Indexing principle and slow query optimization
1. What is an index?
Index is a data structure in the storage engine, or the organization of data, also known as key. It is a data structure used by the storage engine to quickly find records. Building an index for data is like building a directory for a book, or creating a phonetic order table for a dictionary. If you want to look up a word, if you don't use a phonetic order table, you need to look it up page by page from hundreds of pages.
2. Why index
Index optimization should be the most effective means to optimize query performance. Indexing can easily improve query performance by several orders of magnitude.
3. Understand the reserve knowledge of the index
3.1 time of one IO of mechanical disk
Time of one io of mechanical disk = seek time + rotation delay + transmission time
-
Seek time
Seek time refers to the time required for the magnetic arm to move to the specified track. The mainstream disk is generally less than 5ms
-
Rotation delay
Rotation delay is the disk speed we often hear about. For example, 7200 revolutions of a disk means 7200 revolutions per minute, that is, 120 revolutions per second. The rotation delay is 1/120/2 = 4.17ms;
-
Transmission time
Transmission time refers to the time to read or write data from or to the disk, which is generally a few tenths of a millisecond, which is negligible relative to the first two times
Therefore, the time to access a disk, that is, the time to access a disk IO, is about 5+4.17 = 9ms
This 9ms may be very short for people, but it will be a very long time for computers. How long will it be? A 500 MIPS (Millennium instructions per second) machine can execute 500 Million Instructions Per Second, because the instructions depend on the nature of electricity. In other words, about 4.5 million instructions can be executed in the time of executing IO. The database is prone to 100000 or even tens of millions of data, and the time of 9 milliseconds each time is obviously a disaster.

3.2 disk read ahead
Considering that disk IO is a very expensive operation, the computer operating system has been optimized:
During an IO, not only the data of the current disk address is read, but also the adjacent data is read into the memory buffer, because the local pre reading principle tells us that when the computer accesses the data of an address, the adjacent data will also be accessed quickly. The data read by each IO is called a page. The specific data size of a page is related to the operating system, generally 4k or 8k, that is, when we read the data in a page, there is actually only one io. This theory is very helpful for the data structure design of the index.
3.3 index principle
The purpose of index is to improve query efficiency. It is the same as the directory we use to consult books: first locate the chapter, then locate a section under the chapter, and then find the number of pages.
Its essence is to filter out the final desired results by constantly narrowing the range of data to be obtained, and turn random events into sequential events. In other words, with this index mechanism, we can always lock the data in the same way.

4. Index classification
Index models fall into many categories
# ===========B + tree index (both equivalent query and range query are fast) Binary tree->balanced binary tree->B tree->B+tree # ===========HASH index (fast equivalent query and slow range query) Break up the data and then query # ==========FULLTEXT: full text index (can only be used in MyISAM engine) Query through keyword matching, similar to like Fuzzy matching of like + %It is appropriate when there is less text However, for a large number of text data, retrieval will be very slow Full text index can compare with a large amount of data like Much faster, but with low accuracy Baidu uses full-text index when searching articles, but it is more likely to be ES
Different storage engines support different index types
-
InnoDB storage engine
Supports transaction, row level locking, B-tree (default), full text and other indexes, and Hash indexes are not supported.
-
MyISAM storage engine
It does not support transactions, table level locking, B-tree, full text and other indexes, and Hash indexes.
-
Memory storage engine
Transaction, table level locking, B-tree, Hash and other indexes are not supported, and full text indexes are not supported.
The default storage engine of MySQL is InnoDB, and the index model / structure of InnoDB storage engine is B + tree, so we focus on B + tree

5. Data structure of index
There are four common data structures: binary lookup tree, balanced binary tree, B-number and B + number.
5.1 two steps to create an index
- Extract the value of the field of each row record and take the value as the key. What is the value of the key pair? Each index structure is different
- Then build the index structure based on the key value
# 1. Creating an index for the id field of the user table will generate an index structure based on the id field value of each record create index Index name on user(id); Use index select * from user where id = xxx; # 2. Creating an index for the name field of the user table will generate an index structure based on the name field value of each record create index Index name on user(id); Use index select * from user where name = xxx;
So what does the index structure look like to speed up queries?
The default index structure of InnoDB storage engine is B + tree, and B + tree evolved from binary tree, balanced binary tree, B tree and then B + tree.
