For Ubuntu installation, please refer to< How to quickly install Ubuntu 18 04>
For the configuration of samba service, please refer to< How to configure Samba service in Ubuntu>
0. You need to download and install torch when installing Darknet 2caffe environment
- When executing pip3 install torch, it will always be killed, so you need to configure the running memory of Ubuntu.
Make sure your Ubuntu is in the shutdown state, click memory, adjust the memory to 4GB (at least), and then boot Ubuntu. At this time, the running memory of Ubuntu is 4GB.
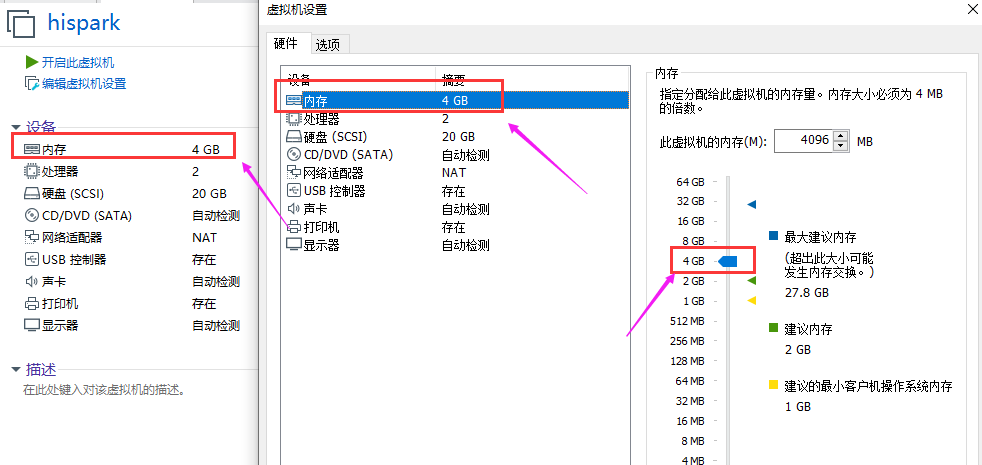
1, At Ubuntu 18 Installing caffe environment on 04
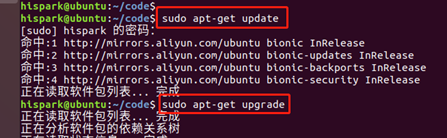
1. Execute the following commands step by step to update the software in Ubuntu
sudo apt-get update sudo apt-get upgrade
2. Execute the following commands step by step to install the required dependent software.
sudo apt-get install -y libopencv-dev sudo apt-get install -y build-essential cmake git pkg-config sudo apt-get install -y libprotobuf-dev libleveldb-dev libsnappy-dev libhdf5-serial-dev protobuf-compiler sudo apt-get install -y liblapack-dev sudo apt-get install -y libatlas-base-dev sudo apt-get install -y --no-install-recommends libboost-all-dev sudo apt-get install -y libgflags-dev libgoogle-glog-dev liblmdb-dev sudo apt-get install -y python-numpy python-scipy sudo apt-get install -y python3-pip sudo apt-get install -y python3-numpy python3-scipy
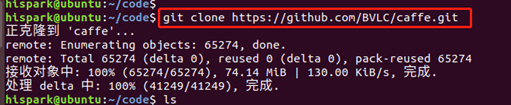
3. Execute the following command to download caffe open source software
git clone https://github.com/BVLC/caffe.git
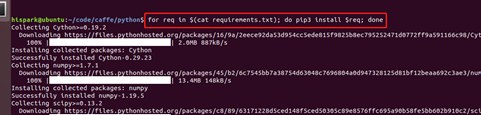
4. Enter the cafe / Python / directory, execute the following command, and download the dependent software
cd caffe/python/ for req in $(cat requirements.txt); do pip3 install $req; done
5. Enter the cafe directory and execute the following command to create the makefile config. Copy an example file and rename it makefile config
cp Makefile.config.example Makefile.config

6. The next step is to modify the makefile For the configuration in config, use the vim command to open makefile config.
vim Makefile.config
- ① CPU_ The comments in front of only are removed.
