Original author: https://zhuanlan.zhihu.com/p/364044293
From 0 to server development -- TinyWebServer
preface:
Project code for modification, complete annotation and addition of functions:
https://github.com/white0dew/WebServer
What is it—— C + + lightweight Web server under Linux helps beginners quickly practice network programming and build their own server.
- Use the concurrency model of thread pool + non blocking socket + epoll (both ET and LT) + event processing (both Reactor and simulated Proactor)
- Use the state machine to parse the HTTP request message, and support the parsing of GET and POST requests
- Access the server database to realize the functions of web user registration and login, and can request server pictures and video files
- Implement synchronous / asynchronous logging system to record the running status of the server
- Through Webbench stress test, tens of thousands of concurrent connection data exchange can be realized
Original code of the project: https://github.com/qinguoyi/TinyWebServer
Invincible! This article is my notes while studying this project.
- Basic knowledge
To start this project, you need to have a certain understanding of Linux programming and network programming. Unix network programming and Linux high performance server programming are recommended.
What is web sever?
Web server generally refers to website server, which refers to the program of some type of computer residing on the Internet. It can process the request of web client such as browser and return the corresponding response - it can place website files for browsing all over the world; Data files can be placed for download all over the world. At present, the three most popular web servers are Apache, Nginx and IIS. The relationship between server and client is as follows:
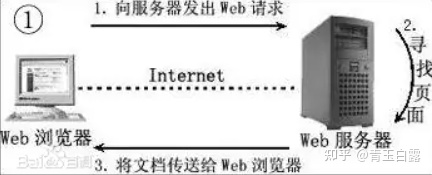
In this project, web request mainly refers to HTTP protocol. For knowledge about HTTP protocol, please refer to introduce HTTP is based on TCP/IP. For more information, please Baidu.
What is socket?
How does the client communicate with the host—— Socket
Socket originated from Unix, and one of the basic philosophies of Unix/Linux is "everything is a file", which can be operated in the mode of "open – > read write/read – > close". Socket is an implementation of this mode. Socket is a special file. Some socket functions are operations (read / write IO, open and close). Let's use the following example of the client obtaining the time of the server to understand the use process of socket:
Server side code
// Common header file of unix network programming
#include "unp.h"
#include <time.h>
int main(int argc, char **argv)
{
int listenfd, connfd;
struct sockaddr_in servaddr;
char buff[MAXLINE];
time_t ticks;
// Create socket file descriptor
listenfd = Socket(AF_INET, SOCK_STREAM, 0);
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
// Bind socket to all available interfaces
// Note htol is the host sequence to network byte sequence, please understand Baidu
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(13);
// Bind the socket and address
Bind(listenfd, (SA *) &servaddr, sizeof(servaddr));
// The server starts listening on this port (create listening queue)
Listen(listenfd, LISTENQ);
// Server processing code
for ( ; ; ) {
// Remove a client connection from the listening queue
connfd = Accept(listenfd, (SA *) NULL, NULL);
ticks = time(NULL);
snprintf(buff, sizeof(buff), "%.24s\r\n", ctime(&ticks));
Write(connfd, buff, strlen(buff));
Close(connfd);
}
}
Client program
// Common header file of unix network programming
#include "unp.h"
int main(int argc, char **argv)
{
int sockfd, n;
char recvline[MAXLINE + 1];
struct sockaddr_in servaddr;
if (argc != 2)
err_quit("usage: a.out <IPaddress>");
// Create client socket
if ( (sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0)
err_sys("socket error");
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(13); /* daytime server */
if (inet_pton(AF_INET, argv[1], &servaddr.sin_addr) <= 0)
err_quit("inet_pton error for %s", argv[1]);
//Try to connect to the server port of the corresponding address
if (connect(sockfd, (SA *) &servaddr, sizeof(servaddr)) < 0)
err_sys("connect error");
// Read the contents of socket
while ( (n = read(sockfd, recvline, MAXLINE)) > 0) {
recvline[n] = 0; /* null terminate */
if (fputs(recvline, stdout) == EOF)
err_sys("fputs error");
}
if (n < 0)
err_sys("read error");
exit(0);
}
The workflow of TCP server and TCP client is shown below:
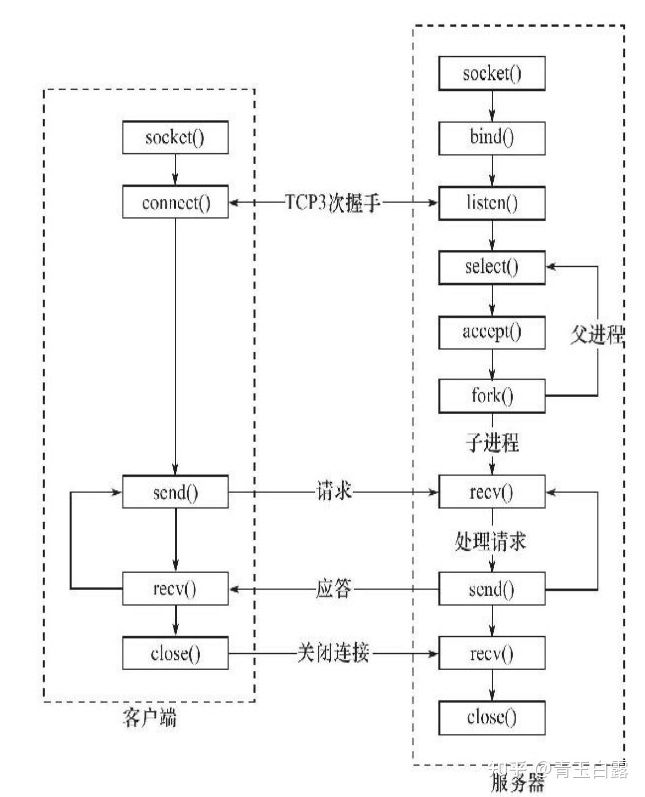
Learn more about socket reference resources.
Imagine that if multiple clients want to connect to the server, how can the server handle these clients? This requires an introduction to IO multiplexing.
What is IO reuse?
IO reuse refers to managing multiple I/O streams simultaneously by recording and tracking the state of each Socket(I/O stream) in a single process The reason for its invention is to improve the throughput of the server as much as possible, Reference link.
