Why do I need a thread pool
We know that the common way to create a thread is new Thread(), and every time new Thread(), a thread will be re created, and the creation and destruction of threads will take time, which will not only consume system resources, but also reduce the stability of the system. In jdk1 There is an executor in the JUC package of 5, which can reuse the threads we create and will not create and destroy threads frequently.
Thread pool first creates some threads, and their collection is called thread pool. Using thread pool can improve performance. When the system starts, the thread pool creates a large number of idle threads. The program passes a task to the thread pool, and the thread pool will start a thread to execute the task. After execution, the thread will not die, but return to the thread pool to become idle again and wait for the execution of the next task.
No matter what it is, let's take a look at the time-consuming situation of using thread pool and new Thread():
public class ThreadPoolTest {
static CountDownLatch latch = new CountDownLatch(100000);
static ExecutorService es = Executors.newFixedThreadPool(4);
public static void main(String[] args) throws InterruptedException {
long timeStart = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
newThread();
//executors();
}
latch.await();
System.out.println(System.currentTimeMillis() - timeStart);
es.shutdown();
}
/**
* Use thread pool
*/
public static void executors() {
es.submit(() -> {
latch.countDown();
});
}
/**
* Direct new
*/
public static void newThread() {
new Thread(() -> {
latch.countDown();
}).start();
}
}Copy code
For 100000 threads running at the same time, if using new takes time:
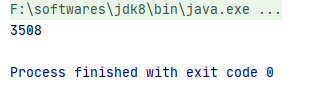
Time consuming to use thread pool:
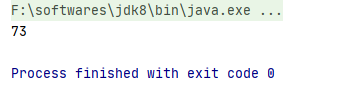
In general, rational use of thread pool can bring the following benefits:
- Reduce resource consumption. By reusing the created threads, the consumption caused by thread creation and destruction is reduced.
- Improve response speed. When the task arrives, the task can be executed immediately without waiting for the thread to be created.
- Increase the manageability of threads. Threads are scarce resources. Thread pool can be used for unified allocation, tuning and monitoring.
Thread pool design idea
Let's first understand the idea of thread pool. Even if you don't know what thread pool is again, you won't tell you a bunch of thread pool parameters as soon as you come up. I tried many ideas to explain its design idea, but they are too official. However, when looking for information, I saw a very easy to understand description on my blog. It is described as follows. First imagine the production process of a factory:
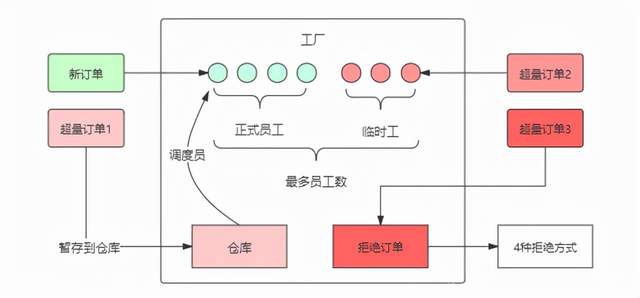
There is a fixed group of workers in the factory, called formal workers, who complete the orders received by the factory. When orders increase, regular workers are already too busy, and the factory will temporarily pile up production raw materials in the warehouse, Wait until there are free workers (because the workers are idle, they will not take the initiative to handle the production tasks in the warehouse, so the dispatcher needs to dispatch in real time). What if the warehouse is full, and the orders are still increasing? The factory can only temporarily recruit a group of workers to cope with the production peak, and these workers will be dismissed after the peak, so they are called temporary workers. At that time, the temporary workers were also called after the recruitment was full (limited by the station limit, there is an upper limit on the number of temporary workers), the subsequent orders can only be reluctantly rejected.
And thread pool are mapped as follows:
- Factory - thread pool
- Order - task (Runnable)
- Regular worker - core thread
- Temporary worker - normal thread
- Warehouse - task queue
- Dispatcher - getTask()
getTask() is a method to schedule tasks in the task queue to idle threads, and then learn from the source code analysis.
After mapping, a thread pool is formed. The flow chart is as follows:
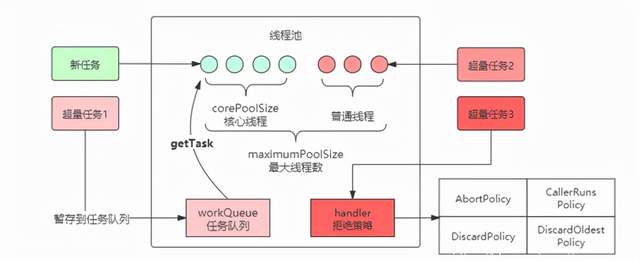
In depth Java thread pool: from design idea to source code interpretation
Working mechanism of thread pool
After understanding the design idea of the process pool, we can summarize the working mechanism of the process pool:
In the programming mode of thread pool, the task is submitted to the whole thread pool rather than directly to a thread. After getting the task, the thread pool looks for whether there are idle threads internally. If so, the task is handed over to an idle thread. If there are no idle threads, that is, the number of threads in the thread pool is greater than the core thread corePoolSize, the task will be added to the task queue. If the task queue is bounded and full, it will judge whether the number of threads in the thread pool is greater than the maximum number of threads. If less than, a new thread will be created to execute the task, Otherwise, the decision policy handler will be executed when there are no idle threads.