take # CPU_ONLY := 1 Change to CPU_ONLY := 1
- ② Opencv_ Remove the comments in front of version
take # OPENCV_VERSION := 3 Change to OPENCV_VERSION := 3
- ③ Because our Ubuntu environment is python, please put PYTHON_INCLUDE = python2.7 this configuration is annotated and python_ INCLUDE=python3. Open the comment of 5 and change all 3.5 to 3.6. The specific modifications are as follows
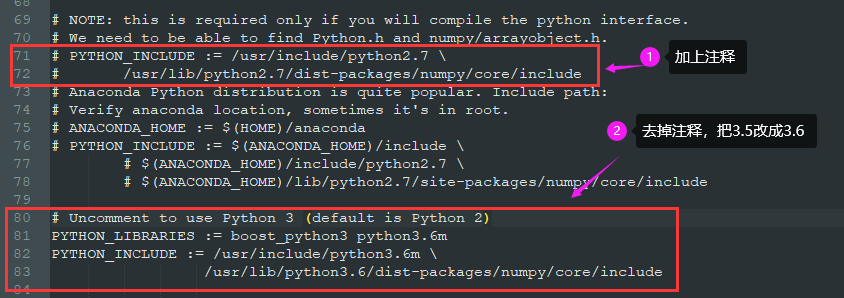
- ④ With_ PYTHON_ Layer: = 1, remove the previous note
take # WITH_PYTHON_LAYER := 1 Change to WITH_PYTHON_LAYER := 1
- ⑤ Modify INCLUDE_DIRS and LIBRARY_DIRS
take INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib Change to INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib usr/lib/x86_64-linux-gnu /usr/lib/x86_64-linux-gnu/hdf5/serial
The modified file is as follows:
