More wonderful articles, pay attention to the public account [tobetopjava Er], more tens of thousands of excellent vip resources for free waiting for you to take!!!
Next, we will analyze the basic type of Hash. I'm sure you are familiar with Hash. Next, we will go deep into the source code to analyze the implementation of Hash in Redis.
First let's look at a picture:
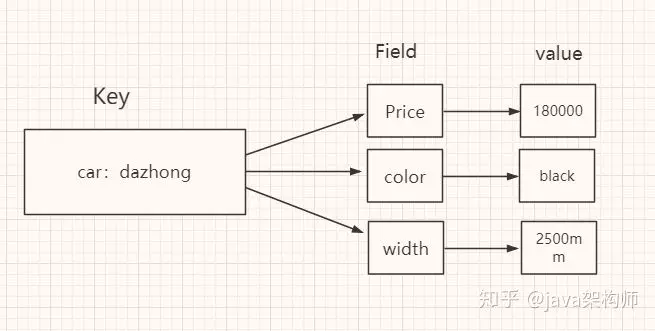
Storage type
Unordered hash with key value pairs. Value can only be a string and cannot nest other types.
Also store String. What's the main difference between Hash and String?
1. Gather all related values into one key to save memory space
2. Use only one key to reduce key conflicts
3. When it is necessary to obtain values in batches, only one command is needed to reduce the consumption of memory / IO/CPU.
Scenes not suitable for Hash:
1. Field cannot set expiration time separately
2. No bit operation
3. The problem of data quantity distribution needs to be considered (when the value value is very large, it cannot be distributed to multiple nodes)
Operation command

Storage (Implementation) principle
Redis's Hash itself is a KV structure, similar to the HashMap in Java.
The outer hash (Redis KV Implementation) only uses hashtable. When storing hash data types,
We call it the inner hash. There are two data structures used to implement the hash bottom layer of the inner layer:
ziplist: Obj? Encoding? Zip list
hashtable: Obj? Encoding? HT (hash table)
As shown in the figure below:
Question 1. When will ziplist and hashtable be used?
In redis.conf, we can see:
In the source code:
/* Source location: t_hash.c. when the number of fields reaches the threshold value, use HT as the code. */ if (hashTypeLength(o) > server.hash_max_ziplist_entries) hashTypeConvert(o, OBJ_ENCODING_HT); /*Source location: t_hash.c. when the field value length is too large, it will be changed to HT. */ for (i = start; i <= end; i++) { if (sdsEncodedObject(argv[i]) && sdslen(argv[i]->ptr) > server.hash_max_ziplist_value) { hashTypeConvert(o, OBJ_ENCODING_HT); break; } }Copy code
So we can know that ziplist encoding is used when the hash object satisfies the following two conditions at the same time:
1) the string length of key and value of all key value pairs is less than or equal to 64byte (one English letter)
One byte);
2) the number of key value pairs saved by hash object is less than 512.
When a hash object exceeds the configured threshold (the length of key and value is > 64BYTE, and the number of key value pairs is > 512).
It will be converted to a hashtable.
Question 2: what is ziplist compressed list
ziplist compressed list
What is a ziplist compressed list?
ziplist is a specially encoded two-way linked list, which does not store nodes pointing to the previous linked list or the next linked list.
The pointers of the linked list nodes store the length of the previous node and the current node, by sacrificing part of the read-write performance.
In exchange for efficient memory space utilization, it is a time for space idea. Only when the number of fields is small, the field value
In a small scene.
The internal structure of ziplist?
The overall structure is as follows:
The source code of entry object definition is as follows:
typedef struct zlentry { unsigned int prevrawlensize; /* Length occupied by the last linked list node */ unsigned int prevrawlen; /* The number of bytes required to store the length value of the last linked list node */ unsigned int lensize; /* The number of bytes required to store the current link node length value */ unsigned int len; /* Length occupied by current linked list node */ unsigned int headersize; /* The head size of the current linked list node (prevrawlensize + lensize), that is, the size of non data fields */ unsigned char encoding; /* Coding mode */ unsigned char *p; /* The compressed list is saved in the form of a string, and the pointer points to the starting position of the current node. */ } zlentry;Copy code
What is hashtable (dict)?
What is hashtable?
In Redis, hashtable is called dictionary, which is an array + linked list structure.
As we know earlier, the KV structure of Redis is implemented through a dictEntry.
Redis encapsulates dictEntry in multiple layers.
dictEntry is defined as follows:
typedef struct dictEntry { void *key; /* key Key definition */ union { void *val; uint64_t u64; /* value Definition */ int64_t s64; double d; } v; struct dictEntry *next; /* Point to the next key value pair node */ } dictEntry Copy code
dictEntry is placed in dictht (hashtable):
/* This is our hash table structure. Every dictionary has two of this as we * implement incremental rehashing, for the old to the new table. */ typedef struct dictht { dictEntry **table; /* Hash table array */ unsigned long size; /* Hash table size */ unsigned long sizemask; /* Mask size used to calculate the index value. Always equal to size-1 */ unsigned long used; /* Number of existing nodes */ } dictht;Copy code
dictht is placed in dict:
typedef struct dict { dictType *type; /* Dictionary type */ void *privdata; /* Private data */ dictht ht[2]; /* A dictionary has two hash tables */ long rehashidx; /* rehash Indexes */ unsigned long iterators; /* Number of iterators currently in use */ } dict;Copy code
dictEntry from the lowest layer to the highest layer -- dictht -- dict -- obj ﹣ encoding ﹣ HT
The overall storage structure of hash is as follows:

