The Thread class in JAVA is a Thread class. When JAVA is based on this class, the understanding of threads is based on this class. Why not use Thread to directly execute Thread examples, but use Thread pool? You can imagine that when there are a large number of concurrent threads and each Thread executes a task for a short time, the efficiency of the system will be greatly reduced because it takes time to create and destroy threads frequently. The Thread pool can achieve this effect: threads can be reused, that is, after executing a task, they can continue to execute other tasks without being destroyed.
Disadvantages of Thread:
- Each time new Thread() creates a new object, the performance is poor;
- Threads lack unified management and may create unlimited new threads, compete with each other, and may occupy too many system resources, resulting in panic or OOM;
- Lack of more functions, such as more execution, periodic execution and thread interruption;
Benefits of thread pooling
- Reuse existing threads, reduce the overhead of object creation and extinction, have good performance and reduce resource consumption;
- It can effectively control the maximum number of concurrent threads and improve the utilization of system resources. At the same time, it can avoid excessive resource competition, avoid blocking and improve the response speed;
- It provides functions such as regular execution, regular execution, single thread and concurrency control, so as to improve the manageability of threads.
In the java development manual released by Ali, the mandatory thread pool is not allowed to be created using Executors, but through ThreadPoolExecutor. This processing method makes the students who write more clear about the running rules of thread pool and avoid the risk of resource depletion. (focus on the official account SpringForAll community, send the key words "manual", and receive free Alibaba Java development manual).
Executors provide us with four ways to implement thread pool by using factory mode, but it is not recommended. The reason is that using executors to create thread pool will not pass in relevant parameters, but use default values. Therefore, we often ignore those important parameters (thread pool size, buffer queue type, etc.), and the default parameters will lead to waste of resources, which is undesirable.
ThreadPoolExecutor
Constructor And Parameters
java. uitl. concurrent. The ThreadPoolExecutor class is the core class in the thread pool. Therefore, if you want to thoroughly understand the thread pool in Java, you must first understand this class. Therefore, we can go directly to the source code:
public class ThreadPoolExecutor extends AbstractExecutorService {
/** Constructor 1 */
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {}
/** Constructor 2 */
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {}
/** Constructor 3 */
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {}
/** Constructor 4 */
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {}
}
ThreadPoolExecutor` The class inheritance structure is:`Executor(I) <- ExecutorService(I) <- AbstractExecutorService(C) <- TreadPoolExecutor
ThreadPoolExecutor class provides four construction methods. Constructor 4 has the most parameters. By observing the other three constructors, it is found that the first three constructors are the initialization of the fourth constructor.
Meanings of parameters in constructor:
-
corePoolSize: the size of the core pool. This parameter is closely related to the implementation principle of the thread pool described later. After the thread pool is created, by default, there are no threads in the thread pool, but wait for a task to arrive before creating a thread to execute a task, unless the method of pre creating a thread is called, that is, a corePoolSize thread or a thread is created before no task arrives:
By default, after the thread pool is created, the number of threads in the thread pool is 0. When a task comes, a thread will be created to execute the task. When the number of threads in the thread pool reaches the corePoolSize, the arriving task will be placed in the cache queue;
-
- prestartCoreThread(): pre creates a core thread and makes it idle waiting for work.
- prestartAllCoreThreads(): starts all core threads, causing them to wait idle for work.
-
maximumPoolSize: the maximum number of threads in the thread pool. This parameter is also a very important parameter. It indicates the maximum number of threads that can be created in the thread pool;
-
keepAliveTime: indicates how long the thread will terminate if it has no task to execute. By default, keepAliveTime works only when the number of threads in the thread pool is greater than corePoolSize, until the number of threads in the thread pool is not greater than corePoolSize, that is, when the number of threads in the thread pool is greater than corePoolSize, if a thread is idle for keepAliveTime, it will terminate until the number of threads in the thread pool does not exceed corePoolSize. However, if the allowCoreThreadTimeOut(boolean) method is called and the number of threads in the thread pool is not greater than corePoolSize, the keepAliveTime parameter will also work until the number of threads in the thread pool is 0;
-
Unit: the time unit of the parameter keepAliveTime. There are seven values. In the TimeUnit class, there are seven static attributes:
-
- TimeUnit.DAYS: in days;
- TimeUnit.HOURS: in hours;
- TimeUnit.MINUTES: in minutes;
- TimeUnit.SECONDS: in seconds;
- TimeUnit.MILLISECONDS: in milliseconds;
- TimeUnit.MICROSECONDS: in microseconds;
- TimeUnit.NANOSECONDS: in nanoseconds;
-
workQueue: a blocking queue used to store tasks waiting to be executed. The selection of this parameter is also very important and will have a significant impact on the running process of the thread pool. Generally speaking, the blocking queue here has the following options:
LinkedBlockingQueue and SynchronousQueue are generally used
-
- ArrayBlockingQueue: array based first in first out queue. The size must be specified when creating this queue;
- LinkedBlockingQueue: a linked list based first in first out queue. If the queue size is not specified when it is created, it defaults to integer MAX_ VALUE;
- Synchronous queue: this queue is special. It will not save the submitted tasks, but will directly create a new thread to execute the new tasks.
