MySQL sub database and table can be realized through the middleware Mycat. This paper briefly introduces several partition strategies of Mycat, mode, range and hash, and tests and verifies them respectively
1. MySQL implements database and table splitting based on Mycat
1.1 principle of warehouse and table division
Data sharding can be divided into vertical sharding and horizontal sharding according to the type of sharding rules:
- Vertical segmentation is to segment into different databases according to different tables. It is suitable for systems with low coupling between business systems and clear business logic
- Horizontal segmentation is to split the data in the same table into multiple databases according to some conditions according to the logical relationship of the data in the table, which is more complex for the application
According to the vertical and horizontal segmentation, the sub database and sub table are divided into four types: horizontal sub database, horizontal sub table, vertical sub database and vertical sub table.
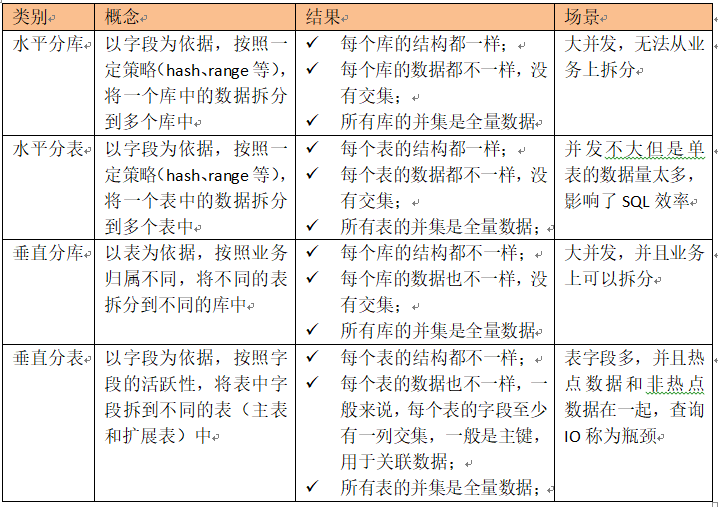
- MySQL vertical partition
MySQL vertical partition is to put the data of different businesses into different database servers in the application layer. When one business collapses, it will not affect the normal progress of other businesses, and can play the role of load diversion, which greatly improves the throughput of the database. The database architecture after vertical partition is as follows:
Vertical partition is to divide databases through different services, but some services are more or less connected, and this partition can not solve the problem of soaring data volume of a single service.
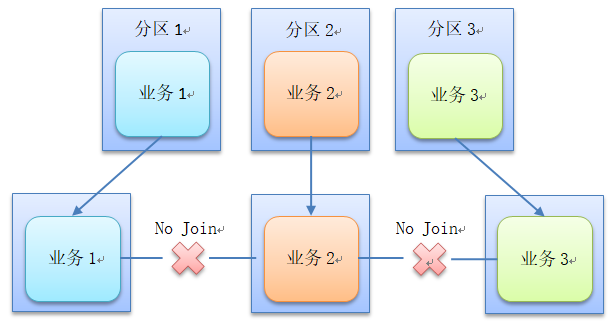
- MySQL horizontal Sharding
MySQL horizontal sharding is to group business data according to certain rules (such as id hash) and store the data of this group in a database shard. In this way, with the increase of the number of users, you can simply configure a server. The schematic diagram is as follows:
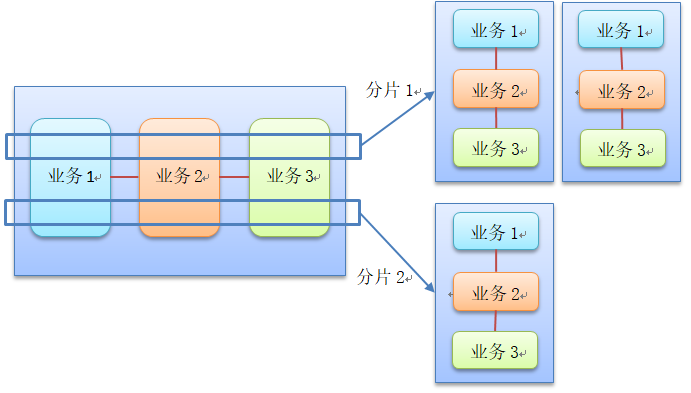
Although sub table and sub database can solve the pressure of large tables on the database system, it is not omnipotent. Sub database and sub table have the following principles:
- For tables within 10 million, fragmentation is not recommended. Performance problems can be solved through appropriate indexes
- The number of shards should be as small as possible and evenly distributed on multiple hosts, because the more shards a query SQL spans, the worse the overall performance
- The selection of fragmentation rules needs to consider the growth mode of data, the access mode of data, the relevance of fragmentation and the expansion of fragmentation
- Try not to span multiple slices of SQL in a transaction
- The query conditions shall be optimized to avoid the "Select *" method. Under a large number of data result sets, a large amount of bandwidth and CPU resources will be consumed
1.2 Mycat implements sub database and sub table
MyCAT implements sharding by defining the sharding rules of the table. The sharding rules will define the sharding field and algorithm. The sharding algorithm includes hash, modulus and range partition. Each table can be bound with a fragmentation rule. Each fragmentation rule specifies a fragmentation field and binds a function to realize the dynamic fragmentation algorithm.
