catalogue
2.1 creating labelme environment
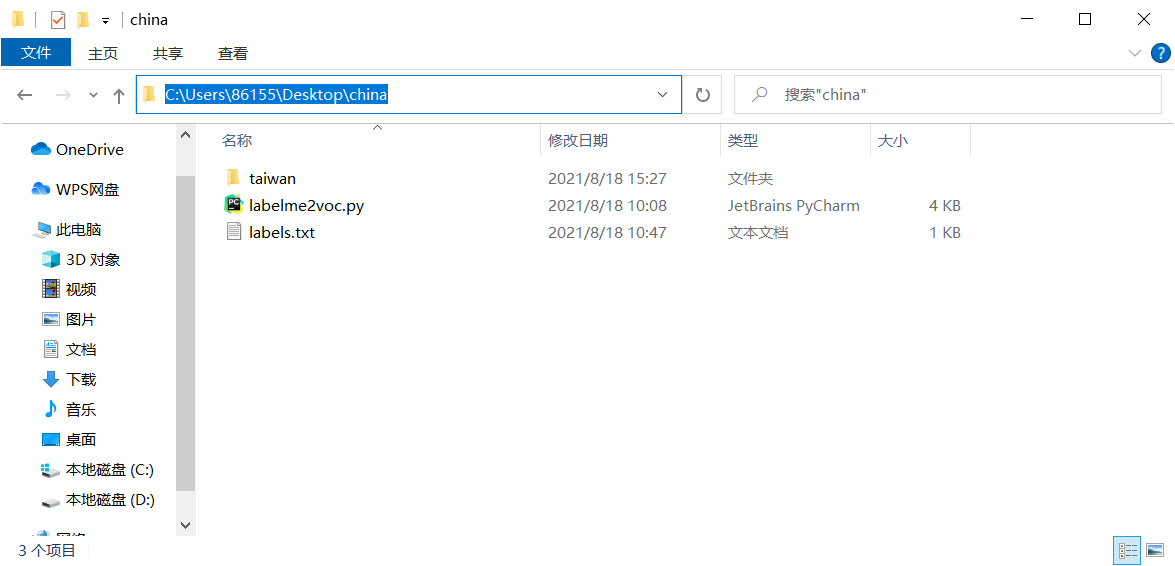
1. Save the file in the taiwan folder under the china folder.
2. Create a labelme2voc Py, copy the following code.
4. Activate labelme environment
5. Switch to the storage path of your pictures:
6. Open labelme, and open the taiwan folder to mark:
7. Incoming json file path, perform conversion
8. The marked documents are in the guizhou folder
1. Find JSON in the labelme installation directory_ to_ dataset. Py file
2. Modify json_to_dataset.py file
3. Use the method in step 1 to find labelme_json_to_dataset.exe file
4. Open anaconda prompt and enter the following command
4.1. If there is a virtual environment, enter (activate) the virtual environment:
4.2 switch the path to the directory address in step 3
4.3 incoming json file path, perform conversion
4.4 the marked files are in the D:\ProgramData\Anaconda3\envs\labelm\Scripts folder
preparation:
1. Install anaconda
First go to Tsinghua mirror website to download anaconda and install it under the program directory on disk d.
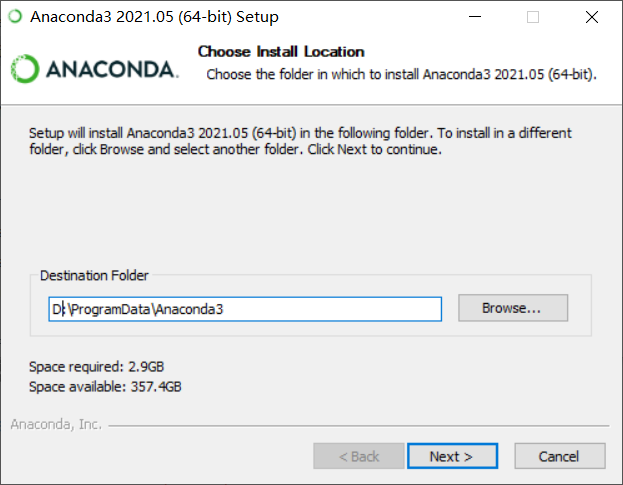
Then you must check add environment variables, or you must add them manually after installation.