5.2 binary lookup tree
Binary Search Tree, also known as ordered binary tree and sorted binary tree, refers to an empty tree or a binary tree with the following properties:
- If the left subtree of any node is not empty, the values of all nodes on the left subtree are less than those of its root node;
- If the right subtree of any node is not empty, the values of all nodes on the right subtree are greater than those of its root node;
- The left and right subtrees of any node are also binary search trees.
- There are no duplicate nodes with equal key values.
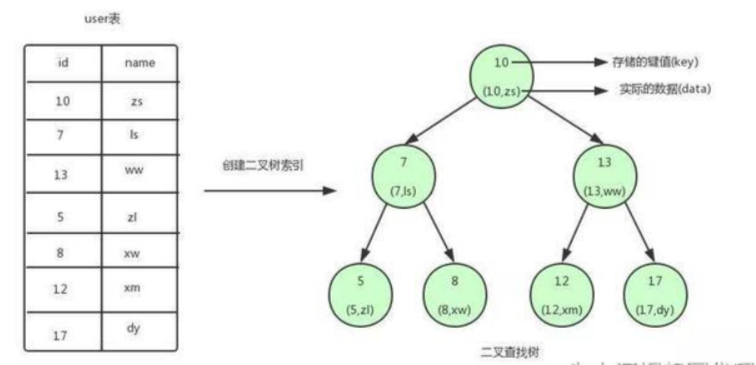
- Extract the id value of each record as the key value. Value is the complete record of the line, that is:
| id | user |
|---|---|
| 10 | zs |
| 7 | ls |
| 13 | ww |
| 5 | zl |
| 8 | xw |
| 12 | xm |
| 17 | dy |
- Build a binary tree based on the size of the key value, as shown in the figure above
The characteristic of binary search tree is that the key value of the left child node of any node is less than that of the current node, and the key value of the right child node is greater than that of the current node. The top node is called the root node, and the node without child nodes is called the leaf node. When we want to find the user information with id=12
The search process is as follows:
- Take the root node as the current node, and compare 12 with the key value 10 of the current node. 12 is greater than 10. Next, we take the right child node of the current node > as the current node.
- Continue to compare 12 with the key value 13 of the current node. It is found that 12 is less than 13. Take the left child node of the current node as the current node.
- Compare 12 with the key value 12 of the current node. 12 equals 12. If the conditions are met, we take data from the current node, that is, id = 1 > 2, name = XM.
Using binary search tree, we only need 3 times to find the matching data. If we search the table one by one, we need 6 times to find it.

5.3 balanced binary number
Based on the binary tree shown in the figure above, we can indeed find data quickly. However, let's go back to the characteristics of binary search tree. Only about binary search tree, its characteristics are: the key value of the left child node of any node is less than that of the current node, and the key value of the right child node is greater than that of the current node. Therefore, according to the characteristics of binary search tree, binary tree can be constructed in this way, as shown in Fig
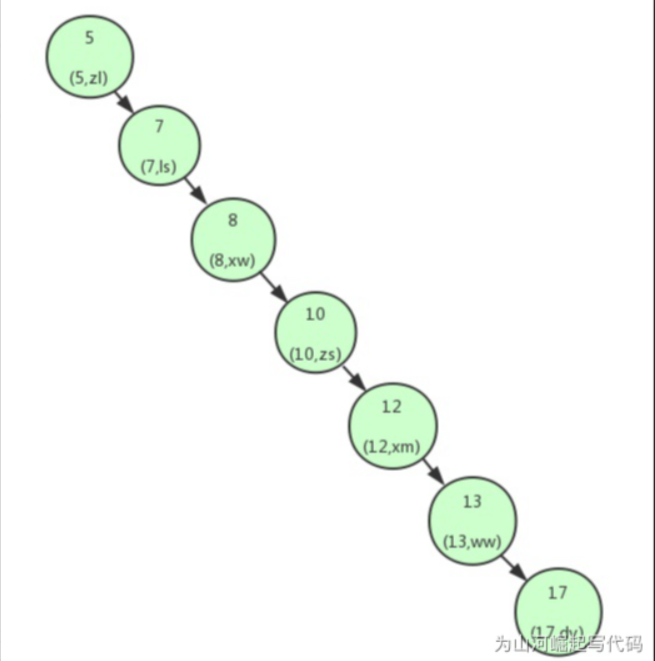
At this time, we can see that our binary lookup tree has become a linked list. If we need to find the user information with id=17, we need to find it seven times, which is equivalent to a full table scan. The reason for this phenomenon is that the binary search tree becomes unbalanced, that is, the height is too high, resulting in the instability of search efficiency.