As mentioned above, when multiple clients are connected to the server, this involves the problem of how to provide services to each client "at the same time". The basic framework of the server is as follows:
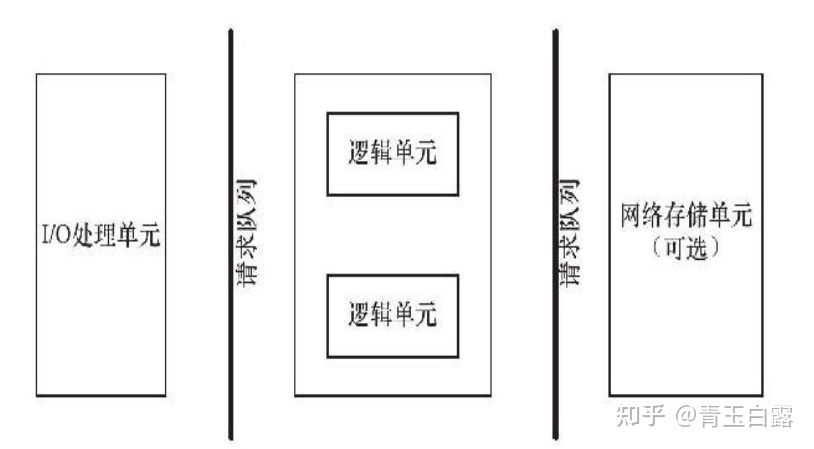
The logical unit in the figure is the function of "write server time" in the above example. To solve the problem of multi client connection, we must first have a queue to sort and store the connection requests, and then respond to the connected customers by means of concurrent multithreading.
This project uses epoll IO multiplexing technology to monitor the listening socket (listenfd) and the connecting socket (the socket after the customer requests to connect) at the same time. Note that although I/O reuse can listen to multiple file descriptors at the same time, it is blocked. Therefore, in order to improve efficiency, this part implements concurrency through thread pool, and allocates a logical unit (thread) for each ready file descriptor.
Unix has five basic IO models:
- Blocking IO (waiting)
- Non blocking IO (no return until there is one, which is actually a polling operation)
- IO reuse (select, poll, etc., so that the system is blocked on the select or poll call instead of the real IO system call (such as recvfrom). The IO system can be called only after the select returns readable. Its advantage is that it can wait for multiple descriptors to be in place)
- Signal driven IO (sigio, i.e. signal processing function is used to inform that the data is complete without blocking the main process)
- Asynchronous IO (the difference between posix's aio_; series of functions and signal driver is that the signal driver is the kernel telling us when IO can be performed, while the latter is the kernel telling us when IO operation has been completed)
For incoming IO events (or other signal / timing events), there are two event processing modes:
- Reactor mode: the main thread (I/O processing unit) is required to only listen for the occurrence of events (readable and writable) on the file descriptor. If so, it will immediately notify the working thread and put the socket readable and writable events into the request queue. Reading and writing data, accepting new connections and processing customer requests are all completed in the working thread. (read and write events need to be distinguished)
- Proactor mode: the main thread and kernel are responsible for I/O operations such as reading and writing data and accepting new connections. The working thread is only responsible for business logic (giving corresponding return url), such as processing customer requests.
Usually, synchronous I/O model (such as epoll_wait) is used to implement Reactor, and asynchronous I/O (such as aio_read and aio_write) is used to implement Proactor. However, asynchronous IO is not mature. Synchronous IO is used to simulate Proactor mode in this project. For further introduction of this part, please refer to Chapter 4, thread pool.
PS: what is synchronous I/O and what is asynchronous I/O?
- Synchronous (blocking) I/O: wait for the IO operation to complete before proceeding to the next operation. This is called synchronous io.
- Asynchronous (non blocking) I/O: when the code performs IO operations, it only issues IO instructions, does not wait for IO results, and then executes other code. After a period of time, when the IO returns the result (the kernel has completed the data copy), notify the CPU for processing. (the subtext of asynchronous operation is that you do it first, I'll do something else, and call me when you're good)
IO reuse requires the help of select/poll/epoll. The reason why epoll is adopted in this project is for reference( Why is epoll faster than select?)
- For select and poll, all file descriptors are added to their set of file descriptors in the user state, and the whole set needs to be copied to the kernel state for each call; Epoll maintains the whole set of file descriptors in the kernel state. Each time a file descriptor is added, a system call needs to be executed. The overhead of system calls is very large, and in the case of many short-term active connections, epoll may be slower than select and poll due to these large system call overhead.
- select uses a linear table to describe the set of file descriptors, which has an upper limit; poll uses linked list to describe; The underlying layer of epoll is described by a red black tree, and a ready list is maintained. The ready events in the event table are added here. Epoll is used_ When calling wait, you can only observe whether there is data in the list.
- The maximum cost of select and poll comes from the process that the kernel judges whether there are file descriptors ready: each time the select or poll call is executed, they will traverse the whole set of file descriptors to judge whether each file descriptor is active; Epoll does not need to check in this way. When there is activity, it will automatically trigger the epoll callback function to notify epoll file descriptors, and then the kernel will put these ready file descriptors into the ready list mentioned earlier and wait for epoll_wait is processed after calling.
- Both select and poll can only work in relatively inefficient LT mode, while epoll supports both LT and ET modes.
- In conclusion, when the number of fd monitored is small and each fd is very active, select and poll are recommended; When the number of fd monitored is large and only part of fd is active per unit time, using epoll will significantly improve the performance.
What does LT and ET mean?
- LT refers to the level trigger. When the IO event is ready, the kernel will keep notifying until the IO event is processed;
- ET refers to the Edge trigger. When the IO event is ready, the kernel will only notify it once. If it is not handled in time this time, the IO event will be lost.
What is multithreading?
The above mentioned concurrent multithreading. In the computer, the program exists as a process, and the thread is a further division of the process, that is, there can be multiple different code execution paths in a process. Compared with the process, the thread does not need the operating system to allocate resources for it, because its resources are in the process, and the creation and destruction of threads are much smaller than the process, so the efficiency of multithreaded programs is higher.
However, in the server project, it is not advisable to frequently create / destroy threads, which introduces the thread pool technology, that is, to create a batch of threads in advance. When a task needs to be executed, select a thread from the thread pool to execute the task. After the task is executed, throw the thread into the thread pool to wait for subsequent tasks.
For details of this part, please refer to: Multithreading and concurrency.
2, Project learning
After understanding the basic knowledge, let's learn the project code now. There is a problem. After all, how can we understand an open source project? Reproduce all the code?
If it is repeated, the cost performance is too small. If the open source project is needed for work, or is modified on its basis, it is essential to browse the whole code. But if it's just to learn the architecture and idea of the project, it's OK to start from the whole, study a function carefully, and then aim at the code block of interest.
