Previous: I'm learning database at station b (8): multi table operation exercise
Function classification
Aggregate function, mathematical function, string function, date function, control flow function, window function
1, Aggregate function
1. Introduction
Aggregate functions are mainly composed of count, sum, min, Max and AVG. these aggregate functions (before) will not be repeated. Another function: group_concat(), which enables the user to merge rows
2. Format
group_concat([distinct] field name [order by sort field asc/desc] [separator '])
explain:
(1) distinct can exclude duplicate values.
(2) If you need to sort the values in the results, you can use the order by clause.
(3) separator is a string value, which defaults to comma.
3. Example
(1) Data preparation
create table emp(
emp_id int primary key auto_increment comment 'number',
emp_name char(20) not null default '' comment 'full name',
salary decimal(10,2) not null default 0 comment 'wages',
department char(20) not null default '' comment 'department'
);
insert into emp(emp_name,salary,department)
values('Zhang Jingjing',5000,'Finance Department'),('Wang Feifei',5800,'Finance Department'),('Gang Zhao',6200,'Finance Department'),('Liu Xiaobei',5700,'Ministry of Personnel'),
('Wang Dapeng',6700,'Ministry of Personnel'),('Zhang Xiaofei',5200,'Ministry of Personnel'),('Liu yunyun',7500,'Sales Department'),('Liu Yunpeng',7200,'Sales Department'),
('Liu Yunpeng',7800,'Sales Department');
(2) Operation
-- Merge the names of all employees into one line select group_concat(emp_name) from emp;

-- Specify separator merge select department,group_concat(emp_name separator ';' ) from emp group by department;

-- Specify sort and separator select department,group_concat(emp_name order by salary desc separator ';' ) from emp group by department;

2, Mathematical function
1. abs(): return absolute value
select abs(-10); #10 select abs(-10); #10
2. ceil(): returns the smallest integer greater than or equal to (rounded up)
select ceil(1.1); #2 select ceil(1.0); #1
3. floor(): returns the largest integer less than or equal to (rounded down)
select floor(1.1); #1 select floor(1.9); #1
4. Greater (expr1,expr2...): take the maximum value of the list
select greatest(1,2,3); #3
5. least (expr1,expr2...): take the minimum value of the list
select least(1,2,3); #1
6. mod(x, y): returns the remainder of X divided by Y (modulo)
select mod(5,2); #1
7. pow (x, y): returns the Y power of X
select pow(2,3) #8
8. rand(): returns a random number from 0 to 1
select rand() #0.93099
9. round(x): returns the integer nearest to X (follow rounding)
select round(1.23456) #1
10. round (x, y): returns the decimal of the specified number of digits (follow rounding)
select round(1.23456,3) #1.235
11. truncate (x, y): returns the value of X reserved to y digits after the decimal point
select truncate(1.23456,3) #1.234
Note: the biggest difference from round is that it will not be rounded
3, String function
1,char_length(s): returns the number of characters of string s
select char_length('hello'); #5
select char_length('how are you'); #3
#Note: -- length takes the length, and the returned unit is bytes
select length('hello'); #5
select length('how are you'); #9 one Chinese character and 3 bytes
2. character -- length (s): returns the number of characters of string s
ditto
3. concat (s1, s2... sn): String s1, s2 and other strings are combined into one string
select concat ('hello','world');

4,concat_ws(x,s1,s2... sn): the same function as above, but x should be added between each string. X can be a separator
select concat_ws ('-','hello','world');

5. field (s,s1,s2...): returns the first string s
The first position in the string list (s1,s2...)
select field('a','a','b','c'); #1
select field('b','a','b','c'); #2
6. ltrim (s): remove the space at the beginning of the string s
select ltrim(' aaaa'); #Remove left space
select rtrim(' aaaa '); #Remove right space
select trim(' aaaa '); #Remove spaces on both sides



7. mid(s,n,len): intercept the substring with length len from the n position of string s, the same as substring (s,n,len)
select mid("helloworld",2,3); #Intercept from the second character, and the intercept length is 3

8. position(s1 in s): get the starting position of s1 from the string s
select position('abc'in 'habcelloworld'); #2
9. Replace (s,s1,s2): replace the string s1 in the string s with the string s2
select replace('helloaaaworld','aaa','bbb');

10. Reverse (s): reverse the order of string s
select reverse('hello');

11. right (s,n): returns the last n characters of string s
select right('hello',3); #Returns the last three characters