In order to solve this problem, we need to ensure that the binary search tree is always balanced, so we need to use the balanced binary tree. Balanced binary tree is also called AVL tree. On the basis of meeting the characteristics of binary search tree, the height of left and right subtrees of each node shall not exceed 1. The following is a comparison between balanced and unbalanced binary trees:
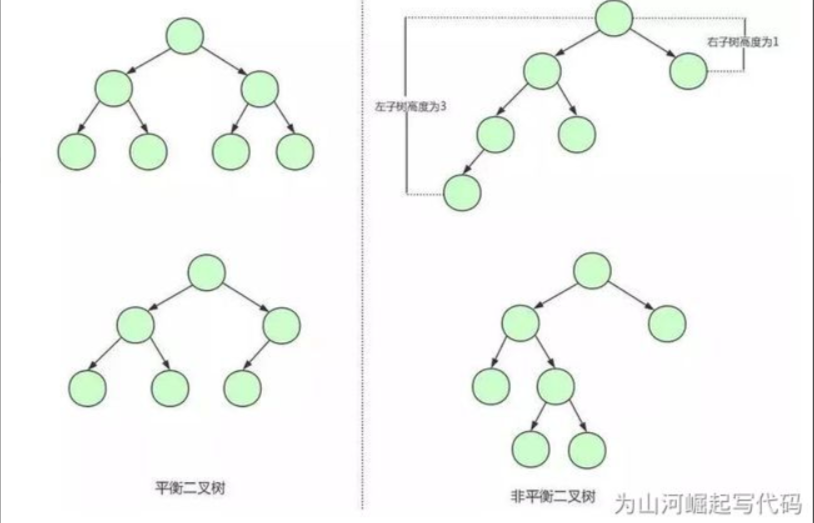
From the construction of balanced binary tree, we can find that the binary tree in the first figure is actually a balanced binary tree. The balanced binary tree ensures that the structure of the tree is balanced. When we insert or delete data, which leads to the imbalance of the balanced binary tree, the balanced binary tree will adjust the nodes on the tree to maintain the balance. Compared with binary search tree, balanced binary tree has more stable search efficiency and faster overall search speed.

5.4 B-tree
Balanced binary tree also has some shortcomings. First, because of the volatile memory. Generally, we will choose to store the data and indexes in the user table in a peripheral device such as disk. However, compared with memory, the speed of reading data from disk will be hundreds, thousands or even tens of thousands of times slower. Therefore, we should try to reduce the number of times of reading data from disk. In addition, when reading data from the disk, it is read according to the disk block, not one by one. If we can put as much data as possible into the disk block, more data will be read in one disk read operation, and the time for us to find data will be greatly reduced. Therefore, if we simply use the balanced binary tree data structure as the index data structure, that is, only one node is placed in each disk block, and only one set of key value pairs are stored in each node. At this time, if the amount of data is too large, there will be many nodes in the binary tree, the height of the tree will become higher, and we will perform disk IO many times to find data, The efficiency of finding data will also become extremely low!
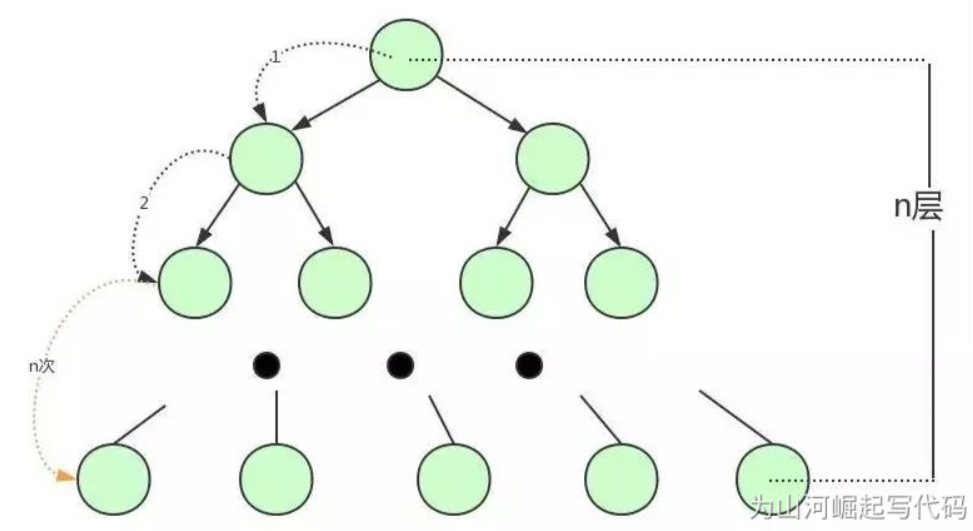
To sum up, if we can put more nodes into one disk block on the basis of balanced binary tree, the disadvantages of balanced binary tree will be solved. That is to build a balanced tree in which a single node can store multiple key value pairs, which is the B tree.
