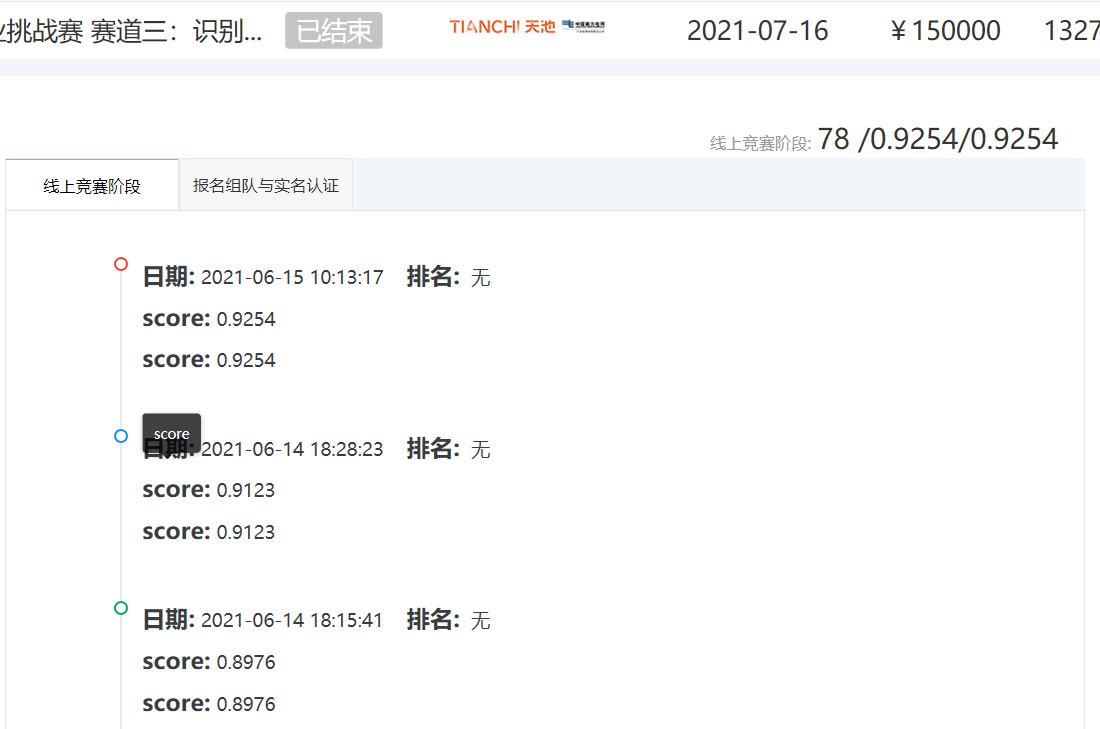
Record the problem-solving process of officially participating in the online algorithm competition for the first time. Although I missed the time of B list, I gained a lot!
Project introduction
Contest link: Track 3 of Guangdong power grid smart field operation challenge: identification of high-altitude operation and wearing of safety belt.

data processing
Label data extraction
The tag data extracted from csv is converted into json file, and then the json file is converted into a single coco dataset format tag, where the box coordinates are normalized x,y,w,h.
(1) Save the csv data tag as a json file. (data_deal.py) rewrite your own data processing code according to the specific text format.