For the server project in this article, the author mainly aims to learn the relevant knowledge of web server. I don't need to know all about it, but most of the code has to be sorted out, so I use this way to learn:
- Code architecture, what module each directory is responsible for (this part can be combined with the documents of open source projects to speed up the understanding of the project)
- Compile and run to see what functions are available;
- Select a function and study its code implementation. I will first select the "user login and registration" function for research, and then consider other functions;
- Add a function. How to add a function under the existing framework? For example, upload files, upload blogs and so on? Add message board?
- Unfinished
ok, the learning route is planned. Now let's start the journey of code learning!
Code architecture
Open the project with VsCode. The code structure of the project is as follows:
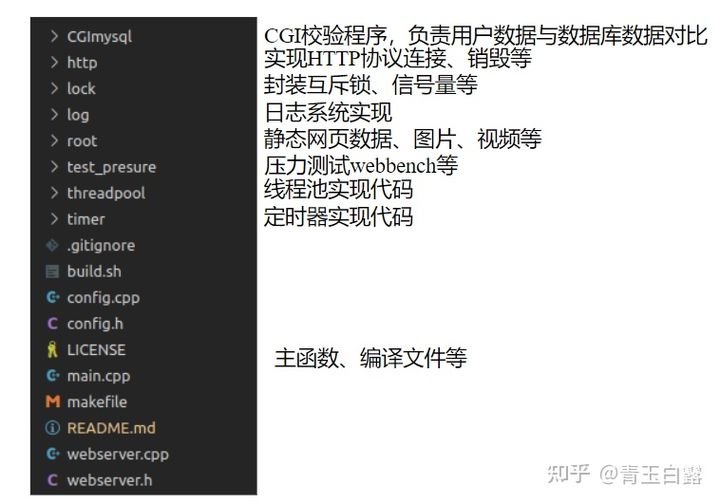
Referring to the document, the code framework of the project is as follows:
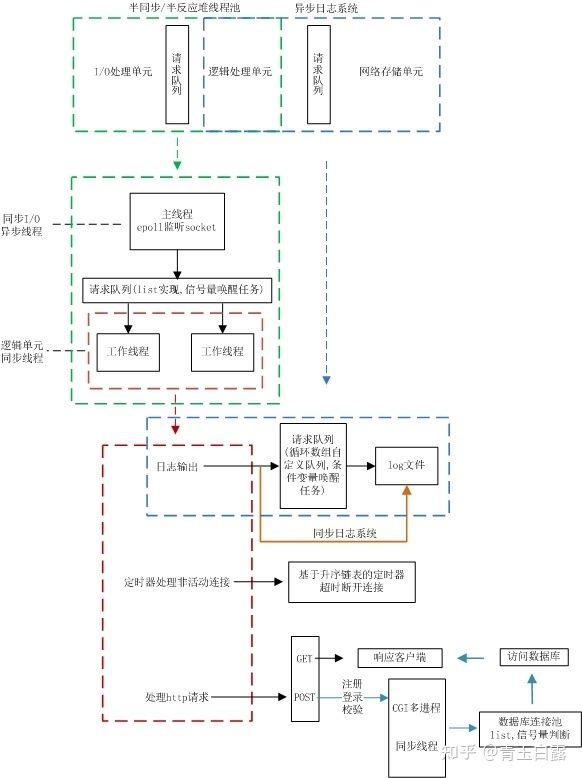
Compile and run
Install Mysql, create database, modify code, compile and run:
sh ./build.sh ./server // Open browser localhost:9006
The browser displays as follows:
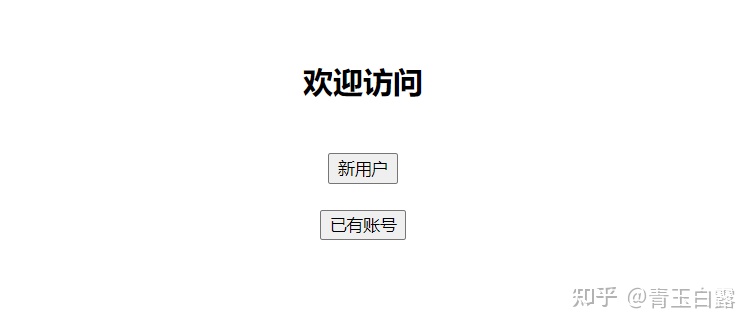
Click new user, register an account and then log in. There are three functions:

They are a picture / video / WeChat official account on the web page.
Read the following logic diagram when running the server:
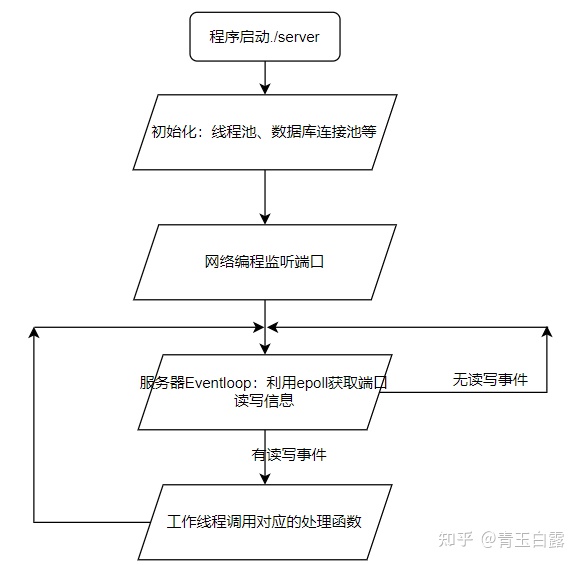
All the functions I'm most interested in are the login and registration function. Let's see how to implement it.
Detailed study of function
As for the login function, the page Jump logic is shown in the figure below. The original figure is from Two ape Society:
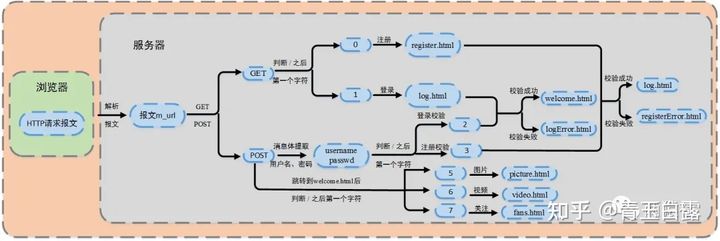
The logic in the figure above is clear. According to whether the HTTP request method is GET or POST, determine whether to obtain the registration / login user interface or update the user password to jump to the login success interface. For the introduction of HTTP, please refer to 3. Pull the rose with mud - http.
To be more specific, first of all, you need to obtain all user names and passwords from the database (PS: in actual large-scale projects, you can refer to the transmission of user passwords User login practice ), these user names and passwords are stored in some data structure, such as a hash table.
When the browser request arrives, access according to its request and return the corresponding interface html or error prompt.