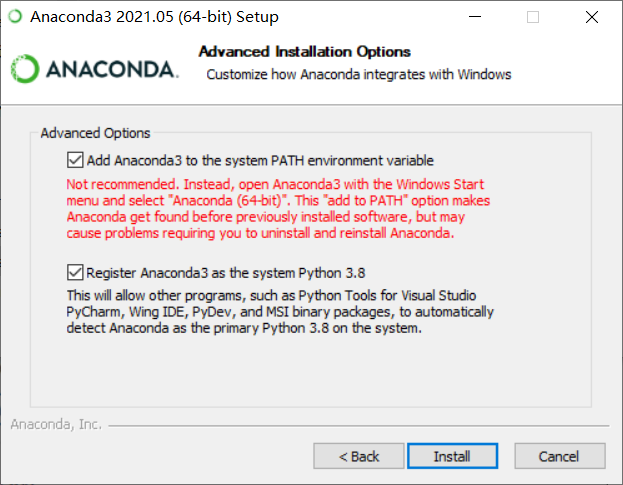
2. Installing labelme
2.1 creating labelme environment
Open anaconda powershell prompt, enter python -V to view the python version. You can see from the figure below that my Python is version 3.8.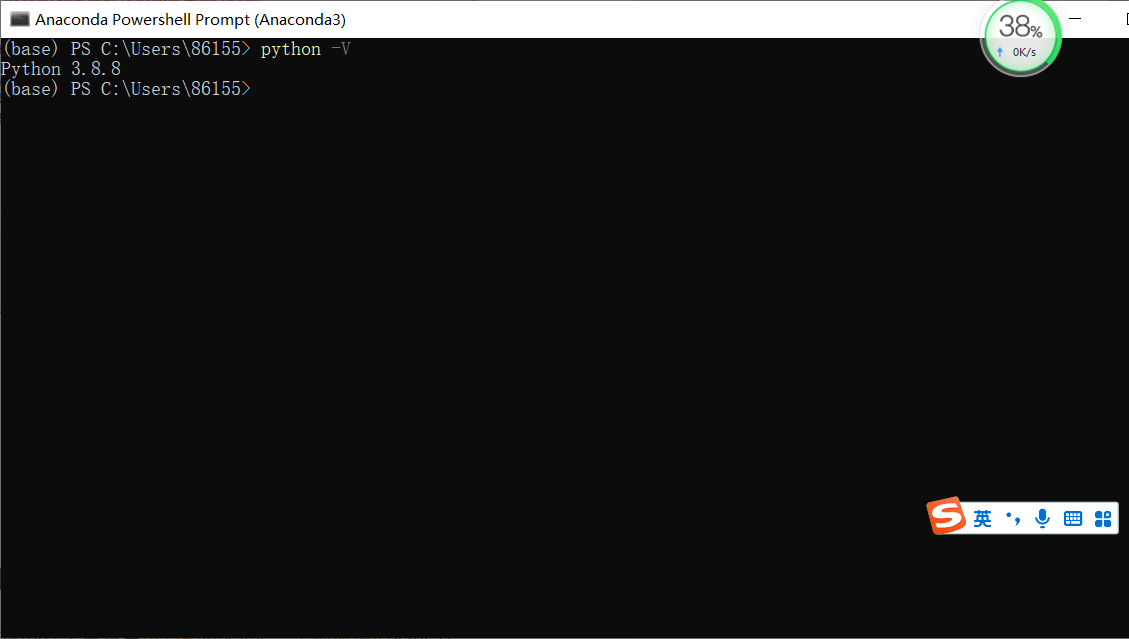
Then enter the command: conda create --name=labelme python=3.8
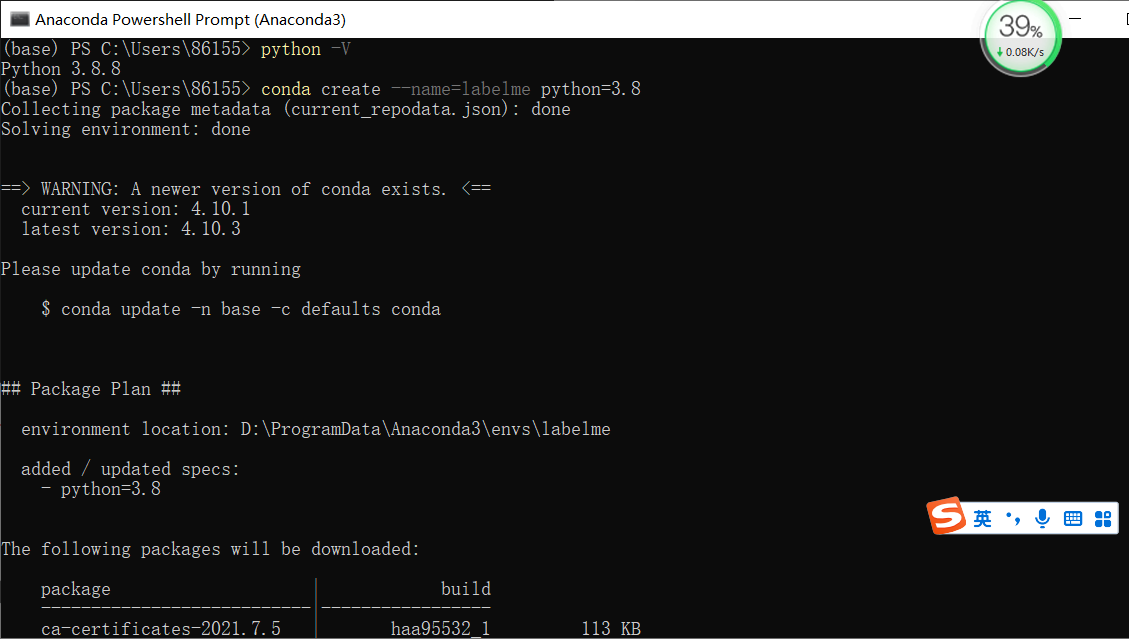
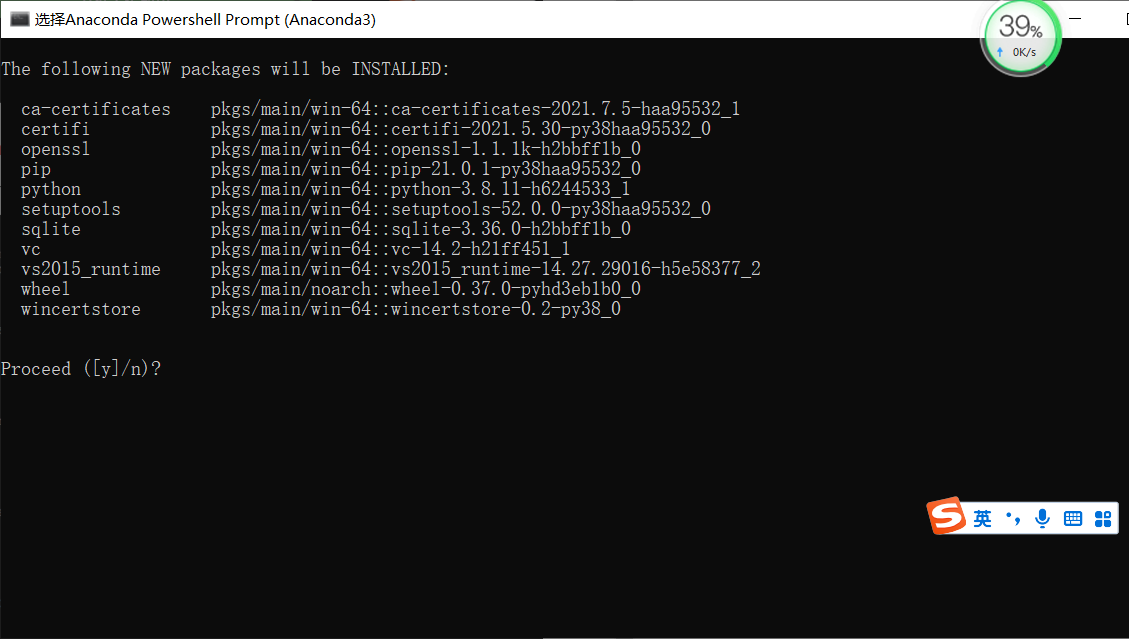
After entering y #, you will download it yourself.
Method 1:
1. Save the file in the taiwan folder under the china folder.
2. Create a labelme2voc Py, copy the following code.
#!/usr/bin/env python
from __future__ import print_function
import argparse
import glob
import os
import os.path as osp
import sys
import imgviz
import numpy as np
import labelme
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("input_dir", help="input annotated directory")
parser.add_argument("output_dir", help="output dataset directory")
parser.add_argument("--labels", help="labels file", required=True)
parser.add_argument(
"--noviz", help="no visualization", action="store_true"
)
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
os.makedirs(osp.join(args.output_dir, "SegmentationClass"))
os.makedirs(osp.join(args.output_dir, "SegmentationClassPNG"))
if not args.noviz:
os.makedirs(
osp.join(args.output_dir, "SegmentationClassVisualization")
)
print("Creating dataset:", args.output_dir)
class_names = []