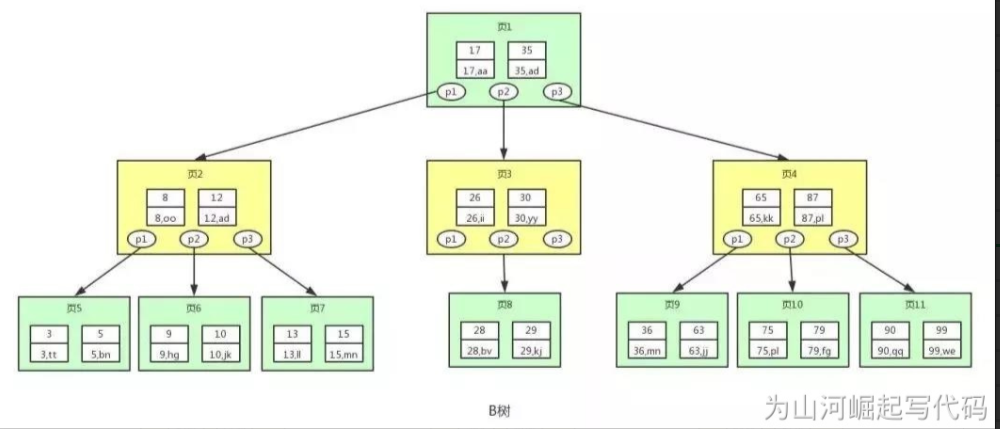
be careful:
- The p node in the graph is a pointer to the child node. In fact, there are binary search trees and balanced binary trees, which are omitted because of the beauty of the graph.
- Multiple sets of key value pairs are placed in each node in the figure. A node is also called a page. A page is a disk block. In mysql, the basic unit of data reading is page, that is, the data of one page is read at a time. Therefore, we call it page here, which is more in line with the bottom data structure of the index in MySQL.
As can be seen from the above figure, each node of the B-tree stores more keys and data than the balanced binary tree, and each node has more child nodes. The number of child nodes is generally called order. The B-tree in the above figure is a third-order B-tree, and its height will be very low. Based on this feature, the number of times B-tree looks up data and reads disk will be few, and the data search efficiency will be much higher than that of balanced binary tree. If we want to find the user information with id=28, the search process in the B tree above is as follows:
- 1. First find the root node, that is, page 1, and judge that 28 is between key values 17 and 35. Then we find page 3 according to the pointer p2 in page 1.
- 2. Comparing 28 with the key value in page 3, 28 is between 26 and 30, and we find page 8 according to the pointer p2 in page 3.
- 3. Comparing the key value 28 with the key value in page 8, it is found that there is a matching key value 28, and the user information corresponding to the key value 28 is (28,bv).
be careful:
- There are some regulations on the construction of B-tree, but this is not the focus of this paper. Interested students can make us understand.
- The B-tree is also balanced. When the B-tree is unbalanced due to adding or deleting data, node adjustment is also required.
Because B-tree is only good at equivalent query, but for range query (the essence of range query is n-times equivalent query), or sorting operation, B-tree will lose its function
select * from user where id=3; -- be good at select * from user where id>3; -- Not good at

5.5 B + tree
- B + tree is a further optimization of B tree.