The whole process is actually a finite state machine. Finite state machine?
Finite state machine refers to the process of transferring system state from one state to another, which represents the process of "selecting" and "updating state". For further information, please refer to: Finite state machine?
Because there are too many internal details of this function, please jump to Chapter 3, pull the Luo and take the mud - HTTP.
3, Pull the pineapple with mud - HTTP
This part is a detailed analysis of the login and registration function in Chapter 2. This paper first introduces the use of Epoll, then introduces the relevant knowledge of HTTP, and then gives the details of the "user login and registration" process.
Epoll
This section mainly introduces the function call framework of epoll. Let's first look at the common functions of epoll.
Common functions
epoll_create
//Create a file descriptor that indicates the epoll kernel event table //This descriptor will be used as the first parameter of other epoll system calls //size doesn't work. int epoll_create(int size)
epoll_ctl
//Operate the events on the file descriptor monitored by the kernel event table: registration, modification and deletion int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)
Where, epfd: epoll_ Handle to create
op: represents the action, which is represented by three macros:
- EPOLL_CTL_ADD (register new fd to epfd),
- EPOLL_CTL_MOD (modify the listening event of the registered fd),
- EPOLL_CTL_DEL (delete one FD from epfd);
event: tells the kernel what events to listen for
The event structure is defined as follows:
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
4};
events describes the event types, among which epoll event types are as follows
- EPOLLIN: indicates that the corresponding file descriptor can be read (including the normal shutdown of the opposite SOCKET)
- EPOLLOUT: indicates that the corresponding file descriptor can be written
- EPOLLPRI: indicates that the corresponding file descriptor has urgent data readability
- EPOLLERR: indicates an error occurred in the corresponding file descriptor
- EPOLLHUP: indicates that the corresponding file descriptor is hung up;
- EPOLLET: set EPOLL to edge triggered mode, which is relative to level triggered
- EPOLLONESHOT: only listen to one event. After listening to this event, if you need to continue listening to this socket, you need to add this socket to the EPOLL queue again
- EPOLLET: edge trigger mode
- EPOLLRDHUP: indicates that read is turned off and peer is turned off. Not all kernel versions support it;
epoll_wait
//This function is used to wait for the generation of events on the monitored file descriptor //Returns the number of ready file descriptors int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout)
Among them,
- Events: used to store the collection of events obtained by the kernel,
- maxevents: tell the kernel how big the events are and cannot be larger than epoll_ size at create();
- Timeout: timeout;
- Return value: successfully returns how many file descriptors are ready, returns 0 when the time expires, and returns - 1 when an error occurs;
example
How does epoll work in practical application? code Original link.
//tcp server epoll concurrent server
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <errno.h>
#include <pthread.h>
#include <ctype.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <sys/epoll.h>
#define MAX_LINK_NUM 128
#define SERV_PORT 8888
#define BUFF_LENGTH 320
#define MAX_EVENTS 5
int count = 0;
int tcp_epoll_server_init(){
//Common routine code for creating server port
int sockfd = socket(AF_INET,SOCK_STREAM,0);
if(sockfd == -1){
printf("socket error!\n");
return -1;
}
struct sockaddr_in serv_addr;
struct sockaddr_in clit_addr;
socklen_t clit_len;
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(SERV_PORT);
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);// Any local ip
int ret = bind(sockfd,(struct sockaddr*)&serv_addr,sizeof(serv_addr));
if(ret == -1){
printf("bind error!\n");
return -2;
}
listen(sockfd,MAX_LINK_NUM);
//Create epoll
int epoll_fd = epoll_create(MAX_EVENTS);
if(epoll_fd == -1){
printf("epoll_create error!\n");
return -3;
}
//Register sockfd with epoll to listen for events
struct epoll_event ev; //epoll event structure
struct epoll_event events[MAX_EVENTS]; //Event listening queue
ev.events = EPOLLIN;
ev.data.fd = sockfd;
int ret2 = epoll_ctl(epoll_fd,EPOLL_CTL_ADD,sockfd,&ev);
if(ret2 == -1){
printf("epoll_ctl error!\n");
return -4;
}
int connfd = 0;
while(1){
//epoll waits for the event to occur
int nfds = epoll_wait(epoll_fd,events,MAX_EVENTS,-1);
if(nfds == -1){
printf("epoll_wait error!\n");
return -5;
}
printf("nfds: %d\n",nfds);
//testing
for(int i = 0;i<nfds;++i){
//Customer service has a new request
if(events[i].data.fd == sockfd){
//Remove the connection
connfd = accept(sockfd,(struct sockaddr*)&clit_addr,&clit_len);
if(connfd == -1){
printf("accept error!\n");
return -6;
}
ev.events = EPOLLIN;
ev.data.fd = connfd;
if(epoll_ctl(epoll_fd,EPOLL_CTL_ADD,connfd,&ev) == -1){
printf("epoll_ctl add error!\n");
return -7;
}
printf("accept client: %s\n",inet_ntoa(clit_addr.sin_addr));
printf("client %d\n",++count);
}
//The client sends data
else{
char buff[BUFF_LENGTH];
int ret1 = read(connfd,buff,sizeof(buff));
printf("%s",buff);
}
}
}
close(connfd);
return 0;
}
int main(){
tcp_epoll_server_init();
}
HTTP
HTTP introduction
HTTP message
HTTP messages are divided into request messages (sent by the browser to the server) and response messages (returned to the browser after processing by the server). Each message must be generated in a unique format before it can be recognized by the browser.
- Request message = request line, request header, blank line and request data.
The request line is used to describe the request type (method), the resource to be accessed and the HTTP version used.
The request header, the part immediately after the request line (i.e. the first line), is used to describe the additional information to be used by the server.
Empty line: the empty line behind the request header is required. Even if the request data in the fourth part is empty, there must be an empty line.
Request data is also called subject, and any other data can be added.
- Response message = status line + message header + blank line + response body
The status line consists of HTTP protocol version number, status code and status message.
The message header is used to describe some additional information to be used by the client.
A blank line after the message header is required.
Response body, text information returned by the server to the client, etc.
HTTP status code and request method
HTTP has five types of status codes, specifically:
- 1xx: instruction information -- indicates that the request has been received and continues to be processed.
- 2xx: successful -- indicates that the request has been processed normally.
200 OK: the client request is processed normally.
206 Partial content: the client made a range request.
- 3xx: redirection -- further operations are necessary to complete the request.
301 Moved Permanently: permanently redirected. The resource has been permanently moved to a new location. In the future, access to the resource will use one of several URI s returned in this response.
302 Found: temporary redirection. The requested resources are temporarily obtained from different URI s.
- 4xx: client error -- the request has syntax error, and the server cannot process the request.