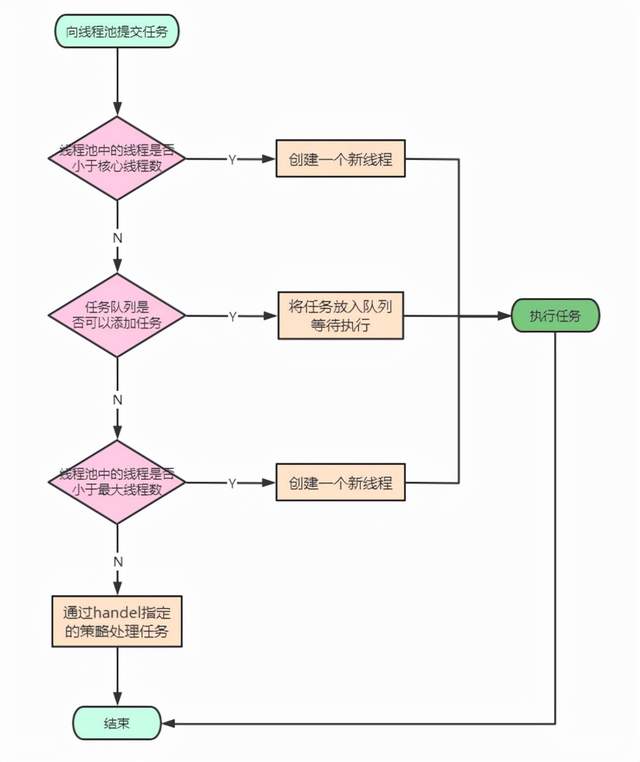
Note: there are no threads in the thread pool at first. When a task is submitted to the thread pool, the thread pool will create a new thread to execute the task. A thread can only execute one task at the same time, but it can submit multiple tasks to a thread pool at the same time.
Parameters and usage of thread pool
The real implementation class of thread pool is ThreadPoolExecutor. The integration relationship of the class is as follows:
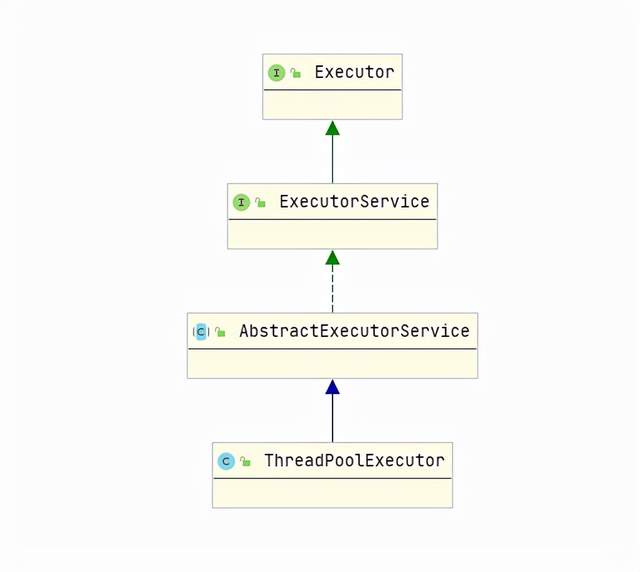
There are several construction methods of ThreadPoolExecutor. You can master the most important ones, including 7 parameters:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) Copy code
- corePoolSize (required), the number of core threads in the thread pool.
- When a task is submitted, the thread pool creates a new thread to execute the task until the current number of threads is equal to corePoolSize.
- If the current number of threads is less than corePoolSize, there are {idle threads at this time, and the submitted task will create a new thread to execute the task.
- If the current number of threads is equal to corePoolSize, the tasks that continue to be submitted are saved to the blocking queue and wait to be executed.
- If the thread pool {prestartAllCoreThreads() method is executed, the thread pool will create and start all core threads in advance.
- maximumPoolSize (required), the maximum number of threads allowed in the thread pool.
- When the queue is full and the number of threads created is less than maximumPoolSize, the thread pool will create new threads to perform tasks. In addition, for unbounded queues, this parameter can be ignored.
- keepAliveTime (required), thread survival hold time.
- The time that a thread continues to survive when no task is executed. By default, this parameter is only useful when the number of threads is greater than corePoolSize, that is, when a non core thread is idle for more than this time, the thread will be recycled. The core thread will also be recycled when the {allowCoreThreadTimeOut} parameter is set to {true}.
- Unit (required), the time unit of keepAliveTime.
- workQueue (required), task queue.
- A blocking queue used to hold tasks waiting to be executed. workQueue must be a BlockingQueue blocking queue. When the number of threads in the thread pool exceeds its corePoolSize, the thread will enter the blocking queue and wait for blocking.