## Refer to http://caffe.berkeleyvision.org/installation.html
# Contributions simplifying and improving our build system are welcome!
# cuDNN acceleration switch (uncomment to build with cuDNN).
# USE_CUDNN := 1
# CPU-only switch (uncomment to build without GPU support).
CPU_ONLY := 1
# uncomment to disable IO dependencies and corresponding data layers
# USE_OPENCV := 0
# USE_LEVELDB := 0
# USE_LMDB := 0
# This code is taken from https://github.com/sh1r0/caffe-android-lib
# USE_HDF5 := 0
# uncomment to allow MDB_NOLOCK when reading LMDB files (only if necessary)
# You should not set this flag if you will be reading LMDBs with any
# possibility of simultaneous read and write
# ALLOW_LMDB_NOLOCK := 1
# Uncomment if you're using OpenCV 3
OPENCV_VERSION := 3
# To customize your choice of compiler, uncomment and set the following.
# N.B. the default for Linux is g++ and the default for OSX is clang++
# CUSTOM_CXX := g++
# CUDA directory contains bin/ and lib/ directories that we need.
CUDA_DIR := /usr/local/cuda
# On Ubuntu 14.04, if cuda tools are installed via
# "sudo apt-get install nvidia-cuda-toolkit" then use this instead:
# CUDA_DIR := /usr
# CUDA architecture setting: going with all of them.
# For CUDA < 6.0, comment the *_50 through *_61 lines for compatibility.
# For CUDA < 8.0, comment the *_60 and *_61 lines for compatibility.
# For CUDA >= 9.0, comment the *_20 and *_21 lines for compatibility.
CUDA_ARCH := -gencode arch=compute_20,code=sm_20 \
-gencode arch=compute_20,code=sm_21 \
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_52,code=sm_52 \
-gencode arch=compute_60,code=sm_60 \
-gencode arch=compute_61,code=sm_61 \
-gencode arch=compute_61,code=compute_61
# BLAS choice:
# atlas for ATLAS (default)
# mkl for MKL
# open for OpenBlas
BLAS := atlas
# Custom (MKL/ATLAS/OpenBLAS) include and lib directories.
# Leave commented to accept the defaults for your choice of BLAS
# (which should work)!
# BLAS_INCLUDE := /path/to/your/blas
# BLAS_LIB := /path/to/your/blas
# Homebrew puts openblas in a directory that is not on the standard search path
# BLAS_INCLUDE := $(shell brew --prefix openblas)/include
# BLAS_LIB := $(shell brew --prefix openblas)/lib
# This is required only if you will compile the matlab interface.
# MATLAB directory should contain the mex binary in /bin.
# MATLAB_DIR := /usr/local
# MATLAB_DIR := /Applications/MATLAB_R2012b.app
# NOTE: this is required only if you will compile the python interface.
# We need to be able to find Python.h and numpy/arrayobject.h.
# PYTHON_INCLUDE := /usr/include/python2.7 \
# /usr/lib/python2.7/dist-packages/numpy/core/include
# Anaconda Python distribution is quite popular. Include path:
# Verify anaconda location, sometimes it's in root.
# ANACONDA_HOME := $(HOME)/anaconda
# PYTHON_INCLUDE := $(ANACONDA_HOME)/include \
# $(ANACONDA_HOME)/include/python2.7 \
# $(ANACONDA_HOME)/lib/python2.7/site-packages/numpy/core/include
# Uncomment to use Python 3 (default is Python 2)
PYTHON_LIBRARIES := boost_python3 python3.6m
PYTHON_INCLUDE := /usr/include/python3.6m \
/usr/lib/python3.6/dist-packages/numpy/core/include
# We need to be able to find libpythonX.X.so or .dylib.
PYTHON_LIB := /usr/lib
# PYTHON_LIB := $(ANACONDA_HOME)/lib
# Homebrew installs numpy in a non standard path (keg only)
# PYTHON_INCLUDE += $(dir $(shell python -c 'import numpy.core; print(numpy.core.__file__)'))/include
# PYTHON_LIB += $(shell brew --prefix numpy)/lib
# Uncomment to support layers written in Python (will link against Python libs)
WITH_PYTHON_LAYER := 1
# Whatever else you find you need goes here.
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib usr/lib/x86_64-linux-gnu /usr/lib/x86_64-linux-gnu/hdf5/serial
# If Homebrew is installed at a non standard location (for example your home directory) and you use it for general dependencies
# INCLUDE_DIRS += $(shell brew --prefix)/include
# LIBRARY_DIRS += $(shell brew --prefix)/lib
# NCCL acceleration switch (uncomment to build with NCCL)
# https://github.com/NVIDIA/nccl (last tested version: v1.2.3-1+cuda8.0)
# USE_NCCL := 1
# Uncomment to use `pkg-config` to specify OpenCV library paths.
# (Usually not necessary -- OpenCV libraries are normally installed in one of the above $LIBRARY_DIRS.)
# USE_PKG_CONFIG := 1
# N.B. both build and distribute dirs are cleared on `make clean`
BUILD_DIR := build
DISTRIBUTE_DIR := distribute
# Uncomment for debugging. Does not work on OSX due to https://github.com/BVLC/caffe/issues/171
# DEBUG := 1
# The ID of the GPU that 'make runtest' will use to run unit tests.
TEST_GPUID := 0
# enable pretty build (comment to see full commands)
Q ?= @
7. Modify some configurations in the Makefile file. Open the Makefile with vim and make modifications.
vim Makefile
- ① Modify dynamic_ VERSION_ Value of revision
take DYNAMIC_VERSION_REVISION := 0 Change to DYNAMIC_VERSION_REVISION := 0-rc3
- ② Modify the value of LIBRARIES.
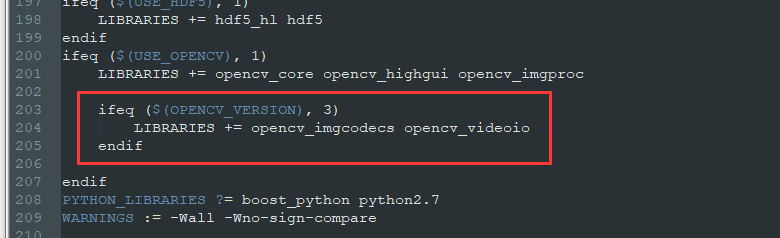
take LIBRARIES += glog gflags protobuf boost_system boost_filesystem m Change to LIBRARIES += glog gflags protobuf boost_system boost_filesystem boost_regex m hdf5_hl hdf5

take LIBRARIES += opencv_imgcodecs Change to LIBRARIES += opencv_imgcodecs opencv_videoio
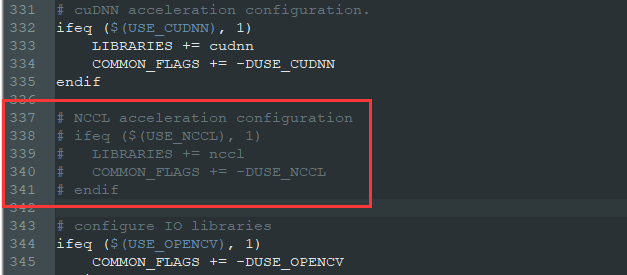
- ③ Comment out the # four lines under NCCL acceleration configuration
take # NCCL acceleration configuration ifeq ($(USE_NCCL), 1) LIBRARIES += nccl COMMON_FLAGS += -DUSE_NCCL endif Change to # NCCL acceleration configuration # ifeq ($(USE_NCCL), 1) # LIBRARIES += nccl # COMMON_FLAGS += -DUSE_NCCL # endif
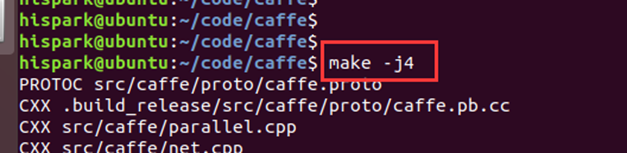
8. In the caffe directory, execute the following commands step by step to compile caffe.
make -j4 make pycaffe

9. Execute the following command to set the python path of caffe as the environment variable and update the environment variable.