'''
Official csv Medium
{
"meta":{},
"id":"88eb919f-6f12-486d-9223-cd0c4b581dbf",
"items":
[
{"meta":{"rectStartPointerXY":[622,2728],"pointRatio":0.5,"geometry":[622,2728,745,3368],"type":"BBOX"},"id":"e520a291-bbf7-4032-92c6-dc84a1fc864e","properties":{"create_time":1620610883573,"accept_meta":{},"mark_by":"LABEL","is_system_map":false},"labels":{"Label":"ground"}}
{"meta":{"pointRatio":0.5,"geometry":[402.87,621.81,909,1472.01],"type":"BBOX"},"id":"2c097366-fbb3-4f9d-b5bb-286e70970eba","properties":{"create_time":1620610907831,"accept_meta":{},"mark_by":"LABEL","is_system_map":false},"labels":{"Label":"safebelt"}}
{"meta":{"rectStartPointerXY":[692,1063],"pointRatio":0.5,"geometry":[697.02,1063,1224,1761],"type":"BBOX"},"id":"8981c722-79e8-4ae8-a3a3-ae451300d625","properties":{"create_time":1620610943766,"accept_meta":{},"mark_by":"LABEL","is_system_map":false},"labels":{"Label":"offground"}}
],
"properties":{"seq":"1714"},"labels":{"invalid":"false"},"timestamp":1620644812068
}
'''
import pandas as pd
import json
import os
from PIL import Image
df = pd.read_csv("3train_rname.csv",header=None)
df_img_path = df[4]
df_img_mark = df[5]
# print(df_img_mark)
# Count the categories, regenerate the original dataset annotation file, and save it to the json file
dict_class = {
"badge": 0,
"offground": 0,
"ground": 0,
"safebelt": 0
}
dict_lable = {
"badge": 1,
"offground": 2,
"ground": 3,
"safebelt": 4
}
data_dict_json = []
image_width, image_height = 0, 0
ids = 0
false = False # Convert the false field to the Boolean false
true = True # Convert the true field to Boolean true
for img_id, one_img in enumerate(df_img_mark):
# print('img_id',img_id)
one_img = eval(one_img)["items"]
# print('one_img',one_img)
one_img_name = df_img_path[img_id]
img = Image.open(os.path.join("./", one_img_name))
# print(os.path.join("./", one_img_name))
ids = ids + 1
w, h = img.size
image_width += w
# print(image_width)
image_height += h
# print(one_img_name)
i=1
for one_mark in one_img:
# print('%d '%i,one_mark)
one_label = one_mark["labels"]['label']
# print('%d '%i,one_label)
try:
dict_class[str(one_label)] += 1
# category = str(one_label)
category = dict_lable[str(one_label)]
bbox = one_mark["meta"]["geometry"]
except:
dict_class["badge"] += 1 # The label "monitoring armband (red only)" indicates the category "badge"
# category = "badge"
category = 1
bbox = one_mark["meta"]["geometry"]
i+=1
one_dict = {}
one_dict["name"] = str(one_img_name)
one_dict["category"] = category
one_dict["bbox"] = bbox
data_dict_json.append(one_dict)
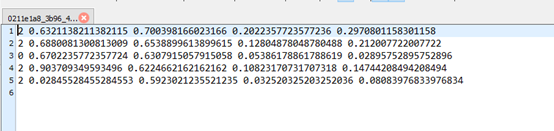
print(image_height / ids, image_width / ids)
print(dict_class)
print(len(data_dict_json))
print(data_dict_json[0])
with open("./data.json2", 'w') as fp:
json.dump(data_dict_json, fp, indent=1, separators=(',', ': ')) # Indent is set to 1, elements are separated by commas, and key s and contents are separated by colons
fp.close()
Generate data JSON file:
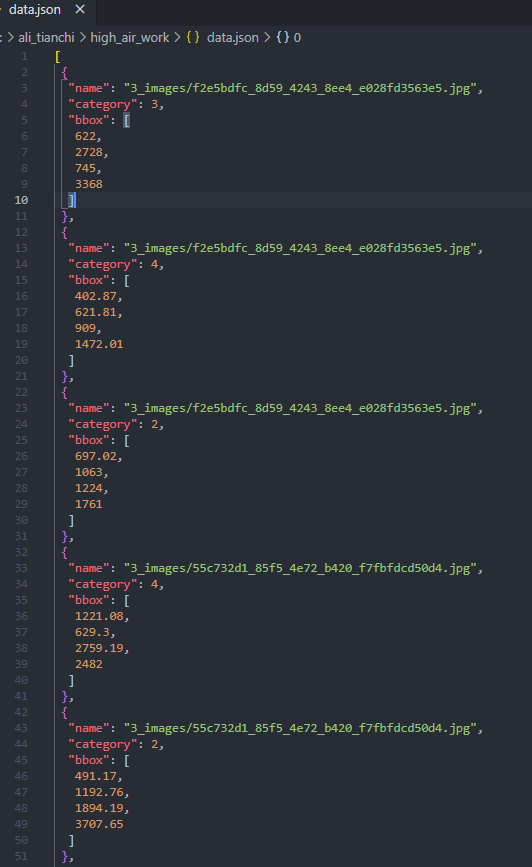
Label dataset production
(2) Insert data json file prepares the data according to the label format of coco data (save the labels information in the json file according to the name of the picture)_ to_ txt. Py here, all tags are subtracted by one, and you can do it yourself. The current tag: "badge": 0, "off ground": 1, "ground": 2, "safebelt": 3 bbox is normalized (for this sub data set, some data sets have different formats, which can be changed according to specific circumstances)
