The source code version involved in this article is Go SDK 1.16.1
1. Basic structure of map
Map is a common data structure in Golang. It is essentially a hash table, similar to HashMap in java and dict in Python. It is a data structure that stores key value pairs. A general map contains two main structures:
- Array: the values in the array point to a linked list
- Linked list: aims to solve the problem of hash conflict and store key values
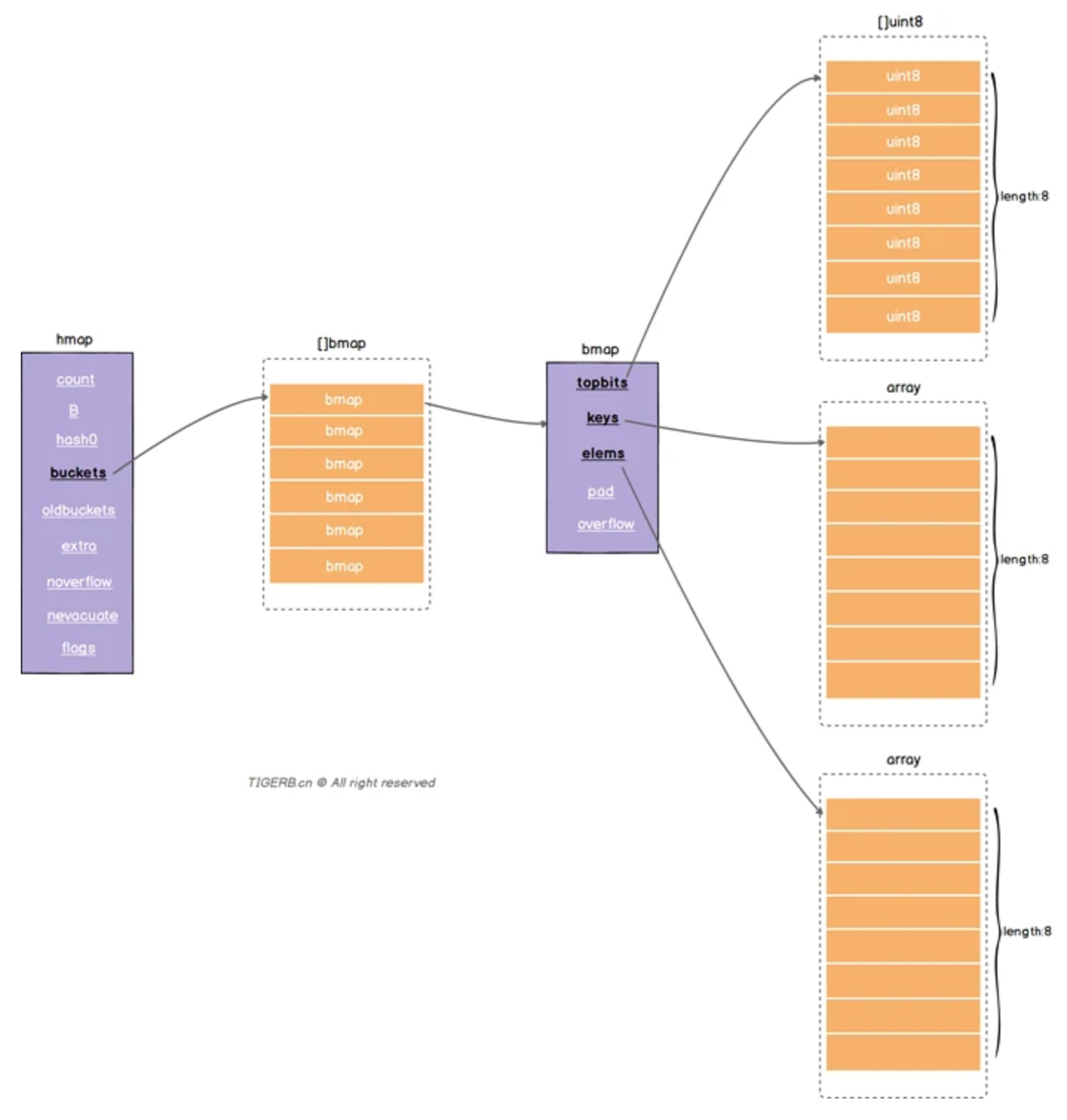
In Golang, the hash conflict is not solved by linked lists, but by arrays (i.e. continuous space in memory), and two arrays are used to store keys and values respectively, as shown in the following figure. It mentions two core structures in the map: hmap and bmap. The underlying data structure of each map is hmap, and each hamp is a bucker array composed of several bmaps. The structure of hmap is defined as follows (src/runtime/map.go):
type hmap struct {
count int //Number of elements
flags uint8
B uint8 // For capacity expansion related fields, B is the logarithm 2^B of the length of the buckets array
noverflow uint16 // The number of overflowing bucket s. A bmap can store up to 8 groups of key value pairs. When it is full, it will be stored in the bmap pointed to
hash0 uint32 // hash factor
buckets unsafe.Pointer // buckets array pointer
oldbuckets unsafe.Pointer // During capacity expansion, store the previous buckets(Map capacity expansion related fields)
nevacuate uintptr // Shunting times, the field of doubling the shunting operation count (related fields of Map capacity expansion)
extra *mapextra // Pointer for capacity expansion
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
bmap # is what we often call "bucket". There are at most 8 keys in the bucket. The reason why these keys fall into the same bucket is that after hash calculation, the hash results are the same. When the hash function is the same, the position of the key in the bucket will be determined according to the high 8 bits of the hash value calculated by the key (there are at most 8 positions in a bucket). bmap in map The code definition in go is as follows. It is worth mentioning that a new bmap structure will be dynamically created during compilation:
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8 //Array of length 8
}
//New bamp structure created at compile time
type bmap struct {
topbits [8]uint8 //An array with a length of 8, []uint8 stores the top 8 bits of the hash obtained by the key. It is used in comparison during traversal to improve performance.
keys [8]keytype //An array with a length of 8 stores the specific key value.
values [8]valuetype //An array with a length of 8 stores the specific value value
pad uintptr //Point to the hmap extra. Overflow the bmap in the overflow bucket. The fields topbits, keys and elements above are 8 in length. Up to 8 groups of key value pairs are stored. When they are full, they are stored in the bmap pointed to
overflow uintptr //For memory alignment, not every bmap has this field, which must meet certain conditions
}After understanding the basic structure of hmap and bmap, you can get the following Map structure diagram:
2. Load factor
Load factor is an indicator to measure the space utilization in the hash table. Load factor = the total number of stored key value pairs in the hash table / the number of hash buckets (i.e. the number of buckets array in the hmap structure). We know that the load factor determines the storage efficiency of the hash table: too small a load factor will lead to low space utilization; A large load factor will cause frequent collisions between the insertion and lookup of the hash table, degrade the hash table into a linked list, and trigger capacity expansion. In golang, the load factor is set to 6.5. Why is it set to 6.5 instead of other values? Golang officially gives a set of test data:
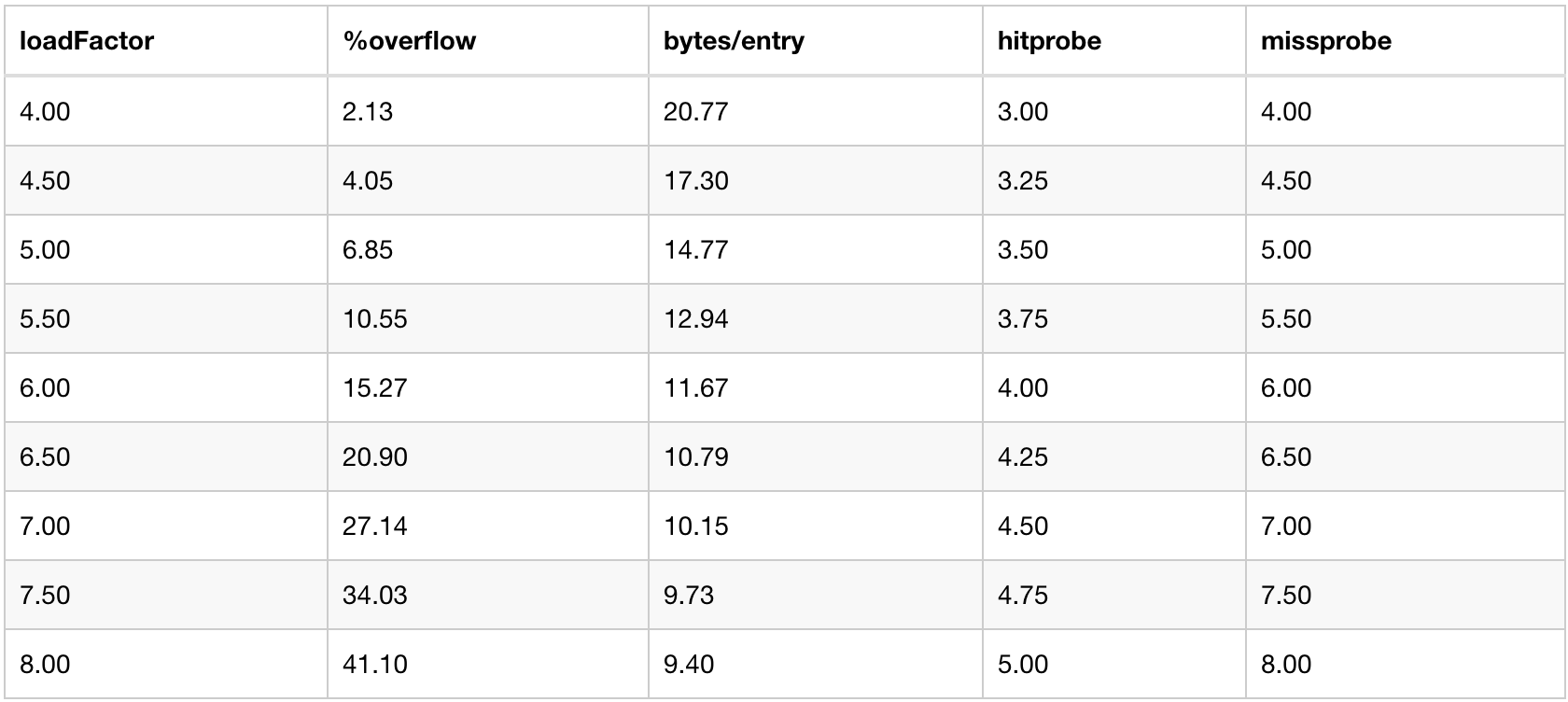
From the table, we can see that when the load factor is set to 6.5, the overflow rate (% overflow), the byte / entry ratio of each key value pair and the number of lookups achieve a certain balance. When make(map[k]v,hint) is initialized map in Golang, the number of buckets created is determined according to the number of initialized elements and load factors. The core code is as follows:
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand() //Initialize hash factor