Execute the following command to open bashrc
sudo vim ~/.bashrc
Add the following statement at the end of the file
export PYTHONPATH=/home/hispark/code/caffe/python:$PYTHONPATH
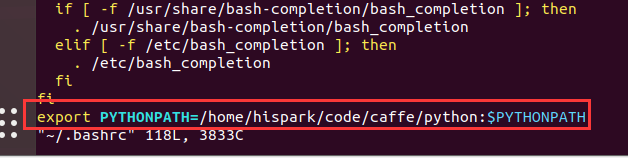
Then execute the following command to update the environment variable
source ~/.bashrc
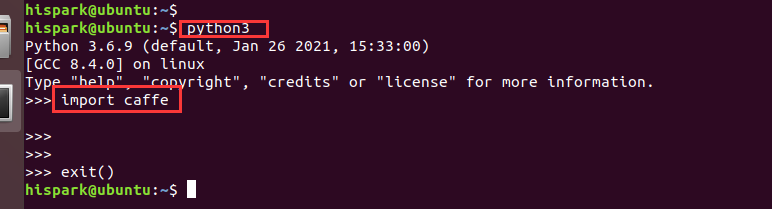
10. Test whether the caffe environment is OK. Run Python 3 in any directory of Ubuntu. When the "> > >" prompt appears, enter import caffe. If there is no error message, it indicates that the caffe environment has been built successfully.
python3 import caffe
2, Perform the following steps to install the Darknet 2caffe environment
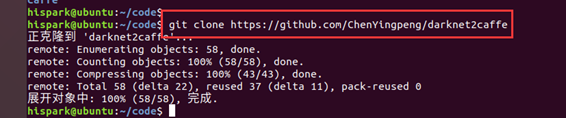
1. Execute the following command to download the code of darknet2caffe to Ubuntu.
git clone https://github.com/ChenYingpeng/darknet2caffe
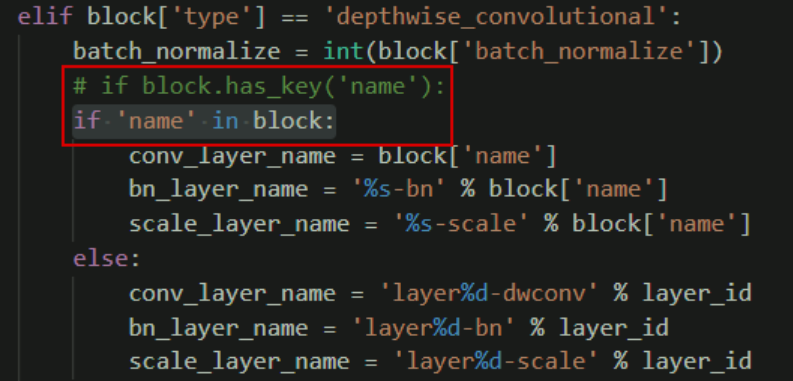
2. Because the local version of Python is Python 3 6. The open source code is python2 10. Therefore, the code syntax needs to be adjusted appropriately
- ① Set darknet2caffe All if blocks in py has_ Key ('name '): replace with if' name 'in block:
- ② Then put caffe_ Change root to the actual absolute path of cafe, such as: / home / hispark / code / cafe/
take caffe_root='/home/chen/caffe/' Change to caffe_root='/home/hispark/code/caffe/' # /Home / hispark / code / Cafe / is your cafe path
- ③ Set prototext Py installation is modified as shown in the figure below
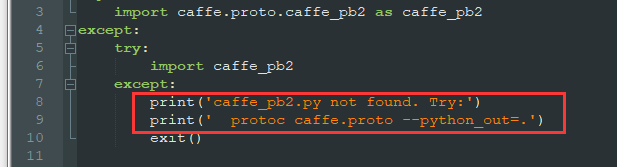
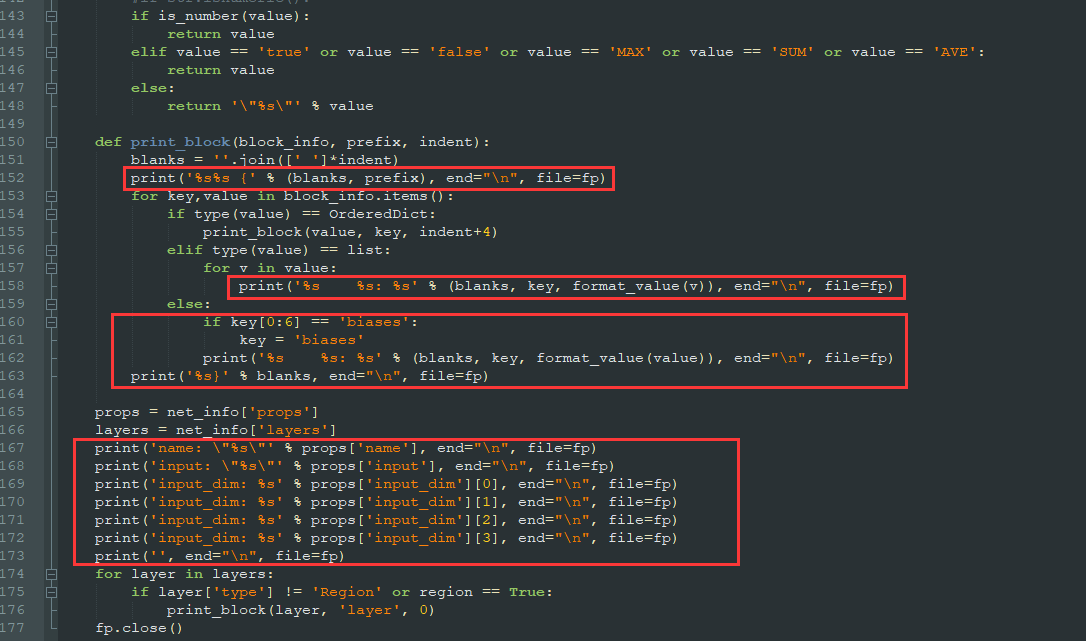
Modified protxt Py is shown below
from collections import OrderedDict
try:
import caffe.proto.caffe_pb2 as caffe_pb2
except:
try:
import caffe_pb2
except:
print('caffe_pb2.py not found. Try:')
print(' protoc caffe.proto --python_out=.')
exit()
def parse_caffemodel(caffemodel):
model = caffe_pb2.NetParameter()
print('Loading caffemodel: ', caffemodel)
with open(caffemodel, 'rb') as fp:
model.ParseFromString(fp.read())
return model
def parse_prototxt(protofile):
def line_type(line):
if line.find(':') >= 0:
return 0
elif line.find('{') >= 0:
return 1
return -1
def parse_block(fp):
block = OrderedDict()
line = fp.readline().strip()
while line != '}':
ltype = line_type(line)
if ltype == 0: # key: value
#print line
line = line.split('#')[0]
key, value = line.split(':')
key = key.strip()
value = value.strip().strip('"')
if block.has_key(key):