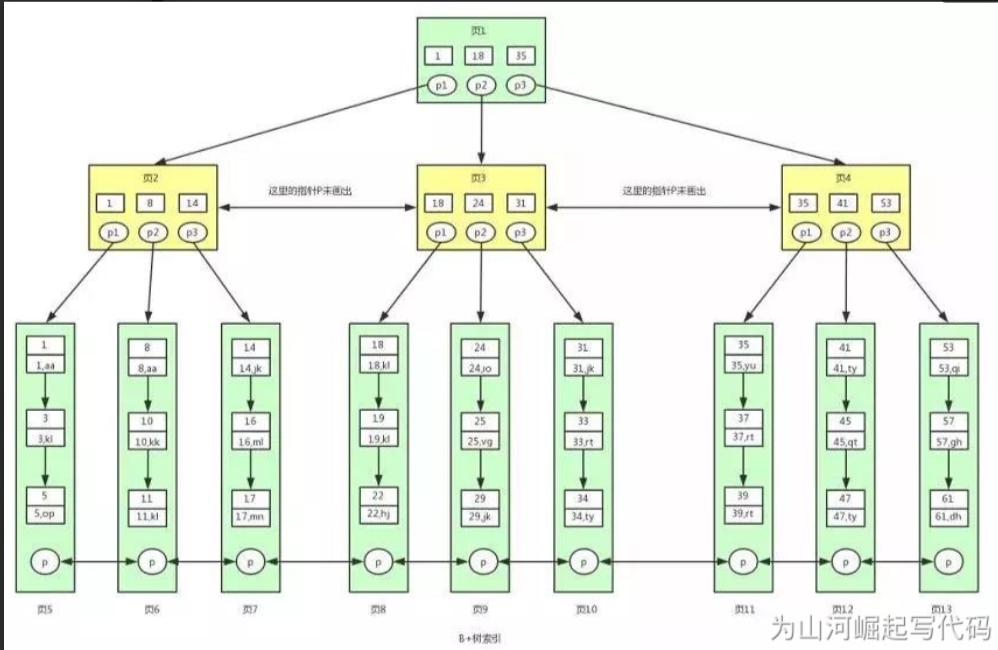
- Differences between B-tree and B + number:
- The non leaf node of the B + tree does not store data and only stores keys, while the non leaf node of the B tree stores not only keys but also data. The significance of B + tree is that a node of the tree is a page, and the page size in the database is fixed. innodb storage engine defaults to 16KB. Therefore, on the premise of fixed page size, if more nodes can be put into a page, the corresponding tree order (node's child node tree) will be larger, and the tree height will be shorter and fatter, In this way, the IO times of finding data for disk will be reduced again, and the efficiency of data query will be faster.
- The order of the B + tree is equal to the number of keys. For example, in the above figure, each node in our B + tree can store 3 keys, and the three-tier B + tree can store 333 = 27 data. Therefore, if one node of our B + tree can store 1000 key values, the three-tier B + tree can store 1000 × one thousand × 1000 = 1 billion data. In general, the root node is resident in memory, so we generally need only two disk IO to find 1 billion data. It's a terrible design. Of course, this also leads to memory overflow if the data is too large.
- Because all the data of the B + tree index is stored in the leaf node, and the data is arranged in order. Then B + tree makes range search, sorting search, grouping search and de duplication search extremely simple. Because the data of B tree is scattered in each node, it is not easy to realize this. Moreover, each page in the B + tree is also connected through a two-way linked list, and the data in the leaf node is connected through a one-way linked list. In fact, in the B tree above, we can also add a linked list to each node. In fact, these are not the differences between them, because in the innodb storage engine of mysql, indexes are stored in this way. That is to say, the B + tree index in the above figure is the real implementation of the B + tree index in innodb. To be exact, it should be a clustered index.
As can be seen from the above figure, in InnoDB, we can find all the data in the table by connecting the data pages through a two-way linked list and the data in the leaf node through a one-way linked list.

6. Index management
- The function of index is to speed up search
- The primary key, unique and unique indexes in mysql are also indexes. These indexes not only speed up search, but also have constraint functions
6.1 MySQL common index classification
# ===========B + tree index (innodb storage engine default)
Clustered index: primary key index, PRIMARY KEY
Purpose:
1,Accelerated search
2,Constraint (not null and cannot be repeated)
Unique index: UNIQUE
Purpose:
1,Accelerated search
2,Constraint (cannot be repeated)
General index INDEX:
Purpose:
1,Accelerated search
Federated index:
PRIMARY KEY(id,name):Federated primary key index
UNIQUE(id,name):Federated unique index
INDEX(id,name):Joint general index
# ===========HASH index (fast single query, slow range query)
Break up the data and then query
Innodb and Myisam It doesn't support either. After setting, it's still Btree
memery Storage engine support
#===========FULLTEXT: full text index (can only be used in MyISAM engine)
Query through keyword matching, similar to like Fuzzy matching of
like + %It is appropriate when there is less text
However, for a large number of text data, retrieval will be very slow
Full text index can compare with a large amount of data like Much faster, but with low accuracy
Baidu uses full-text index when searching articles, but it is more likely to be ES
# ===========RTREE: R-tree index
RTREE stay mysql Rarely used, only supported geometry data type
geometry The data type is generally filled in longitude and latitude
Only storage engines that support this type MyISAM,BDb,InnoDb,NDb,Archive Several.
