Let's implement a complex case.
Find out the best friends between two.
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
/* The map function in the first stage mainly accomplishes the following tasks 1. Traverse the original file for each line of <All Friends> information 2. Traversing the set of "friends" with each "friend" as the key, the original value of "people" is output < friends, people > */ /* The reduce function in the first stage accomplishes the following tasks 1. Stitching all the < friends, list (people)> that came from us, and outputting < friends, everyone who owns this friend > */ /* The map function in the second stage mainly accomplishes the following tasks 1. Sort the "everyone who owns this friend" in the information of "Friends, Owners of this friend" from the previous stage of reduce output in order to prevent duplication such as B-C-B. 2. Match "everyone who owns this friend" in pairs, and use the paired string as the key, and "friend" as the value output, i.e. < person-person, common friend > */ /* The reduce function in the second stage mainly accomplishes the following tasks 1. The "common friends" in "People-People, List (Common Friends)" are spliced together and the final output is "People-People, All Common Friends of Two People". */
Phase I Procedure
Mapper end
package hadoop.MapReduce.friend;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FriendMapper1 extends Mapper<LongWritable,Text,Text,Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] people_friend = value.toString().split(":");
String people = people_friend[0];
String[] friends = people_friend[1].split(",");
for (String friend:friends){
context.write(new Text(friend),new Text(people));
}
}
}
Reduce end
package hadoop.MapReduce.friend;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FriendReducer1 extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String sum = new String();
for (Text value:values){
sum += value.toString() + ",";
}
String s = sum.substring(0,sum.length()-1);
context.write(key,new Text(s));
}
}
Driver end
package hadoop.MapReduce.friend;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FriendDriver1 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(FriendDriver1.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(FriendMapper1.class);
job.setReducerClass(FriendReducer1.class);
FileInputFormat.addInputPath(job,new Path("D:\\a\\friend.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\a\\b6"));
job.waitForCompletion(true);
}
}
Phase II Procedures
Mapper end
package hadoop.MapReduce.friend;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Arrays;
public class FriendMapper2 extends Mapper<LongWritable,Text,Text,Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] people_friend = value.toString().split("\t");
String people = people_friend[0];
String[] friends = people_friend[1].split(",");
Arrays.sort(friends);
for (int i = 0;i < friends.length-1;i++) {
for (int j = i + 1; j < friends.length; j++) {
context.write(new Text(friends[i]+"-"+friends[j]+":"), new Text(people));
}
}
}
}
Reduce end
package hadoop.MapReduce.friend;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
public class FriendReducer2 extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String sum = new String();
Set<String> set = new HashSet<String>();
for (Text value:values){
if (!set.contains(value.toString()))
set.add(value.toString());
}
for (String value:set){
sum += value.toString()+",";
}
String s = sum.substring(0,sum.length()-1);
context.write(key,new Text(s));
}
}
Driver
package hadoop.MapReduce.friend;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FriendDriver2 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(FriendDriver2.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(FriendMapper2.class);
job.setReducerClass(FriendReducer2.class);
FileInputFormat.addInputPath(job,new Path("D:\\a\\b6\\part-r-00000"));
FileOutputFormat.setOutputPath(job,new Path("D:\\a\\b7"));
job.waitForCompletion(true);
}
}
Achieving results
Phase I
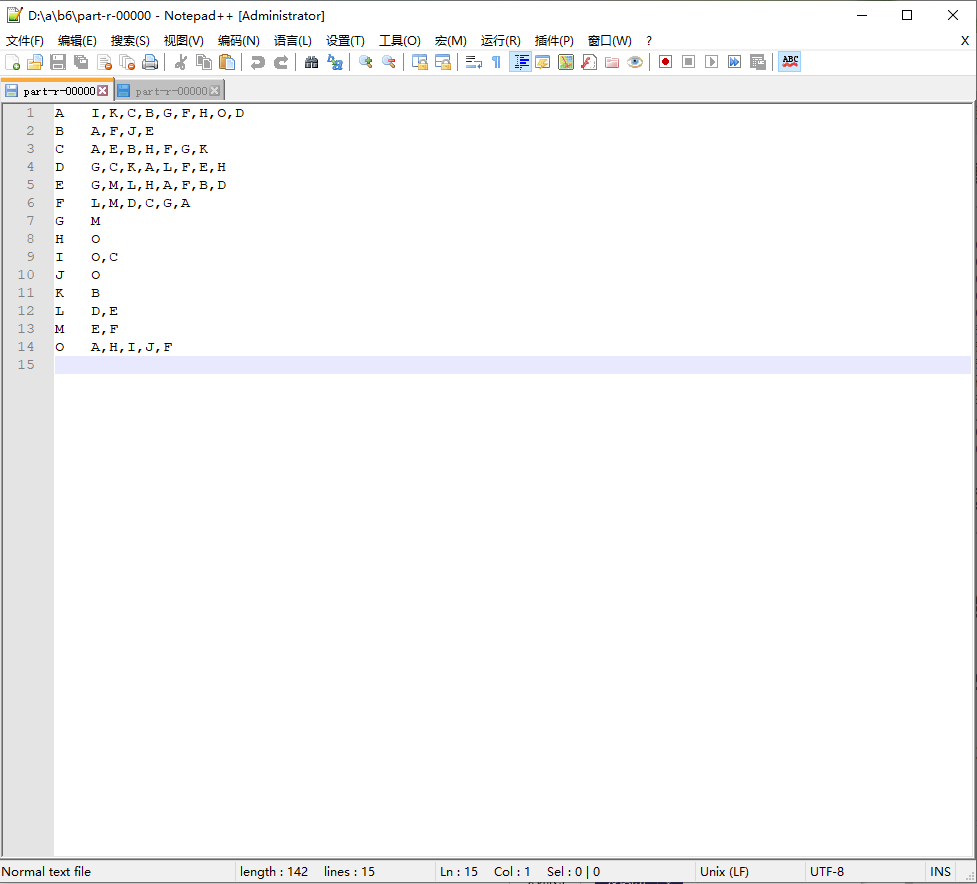
Phase II