Note: NULL after dictht indicates that the second ht has not been used. NULL after dictEntry * indicates that there is no hash to this address. NULL after dictEntry indicates no hash conflict.
Question 3. Why define two hash tables? ht[2]?
The hash of redis uses ht[0] by default, and ht[1] does not initialize and allocate space.
The hash table dictht uses the chain address method to solve the collision problem. In this case, the performance of the hash table depends on the ratio between its size (size attribute) and the number of nodes it holds (used attribute):
1. When the ratio is 1:1 (only one node entry is stored in a hash table ht), the performance of hash table is the best.
2. If the number of nodes is much larger than the size of the hash table (this ratio is represented by ration, 5 means that an average ht stores 5 entries), then the hash table will degenerate into multiple linked lists, and the performance advantage of the hash table itself will no longer exist.
In this case, the capacity needs to be expanded. This operation in Redis is called rehash.
1. Allocate space for the character ht[1] hash table. The size of the hash table depends on the operation to be performed and the number of key value pairs currently contained in ht[0].
Extension: the size of ht[1] is the first one greater than or equal to ht[0].used*2.
2. rehash all nodes on ht[0] to ht[1], recalculate the hash value and index, and then put them in the specified location.
3. After ht[0] is migrated to ht[1], free up the space of ht[0], set ht[1] to ht[0] table, and create a new ht[1] to prepare for the next rehash.
Question 4. When will capacity expansion be triggered?
Key factor: load factor
The definition source code is as follows:
static int dict_can_resize = 1; static unsigned int dict_force_resize_ratio = 5;Copy code
ratio = used / size, the ratio of used nodes to dictionary size.
The ratio between the number of used nodes and the size of dictionary exceeds 1:5, triggering the expansion.
The source code of "dictExpandIfNeeded" is as follows:
if (d->ht[0].used >= d->ht[0].size &&(dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) { return dictExpand(d, d->ht[0].used*2); }r eturn DICT_OK;Copy code
The source code of the expansion method dictExpand is as follows:
static int dictExpand(dict *ht, unsigned long size) { dict n; /* the new hashtable */ unsigned long realsize = _dictNextPower(size), i; /* the size is invalid if it is smaller than the number of * elements already inside the hashtable */ if (ht->used > size) return DICT_ERR; _dictInit(&n, ht->type, ht->privdata); n.size = realsize; n.sizemask = realsize-1; n.table = calloc(realsize,sizeof(dictEntry*)); /* Copy all the elements from the old to the new table: * note that if the old hash table is empty ht->size is zero, * so dictExpand just creates an hash table. */ n.used = ht->used; for (i = 0; i < ht->size && ht->used > 0; i++) { dictEntry *he, *nextHe; if (ht->table[i] == NULL) continue; /* For each hash entry on this slot... */ he = ht->table[i]; while(he) { unsigned int h; nextHe = he->next; /* Get the new element index */ h = dictHashKey(ht, he->key) & n.sizemask; he->next = n.table[h]; n.table[h] = he; ht->used--; /* Pass to the next element */ he = nextHe; } }a ssert(ht->used == 0); free(ht->table); /* Remap the new hashtable in the old */ *ht = n; return DICT_OK; }Copy code
The shrink source code is as follows:
int htNeedsResize(dict *dict) { long long size, used; size = dictSlots(dict); used = dictSize(dict); return (size > DICT_HT_INITIAL_SIZE &&(used*100/size < HASHTABLE_MIN_FILL)); }Copy code
Application scenario
String
What String can do, Hash can do.
Store data of object type
For example, the data of an object or a table saves more key space than String, and is more convenient for centralized management.
Shopping Cart

key: user id;
field: Commodity id;
value: quantity of goods.
+1: hincr.
-1: hdecr.
Delete: hdel.
Select all: hgetall.
Number of products: hlen.
Today, we have analyzed the basic data type Hash from the underlying source code. Next, we will discuss the remaining common basic types in depth. Please look forward to it.