- Generally speaking, we should try to use bounded queues, because using unbounded queues as work queues will have the following effects on the thread pool.
- When the number of threads in the thread pool reaches corePoolSize, the new task will wait in the unbounded queue, so the number of threads in the thread pool will not exceed corePoolSize.
- Because of 1, maximumPoolSize will be an invalid parameter when using unbounded queues.
- Because of 1 and 2, keepAliveTime will be an invalid parameter when using unbounded queues.
- More importantly, the use of unbounded queues may exhaust system resources, while bounded queues help to prevent resource depletion. At the same time, even if bounded queues are used, try to control the size of the queue in an appropriate range. It is generally used, such as ArrayBlockingQueue, LinkedBlockingQueue, synchronous queue, PriorityBlockingQueue, etc.
- threadFactory (optional) to create a factory for threads.
- Through the custom thread factory, you can set a thread name with recognition for each new thread. The thread created by threadFactory also adopts the method of "new Thread(). The thread names created by threadFactory have a unified style: pool-m-thread-n (M is the number of thread pool and N is the number of threads in thread pool).
- handler (optional), thread saturation policy.
- When the blocking queue is full and there are no idle worker threads, if you continue to submit a task, you must adopt a strategy to process the task. The thread pool provides four strategies:
- AbortPolicy, throw an exception directly, default policy.
- CallerRunsPolicy, which uses the thread of the caller to execute the task.
- DiscardOldestPolicy: discards the top task in the blocking queue and executes the current task.
- Discard policy, directly discard the task.
- Of course, you can also implement the {RejectedExecutionHandler} interface according to the application scenario to customize the saturation strategy, such as logging or tasks that cannot be handled by persistent storage.
Status of thread pool
ThreadPoolExecutor uses the upper 3 bits of int to indicate the thread pool status, and the lower 29 bits to indicate the number of threads:
The source code is as follows:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); private static final int COUNT_BITS = Integer.SIZE - 3;//29 private static final int CAPACITY = (1 << COUNT_BITS) - 1;//About 500 million // runState is stored in the high-order bits private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS;
Copy code
I think the main reason for this design is to avoid additional overhead. If two variables are used to represent the state and the number of threads respectively, additional locking operations must be carried out in order to ensure atomicity, and ctl solves this problem through atomic classes. The state and the number of threads can be obtained through bit operations.
Submit task
Two methods can be used to submit tasks to the thread pool: the execute() and submit() methods.
- execute() is used to submit a task that does not need a return value, so it is impossible to judge whether the task is successfully executed by the thread pool.
- submit() is used to submit tasks that require return values. The thread pool will return an object of type future. Through this future object, you can judge whether the task is successfully executed, and you can obtain the return value through the , get() method of future. The get() method will block the current thread until the task is completed, while the , get(long timeout, timeunit) method will block the current thread for a period of time and return immediately, At this time, it is possible that the task has not been completed.
In addition, ExecutorService , also provides two methods to submit tasks, invokeAny() and , invokeAll().
- invokeAny(), submit all tasks. Which task is successfully executed first, return the execution result of this task, and cancel other tasks.
- invokeAll(), submit all tasks and complete them.
corePoolSize and maximumPoolSize
The number of test core threads is 1, the maximum number of threads is 2, and the task queue is 1.
@Slf4j(topic = "ayue")
public class ThreadExecutorPoolTest1 {
public static void main(String[] args) {
ThreadPoolExecutor executor =
new ThreadPoolExecutor(1, 2, 3, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1));
for (int i = 1; i < 4; i++) {
//Perform tasks
executor.execute(new MyTask(i));
}
}
//task
static class MyTask implements Runnable {
private int taskNum;
public MyTask(int num) {
this.taskNum = num;
}
@Override
public void run() {
log.debug("Thread Name:{},Executing task: {}", Thread.currentThread().getName(), taskNum);
try {
//Simulate other operations
Thread.currentThread().sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("task{}completion of enforcement", taskNum);
}
}
}Copy code
Output:
<code data-type="codeline">11:07:04.377 [pool-1-thread-2] DEBUG ayue - Thread Name: pool-1-thread-2,Executing task: 3</code><code data-type="codeline">11:07:04.377 [pool-1-thread-1] DEBUG ayue - Thread Name: pool-1-thread-1,Executing task: 1</code><code data-type="codeline">11:07:05.384 [pool-1-thread-2] DEBUG ayue - task3 completion of enforcement</code><code data-type="codeline">11:07:05.384 [pool-1-thread-1] DEBUG ayue - task1 completion of enforcement</code><code data-type="codeline">11:07:05.384 [pool-1-thread-2] DEBUG ayue - Thread Name: pool-1-thread-2,Executing task: 2</code><code data-type="codeline">11:07:06.397 [pool-1-thread-2] DEBUG ayue - task2 completion of enforcement</code>
Copy code
When three threads execute tasks through the thread pool, because there is only one core thread and the task queue is 1, when the third thread arrives, a new thread pool-1-thread-2 will be restarted to execute tasks.