B := uint8(0)//Find the appropriate B value
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
//B is defined according to the load factor and the number of initialization map s, and the number of buckets = 2^B
func overLoadFactor(count int, B uint8) bool {
//loadFactorNum=13, loadfactorDen=2
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
func bucketShift(b uint8) uintptr {
return uintptr(1) << (b & (sys.PtrSize*8 - 1))
}The makemap function creates a random hash seed through {fastrand}, then calculates the minimum number of buckets required according to the number of incoming initialization maps, and finally uses} makeBucketArray to create an array for storing buckets, In fact, this method allocates a continuous space in the memory for storing data according to the number of buckets to be created calculated by the incoming ^ B ^ and some additional buckets for storing overflow data will be created in the process of creating buckets, with the number of ^ (B-4). The hmap pointer is returned after initialization.
3. Capacity expansion
As more and more values are inserted in the Hash table, the probability of collision increases gradually. If the current load factor exceeds the threshold of 6.5, capacity expansion will be triggered. Is capacity expansion triggered only in this scenario? In fact, it is not. When a new key is inserted into the map, condition detection will be performed. If the following two conditions are met, capacity expansion will be triggered:
1. The load factor exceeds the threshold. The threshold defined in the source code is 6.5
2. overflow has too many bucket s
The first scenario is well understood. In the previous section, we already knew the importance of the loading factor. Why does the second scenario trigger capacity expansion? This is because the number of buckets is too large and the density of storage elements is very low due to continuous insert and delete operations, which will also reduce the insertion and search efficiency of Hash table. At this time, it is also necessary to expand the capacity to move the data from the old bucket to the new bucket, so as to improve the data storage density and query efficiency.