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == "__ignore__"
continue
elif class_id == 0:
assert class_name == "_background_"
class_names.append(class_name)
class_names = tuple(class_names)
print("class_names:", class_names)
out_class_names_file = osp.join(args.output_dir, "class_names.txt")
with open(out_class_names_file, "w") as f:
f.writelines("\n".join(class_names))
print("Saved class_names:", out_class_names_file)
for filename in glob.glob(osp.join(args.input_dir, "*.json")):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
out_lbl_file = osp.join(
args.output_dir, "SegmentationClass", base + ".npy"
)
out_png_file = osp.join(
args.output_dir, "SegmentationClassPNG", base + ".png"
)
if not args.noviz:
out_viz_file = osp.join(
args.output_dir,
"SegmentationClassVisualization",
base + ".jpg",
)
with open(out_img_file, "wb") as f:
f.write(label_file.imageData)
img = labelme.utils.img_data_to_arr(label_file.imageData)
lbl, _ = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=label_file.shapes,
label_name_to_value=class_name_to_id,
)
labelme.utils.lblsave(out_png_file, lbl)
np.save(out_lbl_file, lbl)
if not args.noviz:
viz = imgviz.label2rgb(
label=lbl,
img=imgviz.rgb2gray(img),
font_size=15,
label_names=class_names,
loc="rb",
)
imgviz.io.imsave(out_viz_file, viz)
if __name__ == "__main__":
main()3. Create a new label Txt file, fill in the label you want to mark. If you don't know how to complete it, copy the following code.