400 Bad Request: syntax error in request message.
403 Forbidden: the request was rejected by the server.
404 Not Found: the request does not exist. The requested resource cannot be found on the server.
- 5xx: server side error -- server processing request error.
500 Internal Server Error: the server encountered an error while executing the request.
HTTP1. After 1, there are eight method names, as shown below:

Since the project mainly involves GET and POST, what are the differences and connections between these two instructions?
In short, GET is mainly used to GET new web pages; POST is used to transfer the user's form data to the server, such as user name, password, message, etc;
Further, GET includes the parameters in the URL, and POST passes the parameters through request body.
In fact, GET and POST are just two output transmission identifiers defined by HTTP. Their transmission size is limited by TCP/IP protocol, and POST generally requires two transmissions. Blog is strongly recommended: The difference between get and post.
Here are two typical examples of GET and POST:
GET
GET /562f2.jpg HTTP/1.1 Host:img.mukewang.com User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36 Accept:image/webp,image/*,*/*;q=0.8 Referer:http://www.imooc.com/ Accept-Encoding:gzip, deflate, sdch Accept-Language:zh-CN,zh;q=0.8 Empty line Request data is empty
POST
POST / HTTP1.1 Host:www.wrox.com User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022) Content-Type:application/x-www-form-urlencoded Content-Length:40 Connection: Keep-Alive Empty line name=Professional%20Ajax&publisher=Wiley
HTTP processing flow
The HTTP processing flow is divided into the following three steps:
- Connection processing: the browser sends an http connection request. The main thread creates an http object to receive the request, reads all data into the corresponding buffer, inserts the object into the task queue, and waits for the working thread to take a task from the task queue for processing.
- Processing the message request: after the worker thread takes the task, it calls the process processing function and parses the request message through the host and slave state machine.
- Return response message: after parsing, a response message is generated and returned to the browser.
Next, three steps are introduced in sequence:
Connection processing
In the connection stage, the most important thing is the tcp connection process and reading http request message (in fact, reading request message is just reading the data sent by the client). The tcp connection process involves epoll kernel event creation, etc. see the subsequent epoll section for details.
How does the server read HTTP messages? First, the server needs to establish an HTTP class object for each established connection http. This part of the code is as follows (the server has been running eventloop, that is, loopback event, because the whole server is actually event driven):
//Event loopback (i.e. server main thread)
void WebServer::eventLoop()
{
......
while (!stop_server)
{
//Wait for an event to occur on the monitored file descriptor
int number = epoll_wait(m_epollfd, events, MAX_EVENT_NUMBER, -1);
if (number < 0 && errno != EINTR)
{
LOG_ERROR("%s", "epoll failure");
break;
}
//Handle all ready events
for (int i = 0; i < number; i++)
{
int sockfd = events[i].data.fd;
//Handle new customer connections
if (sockfd == m_listenfd)
{
bool flag = dealclinetdata();
if (false == flag)
continue;
}
//Handling exception events
else if (events[i].events & (EPOLLRDHUP | EPOLLHUP | EPOLLERR))
{
//The server closes the connection and removes the corresponding timer
util_timer *timer = users_timer[sockfd].timer;
deal_timer(timer, sockfd);
}
//Signal processing
else if ((sockfd == m_pipefd[0]) && (events[i].events & EPOLLIN))
{
bool flag = dealwithsignal(timeout, stop_server);
if (false == flag)
LOG_ERROR("%s", "dealclientdata failure");
}
//Process the data received on the customer connection
else if (events[i].events & EPOLLIN)
{
dealwithread(sockfd);
}
//Processing data received on customer connections is writable
else if (events[i].events & EPOLLOUT)
{
dealwithwrite(sockfd);
}
}
......
}
}
The dealclientdata() function in line 22 calls timer() to create a new client connection user, and adds a timing event (see the following section).
After completing this series of steps, a series of client client connections are maintained in the server. When one of the clients clicks a button on the page, generates a request message and transfers it to the server, it calls dealwithread () in the above event loopback code.
This function adds the port event append to the task request queue and waits for the thread in the thread pool to execute the task. According to the Reactor/Proactor mode, the worker thread reads the data of HTTP request message by read_once() function is completed, see http_conn.cpp.
read_ The once() function reads the browser (client) data into the cache array for subsequent worker threads to process.
Request message processing
When there are idle threads in the thread pool of webserver, a thread calls process () to complete the parsing of the request message and the corresponding tasks of the message. See HTTP for details_ conn/process():
//Handle http message request and message response
void http_conn::process()
{
//NO_REQUEST indicates that the request is incomplete and needs to continue to receive the request data
HTTP_CODE read_ret = process_read();
if (read_ret == NO_REQUEST)
{
//Register and listen for read events
modfd(m_epollfd, m_sockfd, EPOLLIN, m_TRIGMode);
return;
}
//Call process_write completion message response
bool write_ret = process_write(read_ret);
if (!write_ret)
{
close_conn();
}
//Register and listen for write events
modfd(m_epollfd, m_sockfd, EPOLLOUT, m_TRIGMode);
}
First introduce the processing of request message, that is, process_read() function.
This function encapsulates the master-slave state machine through the while loop, and circularly processes each line of the message. The main state machine here refers to process_ The read() function refers to parse from the state machine_ Line() function.