Of course, someone here may ask whether the core thread will be greater than the maximum thread? Of course not. If corepoolsize > maximumpoolsize, an error will be reported directly when the program starts.
Task queue
The task queue is implemented based on the blocking queue, that is, the producer consumer mode is adopted, and the {BlockingQueue} interface needs to be implemented in Java. However, Java has provided us with seven implementations of blocking queues:
- ArrayBlockingQueue: a bounded blocking queue composed of an array structure.
- LinkedBlockingQueue: a bounded blocking queue composed of a linked list structure. When the capacity is not specified, the capacity defaults to integer MAX_ VALUE .
- PriorityBlockingQueue: an unbounded blocking queue that supports prioritization. It has no requirements for elements. It can implement the Comparable interface or provide a Comparator to compare the elements in the queue. It has nothing to do with time. It just takes tasks according to priority.
- DelayQueue: similar to PriorityBlockingQueue, it is an unbounded priority blocking queue implemented by binary heap. All elements are required to implement the Delayed interface. Tasks are extracted from the queue through execution delay. Tasks cannot be retrieved before the time is up.
- SynchronousQueue: a blocking queue that does not store elements. Blocking occurs when the consumer thread calls the take() method. Until a producer thread produces an element, the consumer thread can get the element and return it; When the producer thread calls the {put() method, blocking will also occur. The producer will not return until a consumer thread consumes an element.
- LinkedBlockingDeque: a bounded two terminal blocking queue implemented using a two-way queue. Double ended means that it can be FIFO (first in first out) like an ordinary queue or FILO (first in first out) like a stack.
- LinkedTransferQueue: it is a combination of concurrent linkedqueue, LinkedBlockingQueue and synchronous queue, but it is used in ThreadPoolExecutor. It has the same behavior as LinkedBlockingQueue, but it is an unbounded blocking queue.
Thread factory
The default thread name created by the thread factory is pool-m-thread-n, which is in the
Executors.defaultThreadFactory() can see:
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" + poolNumber.getAndIncrement() + "-thread-";
}
public Thread newThread(Runnable r) {
//Thread Name: nameprefix + threadnumber getAndIncrement()
Thread t = new Thread(group, r, namePrefix + threadNumber.getAndIncrement(),0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}Copy code
We can also customize the thread name through {ThreadPoolExecutor}:
@Slf4j(topic = "ayue")
public class ThreadExecutorPoolTest1 {
public static void main(String[] args) {
//Self incrementing thread id
AtomicInteger threadNumber = new AtomicInteger(1);
ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 2, 3, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1), new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "javatv-" + threadNumber.getAndIncrement());
}
});
for (int i = 1; i < 4; i++) {
executor.execute(new MyTask(i));
}
}
static class MyTask implements Runnable {
private int taskNum;
public MyTask(int num) {
this.taskNum = num;
}
@Override
public void run() {
log.debug("Thread Name:{},Executing task: {}", Thread.currentThread().getName(), taskNum);
try {
//Simulate other operations
Thread.currentThread().sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("task{}completion of enforcement", taskNum);
}
}
}Copy code
Output:
<code data-type="codeline">14:08:07.166 [javatv-1] DEBUG ayue - Thread Name: javatv-1,Executing task: 1</code><code data-type="codeline">14:08:07.166 [javatv-2] DEBUG ayue - Thread Name: javatv-2,Executing task: 3</code><code data-type="codeline">14:08:08.170 [javatv-1] DEBUG ayue - task1 completion of enforcement</code><code data-type="codeline">14:08:08.170 [javatv-2] DEBUG ayue - task3 completion of enforcement</code><code data-type="codeline">14:08:08.170 [javatv-1] DEBUG ayue - Thread Name: javatv-1,Executing task: 2</code><code data-type="codeline">14:08:09.172 [javatv-1] DEBUG ayue - task2 completion of enforcement</code>
Copy code
Reject policy
Thread pools provide four strategies:
- AbortPolicy, throw an exception directly, default policy.
- CallerRunsPolicy, which uses the thread of the caller to execute the task.
- DiscardOldestPolicy: discards the top task in the blocking queue and executes the current task.
- DiscardPolicy, directly discarding the task
If you change the number of cycles of the above code to 4, an exception will be thrown
java.util.concurrent.RejectedExecutionException.
for (int i = 1; i < 5; i++) {
executor.execute(new MyTask(i));
}Copy code
Close thread pool
You can close the thread pool by calling the thread pool's {shutdown} or {shutdown now} methods. Their principle is to traverse the working threads in the thread pool, and then call the thread's interrupt method one by one to interrupt the thread, so the task that cannot respond to the interrupt may never be terminated. However, there are some differences between them. Shutdown now first sets the state of the thread pool to shutdown, then attempts to STOP all threads executing or pausing tasks and return to the list of tasks waiting to be executed. Shutdown only sets the state of the thread pool to shutdown, and then interrupts all threads not executing tasks. In short:
- shutdown(): when the thread pool state changes to SHUTDOWN, new tasks will not be received, but the submitted tasks will be completed and the execution of the calling thread will not be blocked.