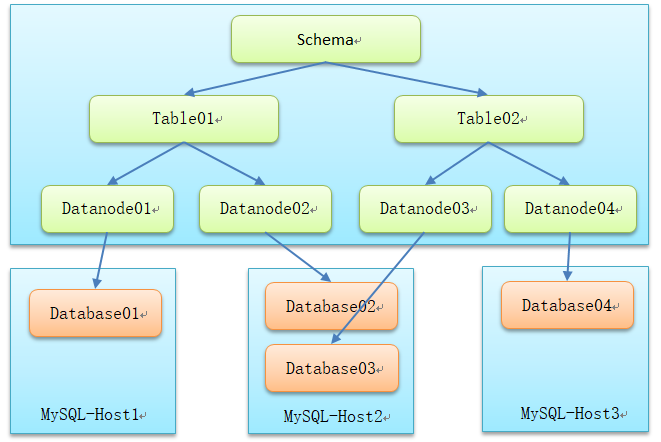
- Schema: logical library, which corresponds to the Database in MySQL. The included tables are defined in a logical library.
- Table: logical table, that is, a table stored in the physical database. Unlike the traditional database, the table here needs to declare its stored logical data node DataNode. Here, you can specify the fragmentation rules of the table.
- DataNode: the logical data node of MyCAT, which is the specific physical node storing the table, also known as the partition node. It is associated to a specific database at the back end through the DataSource
- Database: defines the access address of a physical library, which is used to bind to Datanode
- Sharding rules: as mentioned earlier, a large table is divided into several sharding tables, which requires certain rules. In this way, the rules for dividing data into shards according to certain business rules are sharding rules. It is very important to select appropriate sharding rules for data sharding, which will greatly avoid the difficulty of subsequent data processing
1.2.1 environmental preparation
1) MySQL master-slave replication cluster environment: refer to "MySQL master-slave replication cluster architecture deployment"
2) Mycat installation: refer to "MySQL master-slave copy read-write separation implementation"
3) Start MySQL Cluster Environment
[mysql@tango-centos01 mysql]$ service mysql start [mysql@tango-centos01 mysql]$ service mysql status
1.2.2 MyCAT sub database and sub table configuration
The configuration files in MYCAT mainly include schema XML and rule xml: schema.xml specifies the association relationship between each database node and the virtual database and table in MYCAT, and specifies the table splitting strategy of the current table; In rule XML specifies the specific table splitting strategy and the algorithm implementation class used. Commonly used slicing algorithms in MYCAT include modulus taking, range slicing and consistency hash algorithm. The following three algorithm configurations are introduced respectively.
