Author: xidianwangtao@gmail.com
stay Kubernetes 1.8 Preemption Source Code Analysis for Preemptive Scheduling We mentioned Nominated Pods in several places, but did not give enough analysis at that time. Today we will focus on the significance and principle of Nominated Pods.
What is Nominated Pods?
When enable PodPriority feature gate is enabled, scheduler preempts low-priority Pods (victims) resources for preemptor when cluster resources are insufficient. Then preemptor will enter the scheduling queue again, waiting for the next victims graceful termination and the next scheduling.
In order to avoid the scheduler in the period from preemptor preemption to real re-execution of scheduling, it can perceive that those resources have been preempted. When scheduler schedules other higher priority Pods, it considers that these resources have been preempted. Therefore, in the preemption phase, pod.Status.NominatedNodeName is set for preemptor, which means preemption occurs on NominatedNodeName. Emptor expects scheduling on the node.
Nominated Pods on each node are cached in PriorityQueue. These Nominated Pods indicate that they have been nominated by the node and are expected to be scheduled on the node, but have not yet been successfully scheduled.
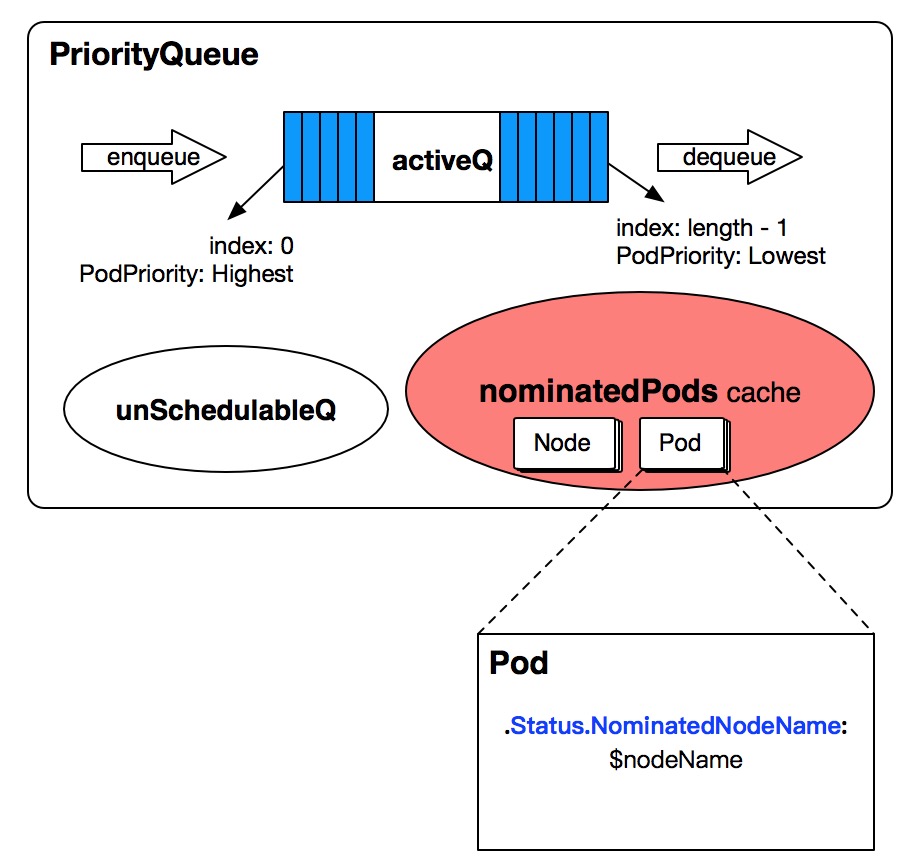
What happened to preemptive scheduling?
Let's focus on the process associated with scheduler's preempt ion.
func (sched *Scheduler) preempt(preemptor *v1.Pod, scheduleErr error) (string, error) { ... node, victims, nominatedPodsToClear, err := sched.config.Algorithm.Preempt(preemptor, sched.config.NodeLister, scheduleErr) ... var nodeName = "" if node != nil { nodeName = node.Name err = sched.config.PodPreemptor.SetNominatedNodeName(preemptor, nodeName) if err != nil { glog.Errorf("Error in preemption process. Cannot update pod %v annotations: %v", preemptor.Name, err) return "", err } ... } // Clearing nominated pods should happen outside of "if node != nil". Node could // be nil when a pod with nominated node name is eligible to preempt again, // but preemption logic does not find any node for it. In that case Preempt() // function of generic_scheduler.go returns the pod itself for removal of the annotation. for _, p := range nominatedPodsToClear { rErr := sched.config.PodPreemptor.RemoveNominatedNodeName(p) if rErr != nil { glog.Errorf("Cannot remove nominated node annotation of pod: %v", rErr) // We do not return as this error is not critical. } } return nodeName, err }
-
Invoke Schedule Algorithm. Preempt preempts resources and returns node, victim, nominatedPodsToClear where preemption occurs.