import json
import os
import cv2
file_name_list = {}
with open("./data.json", 'r', encoding='utf-8') as fr:
data_list = json.load(fr)
file_name = ''
label = 0
[x1, y1, x2, y2] = [0, 0, 0, 0]
for data_dict in data_list:
for k,v in data_dict.items():
if k == "category":
label = v
if k == "bbox":
[x1, y1, x2, y2] = v
if k == "name":
file_name = v[9:-4]
if not os.path.exists('./data1/'):
os.mkdir('./data1/')
print('./3_images/' + file_name + '.jpg')
img = cv2.imread('./3_images/' + file_name + '.jpg')
size = img.shape # (h, w, channel)
dh = 1. / size[0]
dw = 1. / size[1]
x = (x1 + x2) / 2.0
y = (y1 + y2) / 2.0
w = x2 - x1
h = y2 - y1
x = x * dw
w = w * dw
y = y * dh
h = h * dh
# print(size)
# cv2.imshow('image', img)
# cv2.waitKey(0)
content = str(label-1) + " " + str(x) + " " + str(y) + " " + str(w) + " " + str(h) + "\n"
if not content:
print(file_name)
with open('./data1/' + file_name + '.txt', 'a+', encoding='utf-8') as fw:
fw.write(content)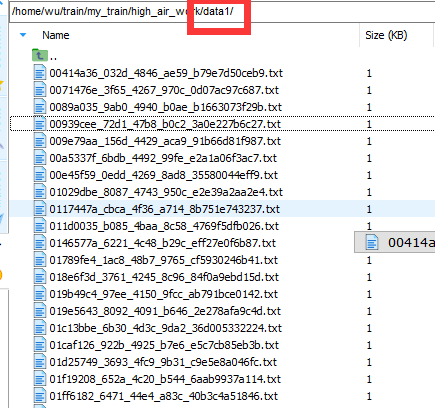
model training
reference resources: yolov5 training your own data set (one article training)
Data set division (there is a step before here! Because the script when dividing the data set is indexed according to the file name, but there are more than one image format this time, so before that, change all images to a unified suffix: remane.py)
import os
class BatchRename():
# Batch rename picture files in folders
def __init__(self):
self.path = './3_images' #Represents the folder that needs naming processing
def rename(self):
filelist = os.listdir(self.path) #Get file path
total_num = len(filelist) #Get file length (number)
print(total_num)
i = 1 #Indicates that the file naming starts with 1
for item in filelist:
# print(item)
file_name=item.split('.',-1)[0]
# print(file_name)
src = os.path.join(os.path.abspath(self.path), item)
# print(src)
dst = os.path.join(os.path.abspath(self.path), file_name + '.jpg')
# print(dst)
try:
os.rename(src, dst)
print ('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print ('total %d to rename & converted %d jpgs' % (total_num, i))
if __name__ == '__main__':
demo = BatchRename()
demo.rename()Modify training parameters (path and its own category)
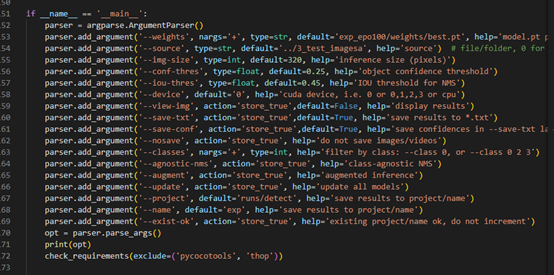
train
Write your own detect Py file (it doesn't need to be changed here, just save all the required parameters in the test results, and pass in the following parameters in the detect.py file)
Data integration
Detected results (pictures and all label files):
cls bbox score detected by the current picture is saved in each txt:
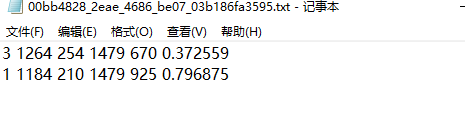
What we need to do is to index the corresponding test results in the results folder according to the picture order in the csv of the test data provided by the sponsor, and save all the results in the json file according to the data format given by the sponsor. result_imerge_2.py file (here, because the training data label is not exactly the same as the submitted label, the submitted result must be the label of the corresponding person of the class, so we need to integrate the results and extract useful data. At present, our logical relationship needs to be further improved)