1) Take mold
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- Specifies the name of the database displayed externally, that is, the client connection MyCat Database, developed database by mydb
The table configuration in the current database is based on the following configuration -->
<schema name="mydb" checkSQLschema="true" sqlMaxLimit="100">
<!-- Defines a t_goods Table whose primary key is id,This field is self growing, and the data of this table will be assigned to dn1,dn2 and
dn3 In fact, these three refer to the current situation MyCat The node name of the real database represented by the database. The specific configuration of each node is shown in the following table
Configuration in progress. here rule Property specifies t_goods The data in the table is assigned to dn1,dn2 and dn3 On the strategy, mod-long refer to
Allocate by long integer remainder, that is, by id Take the remainder of the number of nodes -->
<table name="t_goods" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2,dn3"
rule="mod-long"/>
</schema>
<!-- Specified separately dn1,dn2 and dn3 The relationship between the three nodes and the corresponding database, dataHost The corresponding is the following database node configuration -->
<dataNode name="dn1" dataHost="dhost1" database="db1"/>
<dataNode name="dn2" dataHost="dhost2" database="db2"/>
<dataNode name="dn3" dataHost="dhost3" database="db3"/>
<!-- The configuration of each database node is specified here -->
<dataHost name="dhost1" maxCon="1000" minCon="10" balance="0" writeType="0"
dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="localhost:3306" user="root" password="password"/>
</dataHost>
a
<dataHost name="dhost2" maxCon="1000" minCon="10" balance="0" writeType="0"
dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="localhost:3306" user="root" password="password"/>
</dataHost>
<dataHost name="dhost3" maxCon="1000" minCon="10" balance="0" writeType="0"
dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM3" url="localhost:3306" user="root" password="password"/>
</dataHost>
</mycat:schema>
rules. The XML configuration is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<!-- there mod-long Corresponding to the above schema.xml In table configuration rule Property, whose columns node
Specifies the field name corresponding to the current rule, that is id,algorithm The node specifies the algorithm used by the current rule
The algorithm corresponds to the following function The implementation class specified by the node-->
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<!-- What is specified here is mod-long The specific implementation class used by this algorithm needs to use the fully qualified path, and the specific code readers
Can read MyCat Source code, and readers can also view it MyCat Which table splitting strategies are provided for us by default -->
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- Specifies the number of database nodes currently in use -->
<property name="count">3</property>
</function>
</mycat:rule>
2) Slice by range
Slicing by range, as the name suggests, is to first divide the range of the overall data, and then assign each range interval to the corresponding database node. When the user inserts data, judge which range it belongs to according to the value of the specified field, and then insert the data into the database node corresponding to the range.
<!-- schema.xml --> <table name="t_company" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="range-sharding-by-id-count"/>
rules. The XML configuration is as follows:
<!-- rule.xml -->
<tableRule name="range-sharding-by-id-count">
<rule>
<!-- The slice field is specified -->
<columns>id</columns>
<algorithm>range-id-count</algorithm>
</rule>
</tableRule>
<function name="range-id-count" class="io.mycat.route.function.AutoPartitionByLong">
<!-- Specifies the range of the range slice-Corresponding policy of node '' -->
<property name="mapFile">files/tb-range-partition.txt</property>
<!-- Specifies the data node to which the out of range data will be assigned -->
<property name="defaultNode">0</property>
</function>
mapFile specifies the corresponding relationship between the range and the data node, as follows:
<!-- above mapFile Property id-range-partition.txt File content, which specifies the corresponding relationship between the specific range and the data node --> 0-10=0 11-50=1 51-100=2 101-1000=0 1001-9999=1 10000-9999999=2
3) Consistent Hash fragmentation
<!-- schema.xml --> <table name="t_house" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="sharding-by-hash"/>
rule. The XML file is as follows:
<!-- rule.xml -->
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>hash</algorithm>
</rule>
</tableRule>
