Huffman encoding and decoding of files
- 1. The global variable count conflicts with std:count. It is recommended to use other variable names.
- 2. Memory leakage. Note that the space should be open enough that the pointer cannot cross the boundary. The stack space opened in the main function is generally 8MB. If you want to open a large array, please go outside the main function
- 3. Compiler error. We recommend that you use a newer and more stable compiler
- 4. Remember to close the file operation after it is opened, otherwise it will occupy system resources
- 5. After applying for space, remember to release and form a habit. Release functions should not be arrogant (pay attention to the warning of the compiler). Malloc / free and new / delete should be paired.
Coding requirements and tasks:
Prepare a character file that requires:
- Count the frequency of various characters in the file
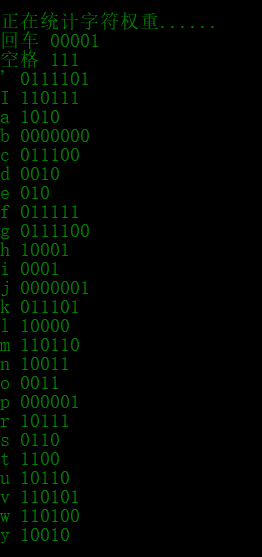
- Huffman code each character and display the code of each character
- And translating the file into Huffman encoded file
- Then the Huffman encoded file is translated into the source file
- Displays the encoded file after binary encoding of each character in one byte
The implementation steps can be divided into:
- Count the frequency of characters in the encoded file, i.e. statistical weight
- According to the weight, Huffman tree is constructed for Huffman coding
- Read the file for binary encoding
- Read the file, match each character with Huffman coding, and write it to a new file, that is, complete the coding
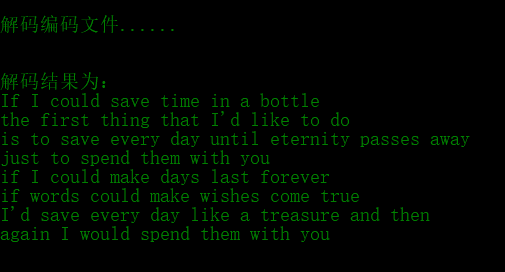
- Read the encoded file, decode according to Huffman encoding, and write a new file
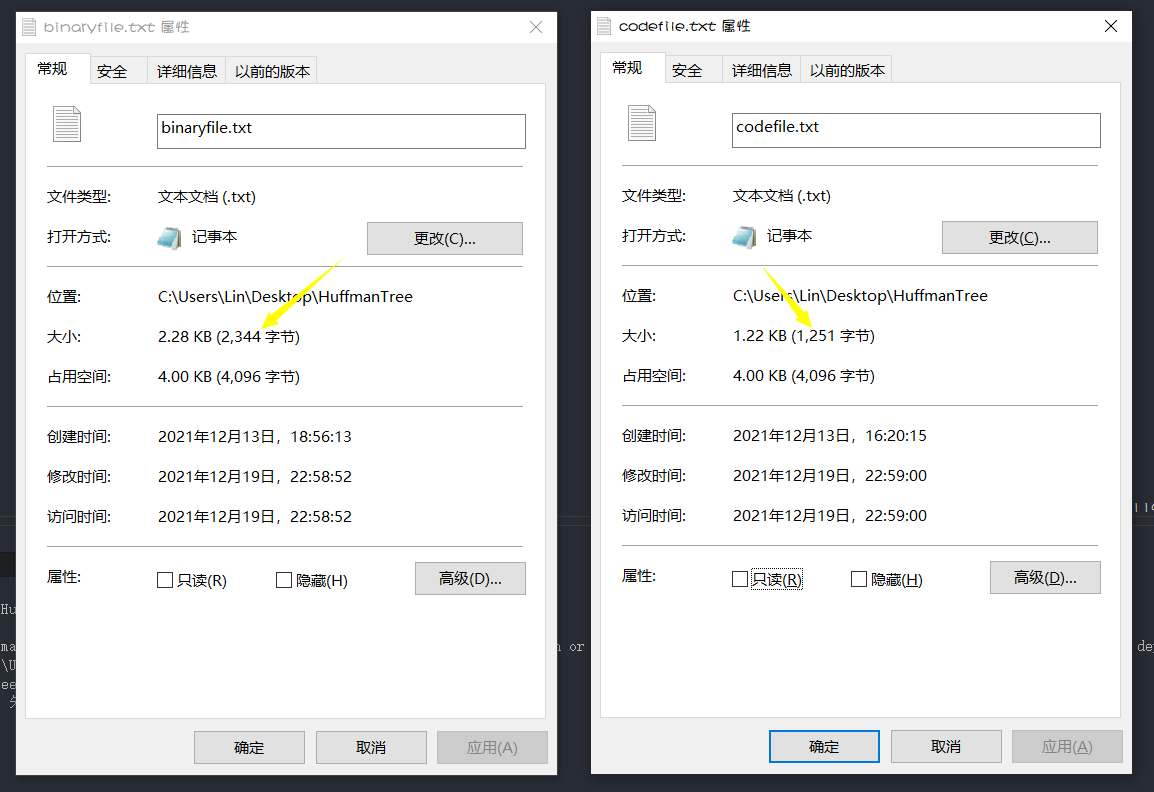
- Compare the file byte size after binary coding and Huffman coding, and calculate the compression rate
First, prepare a source file
Here I prepared a little poem, wrote it into a file and named it poem txt
If I could save time in a bottle the first thing that I'd like to do is to save every day until eternity passes away just to spend them with you if I could make days last forever if words could make wishes come true I'd save every day like a treasure and then again I would spend them with you
Build Huffman node
