There are some general optimization steps for the optimization of SQL query statements. This section introduces the general optimization steps.
How is a query executed
First, if we want to understand the process of a query statement, then we can optimize the process.
Refer to a MySQL infrastructure diagram I drew earlier:
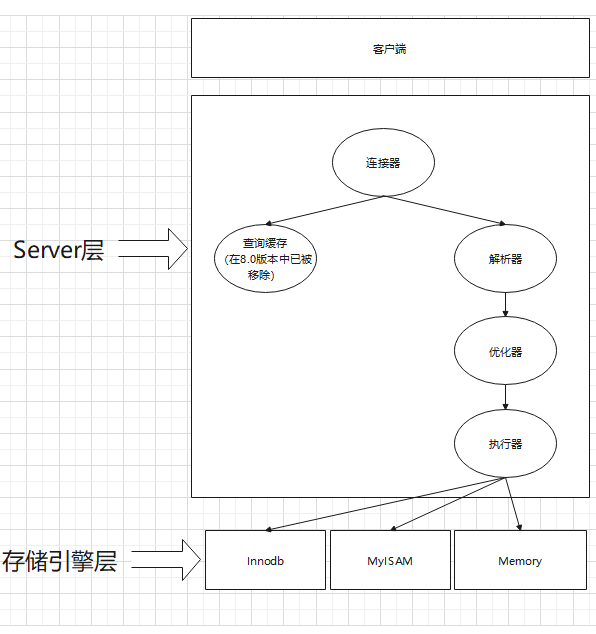
The life cycle of a query statement in MySQL can be divided into
- The client connects to the server through a connector
- Parsing SQL statements in the parser
- Optimizer for optimization
- The executor executes the generated execution plan
- Return results to the client
Generally speaking, the actuator execution stage is the most important stage, that is, the stage that consumes the most performance. So our optimization is actually optimizing the execution plan of the actuator.
How to find and solve slow queries
The reason for low query performance is that the amount of data accessed is too large, which makes a query very slow. So how can we find and solve slow queries.
Slow query log
There is a log in MySQL called slow query log_ QUERY_ Log, which will record the statements whose response time exceeds the threshold (long_query_time) in MySQL. The slow query log is not enabled by default, and the default threshold is 10. If it is an online environment, it is not recommended to enable the slow query log. It is more appropriate to enable it when there is a need for tuning.
mysql> show variables like '%slow_query_log%'; +---------------------+-------------------------------------------------+ | Variable_name | Value | +---------------------+-------------------------------------------------+ | slow_query_log | OFF | | slow_query_log_file | /var/lib/mysql/iZwz9iiwojnmkotgajxjlqZ-slow.log | +---------------------+-------------------------------------------------+ 2 rows in set (0.01 sec) mysql> set global slow_query_log=1; Query OK, 0 rows affected (0.00 sec)
Use set global slow_query_log=1. The slow query will be invalid after MySQL is restarted. If it is to be effective all the time, you need to modify the configuration file my cnf.
slow_query_log_file to see the location of your stored slow query log. Let's execute the following statement first:
mysql> select sleep(12); +-----------+ | sleep(12) | +-----------+ | 0 | +-----------+ 1 row in set (12.00 sec)
Then go to / var / lib / MySQL / izwz9iiwojnmkotgajxjlqz slow log
/usr/sbin/mysqld, Version: 8.0.27-0ubuntu0.20.04.1 ((Ubuntu)). started with: Tcp port: 3306 Unix socket: /var/run/mysqld/mysqld.sock Time Id Command Argument # Time: 2022-02-04T08:27:51.234016Z # User@Host: root[root] @ localhost [] Id: 1653 # Query_time: 12.001395 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1 SET timestamp=1643963259; select sleep(12);
We can see that a slow query has been recorded in the slow query log, and then we can optimize it step by step according to the normal optimization steps mentioned later.
Note: because I focus on the back end, the slow query log of MySQL is only simple to use here. In fact, there are many other parameters of the slow query log, and there are a variety of MySQL log analysis tools to assist. When necessary in the future, I will devote a chapter to the use of MySQL log analysis tools.
General optimization ideas
There are some general ideas for SQL statement optimization, which are introduced here one by one.
Try not to get unnecessary data
Sometimes, the query will request more data than the actual needs, and then discard the excess data in the application. This will bring additional burden to the MySQL server, increase the network overhead and consume the CPU and memory resources of the application server.