<!-- In the following properties, count The number of database nodes to be partitioned is specified, which must be specified, otherwise it cannot be partitioned; virtualBucketTimes refer to
An actual database node is mapped to so many virtual nodes. The default is 160 times, that is, the number of virtual nodes is 160 times that of physical nodes;
weightMapFile The weight of the node is specified. The default value of the node without weight is 1. with properties Fill in the format of the document,
Start from 0 to count-1 The integer value of, that is, the node index is key,Take the node weight value as the value. The ownership value must be a positive integer,
Otherwise, replace with 1; bucketMapPath It is used to observe the distribution of physical nodes and virtual nodes during testing. If this attribute is specified,
Will put the virtual node murmur hash The mapping between value and physical node is output to this file by line. There is no default value. If it is not specified,
It won't output anything-->
<function name="hash" class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- The default is 0 -->
<property name="count">3</property>
<property name="virtualBucketTimes">160</property><!-- -->
<!-- <property name="weightMapFile">weightMapFile</property> -->
<property name="bucketMapPath">
/usr/local/mycat/bucketMap.txt</property>
</function>
1.2.3 MyCAT sub database and table test
MyCat sub database and sub table test scenarios are as follows:
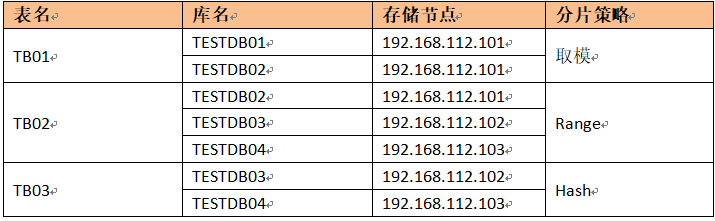
1) Create databases and tables
Create databases TESTDB01 and TESTDB02 on mysql of host 192.168.112.101, and TESTDB03 and TESTDB04 on 192.168.112.102 and 192.168.112.103 respectively. It is necessary to put table TB01 into libraries TESTDB01 and TESTDB02, table TB02 into libraries TESTDB02, TESTDB03 and TESTDB04, and table TB03 into TESTDB03 and TESTDB04.
- At 192.168.112.101 node
[mysql@tango-centos01 mysql]$ ./bin/mysql -uroot –ppassword mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 10 Server version: 5.7.31-log MySQL Community Server (GPL) Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> CREATE DATABASE TESTDB01 CHARACTER SET utf8 COLLATE utf8_general_ci; Query OK, 1 row affected (0.89 sec) mysql> use TESTDB01; Database changed mysql> create table TB01 (id int not null auto_increment,city varchar(50) not null, primary key(id)) AUTO_INCREMENT= 1 ENGINE=InnoDB DEFAULT CHARSET=utf8; Query OK, 0 rows affected (0.36 sec) mysql> CREATE DATABASE TESTDB02 CHARACTER SET utf8 COLLATE utf8_general_ci; Query OK, 1 row affected (0.00 sec) mysql> use TESTDB02; Database changed mysql> create table TB01 (id int not null auto_increment,city varchar(50) not null, primary key(id)) AUTO_INCREMENT= 1 ENGINE=InnoDB DEFAULT CHARSET=utf8; Query OK, 0 rows affected (0.22 sec) mysql> create table TB02 (id int not null auto_increment,city varchar(50) not null, primary key(id)) AUTO_INCREMENT= 1 ENGINE=InnoDB DEFAULT CHARSET=utf8; Query OK, 0 rows affected (0.01 sec)
- At 192.168.112.102 node
[mysql@tango-centos02 mysql]$ ./bin/mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 41 Server version: 5.7.31-log MySQL Community Server (GPL) Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> CREATE DATABASE TESTDB03 CHARACTER SET utf8 COLLATE utf8_general_ci; Query OK, 1 row affected (0.11 sec) mysql> use TESTDB03; Database changed mysql> create table TB02 (id int not null auto_increment,city varchar(50) not null, primary key(id)) AUTO_INCREMENT= 1 ENGINE=InnoDB DEFAULT CHARSET=utf8; Query OK, 0 rows affected (0.29 sec) mysql> create table TB03 (id int not null auto_increment,city varchar(50) not null, primary key(id)) AUTO_INCREMENT= 1 ENGINE=InnoDB DEFAULT CHARSET=utf8; Query OK, 0 rows affected (0.01 sec)
- At 192.168.112.103 node
[mysql@tango-centos03 mysql]$ ./bin/mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 47 Server version: 5.7.31-log MySQL Community Server (GPL) Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> CREATE DATABASE TESTDB04 CHARACTER SET utf8 COLLATE utf8_general_ci; Query OK, 1 row affected (0.11 sec) mysql> use TESTDB04; Database changed mysql> create table TB02 (id int not null auto_increment,city varchar(50) not null, primary key(id)) AUTO_INCREMENT= 1 ENGINE=InnoDB DEFAULT CHARSET=utf8; Query OK, 0 rows affected (0.05 sec) mysql> create table TB03 (id int not null auto_increment,city varchar(50) not null, primary key(id)) AUTO_INCREMENT= 1 ENGINE=InnoDB DEFAULT CHARSET=utf8; Query OK, 0 rows affected (0.01 sec)
Special attention should be paid to:
- A primary key must be created when creating a split table table. Otherwise, an error or primary key conflict will be reported when writing data on the mycat side
- The table of sub table should be created on several databases across databases.