-
Threadfactory: thread factory, mainly used to create threads. One of the most important tasks of thread pool is to create threads when certain conditions are met. In the ThreadPoolExecutor thread pool, the creation of threads is left to threadfactory. To use a thread pool, you must specify threadfactory. If the constructor we use does not specify the threadfactory to be used, the ThreadPoolExecutor will use a default threadfactory: DefaultThreadFactory (this class is in the Executors tool class);
-
handler: there is another important interface in the ThreadPoolExecutor thread pool: RejectedExecutionHandler. When a new task submitted to the thread pool cannot be directly processed by the "core thread" in the thread pool, cannot join the waiting queue, and cannot create a new thread for execution; Or the thread pool has called the shutdown() method to stop working; Or the thread pool is not in normal working state; At this time, the ThreadPoolExecutor thread pool will refuse to handle this task and trigger the implementation of the RejectedExecutionHandler interface defined when creating the ThreadPoolExecutor thread pool,
Indicates the policy when processing a task is rejected. There are four values, all of which are static internal classes:
-
- ThreadPoolExecutor.AbortPolicy: discards the task and throws RejectedExecutionException.
- ThreadPoolExecutor.DiscardPolicy: also discards tasks without throwing exceptions.
- ThreadPoolExecutor.DiscardOldestPolicy: discard the task at the top of the queue, and then try to execute the newly submitted task again.
Operating principle
After introducing the above constructor and its parameters, let's introduce the operation principle of ThreadPoolExecutor. I browsed a related article on the Internet, so I referenced it directly
Deeply understand the java thread pool - ThreadPoolExecutor. The following contents refer to this article and add a little understanding
ThreadPoolExecutor.execute()
Submit a task to the thread pool that does not need to return results
public void execute(Runnable command) {
//If the task is null, an exception is thrown
if (command == null)
throw new NullPointerException();
//Take out the current value of ctl recording runState and workerCount
int c = ctl.get();
/**
* 1.Step 1:
* Use the workerCountOf method to extract the lower 29 bit value from the int value represented by ctl, that is, the number of currently active threads.
* If the number of currently active threads is less than corePoolSize, create a new thread through addWorker(command, true) and add a task (command) to the thread
*/
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
/**
* 2.Step 2:
* 2.1 isRunning(c) Whether the current thread pool is RUNNING. The source code determines the return value by judging C < SHUTDOWN. Because RUNNING will receive new tasks, and only this value - 1 is less than SHUTDOWN
* 2.2 workQueue.offer(command) Add task to buffer queue
*/
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
/**
* If the thread pool is already in a non running state, remove the task from the buffer queue and reject the task using the policy specified by the thread pool
*/
if (! isRunning(recheck) && remove(command))
reject(command);
/**
* If the number of tasks in the thread pool is 0, try to create a new thread through addWorker(null, false), and the corresponding task of the new thread is null
*/
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
/**
* 3.The third step, that is, the above two steps are not satisfied:
* 3.1 The current thread pool is not in Running state
* 3.2 The current thread pool is in Running state, but the buffer queue is full
*/
else if (!addWorker(command, false))
reject(command);
}
From the execute() method above, ctl appears, and tracing source code analysis works:
//The 32 bits of integer are divided into high 3 bits and low 29 bits. The high 3 bits represent the status of thread pool and the low 29 bits represent the number of active threads private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); //Get the top three private static final int COUNT_BITS = Integer.SIZE - 3; //The largest binary integer represented by 29 bits, that is, the number of active threads private static final int CAPACITY = (1 << COUNT_BITS) - 1; //The operating status is stored in the upper three bits private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS;
Thread pool indicates the status of the current thread pool through the upper 3 bits of Integer type. RUNNING, SHUTDOWN, STOP, TIDYING and TERMINATED. The lower 29 bits indicate the number of RUNNING tasks of the current thread. Then, the number of RUNNING states and tasks are calculated by bit operation.