- Shutdown now(): when the thread pool status changes to STOP, it will receive new tasks, return the tasks in the queue, and interrupt the executing tasks in the way of interrupt.
The isShutdown method returns true whenever either of the two shutdown methods is called. When all tasks have been closed, it indicates that the thread pool has been closed successfully. At this time, calling the {isTerminaed method will return true. As for which method should be called to close the thread pool, it should be determined by the task characteristics submitted to the thread pool. Usually, call the {shutdown} method to close the thread pool. If the task does not have to be completed, you can call the} shutdown now} method.
Executors static factory
Executors, which provides a series of static factory methods for creating various types of thread pools, is based on ThreadPoolExecutor.
- FixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}Copy code
Features: the number of core threads is equal to the maximum number of threads, so there is no need for timeout. It is recycled immediately after execution. The blocking queue is unbounded, and any number of tasks can be put.
Scenario: applicable to tasks with known amount of tasks and relatively time-consuming.
- newCachedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}Copy code
You can create a thread pool for new threads as needed. If there are no existing threads available, create a new thread and add it to the pool. If there are threads that have been used but have not been destroyed, reuse the thread. Terminate and remove threads from the cache that have not been used for 60 seconds. Therefore, a thread pool that remains idle for a long time will not use any resources. This thread pool is flexible. For programs that perform many short-term asynchronous tasks, these thread pools can usually improve program performance.
Features: the number of core threads is 0, and the maximum number of threads is integer MAX_ Value, all of which are collected by idle threads after 60s.
Scenario: perform a large number of tasks that take less time.
- newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}Copy code
Features: single thread pool. Multiple tasks are expected to be queued for execution. The number of threads is fixed to 1. When the number of tasks is more than 1, they will be queued in an unbounded queue. After the task is executed, the only thread will not be released.
Scenario: it is different from creating a single thread serial execution task. If the {new Thread} task fails to execute and terminates, there is no remedy, and a new Thread will be created in the thread pool to ensure the normal operation of the pool.
- ScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}Copy code
ScheduledThreadPoolExecutor inherits from ThreadPoolExecutor. It is mainly used to run tasks after a given delay, or to execute tasks regularly. The function of ScheduledThreadPoolExecuto is similar to that of timer, but ScheduledThreadPoolExecutor is more powerful and flexible. Timer corresponds to a single background thread, while ScheduledThreadPoolExecutor can specify multiple corresponding background threads in the constructor.
Features: the number of core threads is fixed, and the number of non core threads is unlimited. It is recovered after idle for 10ms. The task queue is a delay blocking queue.
Scenario: perform scheduled or periodic tasks.
Reasonably configure thread pool
It needs to be handled according to specific conditions. Different task categories should adopt thread pools of different sizes. Task categories can be divided into CPU intensive tasks, IO intensive tasks and hybrid tasks.
- CPU intensive tasks: the number of threads in the thread pool should be as few as possible and should not be greater than the number of CPU cores;
- IO intensive tasks: since the IO operation speed is much lower than the CPU speed, the CPU is idle most of the time when running such tasks, so the thread pool can be configured with as many threads as possible to improve CPU utilization;
- Hybrid tasks: they can be divided into CPU intensive tasks and IO intensive tasks. When the execution time of these two types of tasks is almost the same, the throughput of splitting and re execution is higher than that of serial execution. However, if there is a data level difference in the execution time of these two types of tasks, there is no significance of splitting.
Thread pool monitoring
If the thread pool is widely used in the system, it is necessary to monitor the thread pool to quickly locate the problem according to the usage of the thread pool. The parameters provided by the thread pool are used for monitoring. The parameters are as follows:
- taskCount: the number of tasks to be executed by the thread pool.
- completedTaskCount: the number of tasks completed by the thread pool during running, which is less than or equal to taskCount.
- largestPoolSize: the maximum number of threads that have been created in the thread pool. This data can be used to know whether the thread pool is full. If it is equal to the maximum size of the thread pool, it indicates that the thread pool has been full.
- getPoolSize: number of threads in the thread pool. If the thread pool is not destroyed, the threads in the pool will not be destroyed automatically, so this size only increases.
- getActiveCount: gets the number of active threads.
Monitor by extending the thread pool: inherit the thread pool and override the , beforeExecute(), afterExecute() and , terminated() methods of the thread pool. You can customize the behavior before and after task execution and before the thread pool is closed. Such as average execution time, maximum execution time and minimum execution time of monitoring tasks.