RTREE Range lookup is strong, but Btree Not weak.
#Different storage engines support different index types
InnoDB Supports transaction, row level locking, and B-tree,Full-text Index, not supported Hash Indexes;
MyISAM Transaction is not supported, table level locking is supported, and B-tree,Full-text Index, not supported Hash Indexes;
Memory Transaction is not supported, table level locking is supported, and B-tree,Hash Index, not supported Full-text Indexes;
NDB Supports transaction, row level locking, and Hash Index, not supported B-tree,Full-text Equal index;
Archive Transaction and table level locking are not supported B-tree,Hash,Full-text Equal index;

6.2 syntax for creating / deleting indexes
6.2.1 when creating a table
CREATE TABLE Table name(
Field name 1 data type [Integrity constraints],
Field name 2 data type [Integrity constraints],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[Index name] (Field name[(length)] [ASC |DESC])
);
-- case
mysql> CREATE TABLE t1 ( id int PRIMARY KEY );
Query OK, 0 rows affected (0.10 sec)
mysql> SHOW CREATE TABLE t1\G
*************************** 1. row ***************************
Table: t1
Create Table: CREATE TABLE `t1` (
`id` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
6.2.2 CREATE creates an index on an existing table
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX Index name
ON Table name (Field name[(length)] [ASC |DESC]) ;
-- case
mysql> CREATE TABLE t2(
-> id int
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> CREATE UNIQUE INDEX index1 on t2(id);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table t2\G
*************************** 1. row ***************************
Table: t2
Create Table: CREATE TABLE `t2` (
`id` int(11) DEFAULT NULL,
UNIQUE KEY `index1` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
6.2.3 ALTER TABLE create index on existing table
ALTER TABLE Table name ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
Index name (Field name[(length)] [ASC |DESC]) ;
-- case
mysql> CREATE TABLE t3( id int );
Query OK, 0 rows affected (0.00 sec)
mysql> ALTER TABLE t3 ADD INDEX index1 (id) ;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table t3\G
*************************** 1. row ***************************
Table: t3
Create Table: CREATE TABLE `t3` (
`id` int(11) DEFAULT NULL,
KEY `index1` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)

6.2.4 view index command
#View index Method 1: mysql> desc t1; +-----+ | Key | +-----+ | PRI | primary key | MUL | General index | UNI | Unique key index +-----+ Method 2: mysql> show index from t1;
6.2.5 delete index command
DROP INDEX Index name ON Table name; alter table country drop index Index name; mysql> DROP INDEX index1 ON t2; Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc t2; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | +-------+---------+------+-----+---------+-------+ 1 row in set (0.00 sec) mysql> alter table t3 drop index index1; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc t3; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | +-------+---------+------+-----+---------+-------+ 1 row in set (0.00 sec)

Example:
# 1) Primary key index (clustered index)
#Create primary key index
mysql> alter table student add primary key pri_id(id);
mysql> create table student(id int not null, primary key(id));
mysql> create table student(id int not null primary key auto_increment comment 'Student number');
#Tips:
database Can write schema
index Can write key
# 2) Unique key index
#Create unique index
mysql> alter table country add unique key uni_name(name);
mysql> create table student(id int unique key comment 'Student number');
mysql> create unique key index index_name on table_name(id);
# 3) Normal index (secondary index)
#Creation of general index
mysql> alter table student add index idx_gender(gender);
CREATE INDEX index_name ON table_name (column_list);
# 4) Create prefix index
According to the first column of data n Create index with letters
mysql> alter table student add index idx_name(name(4));
# 5) Full text index
#Full text index is made for content:
CREATE TABLE t1 (
id int NOT NULL AUTO_INCREMENT,
title char(255) NOT NULL,
content text,
PRIMARY KEY (id),
FULLTEXT (content));
When searching:
select * from table where match(content) against('String to query');
6.3 test index
- The main purpose of testing the index is to test the performance of the index.