__ignore__ _background_ aeroplane bicycle bird boat bottle bus car cat chair cow diningtable dog horse motorbike person potted plant sheep sofa train foot eyes head tv/monitor
Then the file structure becomes like this:
4. Activate labelme environment
Input instruction: conda activate labelme, the first (base) becomes (labelme)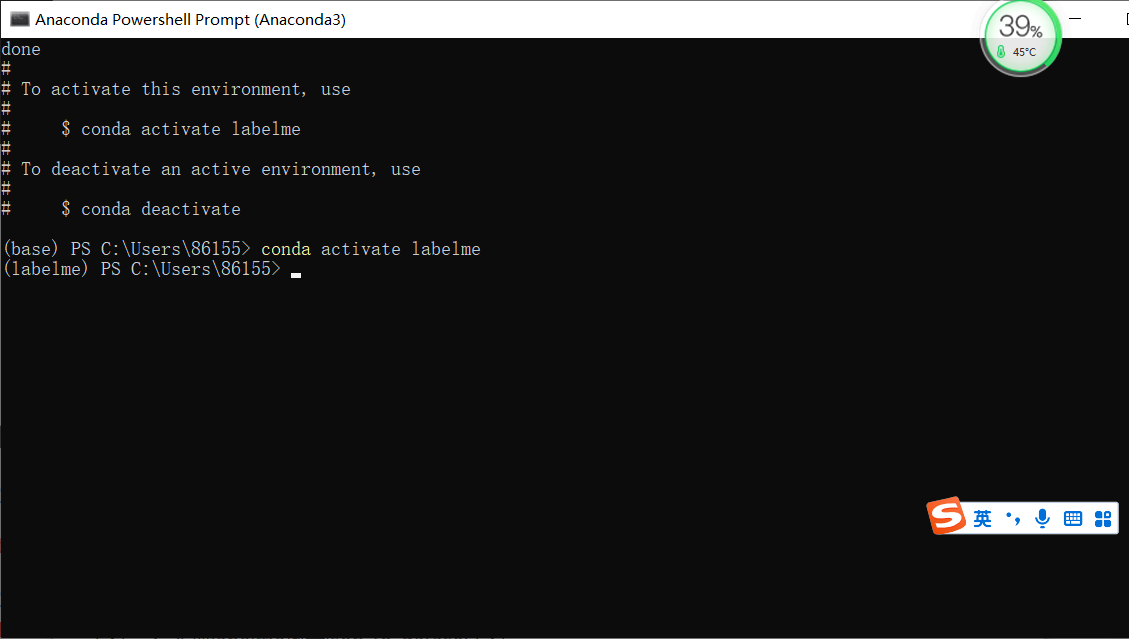
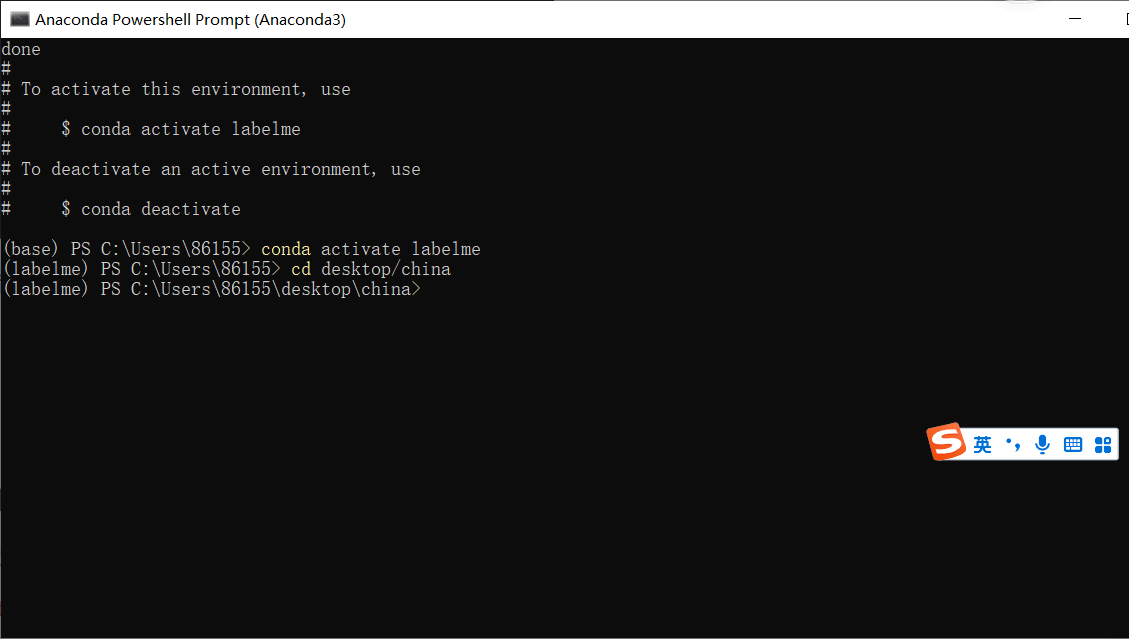
5. Switch to the storage path of your pictures:
cd desktop/china
6. Open labelme, and open the taiwan folder to mark:
labelme taiwan --labels labels.txt --nodata --validatelabel exact --config '{shift_auto_shape_color: -2}'
7. Incoming json file path, perform conversion
./labelme2voc.py taiwan guizhou --labels labels.txt
Among them, taiwan is the folder for pictures, guizhou is the folder for labels, and there are spaces after config and before - 2
8. The marked documents are in the guizhou folder
Method 2:
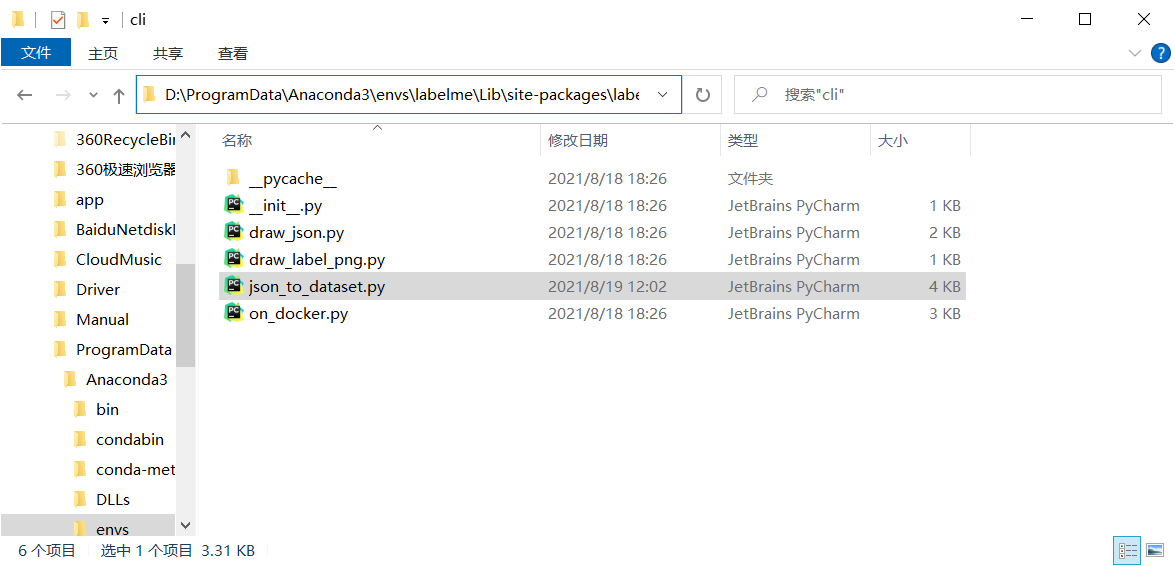
1. Find JSON in the labelme installation directory_ to_ dataset. Py file
Case 1: anaconda's installation environment is the default installation directory and labelme is not provided with a virtual environment:
C:\ProgramData\Anaconda3\Lib\site-packages\labelme\cli
Case 2: Anaconda's installation environment is the default installation directory, but a virtual environment is created for labelme: C: \ programdata \ anaconda3 \ envs \ labelme \ lib \ site packages \ labelme \ cli
Case 3: anaconda's installation environment is not the default installation directory and labelme is not provided with a virtual environment:
Where you installed anocanda \ anaconda3 \ lib \ site packages \ labelme \ cli
Scenario 4: anaconda's installation environment is not the default installation directory, but a virtual environment is created for labelme:
You need to find the virtual environment file in the envs folder under the ananonda installation directory. My name is:
D:\ProgramData\Anaconda3\envs\labelme\Lib\site-packages\labelme\cli
2. Modify json_to_dataset.py file
Set JSON_ to_ dataset. Replace the code in the PY file with the following code
import argparse
import json
import os
import os.path as osp
import warnings
import PIL.Image
import yaml
from labelme import utils
import base64
def main():
warnings.warn("This script is aimed to demonstrate how to convert the\n"
"JSON file to a single image dataset, and not to handle\n"
"multiple JSON files to generate a real-use dataset.")
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
if args.out is None:
out_dir = osp.basename(json_file).replace('.', '_')
out_dir = osp.join(osp.dirname(json_file), out_dir)
else:
out_dir = args.out
if not osp.exists(out_dir):
os.mkdir(out_dir)
count = os.listdir(json_file)
for i in range(0, len(count)):
path = os.path.join(json_file, count[i])
if os.path.isfile(path):
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions = ['{}: {}'.format(lv, ln)
for ln, lv in label_name_to_value.items()]
lbl_viz = utils.draw_label(lbl, img, captions)
out_dir = osp.basename(count[i]).replace('.', '_')
out_dir = osp.join(osp.dirname(count[i]), out_dir)
if not osp.exists(out_dir):
os.mkdir(out_dir)
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
#PIL.Image.fromarray(lbl).save(osp.join(out_dir, 'label.png'))
utils.lblsave(osp.join(out_dir, 'label.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
main()
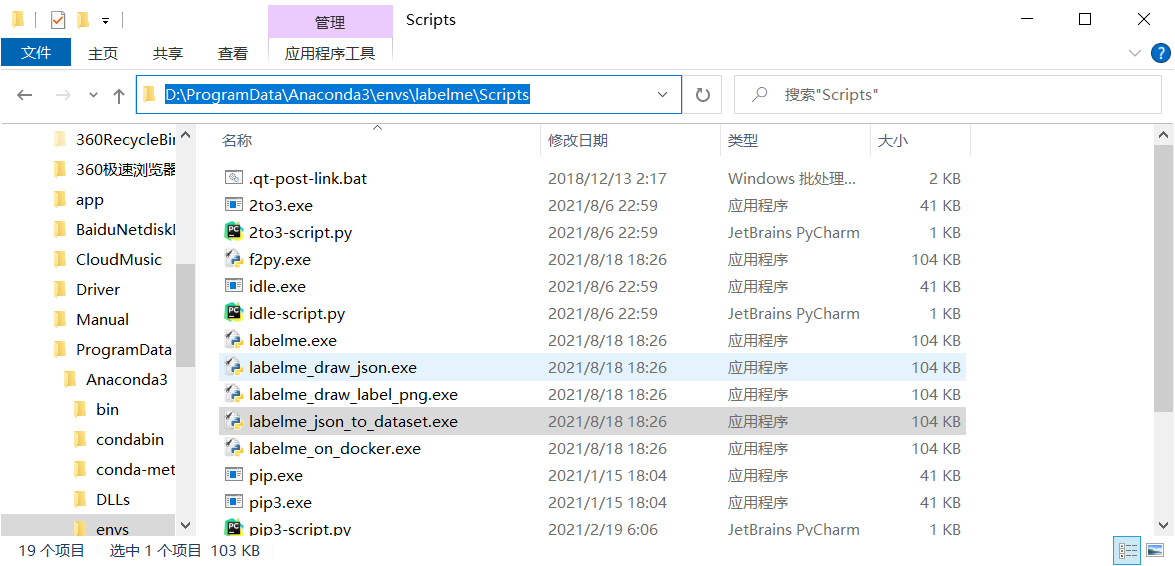
3. Use the method in step 1 to find labelme_json_to_dataset.exe file