Functions related to capacity expansion include hashGrow() and growWork(). hashGrow() will open up a new bucket space and mount the current buckets to the old buckets. In growWrok(), the actual bucket relocation will be carried out, and the map will try to relocate buckets when inserting, modifying or deleting key s. From the code, we can see that the relocation of buckets is not completed at one time, but a gradual method of "relocation" at most two times.
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1) //Incremental capacity expansion
if !overLoadFactor(h.count+1, h.B) { //Equal capacity expansion
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets // Mount buckets to old buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)//Open up a new bucket space
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
//......
}
func growWork(t *maptype, h *hmap, bucket uintptr) {
// Moving old bucket s in use
evacuate(t, h, bucket&h.oldbucketmask())//The evaluate function is too long to expand here
// Move another bucket to speed up the relocation process
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}4. Traversal
When we use range to traverse the map, we will find that the order of each traverse is different. For example, if we traverse the map three times with the following code, the results are different.
var mapTest = map[string]int{
"a": 1, "b": 2, "c": 3, "d": 4, "e": 5, "f": 6,
}
for i := 0; i < 3; i++ {
for key := range mapTest {
fmt.Print(key + " ")
}
fmt.Println()
}
/* Traversal result
b c d e f a
a b c d e f
c d e f a b
*/This is because when we traverse the map, we do not start from bucket 0. Each time we traverse from a bucket with a random number, and we traverse from a cell with a random number of the bucket. mapiterinit is a function to select the initial bucket during traversal. The source code is as follows.
func mapiterinit(t *maptype, h *hmap, it *hiter) {
//......
it.t = t
it.h = h
it.B = h.B
it.buckets = h.buckets
if t.bucket.ptrdata == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
it.bucket = it.startBucket
if old := h.flags; old&(iterator|oldIterator) != iterator|oldIterator {
atomic.Or8(&h.flags, iterator|oldIterator)
}
mapiternext(it)
}The code generates random numbers by calling fastrand() to determine the starting position of traversal, resulting in different results for each traversal. If you want to get the same result every time you traverse, you can copy the key in the map to the array first, and then traverse the array.
5. Concurrency and sync map
Map is not thread safe. If concurrent reads and writes occur in the map, it will lead to panic. We can know this from the map initialization function mapassign. In order to solve the problem of concurrent use of map, Golang gives different solutions in different versions.
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
//Determine whether the hmap has been initialized (whether it is nil)
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
//...
//Judge whether to read and write map concurrently. If so, throw an exception
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
//Call different hash methods to calculate the hash value according to different types of key s
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
//Set the flags flag bit to indicate that a goroutine is writing data. Because alg panic may occur in hash, resulting in an exception
h.flags |= hashWriting
//Judge whether buckets are nil. If so, call newobject to allocate according to the current bucket size
//If there are no initial buckets during initialization, it will allocate buckets during the first assignment
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
}In golang1 Before September 9, Go officials gave a simple solution at that time, that is, locking. Set a struct, embed a read-write lock and a map, and ensure data security by locking in the read-write scenario.
var counter = struct{
sync.RWMutex
m map[string]int
}{m: make(map[string]int)}Go1. After 9, a Map supporting concurrent security was added sync.Map , sync.Map realizes a certain degree of read-write separation by using only atomic operation data and locking data with redundant read-only data, so that most read operations and update operations are atomic operations, and locking is only used to write new data to improve performance. Let's first look at the underlying data structure:
// Encapsulated thread safe map
type Map struct {
// lock
mu Mutex
// Actually, it is the readOnly structure
// A read-only data structure. Because it is read-only, there will be no read-write conflict.
// readOnly contains part of the map data for concurrent secure access. (redundancy, memory for performance)
// No lock is required to access this part.
read atomic.Value // readOnly
// The dirty data contains the entries contained in the current map. It contains the latest entries (including the data not deleted in read. Although there is redundancy, it is very fast to promote the dirty field to read. Instead of copying one by one, this data structure is directly used as a part of the read field). Some data may not be moved to the read field.