#1. Preparation form
create table s1(
id int,
name varchar(20),
gender char(6),
email varchar(50)
);
#2. Create a stored procedure to insert records in batches
delimiter $$ #Declare that the end symbol of the stored procedure is$$
create procedure auto_insert1()
BEGIN
declare i int default 1;
while(i<3000000)do
insert into s1 values(i,'shanhe','male',concat('shanhe',i,'@helloworld'));
set i=i+1;
select concat('shanhe',i,'_ok');
end while;
END$$ #$$end
delimiter ;
#3. View stored procedures
show create procedure auto_insert1\G
#4. Call stored procedure
call auto_insert1()
Summary:
No index: mysql doesn't know whether there is a record with id equal to 333 at all. It can only scan the data table from beginning to end. At this time, the number of disk blocks requires how many IO operations, so the query speed is very slow
On the premise that a large amount of data already exists in the table, the establishment speed of an index for a field segment will be very slow. After the index is established, when the field is used as the query condition, the query speed will be significantly improved
be careful:
- You must create an index for the fields of the search criteria, such as select * from s1 where id = 333; You need to index the ID
- When there is already a large amount of data in the table, the index building will be very slow and occupy hard disk space. After the index building, the query speed will be accelerated, such as create index idx on s1(id); It will scan all the data in the table, and then create an index structure with id as the data item and store it in the table on the hard disk.
After the construction, the query will be very fast. - It should be noted that the index of innodb table will be stored in S1 In the IBD file, and the index of the myisam table will have a separate index file table1 MYI
Supplement:
The MySAM index file and data file are separated, and the index file only saves the address of the data record. In innodb, the table data file itself is an index structure organized according to B+Tree (BTree, i.e. Balance True). The leaf node data field of this tree saves complete data records. The key of this index is the primary key of the data table, so the innodb table data file itself is the primary index.
Because innodb's data files need to be aggregated according to the primary key, innodb requires that the table must have a primary key (Myisam can not). If there is no explicit definition, mysql will automatically select a column that can uniquely identify the data record as the primary key. If there is no such column, mysql will automatically generate an implicit field for the innodb table as the primary key, The length of this field is 6 bytes and the type is long integer.

6.4 correct use of index
It doesn't mean that once we create an index, we will speed up the query. If we want to use the index to achieve the desired effect of improving the query speed, we must follow the following questions when adding an index.
6.4.1 scope issues
The condition is ambiguous. These symbols or keywords appear in the condition: >, > =, <, < =,! = between…and…,like. The smaller the specified range, the faster the search speed, and the larger the range, the slower the query speed
When using like,% or_ It should be placed on the right, and the characters on the left should be as precise as possible, so that the locking range can be smaller. For example, like "python%" instead of like "% python", like "py%"
Note: the like keyword cannot hit the index when% leading is used, and the query speed is very slow. Therefore, try to avoid using% leading in the enterprise.
6.5 query optimization artifact - explain
Please refer to the official website for specific usage and field meaning explain-output Here, we need to emphasize that rows is the core indicator, and most of the small rows statements must execute very quickly (with exceptions, which will be discussed below). Therefore, the optimization statements are basically optimizing rows.
6.5.1 field details

1. id
Contains a set of numbers that represent execution in the query select The order of clauses or action tables
Example(id Same, execution order from top to bottom)
If it is a subquery, id The serial number of the is incremented, id The higher the value, the higher the priority, and the earlier it is executed
id If they are the same, they can be considered as a group and executed from top to bottom; In all groups, id The higher the value, the higher the priority and execute first
2. select_type
Show each in the query select Type of Clause (simple) OR (complex)
a. SIMPLE: The query does not contain subqueries or UNION
b. If the query contains any complex sub parts, the outermost query is marked as: PRIMARY
c. stay SELECT or WHERE The list contains a subquery marked as: SUBQUERY
d. stay FROM The subqueries contained in the list are marked as: DERIVED(Derived) used to represent included in from Of subqueries in Clause select,mysql It will execute recursively and put the results into a temporary table. The internal server is called"Derived table",Because the temporary table is derived from the subquery
e. If the second SELECT Appear in UNION After that, it is marked as UNION;if UNION Included in FROM Clause, the outer layer SELECT Will be marked as: DERIVED
f. from UNION Table to get results SELECT Marked as: UNION RESULT
SUBQUERY and UNION Can also be marked as DEPENDENT and UNCACHEABLE.