2) Configure MyCAT
Log in to mycat machine 192.168.112.10 and set server XML file, rule XML file, schema XML file
- server.xml configuration
[root@tango-01 mycat]## vim conf/server.xml
......
<!-- mycat The default service port is 8066, and the default management port is 9066 -->
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
.....
<!-- Arbitrarily set login mycat User name for,password,database -->
<user name="root">
<property name="password">password</property>
<property name="schemas">mycat</property>
.....
</mycat:server>
- Configure Rules file
The configuration of sub database and sub table involves rule XML file. In this test, three fragmentation algorithms of module taking, range and consistency hash are verified respectively. The configuration is as follows:
[root@tango-01 conf]# cp rule.xml rule.xml.bak
[root@tango-01 conf]# vim rule.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="mod-rule"> <!—TB01 The rule name of the table partition, which is defined here as the module partition mod-rule,This needs to be in schema.xml Reference in file -->
<rule>
<columns>id</columns> <!—TB01 Fragment column of table -->
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="range-rule"> <!—TB02 The rule name of the table partition, which is defined here as the range partition range-rule,This needs to be in schema.xml Reference in file -->
<rule>
<columns>id</columns> <!—TB02 Fragment column of table -->
<algorithm>range-id-count</algorithm>
</rule>
</tableRule>
<tableRule name="hash-rule"> <!—TB03 The rule name of the table partition, which is defined here as the range partition range-rule,This needs to be in schema.xml Reference in file -->
<rule>
<columns>id</columns> <!—TB02 Fragment column of table -->
<algorithm>hash-murmur</algorithm>
</rule>
</tableRule>
<!—TB01 Table assigned to TESTDB01 and TESTDB02 In the library -->
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property> <!-- count The value is the same as the number of slices, here TB01 Table slicing to TESTDB01 Library and TESTDB02 Curry, 2 copies in total. -->
</function>
<!—TB02 Table assigned to TESTDB02,TESTDB03 and TESTDB04 In the library -->
<function name="range-id-count" class="io.mycat.route.function.AutoPartitionByLong">
<!-- Specifies the range of the range slice-Corresponding policy of node '' -->
<property name="mapFile">files/tb02-range-partition.txt</property>
<!-- Specifies the data node to which the out of range data will be assigned -->
<property name="defaultNode">0</property>
</function>
<!—TB03 Table assigned to TESTDB03 and TESTDB04 In the library -->
<function name="hash-murmur" class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- The default is 0 -->
<property name="count">2</property>
<property name="virtualBucketTimes">160</property><!-- -->
<property name="bucketMapPath">/usr/local/mycat/tb03-bucketMap.txt</property>
</function>
</mycat:rule>
Create the file files / tb02-range-partition txt
0-10=0 11-50=1 51-100=2 101-1000=0 1001-9999=1 10000-9999999=2
- Configure schema XML file
[root@tango-01 conf]# cp schema.xml schema.xml.old
[root@tango-01 conf]# vim schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="mycat" checkSQLschema="false" sqlMaxLimit="100">
<table name="TB01" primaryKey="id" dataNode=" DN01,DN02" rule="mod-rule" />
<table name="TB02" primaryKey="id" dataNode=" DN02,DN03,DN04" rule="range-rule" />
<table name="TB03" primaryKey="id" dataNode="DN03,DN04" rule="hash-rule" />
</schema>
<dataNode name="DN01" dataHost="DH01" database=" TESTDB01" />
<dataNode name="DN02" dataHost="DH01" database=" TESTDB02" />
<dataNode name="DN03" dataHost="DH02" database=" TESTDB03" />
<dataNode name="DN04" dataHost="DH03" database=" TESTDB04" />
