How to use the process? What is the difference between and thread usage?
When doing network IO programming, a very ideal situation is to allocate a thread to the new client every time accept returns. Such a client corresponds to a thread. There will be no multiple threads sharing a sockfd. Per request per thread, and the code logic is very readable. But this is only ideal. The cost of thread creation and scheduling is hehe.
Let's take a look at the code of each request and each thread as follows:
while(1) {
socklen_t len = sizeof(struct sockaddr_in);
int clientfd = accept(sockfd, (struct sockaddr*)&remote, &len);
pthread_t thread_id;
pthread_create(&thread_id, NULL, client_cb, &clientfd);
}
In this way, after writing, put it under the production environment. If your boss doesn't kill you, you come to me. Let me help your boss and eliminate harm for the people.
If we have a collaborative process, we can do so. Reference codes are as follows:
https://github.com/wangbojing/NtyCo/blob/master/nty_server_test.c
while (1) {
socklen_t len = sizeof(struct sockaddr_in);
int cli_fd = nty_accept(fd, (struct sockaddr*)&remote, &len);
nty_coroutine *read_co;
nty_coroutine_create(&read_co, server_reader, &cli_fd);
}
Such code can be placed under the generation environment. If your boss wants to kill you, come to me and I'll help you kill your boss and eliminate harm for the people.
Thread API thinking to use the coprocessor, and function call performance to test the coprocessor.
NtyCo encapsulates several interfaces, one is the co process itself, and the other is the asynchronous encapsulation of posix
Collaboration API: while
1. Collaboration creation
int nty_coroutine_create(nty_coroutine **new_co, proc_coroutine func, void *arg)
2. Operation of coordination scheduler
void nty_schedule_run(void)
POSIX asynchronous encapsulation API:
int nty_socket(int domain, int type, int protocol) int nty_accept(int fd, struct sockaddr *addr, socklen_t *len) int nty_recv(int fd, void *buf, int length) int nty_send(int fd, const void *buf, int length) int nty_close(int fd)
The interface format is consistent with the function definition of POSIX standard.
How does the process work internally?
Let's take a look at the code of the collaborative process server case. For the code reference: https://github.com/wangbojing/NtyCo/blob/master/nty_server_test.c
Discuss the obscure workflow of the three collaborative processes respectively. Creation of the first cooperation process; The second IO asynchronous operation; The third subprocess callback
Create collaboration
When we need asynchronous calls, we create a coroutine. For example, accept returns a new sockfd and creates a sub process for client processing. For another example, when you need to listen to multiple ports, create a server sub process, so that multiple ports work at the same time, which is in line with the microservice architecture.
What is the work done when creating a collaboration? Create API as follows:
int nty_coroutine_create(nty_coroutine **new_co, proc_coroutine func, void *arg)
Parameter 1: nty_coroutine **new_co, you need to pass in an empty coroutine object. This object is internally created, and an internally created coroutine object will be returned when the function returns.
Parameter 2: proc_coroutine func, a subprocess of a coprocess. This function is executed when the coroutine is scheduled.
Parameter 3: void *arg, which needs to be passed into the new collaboration.
There is no kinship in the coordination process. They all have the same scheduling relationship and accept the scheduling of the scheduler. Calling the create API will create a new workflow, and the new workflow will be added to the ready queue of the scheduler.
The specific steps of creating a collaboration will be described in primitive operation of collaboration implementation.
Realize IO asynchronous operation
Most friends will be concerned about how to implement IO asynchronous operation and how to implement asynchronous operation when send ing and recv are called.
Let's take a look at a piece of code:
while (1) {
int nready = epoll_wait(epfd, events, EVENT_SIZE, -1);
for (i = 0;i < nready;i ++) {
int sockfd = events[i].data.fd;
if (sockfd == listenfd) {
int connfd = accept(listenfd, xxx, xxxx);
setnonblock(connfd);
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = connfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, connfd, &ev);
} else {
epoll_ctl(epfd, EPOLL_CTL_DEL, sockfd, NULL);
recv(sockfd, buffer, length, 0);
//parser_proto(buffer, length);
send(sockfd, buffer, length, 0);
epoll_ctl(epfd, EPOLL_CTL_ADD, sockfd, NULL);
}
}
}
Before the IO operation (recv, send), execute the del operation of epoll_ctl, delete the corresponding sockfd from epfd, and then perform the add action of epoll_ctl after the IO operation (recv, send). This code seems to have no effect.
