Blocking IO Model (Blocking I/O)
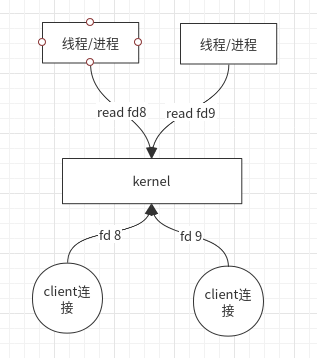
The Linux kernel initially provides read and write blocking operations.
- When a client connects, a corresponding file descriptor (0 standard input, 1 standard output, 2 standard error output) is generated in the file descriptor directory of the corresponding process (/proc/process number/fd), such as FD 8, FD 9;
- When an application needs to read, it reads through the system call read (fd8), and if the data has not arrived, the process or thread of the application will block the wait.
man 2 read
Summary
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
describe
read() Reads count bytes from file descriptor fd and places them in a buffer starting with buf.
If count is zero, read() returns 0, doing nothing else. If count is greater than SSIZE_MAX, the result is unpredictable.
Return value
Returns the number of bytes read upon success (zero means read to file descriptor), which is limited by the number of bytes remaining in the file. When the return value is less than the specified number of bytes, it does not mean an error; this may be because the number of bytes currently readable is less than the specified number of bytes (such as nearing the end of the file, or
A reader is reading data from a pipeline or terminal, or read() is interrupted by a signal). When an error occurs, it returns -1 and collocates errno with the corresponding value. In this case, it is not possible to know if the file offset location has changed.
problem
If there are many client connections, such as 1000, the application will enable 1000 processes or threads to block waiting.Performance issues arise:
- CPU will keep switching, causing process or thread context switching overhead, actual time to read IO will decrease, resulting in waste of CPU power. Therefore, the birth of non-blocking I/O was promoted.
Non-blocking IO Model (non-blocking I/O)
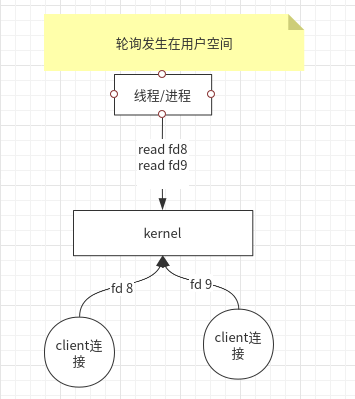
At this point, the Linux kernel initially provides read and write non-blocking operations, and SOCK_NONBLOCK tags can be set through socket s.
- At this point, the application does not need one thread per file descriptor to process, only one thread can read without interrupting polling, and it will return directly if no data arrives.
- If you have data, you can schedule to process business logic.
man 2 socket
Since Linux 2.6.27, the type argument serves a second purpose: in addition to specifying a socket type, it may include the bitwise OR of any of the following values, to modify the behavior of socket(): SOCK_NONBLOCK Set the O_NONBLOCK file status flag on the open file description (see open(2)) referred to by the new file descriptor. Using this flag saves extra calls to fcntl(2) to achieve the same result.
You can see from this that the socket Linux 2.6.27 kernel is beginning to support non-blocking mode.
problem
Similarly, when there are many client connections, such as 1000, it triggers 1000 system calls.(1000 system call overhead is also objective)
Therefore, there is a select.
IO Reuse Model (I/O multiplexing) - select
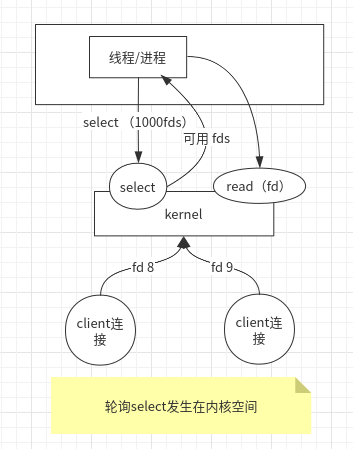
At this point, the Linux kernel begins with a select operation that simplifies 1,000 system calls to one system call, where polling occurs in kernel space.
