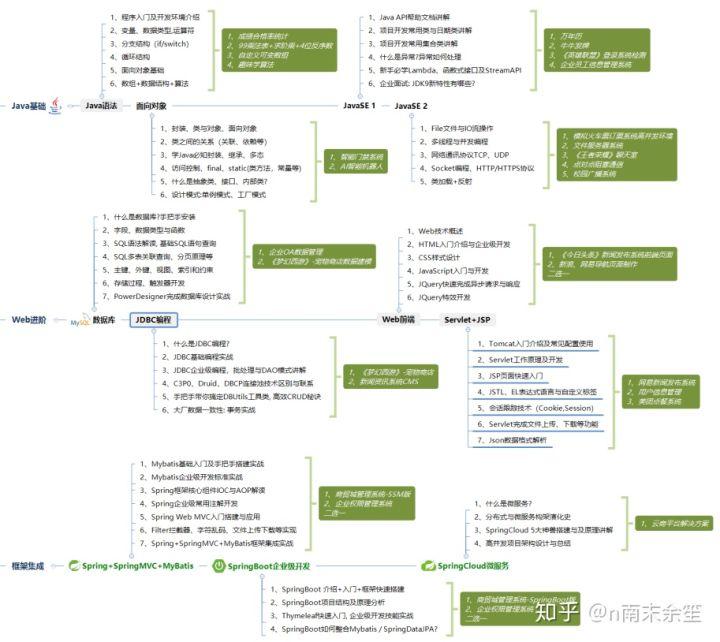
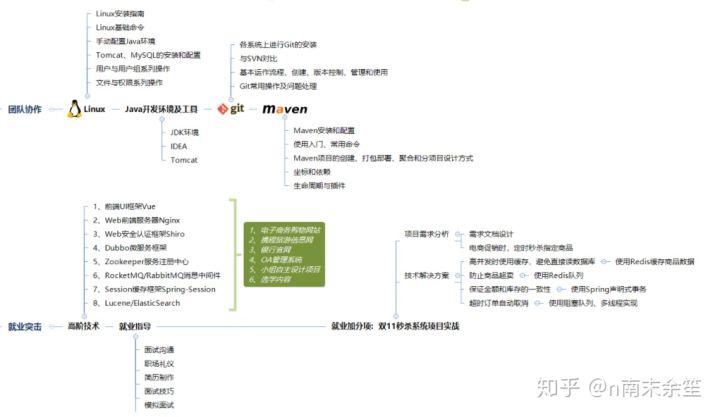
What technologies should be learned to meet the requirements of the enterprise? (summarized in the figure below)
Free access to a full set of Java materials: stamp here
: relatively speaking, the study time is more free, and there is no need to study naked. It is suitable for studying and working while reducing the pressure of life;
④ Course: in terms of course content, it is more in-depth than offline.
What technologies should be learned to meet the requirements of the enterprise? (summarized in the figure below)
Free access to a full set of Java materials: stamp here
[external chain picture transferring... (img-Rl3mi9Bt-1623619919167)]
[external chain picture transferring... (img-VMEhsFO6-1623619919167)]