import pandas as pd
import json
import os
import copy
global data_dict_json
data_dict_json = []
def check_equip(id, equip_list, people_list, cls_result, cls_result2=-1):
for people in people_list:
dict4 = {}
dict_cls = {'image_id': id, 'category_id': -1, 'bbox': [], 'score': 0}
x1, y1, x2, y2, score2 = people
if equip_list:
for equip in equip_list:
dict1, dict2, dict3 = {}, {}, {}
equip_x1, equip_y1, equip_x2, equip_y2, score = equip
center_x = (int(equip_x1) + int(equip_x2)) / 2
center_y = (int(equip_y1) + int(equip_y2)) / 2
if center_x > int(x1) and center_x < int(x2) and center_y < int(y2) and center_y > int(y1):
dict1 = copy.deepcopy(dict_cls)
dict1['image_id'] = id
dict1['category_id'] = cls_result
dict1['bbox'] = list(map(int, people[:-1]))
dict1['score'] = float(score2)
if dict1['category_id'] != -1:
if not dict1 in data_dict_json:
data_dict_json.append(dict1)
dict2 = copy.deepcopy(dict_cls)
dict2['image_id'] = id
dict2['category_id'] = cls_result2
dict2['bbox'] = list(map(int, people[:-1]))
dict2['score'] = float(score2)
if dict2['category_id'] != -1:
if not dict2 in data_dict_json:
data_dict_json.append(dict2)
else:
dict3 = copy.deepcopy(dict3)
dict3['image_id'] = id
dict3['category_id'] = cls_result2
dict3['bbox'] = list(map(int, people[:-1]))
dict3['score'] = float(score2)
if dict3['category_id'] != -1:
if not dict3 in data_dict_json:
data_dict_json.append(dict3)
else:
dict4 = copy.deepcopy(dict_cls)
dict4['image_id'] = id
dict4['category_id'] = cls_result2
dict4['bbox'] = list(map(int, people[:-1]))
dict4['score'] = float(score2)
if dict4['category_id'] != -1:
if not dict4 in data_dict_json:
data_dict_json.append(dict4)
def save_json(file_lines):
badge_list = []
off_list = []
ground_list = []
safebelt_list = []
person_list=[]
for line in file_lines:
line2 = str(line.strip('\n'))
content = line2.split(' ', -1)
if int(content[0]) == 0:
badge_list.append(content[:])
elif int(content[0]) == 1:
off_list.append(content[:])
person_list.append(content[:-1])
elif int(content[0]) == 2:
ground_list.append(content[:])
person_list.append(content[:-1])
elif int(content[0]) == 3:
safebelt_list.append(content[:])
# print('+++++++',person_list)
return person_list
df = pd.read_csv("3_testa_user.csv", header=None)
df_img_path = df[0]
for id, one_img in enumerate(df_img_path):
# dict_data={}
file_name_img = (str(one_img)).split('/', -1)[1]
# print(file_name_img)
file_name_label = file_name_img.split('.', -1)[0] + '.txt'
# print(file_name_label)
path = os.path.join("./exp_epo50_089/labels/", file_name_label) # +file_name_label
file = open(path, 'r')
file_lines = file.readlines()
# print(id, file_lines)
person_list=save_json(file_lines)
dict1, dict2, dict3 = {}, {}, {}
for line in file_lines:
# dict1, dict2, dict3 = {}, {}, {}
# print('___+++___')
line2 = str(line.strip('\n'))
content = line2.split(' ', -1)
cls, equip_x1, equip_y1, equip_x2, equip_y2, score = content[:]
center_x = (int(equip_x1) + int(equip_x2)) / 2
center_y = (int(equip_y1) + int(equip_y2)) / 2
# print(content)
if int(content[0])==1:
dict3['image_id'] = int(id)
dict3['category_id'] = 3
dict3['bbox'] = list(map(int, content[1:-1]))
dict3['score'] = float(content[-1])
if dict3 not in data_dict_json:
data_dict_json.append(dict3)
elif int(content[0])==0:
for i in person_list:
print(i)