<dataHost name="DH01" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="192.168.112.101" url="192.168.112.101:3306" user="root" password="password">
</writeHost>
</dataHost>
<dataHost name="DH02" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" >
<heartbeat>select user()</heartbeat>
<writeHost host="192.168.112.102" url="192.168.112.102:3306" user="root" password="password">
</writeHost>
</dataHost>
<dataHost name="DH03" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="192.168.112.103" url="192.168.112.103:3306" user="root" password="password">
</writeHost>
</dataHost>
</mycat:schema>
4) Start Mycat service
[root@tango-01 mycat]# ./bin/mycat start Starting Mycat-server... [root@tango-01 mycat]# ./bin/mycat status Mycat-server is running (9348). [root@tango-01 mycat]# lsof -i:8066 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 9350 root 81u IPv6 215883 0t0 TCP *:8066 (LISTEN) [root@tango-01 mycat]# lsof -i:9066 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 9350 root 77u IPv6 215878 0t0 TCP *:9066 (LISTEN)
5) Log in to Mycat remotely from the client
[root@tango-01 mysql]# ./bin/mysql -h192.168.112.10 -P8066 -uroot -ppassword Warning: Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.6.29-mycat-1.6.7.1-release-20200209222254 MyCat Server (OpenCloudDB) Copyright (c) 2000, 2015, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> mysql> show databases; +----------+ | DATABASE | +----------+ | mycat | +----------+ 1 row in set (0.00 sec) mysql> use mycat Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +-----------------+ | Tables in mycat | +-----------------+ | tb01 | | tb02 | | tb03 | +-----------------+ 3 rows in set (0.00 sec) mysql> select * from TB01; Empty set (0.14 sec) mysql> select * from TB02; Empty set (0.58 sec) mysql> select * from TB03; Empty set (0.04 sec)
6) Verify Mod fragmentation strategy
- Go to TB01 in mycat
mysql> insert into TB01(id,city) values(1,"Anhui"); Query OK, 1 row affected (0.06 sec) mysql> insert into TB01(id,city) values(2,"Beijing"); Query OK, 1 row affected (0.00 sec) mysql> insert into TB01(id,city) values(11,"Guangzhou"); Query OK, 1 row affected (0.00 sec) mysql> insert into TB01(id,city) values(21,"Shenzhen"); Query OK, 1 row affected (0.01 sec)
Special note: after the sharding strategy is configured (e.g. heihei hei table), when inserting data into the fragmented table in mycat, even if the data of all fields is inserted, the field name of the inserted data must be written after the table name, otherwise the inserted data will report an error: ERROR 1064 (HY000): partition table, insert must provide ColumnList
- Log in to the 192.168.112.101 server and view the data written from mycat
mysql> use TESTDB01; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +--------------------+ | Tables_in_TESTDB01 | +--------------------+ | TB01 | +--------------------+ 1 row in set (0.00 sec) mysql> select * from TB01; +----+---------+ | id | city | +----+---------+ | 2 | Beijing | +----+---------+ 1 row in set (0.03 sec) mysql> use TESTDB02; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +--------------------+ | Tables_in_TESTDB02 | +--------------------+ | TB01 | | TB02 | +--------------------+ 2 rows in set (0.00 sec) mysql> select * from TB01; +----+-----------+ | id | city | +----+-----------+ | 1 | Anhui | | 11 | Guangzhou | | 21 | Shenzhen | +----+-----------+ 3 rows in set (0.00 sec)
7) Verification range partition strategy
- Insert data into TB02 in mycat
