Programmer must read list: https://github.com/silently9527/ProgrammerBooks
WeChat official account: beta Java
preface
In the previous articles, we learned how to implement Map Based on array, linked list, binary tree and red black tree. In this article, we will learn how to implement Map Based on hash table. This method corresponds to HashMap in java, which is also the most used method
The implementation of Map in hash table is mainly divided into two steps:
- The key based lookup function is converted to a hash based array
- There are two ways to deal with hash value conflicts: zipper and linear detection
Hash function
The first step to realize the hash is to consider how to convert a key into the index of the array. At this time, you need to use the hash function. First convert the key value into an integer, and then calculate the index of the array by using the division and remainder method. We need a different hash function for each type of key.
In java, hashCode has been implemented for common data types. We only need to use the division and remainder method according to the value of hashCode to convert it into the subscript of the array
Convention in java: if the equals of two objects are equal, the hashCode must be the same; If hashcodes are the same, equals is not necessarily the same. For custom type keys, we usually need to customize the implementation of hashCode and equals; The default hashCode returns the memory address of the object. This hash value will not be very good.
Let's take a look at the hashCode calculation methods commonly used in Java
Integer
The implementation of hacode needs to directly return the value of hacode, so it is very simple to return the value of hacode
@Override
public int hashCode() {
return Integer.hashCode(value);
}
public static int hashCode(int value) {
return value;
}
Long
The hashCode calculation of Long type in Java is to first move the value unsigned right by 32 bits, and then differ from or from the value to ensure that each bit is used, and finally forcibly convert it to int value
@Override
public int hashCode() {
return Long.hashCode(value);
}
public static int hashCode(long value) {
return (int)(value ^ (value >>> 32));
}
Double,Float
The implementation of hashCode in java for floating-point keys is to represent the keys as binary
public static int hashCode(float value) {
return floatToIntBits(value);
}
public static int floatToIntBits(float value) {
int result = floatToRawIntBits(value);
// Check for NaN based on values of bit fields, maximum
// exponent and nonzero significand.
if ( ((result & FloatConsts.EXP_BIT_MASK) ==
FloatConsts.EXP_BIT_MASK) &&
(result & FloatConsts.SIGNIF_BIT_MASK) != 0)
result = 0x7fc00000;
return result;
}
String
Each char in java can be expressed as an int value, so the string is converted into an int value
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
Soft cache
If calculating a hash value is time-consuming, I can cache the calculated value, that is, use a variable to save the value and return it directly at the next call. String in Java adopts this method.
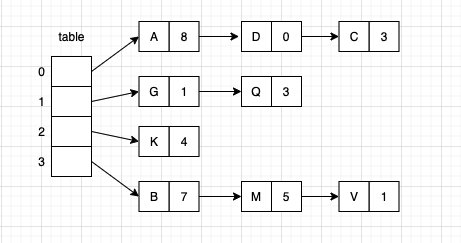
Zipped hash table
The hash function can convert the key value into the subscript of the array; The second step is to deal with collision, that is, how to store two objects with the same hash value. One way is that each element in the array points to a linked list to store objects with the same hash value. This method is called zipper method
The zipper method can use the original linked list to save keys, or it can be represented by the red black tree we implemented before. The mixture of the two methods used in java8 becomes a red black tree after the number of nodes exceeds 8.
Here we use a simple linked list to realize the zipper hash table. The data structure uses the LinkedMap that has been implemented in the previous articles. You can refer to the previous articles Implementation of Map based on array or linked list.
public class SeparateChainingHashMap<K, V> implements Map<K, V> {
private int size;
private LinkedMap<K, V>[] table;
public SeparateChainingHashMap(int capacity) {
this.table = (LinkedMap<K, V>[]) new LinkedMap[capacity];
for (int i = 0; i < capacity; i++) {
this.table[i] = new LinkedMap<>();
}
}
@Override
public void put(K key, V value) {
this.table[hash(key)].put(key, value);
size++;
}
private int hash(K key) {
return (key.hashCode() & 0x7fffffff) % table.length;
}
@Override
public V get(K key) {
return this.table[hash(key)].get(key);
}
@Override
public void delete(K key) {
this.table[hash(key)].delete(key);
size--;
}
@Override
public int size() {
return size;
}
}
This hash function uses the hashCode of the key and the upper 0x7FFFFFFF to get a non negative integer, and then uses the division and remainder method to calculate the subscript of the array. The binary representation of 0x7FFFFFFF is 1 except that the first bit is 0, that is, this is the largest integer int (because the first bit is a sign bit, 0 means it is a positive number). Integer can be used MAX_ Value instead
The main purpose of the hash table is to evenly distribute the key values into the array, so the hash table is unordered. If the Map you need needs to support fetching the maximum and minimum values, the hash table is not suitable.