Case 1: anaconda's installation environment is the default installation directory and labelme is not provided with a virtual environment:
C:\ProgramData\Anaconda3\labelme\Scripts
Case 2: Anaconda's installation environment is the default installation directory, but a virtual environment is created for labelme: C:\ProgramData\Anaconda3\envs\labelme\Scripts
Case 3: anaconda's installation environment is not the default installation directory and labelme is not provided with a virtual environment:
Where you installed anocanda \ Anaconda3\labelme\Scripts, open anaconda prompt to activate the virtual environment
Scenario 4: anaconda's installation environment is not the default installation directory, but a virtual environment is created for labelme:
You need to find the virtual environment file in the envs folder under the ananonda installation directory. My name is:
D:\ProgramData\Anaconda3\envs\labelm\Scripts
4. Open anaconda prompt and enter the following command
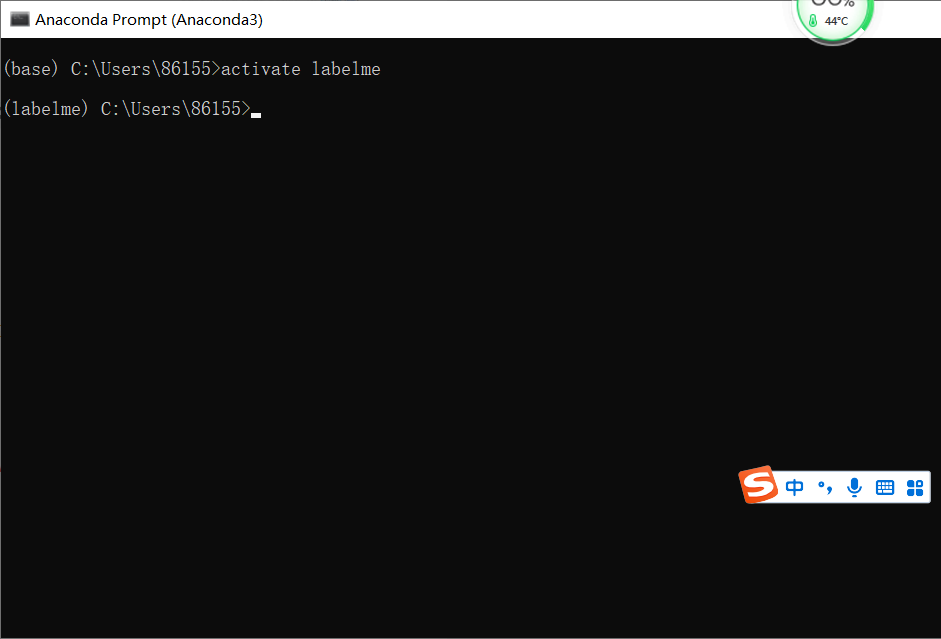
4.1. If there is a virtual environment, enter (activate) the virtual environment:
Enter command:
activate labelme
4.2 switch the path to the directory address in step 3