12. strcmp (s1,s2): compare the strings s1 and s2, if s1
If it is equal to s2, it returns 0. If S1 > s2, it returns 1. If S1 < s2, it returns - 1.
select strcmp('hello','world'); #-1
13. substr (s,start,length): intercept the substring with length from the start position of string s
select substr('hello',2,3); # Intercept from the second character and intercept three characters

14. Substring (s,start,length): intercept the substring with length from the start position of string s
ditto
15. ucase(s): converts a string to uppercase
16. upper (s): converts a string to uppercase
select ucase("helloworld");
select upper("helloworld");
17. lcase (s): turns all letters of string s into lowercase letters
18. lower (s): turns all letters of string s into lowercase letters
select lcase("HELLOWORLD");
select lower("HELLOWORLD");
4, Date function
1,unix_timestamp(): returns the current millisecond value from 1970-01-01-00:00:00
select unix_timestamp();
2,unix_timestamp(DATE): converts the specified date to a time in milliseconds
select unix_timestamp('2022-01-01 08:08:08');
3,from_unixtime(bigint unixtime[,stringformat]): converts the millisecond time value to the specified format date
select from_unixtime(88888888,'%Y-%m-%d %H:%i:%s');
4. Current date (): returns the current date
select curdate();` 5,current_date():Returns the current date ```python select current_date();
6,current_time(): returns the current time
select current_time();
7. curtime(): returns the current time
select curtime();
8,current_timestamp(): returns the current date and time
select current_timestamp();
9. date(): extract the date value (month, year and day) from the date or date time expression
select date('2022-01-01 08:08:08');
10. datediff(d1,d2): calculate the number of days between dates d1 and d2
select datediff('2022-01-01','2000-08-08');
11. timediff (time1,time2): calculate the time difference (in seconds)
select timediff('08:08:08','06:06:06');
12,date_format(d,f): displays the date d as required by expression F
select date_format('2022-1-1 1:1:1','%Y-%m-%d %H:%i:%s');
13,str_to_date(string,format_mask): converts a string to a date
select str_to_date('2022-1-1 1:1:1','%Y-%m-%d %H:%i:%s');
14,date_ Sub (date, interval, expr type): the function subtracts the specified time interval from the date
select date_sub('2022-01-01',interval 2 day);
#Add dates
select date_add('2022-01-01',interval 2 day);
#Add dates
15. Get from date
select extract(hour from '2021-12-12 08:08:08'); #Get hours select extract(year from '2021-12-12 08:08:08'); #Acquisition year select extract(month from '2021-12-12 08:08:08'); #Get month
16. Gets the last day of the specified date
select last_day('2022-01-01');
17. Gets the date of the specified year and days
select makedate('2022',88);
18. Get information by date
select monthname('2020-02-02 08:08:08'); #Get English of month
select dayname(''2020-02-02 08:08:08'') #Get day of week
select dayofmonth(''2020-02-02 08:08:08'') #Gets the day ordinal of the month
5, Control flow function
1. If (expr,v1,v2): if expr is true, the result v1 is returned; otherwise, the result v2 is returned.
select if(5>3,'greater than','less than'); #greater than
2. ifnull(v1,v2): if the value of v1 is not null, v1 is returned; otherwise, v2 is returned.
select ifnull(5,0); #5 select ifnull(null,0); #0
3. isnull (expression): judge whether the expression is null.
select isnull(5); #0 select isnull(null); #1
4. nullif (expr1, expr2): compares two strings. If the strings expr1 and expr2 are equal, null is returned; otherwise, expr1 is returned.
select nullif(12,12) #null select nullif(12,13) #12
5. case when statement
Format:
case expression
when condition 1 then result 1
when condition 2 then result 2
...
else result
end
Explanation: case indicates the beginning of the function and end indicates the end of the function. If condition1 is true, it returns result1. If condition2 is true, it returns result2. If none of them is true, it returns result. When one of them is true, the subsequent ones will not be executed.
Example:
-- Create order table
create table orders(
oid int primary key, -- order id
price double, -- Order price