// Define Huffman tree nodes
typedef struct {
int weight;
int parent;
int l_child;
int r_child;
char data;
} HTNode, * HuffmanTree;
typedef char** HuffmanCode;
frequency statistic
//Count the frequency of various characters in the file
void frequencyRecord(HuffmanTree& HT) {
HuffmanTree TEMP;
TEMP = new HTNode[130];
for (int i = 0; i < 130; ++i) {
TEMP[i].weight = 0;
}
ifstream originFile("poem.txt");
originFile.seekg(0);
if (!originFile) {
cout << "Can't find the file!" << endl;
} else {
char _data;
cin.unsetf(ios::skipws);
while (!originFile.eof()) {
if (originFile.get(_data)) {
TEMP[_data].data = _data;
TEMP[_data].weight++;
}
}
originFile.close();
}
for (int i = 0; i < 130; ++i) {
if (TEMP[i].weight != 0) {
N++;
}
}
HT = new HTNode[2 * N];
int k = 1;
for (int i = 0; i < 130; ++i) {
if (TEMP[i].weight != 0) {
HT[k++] = TEMP[i];
}
}
}
Huffman coding
//Huffman code each character and display the code of each character
void HuffmanCoding(HuffmanTree& HT, HuffmanCode& HC) {
int m = 2 * N - 1;
for (int i = 1; i <= N; ++i) {
HT[i].parent = 0;
HT[i].l_child = 0;
HT[i].r_child = 0;
}
for (int i = N + 1; i <= m; ++i) {
HT[i].weight = 0;
HT[i].parent = 0;
HT[i].l_child = 0;
HT[i].r_child = 0;
HT[i].data = '#';
}
int child1, child2;
for (int i = N + 1; i <= m; i++) {
select(HT, i - 1, child1, child2);
HT[child1].parent = i;
HT[child2].parent = i;
HT[i].l_child = child1;
HT[i].r_child = child2;
HT[i].weight = HT[child1].weight + HT[child2].weight;
}
HC = new char* [N + 1];
char* cd = new char[N];
cd[N - 1] = '\0';
int start, c, f;
for (int i = 1; i <= N; i++) {
start = N - 1;
for (c = i, f = HT[i].parent; f != 0; c = f, f = HT[f].parent) {
if (HT[f].l_child == c) cd[--start] = '0';
else cd[--start] = '1';
}
HC[i] = new char[N - start];
strcpy(HC[i], &cd[start]);
}
delete[] cd;
for (int i = 1; i <= N; i++) {
if (HT[i].data == '\n') {
cout << "enter" << " " << HC[i] << endl;
} else if (HT[i].data == ' ') {
cout << "Space" << " " << HC[i] << endl;
} else {
cout << HT[i].data << " " << HC[i] << endl;;
}
}
}
The function function of finding the smallest two leaf nodes is
//Find the smallest two leaf nodes
void select(HuffmanTree HT, int num, int& child1, int& child2) {
child1 = child2 = 0;
int w1 = 0, w2 = 0;
//Start finding...