- Node: the best node where preemption occurs;
- victims: pods to be deleted to release resources to preemptor;
- Nominated Pods ToClear: Lists of Pods that will be deleted. Status. Nominated NodeName. These Pods belong first to nominated Pods Cache in PriorityQueue, and their Pod Priority is lower than preemptor Pod Priority, which means that these nominated Pods are no longer suitable for dispatching to the node chosen in the previous preemption.
func (g *genericScheduler) Preempt(pod *v1.Pod, nodeLister algorithm.NodeLister, scheduleErr error) (*v1.Node, []*v1.Pod, []*v1.Pod, error) { ... candidateNode := pickOneNodeForPreemption(nodeToVictims) if candidateNode == nil { return nil, nil, nil, err } nominatedPods := g.getLowerPriorityNominatedPods(pod, candidateNode.Name) if nodeInfo, ok := g.cachedNodeInfoMap[candidateNode.Name]; ok { return nodeInfo.Node(), nodeToVictims[candidateNode].Pods, nominatedPods, err } return nil, nil, nil, fmt.Errorf( "preemption failed: the target node %s has been deleted from scheduler cache", candidateNode.Name) } func (g *genericScheduler) getLowerPriorityNominatedPods(pod *v1.Pod, nodeName string) []*v1.Pod { pods := g.schedulingQueue.WaitingPodsForNode(nodeName) if len(pods) == 0 { return nil } var lowerPriorityPods []*v1.Pod podPriority := util.GetPodPriority(pod) for _, p := range pods { if util.GetPodPriority(p) < podPriority { lowerPriorityPods = append(lowerPriorityPods, p) } } return lowerPriorityPods } -
If preemption succeeds (node is not empty), call podPreemptor.SetNominatedNodeName to set preemptor's. Status.NominatedNodeName as the node name, indicating that the preemptor expects to preempt on the node.
func (p *podPreemptor) SetNominatedNodeName(pod *v1.Pod, nominatedNodeName string) error { podCopy := pod.DeepCopy() podCopy.Status.NominatedNodeName = nominatedNodeName _, err := p.Client.CoreV1().Pods(pod.Namespace).UpdateStatus(podCopy) return err } -
Whether the preemption is successful (node is empty or not), nominated PodsToClear may not be empty. You need to traverse all Pods in nominated PodsToClear and call podPreemptor.RemoveNominatedNodeName to set its. Status.NominatedNodeName to empty.
func (p *podPreemptor) RemoveNominatedNodeName(pod *v1.Pod) error { if len(pod.Status.NominatedNodeName) == 0 { return nil } return p.SetNominatedNodeName(pod, "") }
What happened after Preemptor succeeded in grabbing?
After the Premmptor preemption is successful, the Pod will be re-added to the Unschedulable Sub-Queue queue in PriorityQueue, waiting for the condition to start scheduling again. For a more in-depth reading of this section, please refer to my blog. Deep analysis of Kubernetes Scheduler's priority queues . preemptor will again predicate the node through podFitsOnNode.
func podFitsOnNode( pod *v1.Pod, meta algorithm.PredicateMetadata, info *schedulercache.NodeInfo, predicateFuncs map[string]algorithm.FitPredicate, ecache *EquivalenceCache, queue SchedulingQueue, alwaysCheckAllPredicates bool, equivCacheInfo *equivalenceClassInfo, ) (bool, []algorithm.PredicateFailureReason, error) { var ( eCacheAvailable bool failedPredicates []algorithm.PredicateFailureReason ) predicateResults := make(map[string]HostPredicate) podsAdded := false for i := 0; i < 2; i++ { metaToUse := meta nodeInfoToUse := info if i == 0 { podsAdded, metaToUse, nodeInfoToUse = addNominatedPods(util.GetPodPriority(pod), meta, info, queue) } else if !podsAdded || len(failedPredicates) != 0 { // Is there a problem? It should be podsAdded, not! PodsAdded break } // Bypass eCache if node has any nominated pods. // TODO(bsalamat): consider using eCache and adding proper eCache invalidations // when pods are nominated or their nominations change. eCacheAvailable = equivCacheInfo != nil && !podsAdded for _, predicateKey := range predicates.Ordering() { var ( fit bool reasons []algorithm.PredicateFailureReason err error ) func() { var invalid bool if eCacheAvailable { ... } if !eCacheAvailable || invalid { // we need to execute predicate functions since equivalence cache does not work fit, reasons, err = predicate(pod, metaToUse, nodeInfoToUse) if err != nil { return } ... } }() ... } } } return len(failedPredicates) == 0, failedPredicates, nil }
A total of two predicate attempts will be made:
-
The first predicate calls addNominatedPods, traverses all Pods in PriorityQueue nominatedPods, and adds all nominatedPods whose PodPriority is greater than or equal to the priority of the dispatched Pod to the NodeInfo of Scheduler Cache, which means that these high priority nominatedPods are pre-selected when dispatching the pod, such as subtracting their resourceRequest, and updating them. Go to PredicateMetadata and then execute the normal predicate logic.