4.2. 1. Because my anaconda is installed on disk D, you must first switch the path from disk C to disk D (if your anaconda is installed on Disk C, this step is not required):
Enter command:
d:
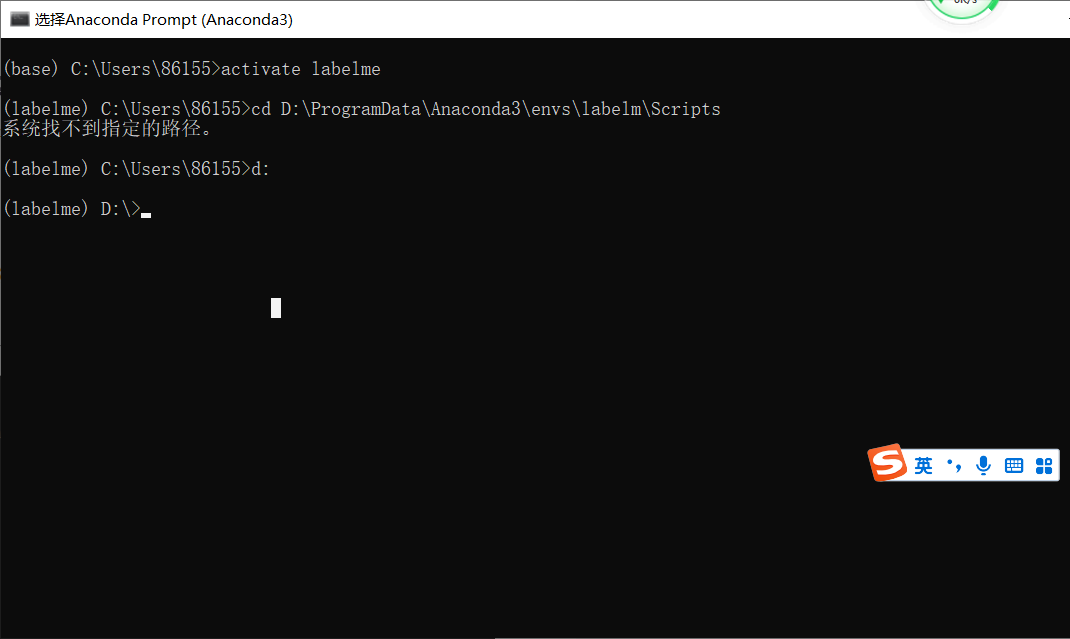
Note: if your anaconda is not installed on Disk c, you execute 4.2 1, but directly execute 4.2 3, you will get the following error:
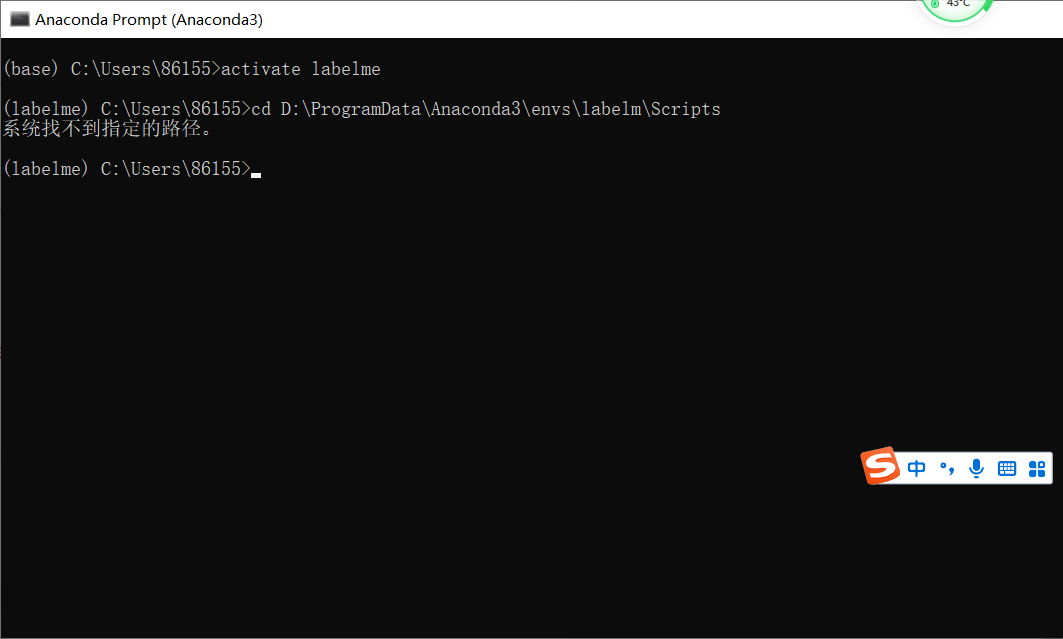
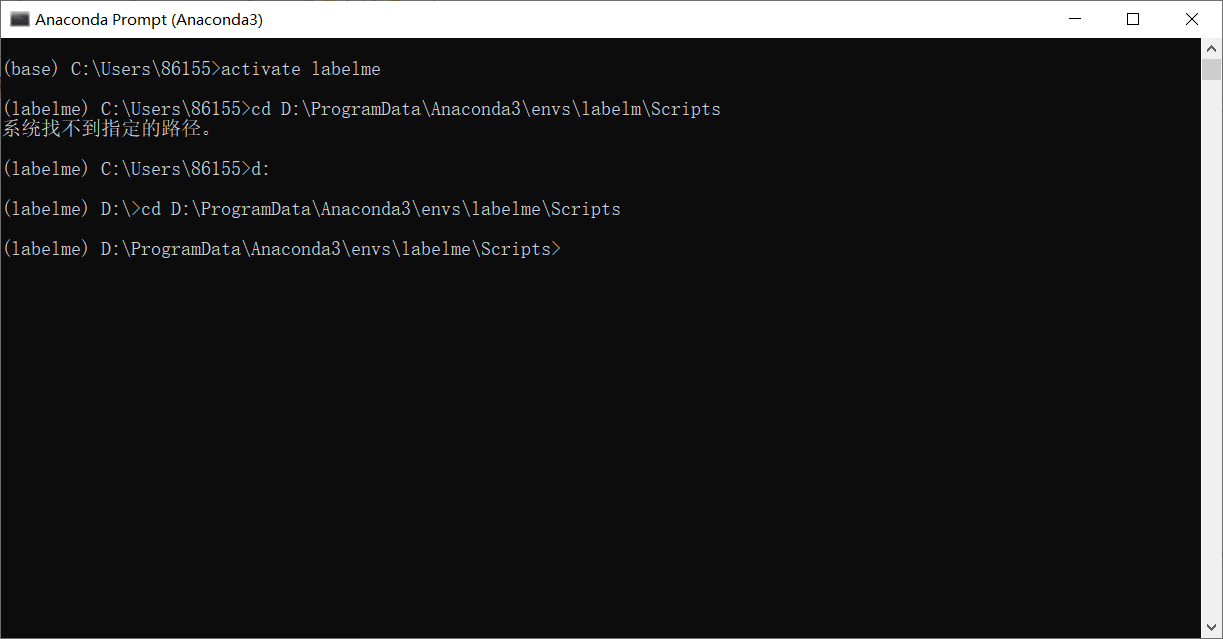
4.2. 2 my path to step 3 is D:\ProgramData\Anaconda3\envs\labelm\Scripts
So my order is:
cd D:\ProgramData\Anaconda3\envs\labelm\Scripts
Note: if you copy directly here, an error will be reported. You must type the cd yourself, and then copy the path in
4.3 incoming json file path, perform conversion
Note: here The json file must save all the json files to be converted in a directory with only json files. It can't be wrong like the following figure.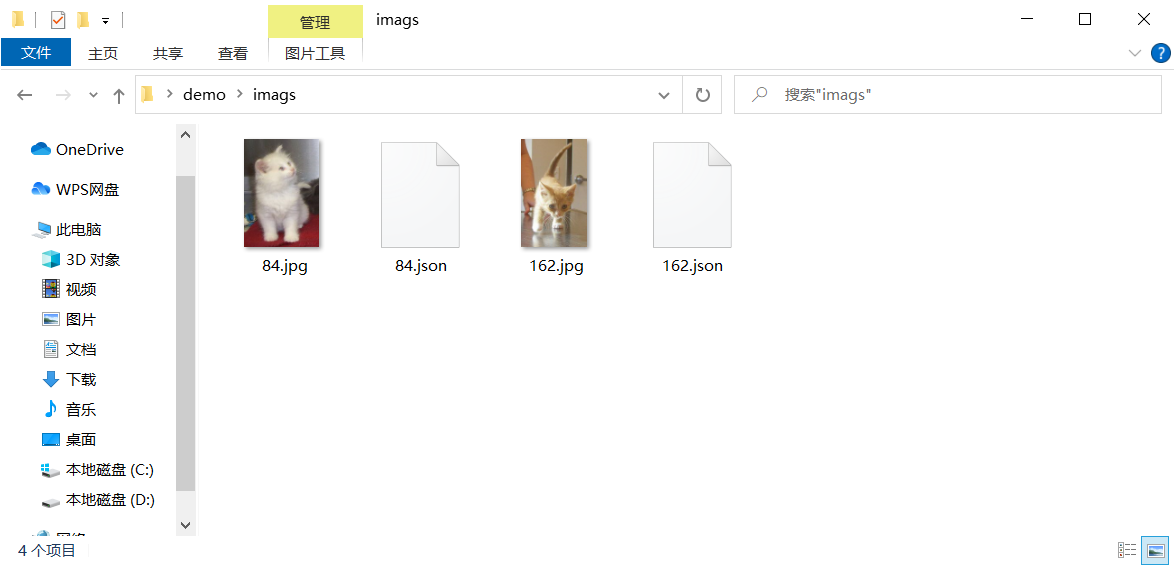
The following figure can be used: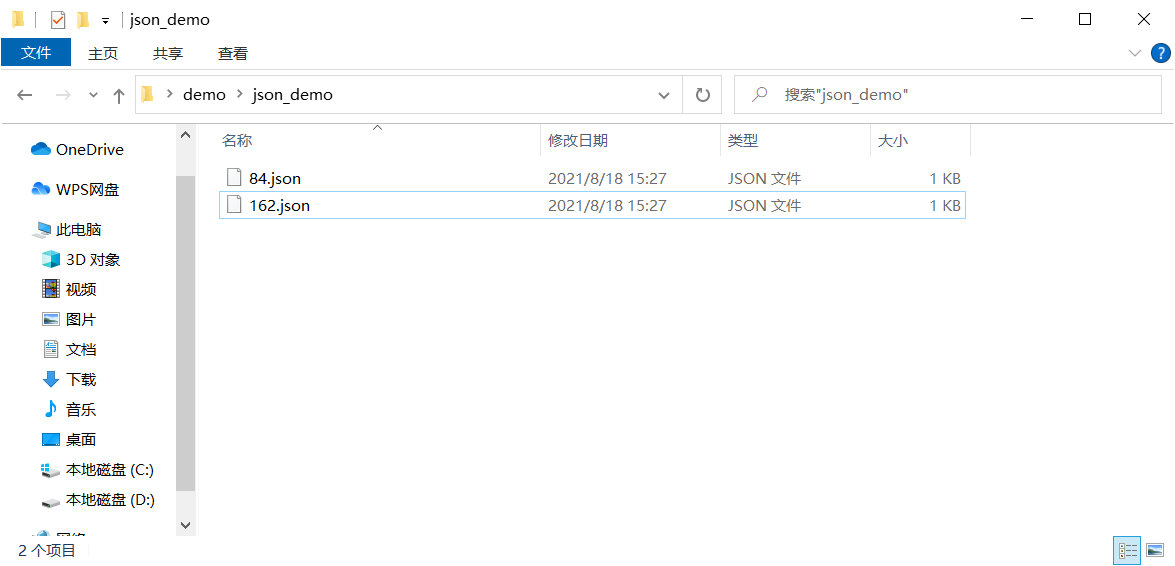
Then enter the command:
labelme_json_to_dataset.exe + the directory where you put the JSON file
My is:
labelme_json_to_dataset.exe D:\demo\json