cls,x1,y1,x2,y2=i
if int(center_x)<int(x2) and int(x1)<int(center_x) and int(y1)<int(center_y) and int(center_y)<int(y2):
dict1['image_id'] = int(id)
dict1['category_id'] = 1
dict1['bbox'] = list(map(int, i[1:]))
# print(' ',list(map(int, i_list[1:-1])))
dict1['score'] = float(content[-1])
if dict1 not in data_dict_json:
data_dict_json.append(dict1)
elif int(content[0])==3:
for i in person_list:
cls,x1,y1,x2,y2=i
if int(center_x) < int(x2) and int(x1) < int(center_x) and int(y1) < int(center_y) and int(
center_y) < int(y2):
dict2['image_id'] = int(id)
dict2['category_id'] = 2
dict2['bbox'] = list(map(int, i[1:]))
dict2['score'] = float(content[-1])
if dict2 not in data_dict_json:
data_dict_json.append(dict2)
with open("./data_result2.json", 'w') as fp:
json.dump(data_dict_json, fp, indent=1, separators=(',', ': ')) # Indent is set to 1, elements are separated by commas, and key s and contents are separated by colons
fp.close()Generation result: data_result.json file
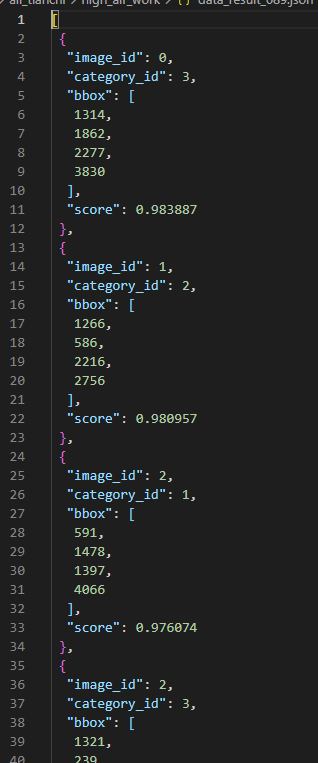
Visual display
Draw the final result on the original picture. It is convenient for us to check the correctness of the results. result_show.py
import cv2
import json
import os
import pandas as pd
file_name_list= {}
df = pd.read_csv("3_testa_user.csv",header=None)
# print(df[0][0])
dict_cls={1:'guarder',2:'safebeltperson',3:'offgroundperson'}
with open("data_resultcopy2.json",'r',encoding='utf-8')as fr:
data_list = json.load(fr)
# file_name = ''
# label = 0
# [x, y, w, h] = [0, 0, 0, 0]
i=0
for data_dict in data_list:
print(data_dict)
img_id = data_dict['image_id']
print(img_id)
file_path=df[0][img_id]
save_path='test_view_data_resultcopy2/'
if not os.path.exists(save_path):
os.mkdir(save_path)
save_name=save_path+str(i)+'_'+(str(df[0][img_id])).split('/',-1)[1]
print(save_name)
img = cv2.imread(file_path)
# cv2.imshow('a',img)
# cv2.waitKey(0)
cls=dict_cls[data_dict['category_id']]
score=data_dict['score']
x1,y1,x2,y2=data_dict['bbox']
# print(x1,y1,x2,y2)
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 0, 255), 2)
cv2.putText(img,str(cls)+' '+str(score),(x1,y1),cv2.FONT_HERSHEY_SIMPLEX,2,(0,0,255),3)
cv2.imwrite(save_name,img)
i+=1
Continue to improve ideas
Data enhancement
It is observed that both off ground and ground are human. Therefore, in order to improve the accuracy of the last submitter's box, all the off ground and ground and the person classes in track 1 and track 2 form a large person dataset as the fourth label. Finally, the bbox of the person class will be more accurate. Then, for the small target armband, we extract the data from track 1 and track 2.
Track one and two data extraction
According to the given csv tag, the tag data of armband and person are extracted separately and stored in json file. Using data_deal.py file, as follows:
Visualize the proposed data:
Convert json tag to normalized coco dataset format json_to_txt.py
Unify the pictures in the original dataset into jpg format (easy to divide the dataset)
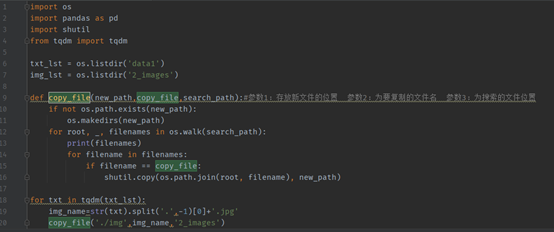
copy the picture corresponding to the required label, and then add it to the data of track 3_ file. Py (continue to use this method to bring out the armband data of track 2 and track 1. Note that the label of each track should be changed to be consistent with the official prompt)
final result