-
In the second predicate, if the previous predicate logic fails or the previous podsAdded is false (if the node is empty for nominatedPods cache when addNominatedPods is added, then the return value podAdded is false), then the second predicate terminates immediately and does not trigger the real predicate logic.
-
If the previous predicate logic is successful and the podAdded is true, then the real second predicate logic needs to be triggered, because the addition of nominatedPods may affect the predicate result.
Below is the code for addNominatedPods, which generates temporary schedulercache.NodeInfo and algorithm.PredicateMetadata for pre-selection of specific predicate functions.
// addNominatedPods adds pods with equal or greater priority which are nominated // to run on the node given in nodeInfo to meta and nodeInfo. It returns 1) whether // any pod was found, 2) augmented meta data, 3) augmented nodeInfo. func addNominatedPods(podPriority int32, meta algorithm.PredicateMetadata, nodeInfo *schedulercache.NodeInfo, queue SchedulingQueue) (bool, algorithm.PredicateMetadata, *schedulercache.NodeInfo) { if queue == nil || nodeInfo == nil || nodeInfo.Node() == nil { // This may happen only in tests. return false, meta, nodeInfo } nominatedPods := queue.WaitingPodsForNode(nodeInfo.Node().Name) if nominatedPods == nil || len(nominatedPods) == 0 { return false, meta, nodeInfo } var metaOut algorithm.PredicateMetadata if meta != nil { metaOut = meta.ShallowCopy() } nodeInfoOut := nodeInfo.Clone() for _, p := range nominatedPods { if util.GetPodPriority(p) >= podPriority { nodeInfoOut.AddPod(p) if metaOut != nil { metaOut.AddPod(p, nodeInfoOut) } } } return true, metaOut, nodeInfoOut } // WaitingPodsForNode returns pods that are nominated to run on the given node, // but they are waiting for other pods to be removed from the node before they // can be actually scheduled. func (p *PriorityQueue) WaitingPodsForNode(nodeName string) []*v1.Pod { p.lock.RLock() defer p.lock.RUnlock() if list, ok := p.nominatedPods[nodeName]; ok { return list } return nil }
The logic of addNominatedPods is as follows:
- Call WaitingPodsForNode to get nominatedPods cache data on the node in PriorityQueue. If nominatedPods is empty, return podAdded to false, and the addNominatedPods process ends.
- PredicateMeta and NodeInfo objects are cloned, nominatedPods are traversed, nominated pod s with priority not less than scheduled pods are added to the cloned NodeInfo objects one by one, and updated to the cloned PredicateMeta objects. These cloned NodeInfo and PrecateMeta objects will eventually be passed into predicate Functions for pre-selection. After the traversal is completed, the podAdded (true) and NodeInfo and PrecateMeta objects are returned.
How to maintain PriorityQueue Nominated Pods Cache
Deep analysis of Kubernetes Scheduler's priority queues The operation of PriorityQueue in EventHandler registered with podInformer, nodeInformer, service Informer and pvcInformer in scheduler is analyzed. The EventHandler related to NominatedPods is as follows.
Add Pod to PriorityQueue
- When a Pod is added to an active queue in PriorityQueue, addNominatedPodIfNeeded is called to delete the pod to be added from the PriorityQueue nominatedPods Cache and then add it back to the nominatedPods cache.
// Add adds a pod to the active queue. It should be called only when a new pod // is added so there is no chance the pod is already in either queue. func (p *PriorityQueue) Add(pod *v1.Pod) error { p.lock.Lock() defer p.lock.Unlock() err := p.activeQ.Add(pod) if err != nil { glog.Errorf("Error adding pod %v to the scheduling queue: %v", pod.Name, err) } else { if p.unschedulableQ.get(pod) != nil { glog.Errorf("Error: pod %v is already in the unschedulable queue.", pod.Name) p.deleteNominatedPodIfExists(pod) p.unschedulableQ.delete(pod) } p.addNominatedPodIfNeeded(pod) p.cond.Broadcast() } return err } func (p *PriorityQueue) addNominatedPodIfNeeded(pod *v1.Pod) { nnn := NominatedNodeName(pod) if len(nnn) > 0 { for _, np := range p.nominatedPods[nnn] { if np.UID == pod.UID { glog.Errorf("Pod %v/%v already exists in the nominated map!", pod.Namespace, pod.Name) return } } p.nominatedPods[nnn] = append(p.nominatedPods[nnn], pod) } }
- When adding Pod to unSchedulableQ queue in PriorityQueue, addNominatedPodIfNeeded is called to add/update the pod to PriorityQueue nominatedPods Cache accordingly.