The slave state machine is responsible for reading a line of the message (and modifying \ r\n to \ 0 \ 0). The master state machine is responsible for parsing the data of this line. The master state machine calls the slave state machine internally and the slave state machine drives the master state machine. The relationship between them is shown in the figure below:
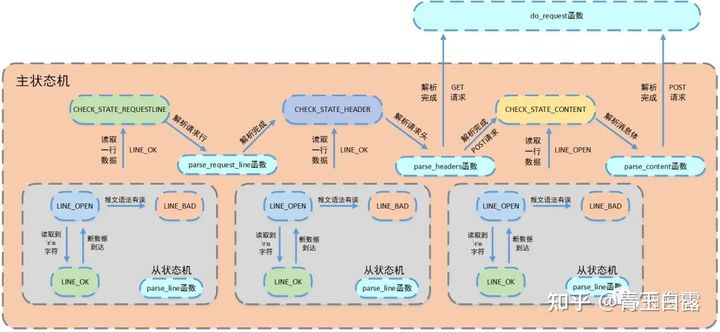
process_ The read() function is very important to understand the HTTP connection and processing part. You must take a look at the source code. Please understand it in combination with the source code and the above flowchart during the learning process:
//Finite state machine processing request message
http_conn::HTTP_CODE http_conn::process_read()
{
//
LINE_STATUS line_status = LINE_OK;
HTTP_CODE ret = NO_REQUEST;
char *text = 0;
while ((m_check_state == CHECK_STATE_CONTENT && line_status == LINE_OK) || ((line_status = parse_line()) == LINE_OK))
{
text = get_line();
m_start_line = m_checked_idx;
LOG_INFO("%s", text);
switch (m_check_state)
{
case CHECK_STATE_REQUESTLINE:
{
ret = parse_request_line(text);
if (ret == BAD_REQUEST)
return BAD_REQUEST;
break;
}
case CHECK_STATE_HEADER:
{
ret = parse_headers(text);
if (ret == BAD_REQUEST)
return BAD_REQUEST;
else if (ret == GET_REQUEST)
{
return do_request();
}
break;
}
case CHECK_STATE_CONTENT:
{
ret = parse_content(text);
if (ret == GET_REQUEST)
return do_request();
line_status = LINE_OPEN;
break;
}
default:
return INTERNAL_ERROR;
}
}
return NO_REQUEST;
}
The above code uses switch Case to reflect the selection of the main state machine, and the state of the main state machine is checked_ STATE_ Requestline / header / content, which is represented by three flags: parsing the request line, parsing the request header and parsing the message body. See the following for the supplement of judgment conditions and circulation body:
- Judgment conditions
- The main state machine is transferred to CHECK_STATE_CONTENT, which involves parsing the message body
- Transition from state machine to LINE_OK, this condition involves parsing the request line and the request header
- The relationship between the two is or. When the condition is true, continue the cycle, otherwise exit
- Circulatory body
- Read data from state machine
- Call get_line function, through m_start_line assigns the data read from the state machine to text indirectly
- Main state machine parsing text
PS: the reading of this part must be combined with the source code! It involves the addition and subtraction of many character array pointers. Please experience it carefully!
The initial state of the main state machine is CHECK_STATE_REQUESTLINE, then call parse_. request_ Line() parses the request line, obtains the HTTP request method, target URL and HTTP version number, and the status changes to CHECK_STATE_HEADER.
After entering the loop body, parse_ is called. Headers() parses the request header information. First, judge whether it is an empty line or a request header. An empty line further distinguishes between POST and GET. If it is a request header, update the connection status, host, and so on.
Note: one of the differences between GET and POST request messages is whether there is a message body part.
Use check when you need to POST a request_ STATE_ Analyze the content and take out the information (user name and password) in the POST message body.
Reference link:
https://mp.weixin.qq.com/s/wAQHU-QZiRt1VACMZZjNlw
Return response message
After parsing the request message, it is clear that if the user wants to log in / register, he needs to jump to the corresponding interface, add a user name, verify the user, etc., write the corresponding data into the corresponding message and return it to the browser. The flow chart is as follows:
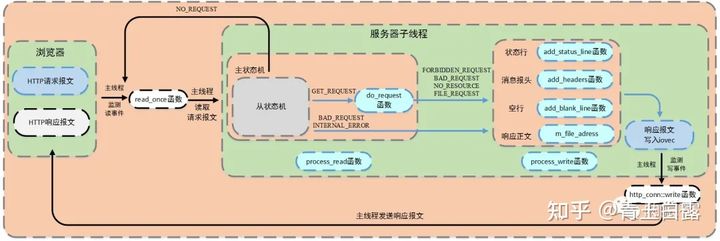
This is in process_ After parsing the request message in read(), the status opportunity calls do_request() function, which is used to process functional logic. This function splices the website root directory and url file, and then determines the file attributes through stat. url, which can be abstracted into ip:port/xxx. XXX is set through the action attribute of html file (i.e. request message). m_url is the request resource parsed in the request message, starting with /, that is, x, and m after parsing in the project_ There are 8 kinds of URLs. See do_request() function, part of the code is as follows:
//Functional logic unit
http_conn::HTTP_CODE http_conn::do_request()
{
strcpy(m_real_file, doc_root);
int len = strlen(doc_root);
//printf("m_url:%s\n", m_url);
const char *p = strrchr(m_url, '/');
//Processing cgi
if (cgi == 1 && (*(p + 1) == '2' || *(p + 1) == '3'))
{
//Judge whether it is login detection or registration detection according to the flag
char flag = m_url[1];
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/");
strcat(m_url_real, m_url + 2);
strncpy(m_real_file + len, m_url_real, FILENAME_LEN - len - 1);
free(m_url_real);
//Extract the user name and password
//user=123&passwd=123
char name[100], password[100];
int i;
for (i = 5; m_string[i] != '&'; ++i)
name[i - 5] = m_string[i];
name[i - 5] = '\0';
int j = 0;
for (i = i + 10; m_string[i] != '\0'; ++i, ++j)
password[j] = m_string[i];
password[j] = '\0';
if (*(p + 1) == '3')
{
//If it is registration, first check whether there are duplicate names in the database
//If there is no duplicate name, add data
......
if (users.find(name) == users.end())
{
m_lock.lock();
int res = mysql_query(mysql, sql_insert);
users.insert(pair<string, string>(name, password));
m_lock.unlock();
if (!res)
strcpy(m_url, "/log.html");
else
strcpy(m_url, "/registerError.html");
}
else
strcpy(m_url, "/registerError.html");
}
......
}
The stat function is used to obtain the type, size and other information of the file; mmap is used to map files to memory and improve access speed. See mmap principle ; iovec defines vector elements. Usually, this structure is used as a multi-element array. See President wechat ; writev is an aggregate write. See link;
Execute do_ After the request () function, the child thread calls process_write() generates response messages (add_status_line, add_headers and other functions). In the process of generating response message, add is mainly called_ The reponse() function updates m_write_idx and m_write_buf.
It is worth noting that there are two types of response messages. One is the existence of the request file. Two iovecs are declared through the io vector mechanism iovec, and the first one points to m_write_buf, the second address pointing to mmap, m_file_address ; The other is the request error. At this time, only one iovec is applied, pointing to m_write_buf .
In fact, what is written in the response message is the html file data in the server, which is parsed, rendered and displayed on the browser page by the browser.
In addition, the verification logic code of user login registration is in do_ In request (), users can be verified and added by querying or inserting the Mysql database.
The above is a detailed introduction to the registration / login module, and then explore the details of the thread pool, log and timer of the project in modules.