The thread pool is executing (runnable), and the execution process is as follows (corresponding to the process in the figure)
- If the number of threads currently running is less than corePoolSize, a new thread is created to perform the task (a global lock is required)
- If the threads running are equal to or more than corePoolSize, add the task to BlockingQueue
- If the task cannot be added to the BlockingQueue (the queue is full), create a new thread to process the task (you need to obtain a global lock)
- If creating a new thread will cause the currently running thread to exceed the maximpoolsize, the task will be rejected and rejectedexecutionhandler will be called Rejectedexecution() method.
The thread pool is designed according to the above process to reduce the number of global locks. After the thread pool is warmed up (the number of currently running threads is greater than or equal to corePoolSize), almost all execute method calls execute step 2.
ThreadPoolExecutor.addWorker()
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get(); //Get running status and work quantity
int rs = runStateOf(c); //Gets the running status of the current thread pool
// Check if queue empty only if necessary.
//Conditions represent the following scenarios. If false is returned directly, it indicates that the creation of the current worker thread failed
//1. RS > shutdown no longer receives new tasks, and all tasks have been executed
//2.rs=SHUTDOWN will not receive new tasks at this time, but will execute the tasks in the queue
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
//First judge whether the number of currently active threads is greater than the maximum value. If it exceeds the maximum value, it will directly return false, indicating that thread creation failed
//If not, make the following judgment according to the value of core
//1. If core is true, judge whether the number of currently active threads is greater than corePoolSize
//2. If core is false, judge whether the current number of active threads is greater than maximumPoolSize
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//Compare whether the current value is the same as c. if it is the same, change it to c+1, jump out of the large loop, and directly execute the Worker for thread creation
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
//Check whether the status of the current thread pool has changed
//If it has been changed, carry out the outer retry cycle, otherwise only the inner cycle
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//Worker is also an implementation class of Runnable
w = new Worker(firstTask);
//Because you can't create threads directly in the Worker's construction method
//Therefore, its reference should be assigned to t to facilitate thread creation later
final Thread t = w.thread;
if (t != null) {
//Lock
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);//Add the created thread to the workers container
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
Worker
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable{
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
}
Worker implements the Runnable interface for an internal class in ThreadPoolExecutor. There is only one constructor. In addWorker() above, final Thread t = w.thread; You know that you actually get the object of the thread, because in the construction method, the reference of the thread is itself.
Therefore, when calling t.start(), you execute (the method in the Worker class):
/** Delegates main run loop to outer runWorker */
public void run() {
//The runWorker in ThreadPoolExecutor is executed here
runWorker(this);
}
ThreadPoolExecutor.runWorker()
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;//Get tasks in Worker
w.firstTask = null; //Empty the task in Woeker
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//If the current task is empty, get the task from getTask
/**
* If the task is not empty, set the task to empty after the task is executed
* If you continue to enter the loop, get the task from getTask
*/
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//Method of calling before task execution
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//Method called after task completion
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
It can be simply understood from the above that executing a task is only processing required for executing a task, including obtaining a task, processing before starting a task, task execution, and processing after task execution. However, the key code is a method called getTask().
beforeExecute(Thread t, Runnable r) and afterExecute(Runnable r, Throwable t) do not have business processing logic in the class, that is, they can be overridden by inheriting the thread pool, so that task execution can be monitored.
I have two questions here?
-
How to exit the While loop, that is, to enter processWorkerExit()
-
- You can know from the body of the While loop that if an exception occurs when the thread is running, it will exit the loop and enter processWorkerExit()
- If the result obtained from getTask() is null, it will also go to processWorkerExit()
-
Why is the getTask() method the most critical? Analyze its execution code
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
//Dead cycle
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
//If allowcorethreadtimeout is set (true)
//Or the number of currently running tasks is greater than the set number of core threads
// timed = true
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
/** ------------------------The above operation is similar to that before----------------------- */
/** ------------------------The key is the following code------------------------- */
/** ------------------------Get task from blocking queue----------------------- */
try {
Runnable r = timed ?