This makes sense in multiple contexts. It can ensure that sockfd can operate IO in only one context. It will not occur when multiple contexts operate on one IO at the same time. The IO asynchronous operation of the coroutine is formally carried out in this mode.
Clear the division between the work of a single process and the work of the scheduler. First introduce two primitive operations resume. yield will explain the implementation of all primitive operations of the process in the primitive operation of process implementation. yield is to give up the operation and resume is to resume the operation. The context switching between the scheduler and the orchestration is shown in the following figure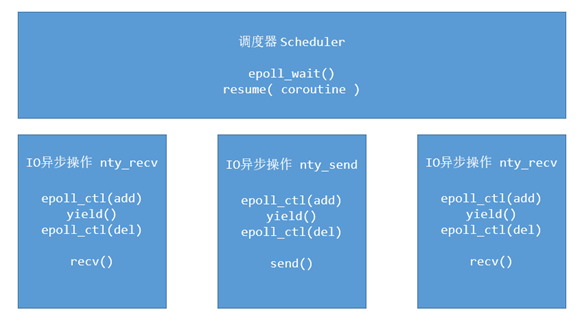
IO asynchronous operation (nty_recv, nty_send) function in the context of coroutine. The steps are as follows:
- Add sockfd to epoll management.
- Switch the context from the process context yield to the scheduler context.
- The scheduler obtains the next collaboration context. Resume new collaboration
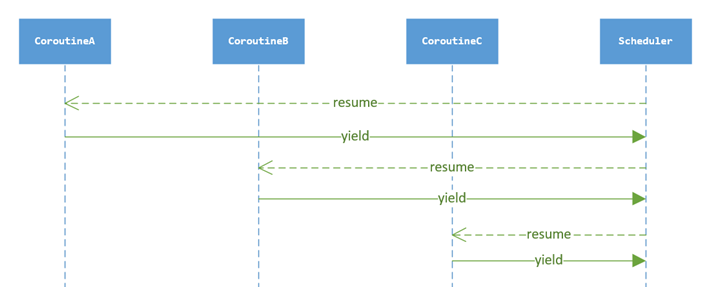
The sequence diagram of context switching of IO asynchronous operation is as follows:
Subprocess of callback process
When will the subprocess be recalled after creating the subprocess? How to tune back the subprocess?
First, let's review x86_64 register related knowledge. The related knowledge of assembly and register will be further discussed in the implementation switching of coprocessor. x86_64 registers have 16 64 bit registers, namely:% rax,% RBX,
%rcx, %esi, %edi, %rbp, %rsp, %r8, %r9, %r10, %r11, %r12, %r13, %r14, %r15.
%rax is used as the return value of the function.
%rsp stack pointer register, pointing to the top of the stack
%RDI,% RSI,% RDX,% RCX,% R8,% R9 are used as function parameters, corresponding to the first parameter in turn, and the second parameter,% RBX,% RBP,% R12,% R13,% R14,% R15 are used as data storage, following the caller's use rules, in other words, they are used casually. Before calling a sub function, it should be backed up to prevent it from being modified%r10 and% R11 from being used as data storage, that is, the original value should be saved before use
Take the implementation of NtyCo as an example to analyze this process. The CPU has a very important register called EIP, which is used to store the address of the next instruction run by the CPU. We can store the address of the callback function in the EIP and the corresponding parameters in the corresponding parameter register. The logic code to realize the sub procedure call is as follows:
void _exec(nty_coroutine *co) {
co->func(co->arg); //Callback function of subprocess
}
void nty_coroutine_init(nty_coroutine *co) {
//ctx is the context of the coroutine
co->ctx.edi = (void*)co; //Set parameters
co->ctx.eip = (void*)_exec; //Set callback function entry
//When context switching is implemented, the entry function is executed_ exec , _exec calls sub procedure func
}
Implementation of collaborative framework, underlying principle and performance analysis (C language)
1. Origin of collaborative process
Origin of Synergy - why does it exist?
How to use? What is the difference between and thread usage?
How does the interior work?
What are primitive operations? How are they implemented?
2. Switching of collaborative process implementation - how to switch the context? How is the code implemented?
How to define the running body? How is the scheduler defined?
How is the collaboration scheduled?
Concurrent multi-core mode - Multi-core implementation
Collaborative performance test - actual performance test
Don't understand the process? Can't use CO process?