for (int i = 1; i <= num; ++i) {
if (HT[i].parent == 0) {
if (child1 == 0) {
child1 = i;
w1 = HT[i].weight;
continue;
}
if (child2 == 0) {
child2 = i;
w2 = HT[i].weight;
continue;
}
if (w1 > w2 && w1 > HT[i].weight) {
child1 = i;
w1 = HT[i].weight;
continue;
}
if (w2 > w1 && w2 > HT[i].weight) {
child2 = i;
w2 = HT[i].weight;
continue;
}
}
}
// Make w1 always less than w2
int temp;
if (w1 > w2) {
temp = child1;
child1 = child2;
child2 = temp;
}
}
Encode and write to file
//Translate the file into Huffman encoded file
void zip(HuffmanTree& HT, HuffmanCode& HC, vector<string>& code) {
ofstream codeFile("codefile.txt");
ifstream originFile("poem.txt");
if (!codeFile) {
cout << "Can't find the file!" << endl;
} else {
char _data;
cin.unsetf(ios::skipws);
while (!originFile.eof()) {
if (originFile.get(_data)) {
for (int i = 1; i <= N; ++i) {
if (HT[i].data == _data) {
codeFile << HC[i];
code.push_back(HC[i]);
}
}
}
}
}
codeFile.close();
}
Open the encoded file for decoding
//Then the Huffman encoded file is translated into the source file
void unzip(HuffmanTree& HT, HuffmanCode& HC, vector<string>& code) {
ofstream decodeFile("decodefile.txt");
if (!decodeFile) {
cout << "Can't find the file!" << endl;
} else {
vector<string>::iterator v = code.begin();
while (v != code.end()) {
for (int i = 1; i <= N; ++i) {
if (HC[i] == *v) {
decodeFile << HT[i].data;
}
}
v++;
}
}
decodeFile.close();
}
Binary coding
//Displays the encoded file after binary encoding of each character in one byte
void binaryCode() {
ofstream binaryFile("binaryfile.txt");
ifstream originFile("poem.txt");
originFile.seekg(0);
if (!originFile) {
cout << "Can't find the file!" << endl;
} else {
char _data;
cin.unsetf(ios::skipws);
while (!originFile.eof()) {
if (originFile.get(_data)) {
bitset<8> data(_data);
binaryFile << data;
}
}
originFile.close();
}
}
Operation results
Read source file, binary encoding

Count the character frequency to get the coding table
Coding source file and coding result

Decoding encoded file and decoding result
Compression effect

Summary
By writing a file encoding and decoding gadget realized by Huffman algorithm, we can deepen the understanding of Huffman algorithm and coding proficiency.
At the same time, we realize the beauty of reducing text space and computer disk load through algorithms. We need excellent algorithms to improve computer performance. Although Huffman coding is rarely heard in the actual compression algorithm, it is not eliminated, but as the core algorithm,
Combined with other compression algorithms, it realizes the compression of files (text, PPT, pictures, movies, etc.), which brings great convenience to daily life.
My gadget has only targeted Huffman coding for English letters and '\ n' 'characters. If you want to realize the coding of Chinese and various supporting languages, you can optimize it on the basis of this code.