How to solve the oversold problem of high price and high price?
A problem caused by second kill
- The biggest problem of second kill is to solve the problem of oversold. One way to solve oversold is as follows:
update goods set num = num - 1 WHERE id = 1001 and num > 0
Let's assume that there is only one item left, and num = 1 in the database;
But 100 threads read num = 1 at the same time, so 100 threads began to reduce inventory.
But you will eventually find that only one thread succeeded in reducing inventory, and all the other 99 threads failed.
Why?
This is why the exclusive lock in MySQL works.
Exclusive locks are also called write locks, or X locks for short. As the name suggests, exclusive locks cannot coexist with other locks. For example, if a transaction obtains an exclusive lock of a data row, other transactions cannot obtain other locks of the row, including shared locks and exclusive locks. However, the transaction that obtains an exclusive lock can read and modify the data row.
It is similar to that when I execute the update operation, this line is a transaction (exclusive lock is added by default). This line cannot be modified, read or written by any other thread
- The second way to solve oversold is as follows
select version from goods WHERE id= 1001; update goods set num = num - 1, version = version + 1 WHERE id= 1001 AND num > 0 AND version = @version(It's from above version);
update goods set num = num - 1, version = version + 1 WHERE id= 1001 AND version = @version(It's from above version);
In addition, a business logic judgment of whether the number of num is greater than 0 should be added before executing the sql statement.
In mysql, the exclusive lock is actually added here, but the version number is also a way to solve oversold, but the version method is used to replace the function of the statement num > 0 in the database, and the judgment of num > 0 is placed in the business logic.
In fact, there is a slight difference between the two ways to solve oversold. Consider two threads. When the inventory quantity is 2, if the first method is adopted, both threads can execute successfully. In the second way, if the second thread executes the same sql and gets the same version value before the first thread commits the transaction (that is, thread 1 and thread 2 get the same version value), then only one thread between the two threads can reduce the number of libraries by one and execute successfully. The final inventory number is not 0, but 1.
This method adopts the version number method, which is actually the principle of CAS.
Assume that version = 100 and num = 1; 100 threads enter here, and they select the version number as version = 100.
When updating directly, only one of them updates first and updates the version number at the same time.
When updating the other 99, you will find that the version is not equal to the version select ed last time, which means that the version has been modified by other threads. Then I'll give up this update
- The third way to solve oversold is as follows
Use the single thread of redis to pre reduce inventory.
For example, there are 100 items. Then I store a k,v in redis. For example < gs1001, 100 >
When each user thread comes in, the key value will be reduced by 1. When it is reduced to 0, all the remaining requests will be rejected.
Then, only 100 threads will enter the subsequent operation. Therefore, there will be no oversold phenomenon.
In many rush buying activities, under the limitation of the limited number of goods, how to ensure that the number of users who rush to buy goods cannot be greater than the number of goods, that is, there can be no oversold problem; In addition, there will be a large number of user visits during rush purchase. How to improve the effect of user experience is also a problem, that is, to solve the performance problem of second kill system.
This paper mainly introduces the second kill function of goods based on Redis. Let's talk about the general idea first. The general idea is to reduce the access to the database, cache the data into the Redis cache as much as possible, and get the data from the cache.
- When the system is initialized, the inventory quantity of goods is loaded into Redis cache. It does not need to be requested once before caching
- When receiving the second kill request, pre reduce the inventory in Redis. When the inventory in Redis is insufficient, it will directly return the second kill failure to reduce the access to the database. Otherwise, proceed to step 3;
- Put the request into the asynchronous queue (RabbitMQ) and immediately return a value to the front end, indicating that it is queued.
- The asynchronous queue on the server side will request to leave the queue. If the request is successful, the second kill logic can be carried out. Reduce inventory – > place order – > write the second kill order. If it is successful, it will return success.
- After the background order is created successfully, a second kill success notification can be sent to the user through websocket. The front end uses this to judge whether the second kill is successful. If the second kill is successful, enter the details of the second kill order, otherwise the second kill fails.
- When the system initializes, put the inventory of second kill goods into redis cache
//First, we need to implement the InitializingBean interface. The InitializingBean interface provides a way for beans to initialize methods, including the afterpropertieset method. All classes that inherit this interface will execute this method when initializing beans.
@Component
public class WebListener implements InitializingBean{
@Autowired
private RedisTemplate redistemplate;
@Override
public void afterPropertiesSet() throws Exception{
List<GoodsVo> goodsList = goodsService.listGoodsVo();
if(goodsList == null) {
return;
}
for(GoodsVo goods : goodsList) {
redistemplate.set(GoodsKey.getMiaoshaGoodsStock, ""+goods.getId(), goods.getStockCount());
localOverMap.put(goods.getId(), false);//First initialize that each item is false, that is, there is still inventory
}
}
}
//This enables us to load all caches when the system starts, and then we can pre reduce inventory by operating redis
- Pre inventory reduction requests are placed in asynchronous queues
//Then, when our concurrency is large enough, the pressure page of redis is very large. Then we can use the map set tag cache to reduce the pressure of redis server
// 1. Generate a map, and store the id of all products as the key and mark false in the map during initialization.
// 2. Before pre reducing the inventory, get the mark from the map. If the mark is false, it indicates the inventory, and,
// 3. Pre reduce inventory: when the inventory is insufficient, set the mark of the commodity to true, indicating that the inventory of the commodity is insufficient.
In this way, all the following requests will be intercepted without access redis Pre reduce inventory.