Source code analysis
When using thread pool, I actually have some problems, such as how to create threads in thread pool? How is the task performed? How are tasks assigned? What happens after the thread is executed? Is it survival or death? When did you die? Why use blocking queues and so on. With these questions, let's read the source code. How to start reading the source code? Through the {execute() method of} ThreadPoolExecutor. The submit underlying layer also calls execute().
execute
public void execute(Runnable command) {
//If there is no task, throw an exception directly
if (command == null)
throw new NullPointerException();
//Get the status of current thread + number of threads
int c = ctl.get();
/**
* workerCountOf,The number of threads in the thread pool, and judge whether it is less than the number of core threads
*/
if (workerCountOf(c) < corePoolSize) {//If less than
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
// Here is the second check of the running status of the thread pool after the task is successfully placed in the task queue
// If the thread pool secondary check status is non running, remove the current task from the task queue and invoke the rejection policy processing (that is, remove the previously successfully queued task instances)
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
/* Go to the else if branch below to explain the following preconditions:
* 1,The task to be executed has been successfully added to the task queue
* 2,The thread pool may be RUNNING
* 3,The incoming task may fail to be removed from the task queue (the only possibility of removal failure is that the task has been executed)
*
* If the current number of worker threads is 0, a non core thread is created and the passed in task object is null - return
* That is, the created non core thread will not run immediately, but wait for the task that obtains the task queue to execute
* If the number of previous worker threads is not 0, it should be the last else branch, but you can do nothing,
* Because the task has been successfully queued, there will always be an appropriate time to allocate other idle threads to execute it.
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
/* Here is the premise:
* 1,The total number of worker threads in the thread pool has been greater than or equal to corePoolSize (in short, all core threads have been created)
* 2,The thread pool may not be RUNNING
* 3,The thread pool may be RUNNING and the task queue is full
*
* If dropping a task to the task queue fails, an attempt is made to create a non core thread to pass in the task for execution
* Failed to create a non core thread. You need to refuse to execute the task at this time
*/
else if (!addWorker(command, false))
reject(command);
}Copy code
addWorker
The first if determines whether the number of threads in the thread pool is less than the number of core threads.
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}Copy code
If less than, enter the addWorker method:
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
//Outer loop: judge thread pool status
for (;;) {
int c = ctl.get();
//Get thread pool status
int rs = runStateOf(c);
// Check whether the thread pool state is alive
if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty()))
return false;
//Inner loop: add the core thread to the thread pool and return the result of whether the addition is successful
for (;;) {
//Number of threads
int wc = workerCountOf(c);
//If the number of threads exceeds the capacity, false is returned
if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//CAS increases the number of threads and jumps out of the outer loop if successful
if (compareAndIncrementWorkerCount(c))
break retry;
//Otherwise, fail and update c
c = ctl.get(); // Re-read ctl
//If the thread pool state changes at this time, spin the outer loop again
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
//If CAS succeeds, move on
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//Create a Worker that implements Runable and regards it as a task unit
w = new Worker(firstTask);
//This Thread is the current task unit Worker, that is, this
final Thread t = w.thread;
if (t != null) {
//Lock, because there may be multiple threads to call
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Check the status of the thread pool again, avoid calling the shutdown method before getting the lock.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) {
//If the t thread has been started but not terminated, an exception is thrown
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//Otherwise, join the thread pool
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//After joining the thread pool, start the thread, which has been set to true
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
//If the thread fails to start, addWorkerFailed is called to roll back the operation
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}Copy code
Worker
Worker is an internal class of ThreadPoolExecutor, which inherits AQS and implements Runnable.
private final class Worker extends AbstractQueuedSynchronizer implements Runnable{
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
//Construction method
Worker(Runnable firstTask) {
//Disable interrupts before calling runWorker
//When other threads call the shutdown now of the thread pool, if the worker status > = 0, the thread will be interrupted
//The specific method can be seen in interruptIfStarted()
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
//Omit other code
}Copy code
It can be seen from the Worker's construction method that the thread attribute is created through this. Therefore, the creation of the core thread of the thread pool is mainly the "runWorker" method in the run method:
runWorker
The runWorker core thread executes logic.
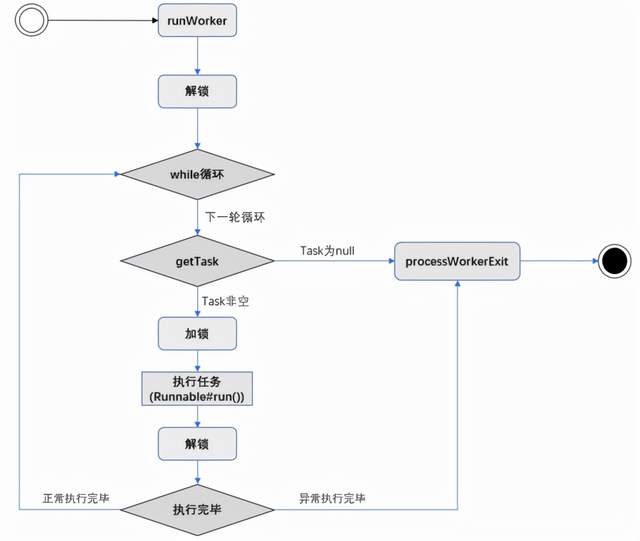
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
// unlock() is called to allow external interrupts
w.unlock(); // allow interrupts
// The reason why the thread exits. true is caused by the task, and false is caused by the normal exit of the thread
boolean completedAbruptly = true;
try {
// 1. If firstTask is not null, execute firstTask
// 2. If firstTask is null, call getTask() to get the task from the queue
// 3. The characteristic of blocking queue is that when the queue is empty, the current thread will be blocked and wait
while (task != null || (task = getTask()) != null) {
w.lock();
// Judge the status of the thread pool. If the thread pool is stopping, interrupt the current thread
if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted())
wt.interrupt();//interrupt
try {
//There is no content in this method. You can extend it yourself, such as the thread pool monitoring mentioned above
beforeExecute(wt, task);
Throwable thrown = null;
try {
//Perform specific tasks
task.run();
} catch (RuntimeException x) {//Operation after thread exception
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//Same as beforeExecute()
afterExecute(task, thrown);
}
} finally {
task = null;//help gc
//Count how many tasks the current worker has completed
w.completedTasks++;
//Release lock
w.unlock();
}
}
completedAbruptly = false;
} finally {
// The processing thread exits. Completedabortly is true, indicating that the thread exits abnormally due to task exceptions
processWorkerExit(w, completedAbruptly);
}
}Copy code
getTask
For the getTask() method, the tasks in the task queue are scheduled to idle threads. This method is very important. Why is it important? It involves the thread pool often asked by interviewers. How to ensure that the core thread will not be destroyed and the idle thread will be destroyed?