if type(block[key]) == list:
block[key].append(value)
else:
block[key] = [block[key], value]
else:
block[key] = value
elif ltype == 1: # blockname {
key = line.split('{')[0].strip()
sub_block = parse_block(fp)
block[key] = sub_block
line = fp.readline().strip()
line = line.split('#')[0]
return block
fp = open(protofile, 'r')
props = OrderedDict()
layers = []
line = fp.readline()
while line != '':
line = line.strip().split('#')[0]
if line == '':
line = fp.readline()
continue
ltype = line_type(line)
if ltype == 0: # key: value
key, value = line.split(':')
key = key.strip()
value = value.strip().strip('"')
if props.has_key(key):
if type(props[key]) == list:
props[key].append(value)
else:
props[key] = [props[key], value]
else:
props[key] = value
elif ltype == 1: # blockname {
key = line.split('{')[0].strip()
if key == 'layer':
layer = parse_block(fp)
layers.append(layer)
else:
props[key] = parse_block(fp)
line = fp.readline()
if len(layers) > 0:
net_info = OrderedDict()
net_info['props'] = props
net_info['layers'] = layers
return net_info
else:
return props
def is_number(s):
try:
float(s)
return True
except ValueError:
return False
def print_prototxt(net_info):
# whether add double quote
def format_value(value):
#str = u'%s' % value
#if str.isnumeric():
if is_number(value):
return value
elif value == 'true' or value == 'false' or value == 'MAX' or value == 'SUM' or value == 'AVE':
return value
else:
return '\"%s\"' % value
def print_block(block_info, prefix, indent):
blanks = ''.join([' ']*indent)
print('%s%s {' % (blanks, prefix))
for key,value in block_info.items():
if type(value) == OrderedDict:
print_block(value, key, indent+4)
elif type(value) == list:
for v in value:
print('%s %s: %s' % (blanks, key, format_value(v)))
else:
print('%s %s: %s' % (blanks, key, format_value(value)))
print('%s}' % blanks)
props = net_info['props']
layers = net_info['layers']
print('name: \"%s\"' % props['name'])
print('input: \"%s\"' % props['input'])
print('input_dim: %s' % props['input_dim'][0])
print('input_dim: %s' % props['input_dim'][1])
print('input_dim: %s' % props['input_dim'][2])
print('input_dim: %s' % props['input_dim'][3])
print('')
for layer in layers:
print_block(layer, 'layer', 0)
def save_prototxt(net_info, protofile, region=True):
fp = open(protofile, 'w')
# whether add double quote
def format_value(value):
#str = u'%s' % value
#if str.isnumeric():