//When the system starts, it will be initialized, and all second kill commodity IDS will be stored in the map. If the inventory is 0, it is true
private Map<Long,Boolean> localOverMap = new HashMap<Long,Boolean>();
//====================================================================================
@RequestMapping(value="/{path}/do_miaosha", method=RequestMethod.POST)
@ResponseBody
public Result<Integer> miaosha(HttpServletRequest request, HttpServletResponse response,
Model model,MiaoshaUser user,
@RequestParam("goodsId")long goodsId,
@PathVariable("path") String path) {
model.addAttribute("user", user);
//If the user is empty, return to the login page
if(user == null) {
return Result.error(CodeMsg.SESSION_ERROR);
}
//Verify path
boolean check = miaoshaService.checkPath(user, goodsId, path);
if(!check){
return Result.error(CodeMsg.REQUEST_ILLEGAL);
}
//Memory mark, judging from the value of map, reducing redis access
boolean over = localOverMap.get(goodsId);
if(over) {
return Result.error(CodeMsg.MIAO_SHA_OVER);
}
//Pre inventory reduction here is an atomic operation
long stock = redisService.decr(GoodsKey.getMiaoshaGoodsStock, ""+goodsId);//10
if(stock < 0) {
localOverMap.put(goodsId, true);
return Result.error(CodeMsg.MIAO_SHA_OVER);
}
//Determine whether the second kill has been reached
MiaoshaOrder order = orderService.getMiaoshaOrderByUserIdGoodsId(user.getId(), goodsId);
if(order != null) {
return Result.error(CodeMsg.REPEATE_MIAOSHA);
}
//Join the team
MiaoshaMessage mm = new MiaoshaMessage();
mm.setUser(user);
mm.setGoodsId(goodsId);
sender.sendMiaoshaMessage(mm);
//Return 0 to represent queuing
return Result.success(0);
}
// Redis relieves the pressure on the database and marks the inventory with map to relieve the pressure on redis
There is another way to write:
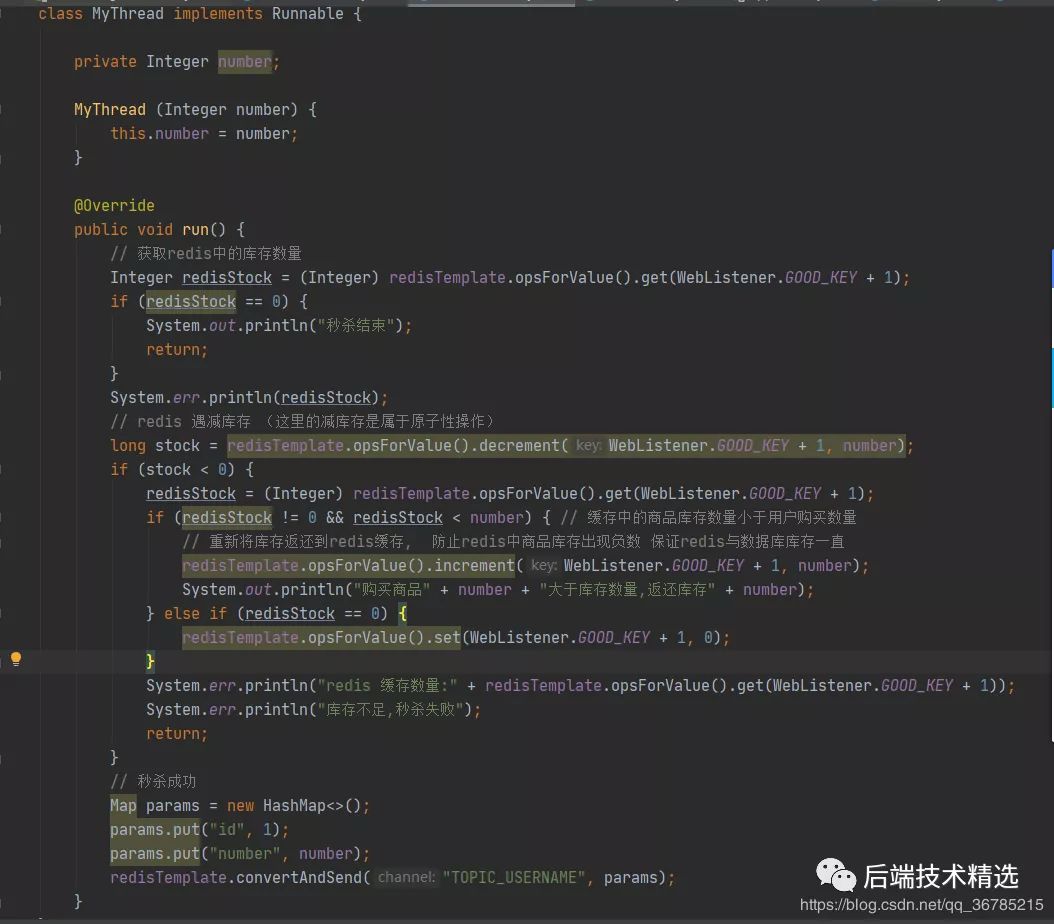
The increment operation in the redis api is used here to pre reduce the number of users' rush purchases, and judge whether the inventory in redis is greater than the number of users' rush purchases. If it is less than 0, the user will be directly prompted that the second kill fails, otherwise the second kill succeeds, enter the redis message queue and perform the database inventory creation operation.
- Because it is written to the database through asynchronous queue, there may be data inconsistency.
[chat seckill system (II) solving consistency problems - Zhihu (zhihu.com)](