private Runnable getTask() {
//Judge whether the latest poll timed out
//poll: remove the first object in the BlockingQueue
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
/**
* Condition 1: thread pool status SHUTDOWN, STOP, TERMINATED
* Condition 2: thread pool STOP, TERMINATED status or workQueue is empty
* If both condition 1 and condition 2 are true, then workerCount-1 and null will be returned
* Note: condition 2 is that the thread pool in SHUTDOWN state will not accept tasks, but will still process tasks (mentioned earlier)
*/
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
/*
* This attribute is used to judge whether the current thread allows timeout:
* 1.allowCoreThreadTimeOut
* If false (default), the core thread remains active even when idle.
* If true, the core thread uses keepAliveTime timeout to wait for work.
* 2.wc > corePoolSize
* Whether the current thread has exceeded the number of core threads.
*/
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
/*
* Determine whether the current thread can exit:
* 1.wc > maximumPoolSize || (timed && timedOut)
* wc > maximumPoolSize = true,Indicates that the current total number of worker threads is greater than the maximum number of threads in the thread pool.
* timed && timedOut = true,Indicates that the current thread allows timeout and has timed out.
* 2.wc > 1 || workQueue.isEmpty()
* If the total number of working threads is greater than 1 or the task queue is empty, subtract 1 from the number of threads through CAS and return null
*/
if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
/*
* 1.poll(long timeout, TimeUnit unit): Take out an object of the head of the queue from the BlockingQueue,
* If there is data available in the queue within the specified time, the data in the queue will be returned immediately. Otherwise, no data is available until the time expires, and failure is returned.
*
* 2.take():Remove the first object in the BlockingQueue. If the BlockingQueue is empty, the block will enter the waiting state until new data is added to the BlockingQueue.
*
*
* If timed is true, pull the timeout through the poll() method. If no valid task is waiting within the keepAliveTime time, null is returned.
*
* If timed is false, blocking pull through take() will block and return when there is the next valid task (generally not null).
*/
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
//Pull the task from the task queue through the poll() method, which is null
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}Copy code
① For the code below getTask(), this logic is mostly for non core threads:
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}Copy code
② Let's read this code in this way. When the number of working threads is greater than the core thread {corePoolSize, enter the second if statement in the} execute() method:
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}Copy code
At this time, the total number of thread pools has exceeded , corePoolSize , but less than , maximumPoolSize. When the task queue is full, non core threads will be added through , addWorker(task,false).
In the case of high concurrency, redundant threads will certainly be generated, that is, in the case of ①, @ WC > maximumpoolsize. What about these redundant threads? Will they be recycled? If workqueue Poll , if no valid task is obtained, the logic in ① is just opposite to , addWorker(task,false). Reduce non core threads through CAS, so that the total number of working threads tends to , corePoolSize.
For non core threads, if the task object obtained in the previous round of loop is "null", by default, @ allowCoreThreadTimeOut = false. Therefore, @ timed = true in getTask(). If the task is not obtained, then, @ timed out = true. This round of loop can easily meet the requirement that "timed & & timed out" is true, At this time, if #getTask() returns null, the Worker#runWorker() method will jump out of the loop, and then the #processWorkerExit() method will be executed to process the subsequent work, while the # Worker # corresponding to the non core thread will become a # free object waiting to be recycled by the JVM.
When allowCoreThreadTimeOut is set to true, the life cycle end logic of non core threads analyzed here will also apply to core threads.
This leads to an interview question: if there are multiple threads in the thread pool that do not get tasks at the same time, will they all be recycled?
For example, the number of core threads in the thread pool is 5, the maximum number of threads is 5, and the current number of working threads is 6 (6 > 5, which means that thread recycling can be triggered). If three threads timeout at the same time and fail to obtain tasks, will all three threads be recycled and destroyed?