DEPENDENT signify select Depends on the data found in the outer query.
UNCACHEABLE signify select Some features in prevent results from being cached in a item_cache Yes.
First line: id A column of 1 indicates the first select,select_type Columnar primary Indicates that the query is an outer query, table Column is marked as<derived3>,Indicates that the query result comes from a derived table, where 3 represents that the query is derived from the third table select Query, i.e id For 3 select.
Second line: id Is 3, indicating that the execution order of the query is 2 (4) => 3),Is the third in the entire query select Part of. Because the query is contained in from Medium, so derived.
Third line: select Subqueries in the list, select_type by subquery,For the second in the entire query select.
Line 4: select_type by union,Explain the fourth select yes union The second in the select,Execute first.
Line 5: represents from union The stage of reading rows from the temporary table of, table Columnar<union1,4>Represents the first and fourth select The results are analyzed union Operation.}
3, type
express MySQL The way to find the desired row in the table is also called "access type".
Common types are: ALL, index, range, ref, eq_ref, const, system, NULL(From left to right, performance from poor to good)
ALL: Full Table Scan,
index: Full Index Scan,index And ALL The difference is index Type traverses only the index tree
range:Retrieve only rows in a given range, using an index to select rows
ref: Indicates the join matching criteria of the above table, that is, which columns or constants are used to find values on index columns
eq_ref: similar ref,The difference is that the index used is unique. For each index key value, only one record in the table matches. In short, it is used in multi table connection primary key perhaps unique key As association condition
const,system: When MySQL These types are used when a part of the query is optimized and converted to a constant. If the primary key is placed in where In the list, MySQL You can convert the query to a constant,system yes const Type, which is used when the query table has only one row system
NULL: MySQL In the optimization process, the statement is decomposed without even accessing the table or index. For example, selecting the minimum value from an index column can be completed through a separate index search.
4,table
Which table does the data in this row show about? Sometimes it is not the real table name,What you see is derivedx(x It's a number,My understanding is the result of step)
5,possible_keys
point out MySQL Which index can be used to find records in the table? If there is an index on the field involved in the query, the index will be listed, but it may not be used by the query
This column is completely independent of EXPLAIN Output the order of the tables shown. This means that in possible_keys Some keys in cannot actually be used in the order of the generated table.
If the column is NULL,There is no associated index. In this case, you can pass the inspection WHERE Clause to see if it references some columns or columns suitable for index to improve your query performance. If so, create an appropriate index and use it again EXPLAIN Check query
6,Key
key Column display MySQL Actually determine the key (index) to use
If no index is selected, the key is NULL. To force MySQL Use or neglect possible_keys Index in column, used in query FORCE INDEX,USE INDEX perhaps IGNORE INDEX. (Note: index hit or not)
7,key_len
Represents the number of bytes used in the index. This column can be used to calculate the length of the index used in the query( key_len The displayed value is the maximum possible length of the index field, not the actual length used, i.e key_len (it is calculated according to the table definition, not retrieved from the table)
Without loss of accuracy, the shorter the length, the better
8,ref
Indicates the join matching criteria of the above table, that is, which columns or constants are used to find values on index columns
9,rows
express MySQL Estimate the number of rows to be read to find the required records according to table statistics and index selection
10,Extra
The column contains MySQL Resolve query details,There are several situations:
Using where:The column data is returned from the table that only uses the information in the index without reading the actual action. This occurs when all the request columns of the table are part of the same index mysql The server will filter the rows after the storage engine retrieves them
Using temporary: express MySQL Temporary tables are required to store result sets, which are common in sorting and grouping queries
Using filesort: MySQL The sort operation that cannot be completed by index in is called "file sort"
Using join buffer: The change emphasizes that the index is not used when obtaining the connection conditions, and the connection buffer is needed to store the intermediate results. If this value appears, it should be noted that depending on the specific situation of the query, you may need to add an index to improve the performance.
Impossible where: This value emphasizes where Statement will result in no qualified rows.
Select tables optimized away: This value means that the optimizer may only return one row from the aggregate function result by using indexes only.
explain Field explanation