payType int -- Payment type(1:Wechat payment 2:Alipay pays 3:Bank card payment 4: others)
);
insert into orders values(1,1200,1);
insert into orders values(2,1000,2);
insert into orders values(3,200,3);
insert into orders values(4,3000,1);
insert into orders values(5,1500,2);
-- Mode 1
select
* ,
case
when payType=1 then 'Wechat payment'
when payType=2 then 'Alipay payment'
when payType=3 then 'Bank card payment'
else 'Other payment methods'
end as payTypeStr
from orders;
-- Mode 2
select
* ,
case payType
when 1 then 'Wechat payment'
when 2 then 'Alipay payment'
when 3 then 'Bank card payment'
else 'Other payment methods'
end as payTypeStr
from orders;
6, Window function (new in 8.0)
1. Concept
Non aggregate window functions are relative to aggregate functions. Aggregate function returns a single value (i.e. grouping) after calculating a group of data. Non aggregate function will only process one row of data at a time. When the window aggregation function calculates the result of a field on a row record, it can input the data within the window into the aggregation function without changing the number of rows.
2. Ordinal function
(1) There are three ordinal functions: row_number(),rank(),dense_rank()
(2) Format:
row_number()|rank()|dense_rank() over (
partition by ...
order by ...
)
(3) Example
#Data preparation
create table employee(
dname varchar(20), -- Department name
eid varchar(20),
ename varchar(20),
hiredate date, -- Entry date
salary double -- salary
);
insert into employee values('R & D department','1001','Liu Bei','2021-11-01',3000);
insert into employee values('R & D department','1002','Guan Yu','2021-11-02',5000);
insert into employee values('R & D department','1003','Fei Zhang','2021-11-03',7000);
insert into employee values('R & D department','1004','Zhao Yun','2021-11-04',7000);
insert into employee values('R & D department','1005','ma chao','2021-11-05',4000);
insert into employee values('R & D department','1006','Huang Zhong','2021-11-06',4000);
insert into employee values('Sales Department','1007','Cao Cao','2021-11-01',2000);
insert into employee values('Sales Department','1008','Xu Chu','2021-11-02',3000);
insert into employee values('Sales Department','1009','Dianwei','2021-11-03',5000);
insert into employee values('Sales Department','1010','Zhang Liao','2021-11-04',6000);
insert into employee values('Sales Department','1011','Xu Huang','2021-11-05',9000);
insert into employee values('Sales Department','1012','Cao Hong','2021-11-06',6000);
#operation
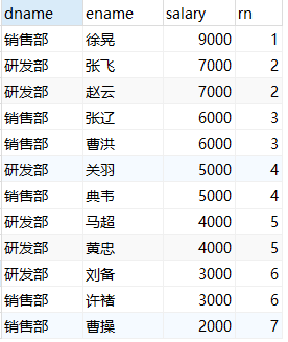
-- Sort the employees of each department according to their salary and give the ranking
select
dname,
ename,
salary,
row_number() over(partition by dname order by salary desc) as rn
from employee;
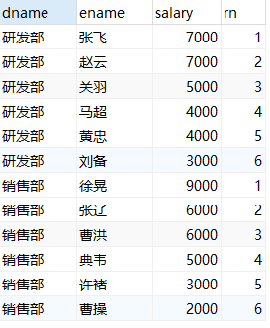
-- Sort the employees of each department according to their salary and give the ranking rank select dname, ename, salary, rank() over(partition by dname order by salary desc) as rn from employee;
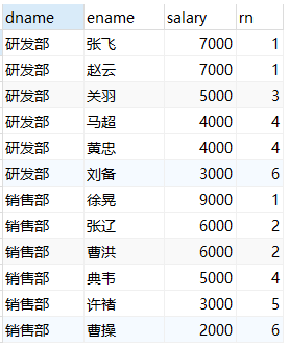
-- Sort the employees of each department according to their salary and give the ranking dense-rank select dname, ename, salary, dense_rank() over(partition by dname order by salary desc) as rn from employee;
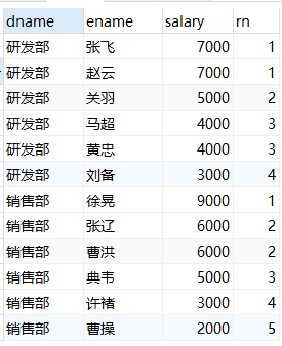
Note: carefully observe the serial numbers of the three results to distinguish them
--Find out the top three employees in each department- Group seeking TOPN
select
*
from
(
select
dname,
ename,
salary,
dense_rank() over(partition by dname order by salary desc) as rn
from employee
)t
where t.rn <= 3
-- Sort all employees globally (without grouping)
-- No partition by Represents a global sort
select
dname,
ename,
salary,
dense_rank() over( order by salary desc) as rn
from employee;
3. Windowed aggregate function
(1) Concept
Aggregate functions (SUM(), AVG(), MAX(), MIN(), COUNT()) are dynamically applied to each record in the window, and various aggregate function values in the specified window can be dynamically calculated.
(2) Example (take sum as an example)
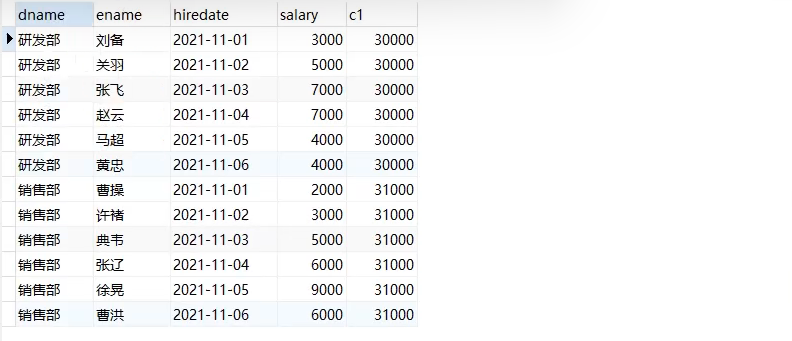
select dname, ename, salary, sum(salary) over(partition by dname order by hiredate) as c1 from employee;