Idea: the core of this problem is that multiple threads timeout at the same time and can't get the task. Under normal circumstances, the process of thread recycling will be triggered. However, we know that when the allowCoreThreadTimeOut variable is not set normally, the thread pool will maintain the number of core threads even if there is no task processing. If all three threads here are recycled, the number of threads will become 3, which does not meet the number of core threads. Therefore, we can get the answer first: not all threads will be recycled. At this time, the interviewer will certainly ask why?
According to the answer, it is not difficult to speculate that in order to prevent the problem of concurrent recycling, the process of thread recycling must have concurrency control.
compareAndDecrementWorkerCount(c) uses the CAS method. If CAS fails, continue to enter the next cycle and re judge.
Like the above example, one of the threads will fail CAS, and then re-enter the loop. It is found that the number of working threads is only 5 and timed = false. This thread will not be destroyed and can be blocked all the time. At this time, it will call} workqueue Take () blocks the task waiting for the next time, that is, the core thread will not die.
It can also be seen from here that although there are core threads, threads do not distinguish whether they are core or non core. It is not the core that is created first, and the non core that is created after exceeding the number of core threads. Which threads are retained in the end is completely random.
Then you can answer the previous question, how does the thread pool ensure that the core thread will not be destroyed and the idle thread will be destroyed?
The core thread will not be destroyed because it calls the blocking method. The idle thread calls the timeout method and dies because it cannot get the task in the next execution.
In fact, this answer is OK, but it may show that you memorize octets, so you should answer that the core thread will not be destroyed not only because the blocking method is called, but also by using CAS.
It can also be concluded that getTask() returns null:
- The status of the thread pool is already STOP, TIDYING, TERMINATED, or SHUTDOWN, and the work queue is empty.
- The number of worker threads is greater than the maximum number of threads or the current worker thread has timed out and its existing worker thread or task queue is empty.
Process of runWorker:
processWorkerExit
In the finally block of runWorker, after the task is executed, it needs to be processed. The working thread will not be truly terminated until it executes the {processWorkerExit() method. The method is as follows:
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// Because throwing a user exception causes the thread to terminate, you can directly reduce the number of working threads by 1
// If there is no exception thrown, the boot thread will normally jump out of the while loop of the runWorker() method by returning null through getTask(). In this case, the number of threads has been reduced by 1 in getTask()
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// The number of global completed task records plus the number of completed tasks in this Worker to be terminated
completedTaskCount += w.completedTasks;
// Remove this Worker to be terminated from the Worker thread collection
workers.remove(w);
} finally {
mainLock.unlock();
}
// See the analysis in the next section to determine whether thread pool terminate processing is required according to the current thread pool status
tryTerminate();
int c = ctl.get();
// If the status of the thread pool is less than STOP, that is, if it is in RUNNING or SHUTDOWN status:
// 1. If the thread is not terminated by throwing a user exception, if the core thread is allowed to timeout, keep at least one worker thread in the thread pool
// 2. If the thread terminates due to throwing a user exception, or the current number of working threads, directly add a new non core thread
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
// If the core thread is allowed to time out, the minimum value is 0, otherwise it is corePoolSize
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
// If the minimum value is 0 and the task queue is not empty, the update minimum value is 1
if (min == 0 && ! workQueue.isEmpty())
min = 1;
// If the number of working threads is greater than or equal to the minimum value, return directly without adding new non core threads
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}Copy code
The latter part of the code will judge the status of the thread pool. If the thread pool is in the "RUNNING" or "SHUTDOWN" status, if the current working thread is terminated due to throwing an exception, a new non core thread will be created. If the current worker thread is terminated (normally terminated) instead of throwing a user exception, it will be handled as follows:
- allowCoreThreadTimeOut = true, that is, on the premise of allowing the core thread to timeout, if the task queue is empty, at least one worker thread in the thread pool will be maintained by creating a non core thread.
- allowCoreThreadTimeOut is false. If the total number of working threads is greater than △ corePoolSize, it will be returned directly. Otherwise, a non core thread will be created, that is, the number of working threads in the thread pool will tend to be △ corePoolSize.
After processWorkerExit() is executed, it means that the life cycle of the worker thread is over.
Interview questions
1. How to create threads in a thread pool? How is the task performed?
It mainly consists of the {Worker} class and the} Worker#runWorker() method.
2. How are tasks assigned?
Refer to the getTask() method.
3. How does the thread pool ensure that the core thread will not be destroyed and the idle thread will be destroyed?
Refer to above.
4. If multiple threads in the thread pool fail to get tasks at the same time, will they all be recycled?
Refer to above.
5. Why use blocking queues?
Thread pool is designed in producer consumer mode. Thread pool is consumer.
When the number of active threads in the thread pool reaches the corePoolSize, the thread pool will submit subsequent tasks to the BlockingQueue (each task is a separate producer thread) and enter the blocking pair. The task thread in the column will wait() to release the cpu, so as to improve the cpu utilization.