if is_number(value):
return value
elif value == 'true' or value == 'false' or value == 'MAX' or value == 'SUM' or value == 'AVE':
return value
else:
return '\"%s\"' % value
def print_block(block_info, prefix, indent):
blanks = ''.join([' ']*indent)
print('%s%s {' % (blanks, prefix), end="\n", file=fp)
for key,value in block_info.items():
if type(value) == OrderedDict:
print_block(value, key, indent+4)
elif type(value) == list:
for v in value:
print('%s %s: %s' % (blanks, key, format_value(v)), end="\n", file=fp)
else:
if key[0:6] == 'biases':
key = 'biases'
print('%s %s: %s' % (blanks, key, format_value(value)), end="\n", file=fp)
print('%s}' % blanks, end="\n", file=fp)
props = net_info['props']
layers = net_info['layers']
print('name: \"%s\"' % props['name'], end="\n", file=fp)
print('input: \"%s\"' % props['input'], end="\n", file=fp)
print('input_dim: %s' % props['input_dim'][0], end="\n", file=fp)
print('input_dim: %s' % props['input_dim'][1], end="\n", file=fp)
print('input_dim: %s' % props['input_dim'][2], end="\n", file=fp)
print('input_dim: %s' % props['input_dim'][3], end="\n", file=fp)
print('', end="\n", file=fp)
for layer in layers:
if layer['type'] != 'Region' or region == True:
print_block(layer, 'layer', 0)
fp.close()
if __name__ == '__main__':
import sys
if len(sys.argv) != 2:
print('Usage: python prototxt.py model.prototxt')
exit()
net_info = parse_prototxt(sys.argv[1])
print_prototxt(net_info)
save_prototxt(net_info, 'tmp.prototxt')
3. Enter the darknet2caffe directory, execute the following command, and copy the three files to the Caffe directory
cp caffe_layers/upsample_layer/upsample_layer.hpp ../caffe/include/caffe/layers/ cp caffe_layers/upsample_layer/upsample_layer.c* ../caffe/src/caffe/layers/


4. Enter the src/caffe/proto / directory of caffe and modify caffe Proto file
cd ../caffe/src/caffe/proto/

Add optional upsampleparameter upsample in message LayerParameter {}_ param = 150;
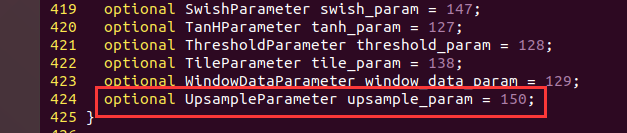
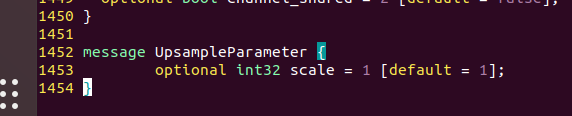
In Caffe Finally, add the UpsampleParameter parameter to proto, as shown in the following figure:
message UpsampleParameter {
optional int32 scale = 1 [default = 1];
}
5. In the caffe directory, execute the following command to recompile the caffe environment.
make clean make -j4 make pycaffe

At this point, the environment of Caffe and darknet2caffe is installed in Ubuntu.