Typical scenario:
- Query unnecessary data
- Return all columns in multi table Association
- Always take out all columns
- Repeatedly query the same data
In conclusion, I think it can be divided into two points:
- Use SELECT * FROM with caution
- Take out only the required fields
Reduce the number of additional record lines scanned by MySQL
For MySQL query statements, the returned data rows are different from the scanned data rows. We can use a very simple example to illustrate:
This is a data table that uses stored procedures to generate 100w pieces of data
These indexes are:

We execute a SQL query statement:
mysql> EXPLAIN SELECT * from user where account = 12345; +----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+ | 1 | SIMPLE | user | NULL | ref | test | test | 4 | const | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec)
EXPLAIN later. As long as you know the keyword, you can see the approximate number of scanning lines.
You can see that the number of scanned lines is 1, and the number of returned lines is also 1.
We delete the 'test' index and execute the same statement again:
mysql> EXPLAIN SELECT * from user where account = 12345; +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 991536 | 10.00 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
We can see that the number of rows scanned is very large, which is a full table scan, but the number of rows returned is actually one row, that is to say, we have done a lot of useless scans.
Generally, MySQL can apply WHERE conditions in the following three ways, from good to bad:
- Use the WHERE condition in the index to filter mismatched records. This is done in the storage engine.
- Scan the returned records using the overlay index, filter the unnecessary records directly from the index and return the hit results. The service layer of MySQL is completed, and there is no need to return to the table.
- Return data from the data table, and then filter the records that do not meet the conditions. Complete in MySQL server layer.
How to reconstruct query
Common ways to reconstruct queries are as follows:
- Split a complex query into multiple simple queries
- Segmentation query: divide and conquer large queries, and query a small part of the results at a time
- Decomposition Association query
One complex query or multiple simple queries
In the traditional implementation, it is emphasized to complete as much work as possible in the database layer. In the past, it was considered that network communication, query parsing and optimization were a very expensive thing.
However, MySQL's design makes the connection and disconnection very lightweight and efficient in returning a small query result. MySQL can scan millions of rows of data in memory every second. Compared with MySQL, the response data to the client is very slow.
So sometimes you can weigh whether you need to decompose a large query into multiple small queries.
Segmentation query
Sometimes, for a large query, divide and conquer, and decompose a large query into small queries. Each query function is exactly the same, and only a small part is returned at a time.
The most typical scenario is to delete old data, such as 100w old data. If you delete all the data in one SQL statement, the SQL statement will execute a long process. At the same time, it may lock a large amount of data, occupy the whole transaction log, exhaust system resources and block other queries. Then we can delete 1w old data at one time, so that the performance loss of deleting all old data can be spread over a long time, greatly reducing the impact on the server.
Decomposition Association query
As for the JOIN keyword, many DBA s will directly disable the JOIN statement because the JOIN statement may scan A large number of rows. I will summarize it in A later blog. In short, if the index cannot be used on the driven table, the whole table will be scanned directly every time the driven table is queried. The number of rows scanned by A JOIN B will directly be the number of rows of A * the number of rows of B.
Therefore, we can split a JOIN statement into multiple simple queries and then assemble them in the application.
Decomposition Association query can have the following advantages:
- Executing a single query can reduce lock contention
- By associating with the application layer, it is easier to split the database and achieve high performance and scalability
- The query of redundant records can be reduced
- This form is equivalent to hash Association in the application layer. In many cases, hash association is much more efficient
MySQL optimizer
MySQL optimizer is a cost based optimizer. There are some reasons why MySQL optimizer chooses the wrong execution plan:
- Inaccurate statistics.
- The estimated cost of implementing the plan is not equal to the actual cost.
- The optimization of MySQL is not just about response time.
- MySQL does not consider concurrent execution.
- MySQL is sometimes optimized based on some fixed rules.
MySQL can handle the following optimization types:
- Redefine the order of associated tables
- Convert external connection to internal connection
- Use equivalent change rules: for example, merge and reduce some comparisons, and remove some identifications or non identifications. For example, (5 = 5 and a > 5) will be rewritten as a > 5.
- Optimize COUNT(), MIN(), MAX()
- The expression is converted into a constant
- Overwrite index scan
- Subquery optimization
- Terminate query in advance: LIMIT, find a condition that does not hold.
- Equivalent propagation: when USING, there is no need to declare the same fields in the two tables repeatedly.
10. Comparison of list IN(): IN() in MySQL is to sort the data in the list first and then binary query.
Application of EXPLAIN keyword
EXPLAIN keyword must be familiar to students who often optimize SQL statements. I'll briefly introduce it here. EXPLAIN displays the expected execution plan of the SQL statement, whether to use index, intermediate table, sorting, etc., and the expected number of rows to scan.
Last words
The above is an overview of the performance optimization of MySQL SQL query statements. Later, targeted blogs will be created to optimize specific scenarios for the following problems:
- Optimize COUNT() query
- Optimize LIMIT paging
- Optimization of related statements
- Optimization of sorting
And EXPLAIN the details, common optimization failures, and how to solve them.