mysql> insert into TB02(id,city) values(1,"Anhui"); Query OK, 1 row affected (0.01 sec) mysql> insert into TB02(id,city) values(2,"Beijing"); Query OK, 1 row affected (0.01 sec) mysql> insert into TB02(id,city) values(11,"Guangzhou"); Query OK, 1 row affected (0.01 sec) mysql> insert into TB02(id,city) values(21,"Shenzhen"); Query OK, 1 row affected (0.02 sec) mysql> insert into TB02(id,city) values(61,"Chengdu"); Query OK, 1 row affected (0.01 sec) mysql> insert into TB02(id,city) values(132,"Hangzhou"); Query OK, 1 row affected (0.00 sec) mysql> select * from TB02; +-----+-----------+ | id | city | +-----+-----------+ | 1 | Anhui | | 2 | Beijing | | 132 | Hangzhou | | 11 | Guangzhou | | 21 | Shenzhen | | 61 | Chengdu | +-----+-----------+ 6 rows in set (0.02 sec)
- Log in to 192.168.112.101-103 server and view the data written from mycat
mysql> use TESTDB02; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +--------------------+ | Tables_in_TESTDB02 | +--------------------+ | TB01 | | TB02 | +--------------------+ 2 rows in set (0.00 sec) mysql> select * from TB02; +-----+----------+ | id | city | +-----+----------+ | 1 | Anhui | | 2 | Beijing | | 132 | Hangzhou | +-----+----------+ 3 rows in set (0.00 sec) mysql> use TESTDB03; Database changed mysql> show tables; +--------------------+ | Tables_in_TESTDB03 | +--------------------+ | TB02 | | TB03 | +--------------------+ 2 rows in set (0.00 sec) mysql> select * from TB02; +----+-----------+ | id | city | +----+-----------+ | 11 | Guangzhou | | 21 | Shenzhen | +----+-----------+ 2 rows in set (0.00 sec) mysql> use TESTDB04; Database changed mysql> show tables; +--------------------+ | Tables_in_TESTDB04 | +--------------------+ | TB02 | | TB03 | +--------------------+ 2 rows in set (0.00 sec) mysql> select * from TB02; +----+---------+ | id | city | +----+---------+ | 61 | Chengdu | +----+---------+ 1 row in set (0.00 sec)
8) Verify Hash fragmentation strategy
- Insert data into TB03 in mycat
mysql> insert into TB03(id,city) values(1,"Anhui"); Query OK, 1 row affected (0.01 sec) mysql> insert into TB03(id,city) values(2,"Beijing"); Query OK, 1 row affected (0.01 sec) mysql> insert into TB03(id,city) values(11,"Guangzhou"); Query OK, 1 row affected (0.01 sec) mysql> insert into TB03(id,city) values(21,"Shenzhen"); Query OK, 1 row affected (0.02 sec) mysql> insert into TB03(id,city) values(61,"Chengdu"); Query OK, 1 row affected (0.01 sec) mysql> insert into TB03(id,city) values(132,"Hangzhou"); Query OK, 1 row affected (0.00 sec) mysql> select * from TB03; +-----+-----------+ | id | city | +-----+-----------+ | 1 | Anhui | | 2 | Beijing | | 132 | Hangzhou | | 11 | Guangzhou | | 21 | Shenzhen | | 61 | Chengdu | +-----+-----------+ 6 rows in set (0.02 sec)
- Log in to the 192.168.112.102-103 server and view the data written from mycat
mysql> select * from TESTDB03.TB03; +----+----------+ | id | city | +----+----------+ | 21 | Shenzhen | +----+----------+ 1 row in set (0.00 sec) mysql> select * from TESTDB04.TB03; +-----+-----------+ | id | city | +-----+-----------+ | 1 | Anhui | | 2 | Beijing | | 11 | Guangzhou | | 61 | Chengdu | | 132 | Hangzhou | +-----+-----------+ 5 rows in set (0.00 sec)
It can be seen from the above that TB01, TB02 and TB03 have successfully realized the function of sub database and sub table by using the three partition strategies of mod, range and hash in mycat.
reference material
- http://mycat.org.cn/document/mycat-definitive-guide.pdf
- https://www.cnblogs.com/kevingrace/p/9365840.html
- https://www.cnblogs.com/littlecharacter/p/9342129.html
- https://www.jianshu.com/p/c6e29d724fca
- https://my.oschina.net/ydsakyclguozi/blog/199498
- https://my.oschina.net/zhangxufeng/blog/3097533
Please indicate the original address for Reprint: https://blog.csdn.net/solihawk/article/details/117837927
The article will be synchronized in the official account of "shepherd's direction". Interested parties can official account. Thank you!