func (p *PriorityQueue) AddUnschedulableIfNotPresent(pod *v1.Pod) error { p.lock.Lock() defer p.lock.Unlock() if p.unschedulableQ.get(pod) != nil { return fmt.Errorf("pod is already present in unschedulableQ") } if _, exists, _ := p.activeQ.Get(pod); exists { return fmt.Errorf("pod is already present in the activeQ") } if !p.receivedMoveRequest && isPodUnschedulable(pod) { p.unschedulableQ.addOrUpdate(pod) p.addNominatedPodIfNeeded(pod) return nil } err := p.activeQ.Add(pod) if err == nil { p.addNominatedPodIfNeeded(pod) p.cond.Broadcast() } return err }
Note that the premise for adding a pod to nominated Pods cache is that the pod's. Status. Nominated NodeName is not empty.
Update Pod in PriorityQueue
When the Pod in PriorityQueue is updated, the nominatedPods Cache in PriorityQueue is updated by calling updateNominatedPod.
// Update updates a pod in the active queue if present. Otherwise, it removes // the item from the unschedulable queue and adds the updated one to the active // queue. func (p *PriorityQueue) Update(oldPod, newPod *v1.Pod) error { p.lock.Lock() defer p.lock.Unlock() // If the pod is already in the active queue, just update it there. if _, exists, _ := p.activeQ.Get(newPod); exists { p.updateNominatedPod(oldPod, newPod) err := p.activeQ.Update(newPod) return err } // If the pod is in the unschedulable queue, updating it may make it schedulable. if usPod := p.unschedulableQ.get(newPod); usPod != nil { p.updateNominatedPod(oldPod, newPod) if isPodUpdated(oldPod, newPod) { p.unschedulableQ.delete(usPod) err := p.activeQ.Add(newPod) if err == nil { p.cond.Broadcast() } return err } p.unschedulableQ.addOrUpdate(newPod) return nil } // If pod is not in any of the two queue, we put it in the active queue. err := p.activeQ.Add(newPod) if err == nil { p.addNominatedPodIfNeeded(newPod) p.cond.Broadcast() } return err }
The logic of updateNominatedPod updating PriorityQueue nominatedPods Cache is to delete oldPod and add newPod.
// updateNominatedPod updates a pod in the nominatedPods. func (p *PriorityQueue) updateNominatedPod(oldPod, newPod *v1.Pod) { // Even if the nominated node name of the Pod is not changed, we must delete and add it again // to ensure that its pointer is updated. p.deleteNominatedPodIfExists(oldPod) p.addNominatedPodIfNeeded(newPod) }
Delete Pod from PriorityQueue
Before deleting a Pod from PriorityQueue, deleteNominatedPodIfExists is called to delete the pod from PriorityQueue nominatedPods cache.
// Delete deletes the item from either of the two queues. It assumes the pod is // only in one queue. func (p *PriorityQueue) Delete(pod *v1.Pod) error { p.lock.Lock() defer p.lock.Unlock() p.deleteNominatedPodIfExists(pod) err := p.activeQ.Delete(pod) if err != nil { // The item was probably not found in the activeQ. p.unschedulableQ.delete(pod) } return nil }
When delete NominatedPodIfExists, first check that the. Status.NominatedNodeName of the pod is empty:
- If it is empty, do nothing and return the process directly.
- If it is not empty, traverse nominated Pods cache. Once a pod matching UID is found, the pod exists in nominated Pods, and then the pod is deleted from the cache. If, after deletion, no nominatePods are found on the NominatedNode corresponding to the pod, the nominatedPods of the entire node are deleted from the map cache.
func (p *PriorityQueue) deleteNominatedPodIfExists(pod *v1.Pod) { nnn := NominatedNodeName(pod) if len(nnn) > 0 { for i, np := range p.nominatedPods[nnn] { if np.UID == pod.UID { p.nominatedPods[nnn] = append(p.nominatedPods[nnn][:i], p.nominatedPods[nnn][i+1:]...) if len(p.nominatedPods[nnn]) == 0 { delete(p.nominatedPods, nnn) } break } } } }
summary
This paper expounds the functions of Nominated Pods and Nominated Node, and analyses the changes of Nominated Pods in preemptive scheduling and after preemptive scheduling from the source code point of view. Finally, it analyses the influence of Pod's Add/Update/Delete operation in PriorityQueue on PriorityQueue Nominated Pods Cache, hoping to help readers deepen their influence on scheduler preemptive scheduling and priority queue. Understand.