// The operation of dirty needs to be locked because there may be read-write competition for its operation.
// When dirty is empty, such as initialization or just promotion, the next write operation will copy the undeleted data in the read field to this data.
dirty map[interface{}]*entry
// When reading an entry from the Map, if the entry is not included in the read, it will try to read it from dirty. At this time, it will add one miss,
// When misses accumulate to the length of dirty, dirty will be promoted to read to avoid missing too many times from dirty. Because the operation dirty needs to be locked.
misses int
}
// readOnly is an immutable struct stored atomically in the Map.read field.
type readOnly struct {
m map[interface{}]*entry
// If map Some data of dirty is not in m, and this value is true
amended bool
}
// An entry is a slot in the map corresponding to a particular key.
type entry struct {
// *interface{}
p unsafe.Pointer
}
(1) Read write separation
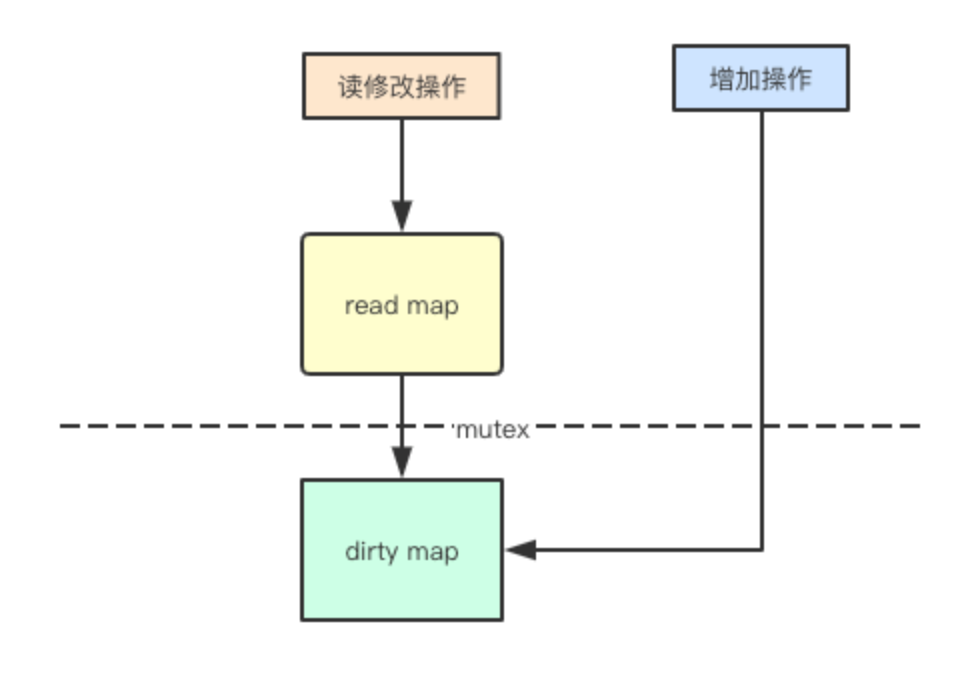
The main problem with concurrent access to map reading is that during capacity expansion, elements may be hash ed to other addresses. If my read map will not be expanded, concurrent and safe access can be carried out, and sync Map uses this method to save the added elements through dirty. By separating the read-only operation from the dirty write map operation, you only need to read the read map through atomic instructions without locking, so as to improve the read performance.