Note: the result is that the first line salary is added to the current line
select dname, ename, hiredate, salary sum(pv) over(partition by dname) as c1 from employee; -- without order by By default, the sorting statement sorts all the data in the group sum operation
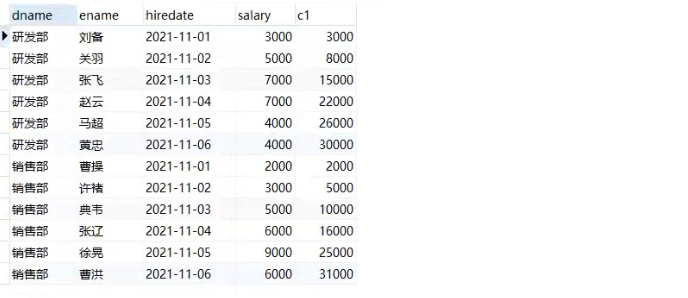
select dname, ename, hiredate, salary, sum(salary) over(partition by dname order by hiredate rows between unbounded preceding and current row) as c1 from employee; #Add from beginning to current line
select dname, ename, salary, sum(salary) over(partition by dname order by hiredate rows between 3 preceding and current row) as c1 from employee; #Add from the first three lines of the current line to the current line

#Similarly, add the current first three lines to the current next line (including this line) select dname, ename, salary, sum(salary) over(partition by dname order by hiredate rows between 3 preceding and 1 following) as c1 from employee; #Add from current line to last line select dname, ename, salary, sum(salary) over(partition by dname order by hiredate rows between current row and unbounded following) as c1 from employee;
4. Distribution function (CUME_DIST)
(1) Purpose: the number of rows less than or equal to the current rank value in the group / the total number of rows in the group
(2) Application scenario: query the proportion less than or equal to the current salary
(3) Example
select dname, ename, salary, cume_dist() over(order by salary) as rn1, -- No, partition Statement all data in a group cume_dist() over(partition by dname order by salary) as rn2 from employee;
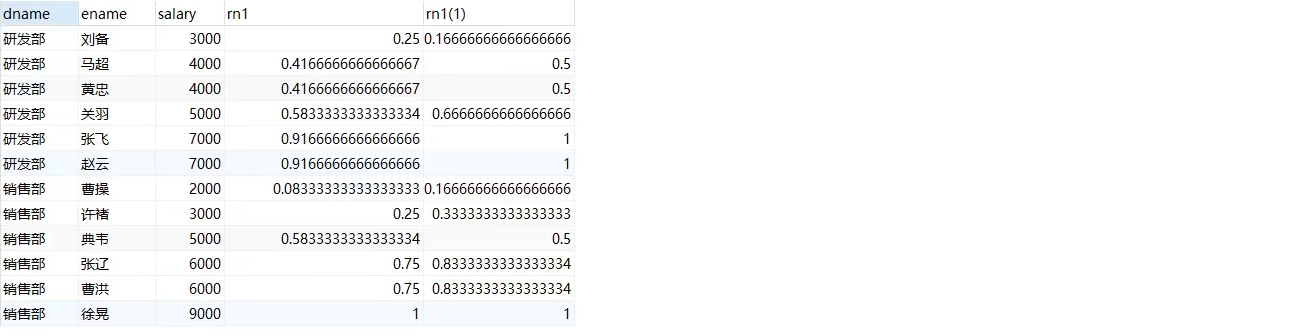
Explanation:
rn1 take the first row 0.25 as an example. Because there is no grouping, the number of rows less than or equal to 3000 divided by the total number of rows in all data. That is, 3 / 12 = 0.25.
rn2 take the first row 0.16666... As an example. Because it is grouped by dname, the number of rows less than or equal to 3000 in a group of data is divided by the total number of rows. I.e. 1 / 6 = 0.1666
5. Distribution function (PERCENT_RANK)