The array size of the zipper hash table we implemented here is fixed, but usually with the increase of the amount of data, the collision probability of the shorter array will increase, so the array needs to support dynamic capacity expansion. After capacity expansion, the original value needs to be re inserted into the expanded array. For the expansion of array, please refer to the previous article Brother, it's time to review data structures and algorithms
Linear detection hash table
Another way to implement hash table is to save N key values with size M, where M > N; To solve the collision conflict, we need to use the empty bits in the array; The simplest implementation of this method is linear detection.
The main idea of linear detection: when a key is inserted and a collision occurs, the index is directly added to check the next position. At this time, there are three situations:
- If the next position is equal to the key to be inserted, the value is modified
- If the next position is not equal to the key to be inserted, add one to the index to continue searching
- If the next position is still an empty space, then directly put the object to be inserted into this empty space
initialization
Linear probing hash table uses two arrays to store keys and values. capacity indicates the size of the initialization array
private int size;
private int capacity;
private K[] keys;
private V[] values;
public LinearProbingHashMap(int capacity) {
this.capacity = capacity;
this.keys = (K[]) new Object[capacity];
this.values = (V[]) new Object[capacity];
}
insert
- When the position of the insert key exceeds the size of the array, you need to go back to the beginning of the array to continue searching until you find a null position; index = (index + 1) % capacity
- When the storage capacity of the array exceeds half of the total capacity of the array, it needs to be expanded to twice the original capacity
@Override
public void put(K key, V value) {
if (Objects.isNull(key)) {
throw new IllegalArgumentException("Key can not null");
}
if (this.size > this.capacity / 2) {
resize(2 * this.capacity);
}
int index;
for (index = hash(key); this.keys[index] != null; index = (index + 1) % capacity) {
if (this.keys[index].equals(key)) {
this.values[index] = value;
return;
}
}
this.keys[index] = key;
this.values[index] = value;
size++;
}
Dynamically resize the array
We can refer to the previous article Brother, it's time to review data structures and algorithms Dynamically adjusting the size of data; In linear detection, the original data needs to be reinserted into the data after capacity expansion. Because the size of the array changes, the position of the index needs to be recalculated.
private void resize(int cap) {
LinearProbingHashMap<K, V> linearProbingHashMap = new LinearProbingHashMap<>(cap);
for (int i = 0; i < capacity; i++) {
linearProbingHashMap.put(keys[i], values[i]);
}
this.keys = linearProbingHashMap.keys;
this.values = linearProbingHashMap.values;
this.capacity = linearProbingHashMap.capacity;
}
query
The idea of realizing query in linear detection hash table: calculate the position of the index according to the hash function of the key to be queried, and then start to judge whether the key in the current position is equal to the key to be queried. If it is equal, it will directly return value. If it is not equal, it will continue to find the next index until a certain position is null, indicating that the key to be queried does not exist;
@Override
public V get(K key) {
if (Objects.isNull(key)) {
throw new IllegalArgumentException("Key can not null");
}
int index;
for (index = hash(key); this.keys[index] != null; index = (index + 1) % capacity) {
if (this.keys[index].equals(key)) {
return this.values[index];
}
}
return null;
}
Delete element
Linear detection deletion is a little troublesome. First, you need to find the location of the element to be deleted. After deleting the element, you need to reinsert the elements at the continuous position after the current index; Because whether there is a vacancy is very important for the search of linear detection hash table; For example: 5 - > 7 - > 9. After deleting 7, if the position of 7 is empty without reinsertion, the get method will not be able to query the element 9;
After each deletion, you need to check the number of actual elements in the array. If there is a large difference between the number of elements and the capacity of the array, you can shrink the size;
@Override
public void delete(K key) {
if (Objects.isNull(key)) {
throw new IllegalArgumentException("Key can not null");
}
int index;
for (index = hash(key); this.keys[index] != null; index = (index + 1) % capacity) {
if (this.keys[index].equals(key)) {
this.keys[index] = null;
this.values[index] = null;
break;
}
}
for (index = (index + 1) % capacity; this.keys[index] != null; index = (index + 1) % capacity) {
this.size--;
this.put(this.keys[index], this.values[index]);
this.keys[index] = null;
this.values[index] = null;
}
this.size--;
if (size > 0 && size < capacity / 4) {
resize(capacity / 2);
}
}
All the source codes in this article have been put into the github warehouse:
https://github.com/silently9527/JavaCore
Last (focus, don't get lost)
There may be more or less deficiencies and mistakes in the article. If you have suggestions or opinions, you are welcome to comment and exchange.
Finally, writing is not easy. Please don't whore me for nothing. I hope friends can praise, comment and pay attention to Sanlian, because these are all the power sources I share 🙏
The beautiful Amoy project is completely open source, and friends in need are concerned about the official account: beta java; Send "source code"