4, Thread pool
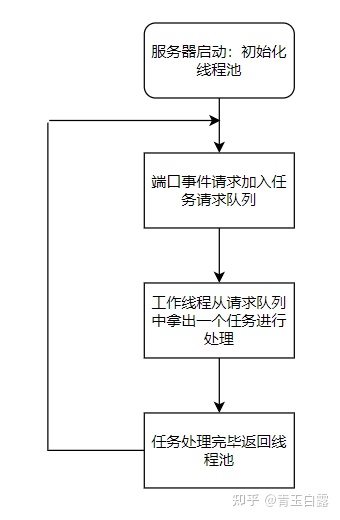
This part focuses on the implementation of thread pool of the project. The overall framework is as follows:
definition
Thread pool is defined as follows:
template <typename T>
class threadpool
{
public:
/*thread_number Is the number of threads in the thread pool, max_requests is the maximum number of requests waiting to be processed in the request queue*/
threadpool(int actor_model, connection_pool *connPool, int thread_number = 8, int max_request = 10000);
~threadpool();
bool append(T *request, int state);
bool append_p(T *request);
private:
/*A function run by a worker thread that continuously takes a task from a work queue and executes it*/
static void *worker(void *arg);//Why use static member functions ----- class specific
void run();
private:
int m_thread_number; //Number of threads in the thread pool
int m_max_requests; //Maximum number of requests allowed in the request queue
pthread_t *m_threads; //An array describing the thread pool, with a size of m_thread_number
std::list<T *> m_workqueue; //Request queue
locker m_queuelocker; //Protect the mutex of the request queue
sem m_queuestat; //Are there any tasks to deal with
connection_pool *m_connPool; //database
int m_actor_model; //Model switching (this switching refers to Reactor/Proactor)
};
Note that the thread pool adopts template programming to enhance its expansibility: all kinds of tasks can be supported.
The thread pool needs to create certain threads in advance, and the most important API is:
#include <pthread.h> //Returns the id of the newly generated thread int pthread_create (pthread_t *thread_tid,//id of the newly generated thread const pthread_attr_t *attr, //Pointer to thread property, usually set to NULL void * (*start_routine) (void *), //Address of the processing thread function void *arg); //start_ Parameters in routine()
The third parameter in the function prototype is the function pointer, which points to the address of the processing thread function. This function is required to be a static function. If the processing thread function is a class member function, it needs to be set as a static member function (because the non static member function of the class has this pointer, it does not match void *). Further understanding Please look.
Thread pool creation
Creation of thread pool in project:
threadpool<T>::threadpool( int actor_model, connection_pool *connPool, int thread_number, int max_requests)
: m_actor_model(actor_model),m_thread_number(thread_number), m_max_requests(max_requests), m_threads(NULL),m_connPool(connPool)
{
if (thread_number <= 0 || max_requests <= 0)
throw std::exception();
m_threads = new pthread_t[m_thread_number]; //pthread_t is a long integer
if (!m_threads)
throw std::exception();
for (int i = 0; i < thread_number; ++i)
{
//0 should be returned if the thread pool is created successfully. If the thread pool fails in the thread creation phase, the thread pool should be closed
if (pthread_create(m_threads + i, NULL, worker, this) != 0)
{
delete[] m_threads;
throw std::exception();
}
//It is mainly to change the thread attribute to unjoinable to facilitate the release of resources. See PS for details
if (pthread_detach(m_threads[i]))
{
delete[] m_threads;
throw std::exception();
}
}
}
PS: notice that pthread needs to be called after creating a thread_ Detect() because linux threads have two states: joinable and unjoinable.
If the thread is in the joinable state, when the thread function exits, it will not release the stack and thread descriptor occupied by the thread (more than 8K in total). Only when pthread is called_ Join, the main thread blocks, waits for the child thread to end, and then reclaims the child thread resources.
The unjoinable attribute can be set in pthread_ Specify pthread when creating or in the thread after the thread is created_ Detach (pthread_detach(), that is, the main thread is separated from the sub thread, and the resources are automatically recycled after the sub thread is completed), such as pthread_detach(pthread_self()) to change the state to rejoinable to ensure the release of resources. In fact, simply add pthread to the thread function header_ If detach (pthread_self()), the thread state changes and pthread is directly at the end of the function_ The exit thread will exit automatically. It saves the trouble of wiping the bottom of the thread.
Join request queue
When epoll detects that an event is activated on the port, put the event into the request queue (note mutual exclusion) and wait for the worker thread to process:
//Request queue in proactor mode
bool threadpool<T>::append_p(T *request)
{
m_queuelocker.lock();
if (m_workqueue.size() >= m_max_requests)
{
m_queuelocker.unlock();
return false;
}
m_workqueue.push_back(request);
m_queuelocker.unlock();
m_queuestat.post();
return true;
}
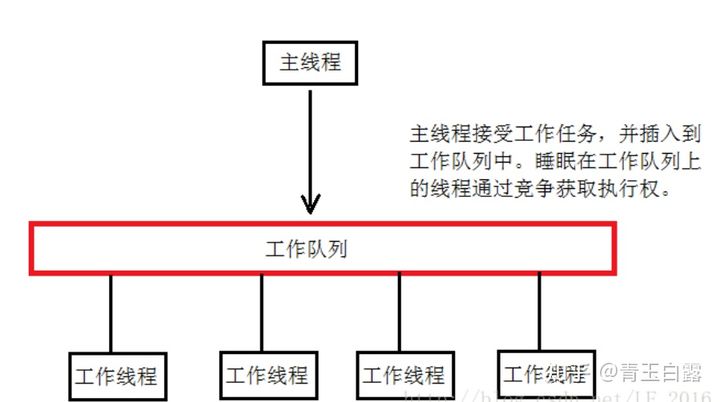
The above is the task request queue in the Proactor mode. If you don't know the Reactor and Proactor modes, please go back to Chapter 1, IO reuse. The project implements a concurrent structure based on semi synchronous / semi Reactor. The workflow of Proactor mode is as follows:
- The main thread acts as an asynchronous thread and is responsible for listening to events on all socket s
- If a new request arrives, the main thread receives it to get a new connection socket, and then registers the read-write events on the socket in the epoll kernel event table
- If a read-write event occurs on the connection socket, the main thread receives data from the socket, encapsulates the data into a request object and inserts it into the request queue
- All working threads sleep on the request queue. When a task arrives, they obtain the takeover right of the task through competition (such as mutex lock)
The principle is as follows:( Picture from)
Thread processing
When establishing the thread pool, pthread is called_ Create points to the static member function of worker(), while worker() calls run() internally.
//Worker thread: pthread_ It is called when you create it
template <typename T>
void *threadpool<T>::worker(void *arg)
{
//* arg is this when calling!