(1) Purpose: each line is calculated according to the formula (rank-1) / (rows-1). Where rank is the sequence number generated by RANK() function, and rows is the total number of records in the current window
(2) Application scenario: not commonly used
(3) Example
select dname, ename, salary, rank() over(partition by dname order by salary desc ) as rn, percent_rank() over(partition by dname order by salary desc ) as rn2 from employee;
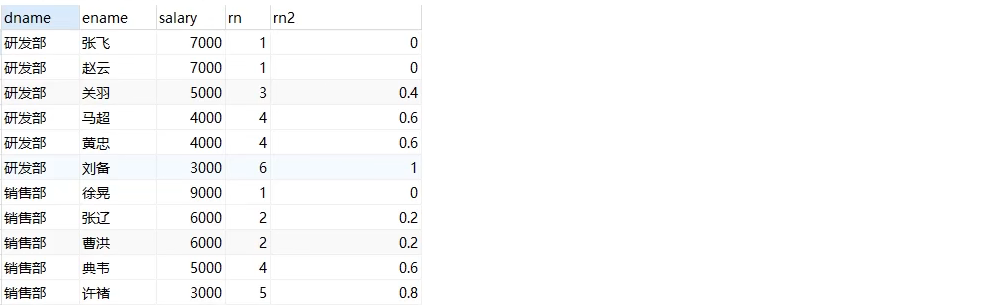
Explanation:
rn2:
First line: (1 - 1) / (6 - 1) = 0
Second line: (1 - 1) / (6 - 1) = 0
The third line: (3 - 1) / (6 - 1) = 0.4
6. Before and after functions (LAG and LEAD)
(1) Purpose: returns the value of expr in the first n rows (LAG(expr,n)) or the next n rows (LEAD(expr,n)) of the current row
(2) Application scenario: query the difference between the score of the first student and that of the current student
(3) Example
-- lag Usage of select dname, ename, hiredate, salary, lag(hiredate,1,'2000-01-01') over(partition by dname order by hiredate) as last_1_time, #The value of the previous line is placed in the current line. If not, the default value is' 2000-01-01 ' lag(hiredate,2) over(partition by dname order by hiredate) as last_2_time #The values of the first two lines are placed in the current line, and the default value is null from employee;
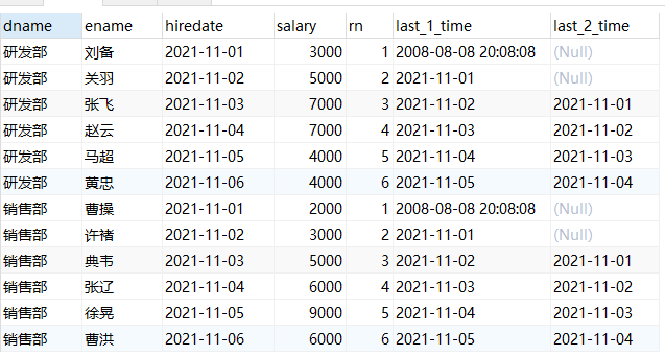
Explanation:
last_1_time: Specifies the value of the first line up, and the default is' 2000-01-01 '. In the first line, the up 1 line is null, so the default value '2000-01-01' is taken
last_2_time: Specifies the value of the second line up, and specifies the default value for
The first line, up 2, is null
-- lead Usage of select dname, ename, hiredate, salary, lead(hiredate,1,'2000-01-01') over(partition by dname order by hiredate) as last_1_time, lead(hiredate,2) over(partition by dname order by hiredate) as last_2_time from employee;
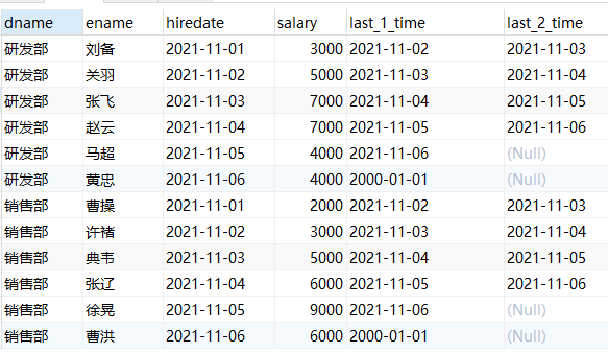
Explanation: lead works with lag, but the lead is down.
7. Head tail function
(1) Purpose: return the value of the first (FIRST_VALUE(expr)) or the last (LAST_VALUE(expr)) expr