- The select system call returns the available fd collection, and the application only needs to traverse the available fd collection to read the data for business processing.
man 2 select
SYNOPSIS #include <sys/select.h> int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); DESCRIPTION select() allows a program to monitor multiple file descriptors, waiting until one or more of the file descriptors become "ready" for some class of I/O operation (e.g., input possible). A file descriptor is considered ready if it is possible to perform a corresponding I/O operation (e.g., read(2), or a sufficiently small write(2)) without blocking. select() can monitor only file descriptors numbers that are less than FD_SETSIZE; poll(2) and epoll(7) do not have this limitation. See BUGS.
You can see support for transferring multiple file descriptors to the kernel for polling.
problem
Although the cost of one system call has been reduced from 1000 system calls, 1000 file descriptors need to be passed in for system call overhead.This can also cause memory overhead.
Therefore, there is epoll.
select() can monitor only file descriptors numbers that are less than FD_SETSIZE; poll(2) and epoll(7) do not have this limitation. See BUGS.
IO Reuse Model (I/O multiplexing) - epoll
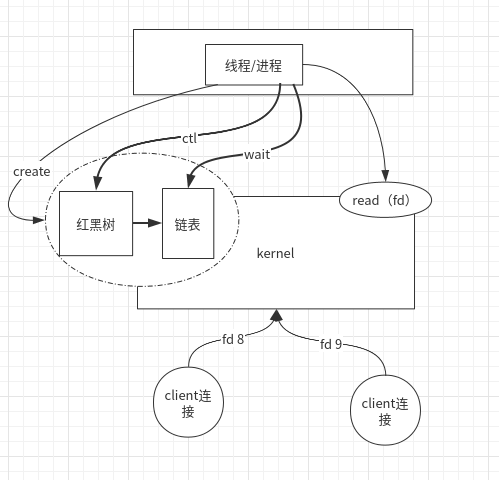
man epoll man 2 epoll_create man 2 epoll_ctl man 2 epoll_wait
- epoll:
SYNOPSIS #include <sys/epoll.h> DESCRIPTION The epoll API performs a similar task to poll(2): monitoring multiple file descriptors to see if I/O is possible on any of them. The epoll API can be used either as an edge-triggered or a level-triggered interface and scales well to large numbers of watched file descriptors. The central concept of the epoll API is the epoll instance, an in-kernel data structure which, from a user-space perspective, can be considered as a container for two lists: • The interest list (sometimes also called the epoll set): the set of file descriptors that the process has registered an interest in monitoring. • The ready list: the set of file descriptors that are "ready" for I/O. The ready list is a subset of (or, more precisely, a set of references to) the file descriptors in the interest list. The ready list is dynamically populated by the kernel as a result of I/O activity on those file descriptors.
- epoll_create :
The kernel produces an epoll instance data structure and returns a file descriptor epfd.
- epoll_ctl :
Register the file descriptor fd with its listening event epoll_event, delete it, or modify its listening event epoll_event.
SYNOPSIS #include <sys/epoll.h> int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); DESCRIPTION This system call is used to add, modify, or remove entries in the interest list of the epoll(7) instance referred to by the file descriptor epfd. It requests that the operation op be performed for the target file descriptor, fd. Valid values for the op argument are: EPOLL_CTL_ADD Add an entry to the interest list of the epoll file descriptor, epfd. The entry includes the file descriptor, fd, a reference to the corresponding open file description (see epoll(7) and open(2)), and the settings specified in event. EPOLL_CTL_MOD Change the settings associated with fd in the interest list to the new settings specified in event. EPOLL_CTL_DEL Remove (deregister) the target file descriptor fd from the interest list. The event argument is ignored and can be NULL (but see BUGS below).
- epoll_wait :
Blocks events waiting to be registered, returns the number of events, and writes available triggered events to the epoll_events array.
extend
Other IO optimization techniques
man 2 mmap man 2 sendfile man 2 fork
mmap:
It is to find a free section of address in the user's virtual address space to operate on the file, without calling read and write system calls anymore. Its ultimate purpose is to map the files on disk to the virtual address space of the user's process, realize the direct read and write of files by the user's process, reduce the cost of file copying, and improve the user's access efficiency.