//For the blocking queue, poll(long timeout, TimeUnit unit) will go to the task within the specified time
//If not, null is returned
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
//take will be blocked all the time, waiting for the task to be added
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
At this point, I finally found out why the thread pool can guarantee to wait for tasks without being destroyed. In fact, it has entered the blocking state.
ThreadPoolExecutor.processWorkerExit()
/**
* @param completedAbruptly Whether the worker thread is dead is related to the exception of executing the task
*/
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) //If you are suddenly interrupted, the number of worker threads will not be reduced
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
tryTerminate();
int c = ctl.get();
//Judge whether the running status is before STOP
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {//Exit normally, that is, task == null
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
//Add a new worker thread to replace the original worker thread
addWorker(null, false);
}
}
AbstractExecutorService.submit()
Submit a task to the thread pool that needs to return results
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
Submit() is not found in ThreadPoolExecutor. Therefore, find the method implementation of submit() from the parent class, that is, the abstract class AbstractExecutorService. From the method implementation, we can see:
- submit() receives the task parameters and encapsulates them as FutureTask task class
- Submit the encapsulated FutureTask to execute()
Conclusion: the task processing process implemented by submit() is the same as that of execute(). It can also be said that submit() calls execute()
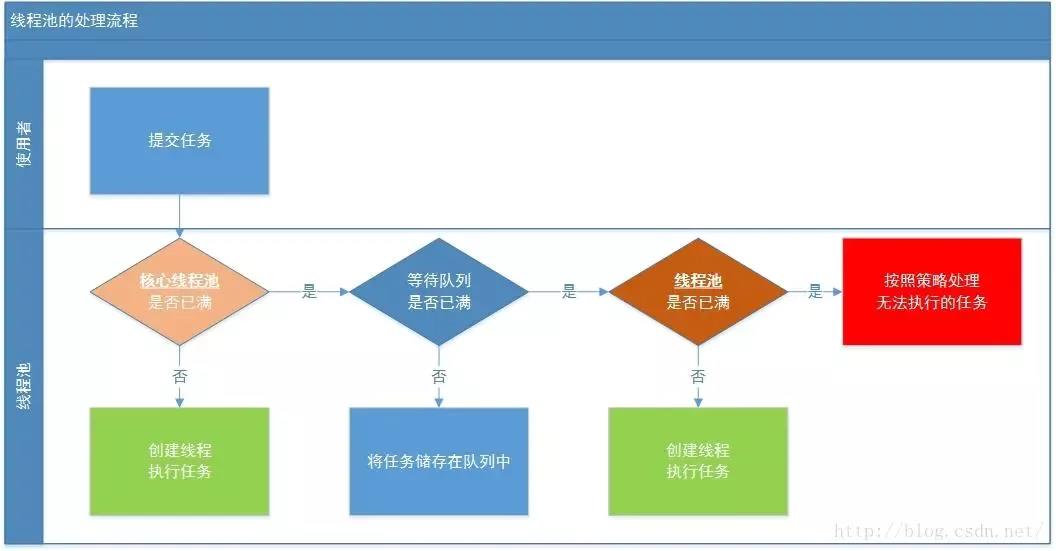
As can be seen from the above flow chart, after submitting a task to the thread pool, it goes through the following processes:
- Submit tasks to the thread pool;
- The thread pool determines whether all the threads in the core thread pool are executing tasks. If not, create a new worker thread to execute tasks. If all the threads in the core thread pool are executing tasks, the next process is entered.
- The thread pool determines whether the work queue is full. If the work queue is not full, the newly submitted task is stored in the work queue. If the work queue is full, proceed to the next process.
- The thread pool determines whether all its internal threads are working. If not, a new worker thread is created to execute the task. If it is full, it is left to the saturation strategy to handle the task.
ThreadPoolExecutor.shutdown()
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();//Check whether the thread terminating the thread pool has permission.
advanceRunState(SHUTDOWN);// Set the status of the thread pool to off.
interruptIdleWorkers();// Interrupt idle threads in the thread pool
onShutdown(); // Hook function, no action in ThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();// Attempt to terminate thread pool
}