(2) Application scenario: as of now, query the salary of the first and last employees by date
(3) Example
-- be careful, If not specified ORDER BY,The sorting is disordered, and wrong results will appear select dname, ename, hiredate, salary, first_value(salary) over(partition by dname order by hiredate) as first, last_value(salary) over(partition by dname order by hiredate) as last from employee;
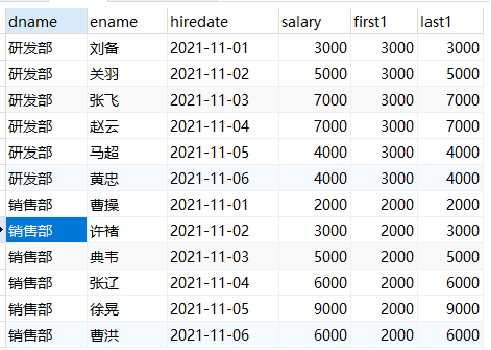
Explanation:
first1: return to the current, sort and query the salary of the first employee by date
last1: return to current, sort and query the salary of the first employee by date
8. Other functions (nth_value (expr, n))
(1) Purpose: return the value of the nth expr in the window. Expr can be an expression or a column name
(2) Application scenario: as of the current salary, the salary ranking second or third in each employee's salary is displayed
(3) Example
-- Query the information of employees whose salary ranks second and third in each department so far select dname, ename, hiredate, salary, nth_value(salary,2) over(partition by dname order by hiredate) as second_score, nth_value(salary,3) over(partition by dname order by hiredate) as third_score from employee
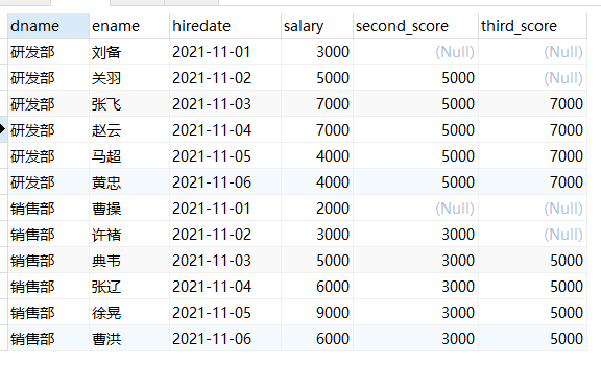
Explanation:
Returns the salary of the second and third ranked employees by employment date up to now
9. Other functions (ntile)
(1) Purpose: divide the ordered data in the partition into n levels and record the number of levels
(2) Application scenario: divide employees of each department into three groups according to their employment date
(3) Example
-- Divide the employees of each department into 3 groups according to the induction date select dname, ename, hiredate, salary, ntile(3) over(partition by dname order by hiredate ) as rn from employee;
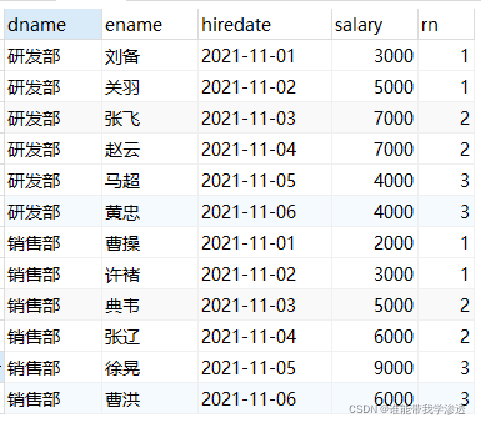
-- Take out the first group of employees in each department
select
*
from
(
SELECT
dname,
ename,
hiredate,
salary,
NTILE(3) OVER(PARTITION BY dname ORDER BY hiredate ) AS rn
FROM employee
)t
where t.rn = 1;