Take reading for example:
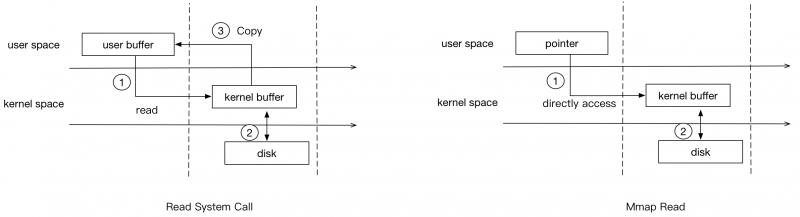
-
An in-depth analysis of mmap principles - starting with three key issues: https://www.jianshu.com/p/eece39beee20
-
Use scenarios
The data file of kafka is mmap, which is used to write the file. It can directly drop the kernel space without passing the user space to the kernel copy.
Another example is MappedByteBuffer in Java, where the bottom layer is mmap on Linux.
sendfile:
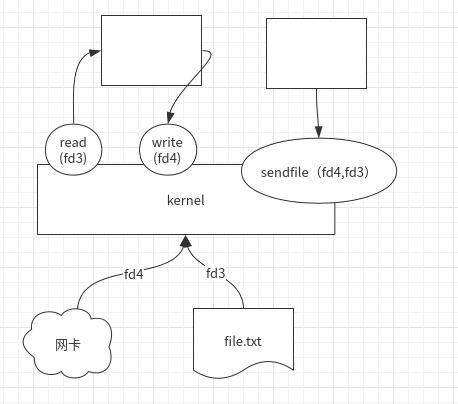
The sendfile system call passes data directly between two file descriptors (operating entirely in the kernel), thus avoiding duplication of data between the kernel buffer and the user buffer. It is highly efficient and is called a zero copy.
- Use scenarios
For example, when consumers consume, kafka directly calls sendfile (FileChannel.transferTo in Java), which reads out the kernel data from memory or data files and sends it directly to the network card without two copies of user space, thus achieving the so-called "zero copy".
For example, web servers such as Tomcat, Nginx, Apache return static resources and send data over the network using sendfile.
fork
man 2 fork
There are three ways to create a child process:
- fork, after invocation, the child process has its own pid and task_struct structure, copies based on all the data resources of the parent process, mainly copying its own pointer, does not copy the virtual space of the parent process, and the parent and child processes work simultaneously, with variables isolated from each other and not interfering with each other.
Now Linux uses Copy-On-Write(COW) technology. To reduce overhead, fork did not actually produce two different copies at first because at that time, a lot of data was exactly the same. Write-time replication is postponing the actual data copy.If a write does occur later, it means that the data of the parent and child processes are inconsistent, and a copy action occurs where each process gets its own copy, which reduces the overhead of system calls.
NOTES Under Linux, fork() is implemented using copy-on-write pages, so the only penalty that it incurs is the time and memory required to duplicate the parent's page tables, and to create a unique task structure for the child.
-
vfork, vfork system call is different from fork, the child process created with vfork shares address space with the parent process, that is, the child process runs completely on the address space of the parent process, that is, the child process changes any data in the virtual address space as seen by the parent process.And vfork finishes the child process, and the parent process is blocking until the child process finishes before continuing.
-
Clone, can be considered as a mixture of fork and vfork.It is up to the user to decide which resources are shared and which copies of the resources are copied by referring to the clone_flags settings.The flag CLONE_VFORK determines whether the parent process is blocked or running when the child process executes. If the flag is not set, the parent and child processes run simultaneously. If the flag is set, the parent process hangs until the child process ends.
-
summary
- Use of fork A process wants to copy itself so that the parent and child processes can execute different pieces of code at the same time. For example, redis RDB persistence uses fork, which ensures that the copy is accurate and fast, without affecting the parent process from continuing to serve.
- Use of vfork The main purpose of processes created with vfork is to execute another program first with the exec function.
- Use of clone Used to selectively set which resources need to be shared between parent and child processes and which resources need replica copies.