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// There is no data in the read-only data, and dirty has more data than read. Lock it in dirty
if !ok && read.amended {
m.mu.Lock()
// Double check because the statement before locking is non atomic
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
// Number of times not read in read-only + 1
e, ok = m.dirty[key]
// Check whether the condition for triggering dirty upgrade read is met
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
// atomic.Load but marked for deletion will return nil
return e.load()
}
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}(2) Write locking and delay lifting
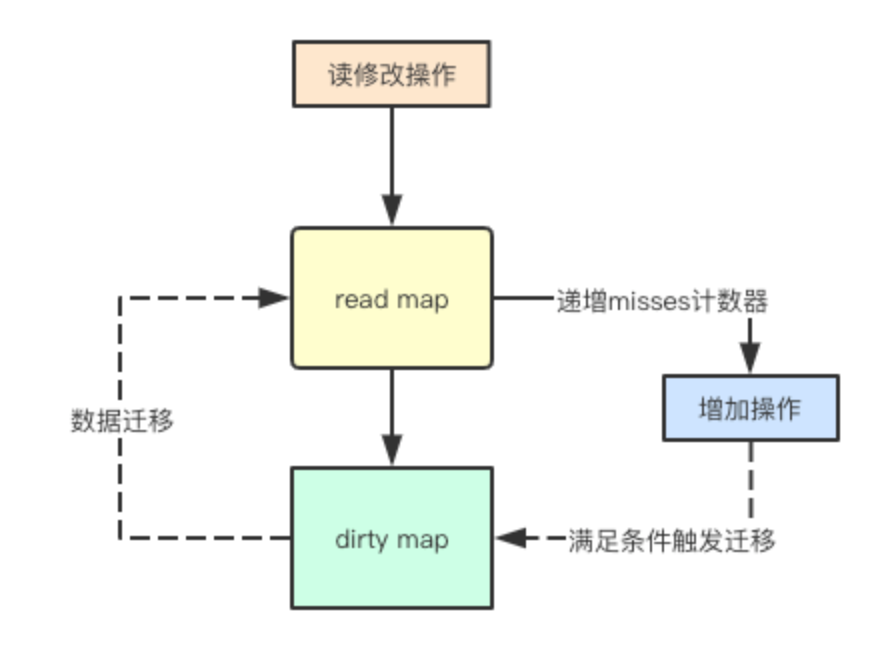
As mentioned above, the operation of adding elements may be added to the dirty write map first. If multiple goroutine s are written at the same time, mutex locking is actually required. If read read-only map and dirty write map, there will be a problem. By default, the added elements are placed in dirty. If the subsequent access to new elements is locked through mutex, the read-only map will lose its meaning, sync The strategy of always delaying promotion is adopted in the map to promote all elements in the current map to the read-only map in batches, so as to provide lock free support for subsequent read access.
func (m *Map) Store(key, value interface{}) {
// Instead of locking, press key to read from the read-only data. If it already exists, it will be overwritten (Updated) by compareAndSwap operation
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
m.mu.Lock()
// Double check get read
read, _ = m.read.Load().(readOnly)
// If the data is in read, update the entry
if e, ok := read.m[key]; ok {
// If the data read by the atomic operation is marked for deletion, it is regarded as new data written to dirty
if e.unexpungeLocked() {
m.dirty[key] = e
}
// Atomic operation writes new data
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok {
// Atomic operation writes new data
e.storeLocked(&value)
} else {
// New data
// When there is no new data in dirty, the data in read is redundant to dirty
if !read.amended {
m.dirtyLocked()
m.read.Store(readOnly{m: read.m, amended: true})
}
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}
func (e *entry) tryStore(i *interface{}) bool {
p := atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
for {
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
return true
}
p = atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
}
}
// Redundancy is triggered when there is no more new data in dirty than read
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
// Check whether the entry is deleted. The deleted data is not redundant
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := atomic.LoadPointer(&e.p)
for p == nil {
// Mark the deleted (nil) data as expunged with cas atomic operation (prevent incorrect redundant data into dirty due to other operations under concurrent conditions)
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
return true
}
p = atomic.LoadPointer(&e.p)
}
return p == expunged
}(3) Inert deletion
Lazy deletion is a common design in concurrent design. For example, to delete a linked list element, you need to modify the pointers of the front and rear elements. For lazy deletion, you usually only need to set a flag bit to delete, and then operate in subsequent modifications, sync This method is also adopted in map, and inert deletion is realized by pointing the pointer to a pointer identifying deletion.
func (m *Map) Delete(key interface{}) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// Read only does not exist. It needs to be deleted in dirty
if !ok && read.amended {
m.mu.Lock()
// Double check because the statement before locking is non atomic
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
delete(m.dirty, key)
}
m.mu.Unlock()
}
if ok {
e.delete()
}
}
func (e *entry) delete() (hadValue bool) {
for {
p := atomic.LoadPointer(&e.p)
if p == nil || p == expunged {
return false
}
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
return true
}
}
}