//So this operation is actually to get the threadpool object address
threadpool *pool = (threadpool *)arg;
//When each thread in the thread pool is created, it will call run() to sleep in the queue
pool->run();
return pool;
}
The run() function can also be regarded as a loopback event, waiting for m_queuestat() signal variable post, that is, a new task enters the request queue. At this time, a task is taken out of the request queue for processing:
//All threads in the thread pool sleep and wait for new tasks in the request queue
void threadpool<T>::run()
{
while (true)
{
m_queuestat.wait();
m_queuelocker.lock();
if (m_workqueue.empty())
{
m_queuelocker.unlock();
continue;
}
T *request = m_workqueue.front();
m_workqueue.pop_front();
m_queuelocker.unlock();
if (!request)
continue;
// ...... The thread starts task processing
}
}
Note: pthread is called every time_ Create will call run() once, because each thread is independent of each other and sleeps on the work queue. It will wake up for task competition only when the signal variable is updated.
5, Timer
Principle analysis
If a client connects with the server for a long time without data interaction, the connection has no meaning and occupies the resources of the server. In this case, the server needs a means to detect meaningless connections and process them.
In addition to handling inactive connections, the server also has some timing events, such as closing file descriptors.
To achieve these functions, the server needs to assign a timer to each event.
The project uses SIGALRM signal to realize the timer. First, each timing event is on an ascending linked list, and the SIGALRM signal is triggered periodically through the alarm() function. Then the signal callback function notifies the main loop through the pipeline. After receiving the signal, the main loop processes the timer on the ascending linked list: if there is no data exchange within a certain time, close the connection.
For the underlying API parsing of this part, it is recommended to read it directly Source code comments I added perhaps Refer to the president's article.
Code and block diagram
Since the timer part is invoked in the source code more complex, it can be understood in combination with the block diagram.
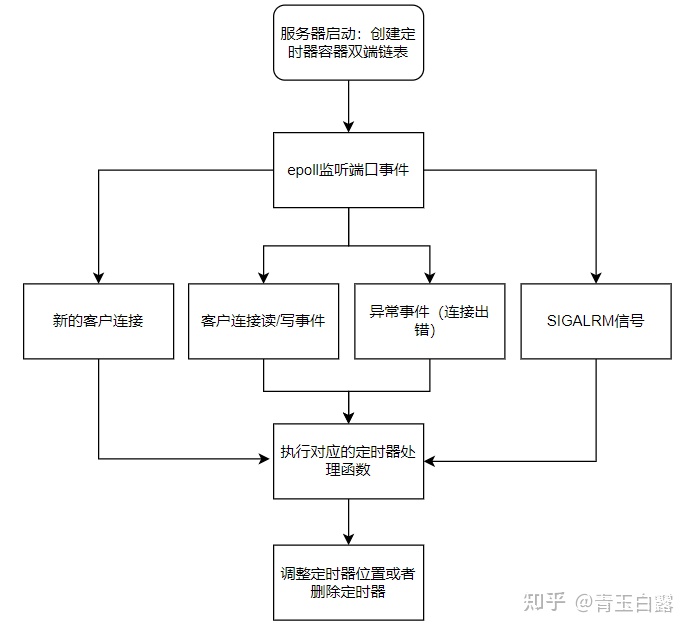
Written Narration:
The server first creates a linked list of timer containers, and then uses a unified event source to handle exception events, read-write events and signal events in a unified way. The timer is used according to the corresponding logic of different events.
Specifically, when the browser connects with the server, create the timer corresponding to the connection and add the timer to the timer container linked list;
When handling an abnormal event, execute a timing event, the server closes the connection and removes the corresponding timer from the linked list;
When processing the timing signal, set the timing flag to true to execute the timer processing function;
When processing read / write events, if a read event occurs on a connection or a connection sends data to the browser, move the corresponding timer backward; otherwise, execute the timing event.
6, Log system
In order to record the running state of the server, error information, files accessing data, etc., a log system needs to be established. In this project, the logging system is created using the singleton mode. The block diagram of this part is as follows (the original picture is from the president):
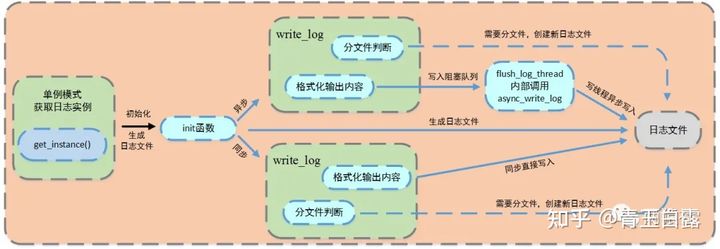
It can be seen from the above figure that the system has two writing modes: synchronous and asynchronous.
In the asynchronous writing mode, the producer consumer model is encapsulated as a blocking queue, and a writing thread is created. The working thread push es the content to be written into the queue, and the writing thread takes out the content from the queue and writes it to the log file. For synchronous writing mode, directly format the output content and write the information to the log file.
The system can realize the function of classification by day and super line.
This part is recommended to directly combine the source code from log H start reading, first check the synchronous writing mode, and then read the asynchronous writing log and blocking queue.
Or refer to the president's: Log system.
7, Other
Database connection pool
When dealing with user connections, the project uses: each HTTP connection obtains a database connection, obtains the user account and password in it for comparison (it consumes a little resources, which is certainly not the case in the actual scenario), and then releases the database connection.
So why create a database connection pool?
The general process of database access is: when the system needs to access the database, the system creates the database connection first, completes the database operation, and then the system disconnects the database connection—— It can be seen that if the system needs to frequently access the database, it needs to frequently create and disconnect the database connection, and creating the database connection is a very time-consuming operation, which is also easy to cause security risks to the database.
When the program is initialized, multiple database connections are created centrally and managed centrally for use by the program, which can ensure faster database reading and writing speed and more safe and reliable.
In fact, the idea of database connection pool and thread pool is basically the same.
In this project, not only the database connection pool is realized, but also the acquisition and release of database connections are encapsulated through RAII mechanism to avoid manual release.
This part is easy to understand. It is recommended to read the source code directly.
Encapsulating synchronization classes
In order to realize the RAII mechanism of synchronization class, the project encapsulates the pthread library and implements mutex and condition similar to C++11_ variable.
You can read the source code in the folder lock to learn this.
reference material
(main information) articles of the president himself:
https://github.com/qinguoyi/TinyWebServer#%E5%BA%96%E4%B8%81%E8%A7%A3%E7%89%9B
(recommended) read TinyWebServer:
https://book.douban.com/subject/24722611/
https://baike.baidu.com/item/WEB%E6%9C%8D%E5%8A%A1%E5%99%A8/8390210?fr=aladdin
Comparison of mainstream servers:
https://www.cnblogs.com/sammyliu/articles/4392269.html
https://blog.csdn.net/u010066903/article/details/52827297/
Project address: