Tell me more about what you are going to do today.
Use HttpClient and Jsoup technology to capture web page information.HttpClient is a client programming toolkit that supports the HTTP protocol, and it supports the HTTP protocol.
jsoup is a web page HTML parser based on Java platform, which can directly parse a URL address, HTML text content, and provides a set of very convenient API interfaces to manipulate data through operations similar to jQuery.
httpClient related documents: http://hc.apache.org/httpcomponents-client-5.0.x/index.html
jsoup related documents: http://jsoup.org/
Case study O() using NetEase precious metal information as an example
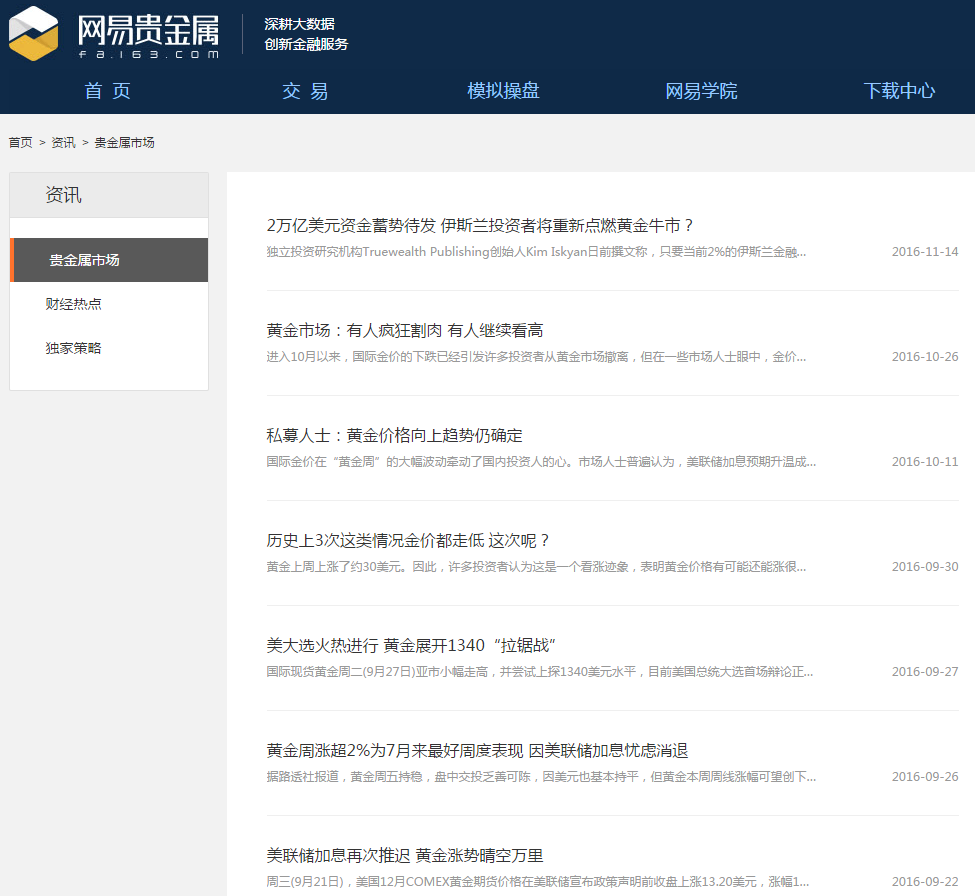
Then we will first analyze the structure of the source code of the web page

Then we can start programming. First, we need to know the process of using httpClient:
1. Create objects for HttpClient;
2. Create an instance of the request method and specify the URL to access;
3. Call the HttpClient object to send the request, which returns an HttpResponse to determine if the return code of responce.getStatusLine().getStatusCode() is 200;
4. Call HttpResponse related methods to get corresponding content;
5. Release the connection.
Of course, when you create a project, import the relevant jar packages. Source + jar packages http://pan.baidu.com/s/1sl55d85 are provided here
StockUtils.java
1 package cn.clay.httpclient.utils; 2 3 import java.io.IOException; 4 5 import org.apache.http.HttpEntity; 6 import org.apache.http.HttpResponse; 7 import org.apache.http.HttpStatus; 8 import org.apache.http.client.HttpClient; 9 import org.apache.http.client.methods.HttpGet; 10 import org.apache.http.impl.client.CloseableHttpClient; 11 12 import org.apache.http.impl.client.HttpClients; 13 import org.apache.http.util.EntityUtils; 14 /** 15 * Pass Web Link 16 * Return to Web Source 17 * @author ClayZhang 18 * 19 */ 20 public class StockUtils { 21 //Get Web Source for the First Time 22 public static String getHtmlByUrl(String url) throws IOException{ 23 String html = null; 24 CloseableHttpClient httpClient = HttpClients.createDefault();//Establish httpClient object 25 HttpGet httpget = new HttpGet(url); 26 try { 27 HttpResponse responce = httpClient.execute(httpget); 28 int resStatu = responce.getStatusLine().getStatusCode(); 29 if (resStatu == HttpStatus.SC_OK) { 30 31 HttpEntity entity = responce.getEntity(); 32 if (entity != null) { 33 html = EntityUtils.toString(entity);//Get html source code 34 } 35 } 36 } catch (Exception e) { 37 System.out.println("Visit ["+url+"]An exception occurred!"); 38 e.printStackTrace(); 39 } finally { 40 //Release Connection 41 httpClient.close(); 42 } 43 return html; 44 } 45 }
Then use jsoup method to write StockTest.java for test class
1 package cn.clay.httpclient.utils.test; 2 3 import java.io.IOException; 4 5 import org.apache.http.ParseException; 6 import org.jsoup.Jsoup; 7 import org.jsoup.nodes.Document; 8 import org.jsoup.nodes.Element; 9 import org.jsoup.select.Elements; 10 11 import cn.clay.httpclient.utils.StockUtils; 12 13 /** 14 * 15 * @author ClayZhang 16 * 17 */ 18 public class StockTest { 19 20 public static void main(String[] args) throws ParseException, IOException { 21 String content = StockUtils.getHtmlByUrl( 22 "http://fa.163.com/zx/gjs/1/"); 23 parserHtml(content); 24 } 25 26 27 public static void parserHtml(String content) throws ParseException, IOException { 28 Document doc = Jsoup.parse(content); 29 Elements links = doc.getElementsByClass("g-news").select("dl"); 30 for (Element e : links) { 31 System.out.println("News Title:" + e.select("a").text().toString()); 32 //Get page links 33 Elements linkHref = e.select("a"); 34 //Intercept time string 35 Elements timeStr = e.select("span[class=f-fr]"); 36 //Brief Information 37 Elements comment = e.select("span[class=f-fl f-ofe u-digest]"); 38 System.out.println("News Link:" + linkHref.attr("href")); 39 System.out.println("Release time:" + timeStr.text()); 40 System.out.println("Brief information:" + comment.text().toString()); 41 42 System.out.println("============================================================="); 43 } 44 45 } 46 }
The results after running are as follows
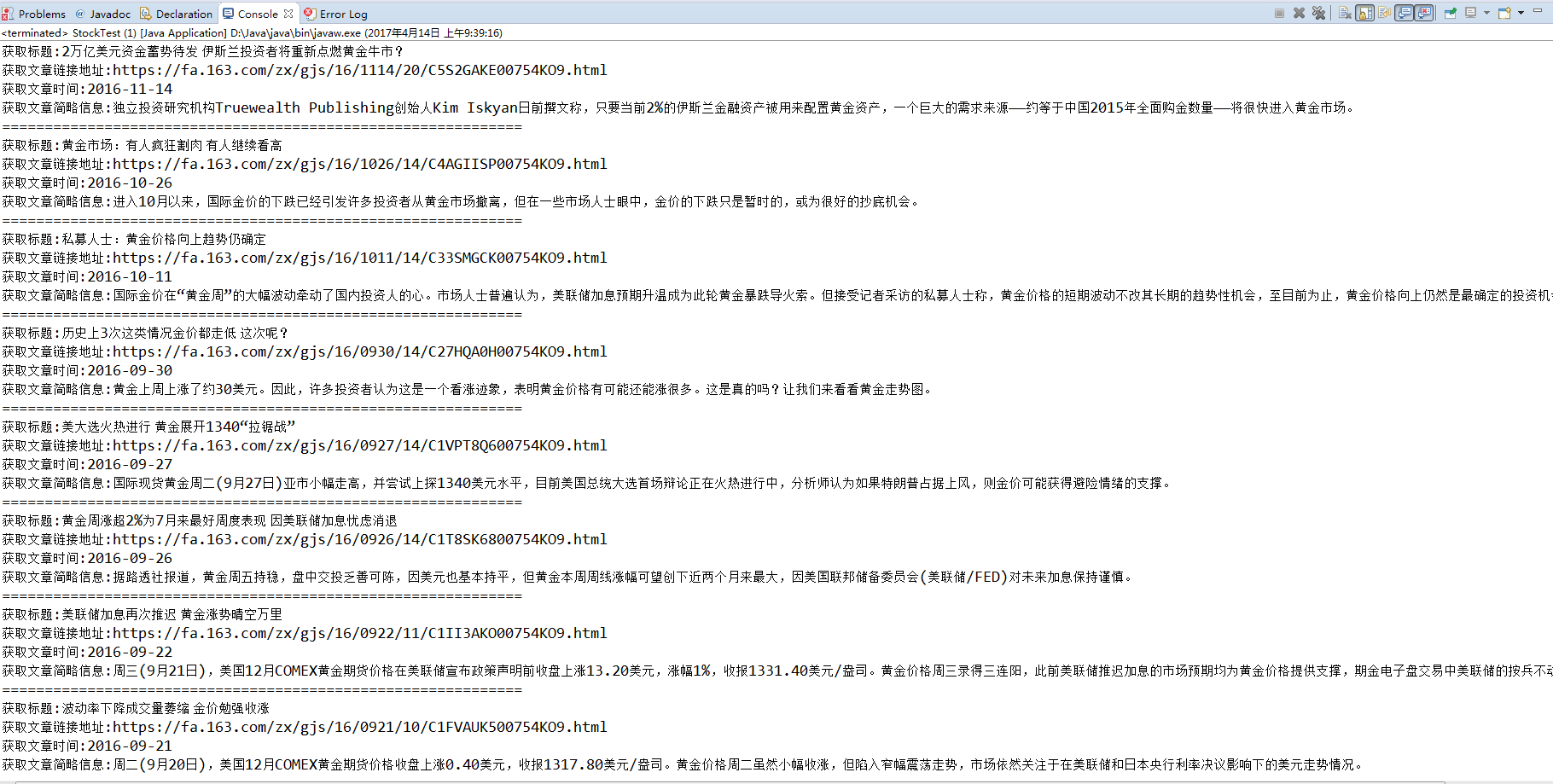
Copyright of this article is owned by the author and blog park. Please indicate the author and the source of the original text for reprinting.
http://www.cnblogs.com/clayzhang