ElasticSearch environment construction
1. Single machine, cluster and node concepts.
1.1 single machine
When a stand-alone ElasticSearch server provides services, it often has the maximum load capacity. If this threshold is exceeded, the server performance will be greatly reduced or even unavailable. Therefore, in the production environment, it generally runs on the specified server cluster.
In addition to load capacity, single point servers have other problems:
- Limited storage capacity of a single machine
- Single server is prone to single point of failure and cannot achieve high availability
- The concurrent processing capacity of a single server is limited
When configuring a server cluster, there is no limit on the number of nodes in the cluster. If there are more than or equal to 2 nodes, it can be regarded as a cluster. Generally, considering high performance and high availability, the number of nodes in the cluster is more than 3.
1.2 cluster
A cluster is organized by one or more server nodes to jointly hold the whole data and provide it together
Index and search functions. An elasticsearch cluster has a unique name ID, which is "elasticsearch" by default. This name is important because a node can only join a cluster by specifying the name of the cluster.
1.3 nodes
The cluster contains many servers, and a node is one of them. As a part of the cluster, it stores data and participates in the indexing and search functions of the cluster.
A node can join a specified cluster by configuring the cluster name. By default, each node is scheduled to join a cluster called "elastic search", which means that if you start several nodes in your network and assume that they can find each other, they will automatically form and join a cluster called elastic search.
In a cluster, you can have as many nodes as you want. Moreover, if no elasticsearch node is running in your network, start a node at this time, and a cluster called "elasticsearch" will be created and joined by default.
2. Installation of Linux stand-alone version
tar.gz can be installed or RPM can be used. It is recommended to use rpm to register in the system service to facilitate start and stop.
2.1 installing tar.gz package
Software download address
Decompression software
tar -zxvf elasticsearch-7.4.2-linux-x86_64.tar.gz -C /usr/local/
Modify profile
/usr/local/elasticsearch-7.4.2/config vi elasticsearch.yml
# Add the following configuration # Modify current node name cluster.name: elasticsearch # Modify cluster name node.name: node-1 # Modify data storage address path.data=/usr/local/elasticsearch-7.4.2/data # Modify log data storage address path.log=usr/local/elasticsearch-7.4.2/log # Modify ip allowed access address network.host: 0.0.0.0 # Modify access port http.port: 9200 # Cluster initialization node cluster.initial_master_nodes: ["node-1"]
Modify JVM parameters
-Xms128m -Xmx256m
Create user
Because of security issues, Elasticsearch does not allow the root user to run directly, so create a new user.
# Add esuser user useradd esuser # Empowerment chown -R esuser:esuser /usr/local/elasticsearch-7.4.2/
Modify / etc/security/limits.conf
# Limit on the number of files that can be opened per process * soft nofile 65536 * hard nofile 131072 # Operating system level limit on the number of processes created per user * soft nproc 2048 * hard nproc 4096
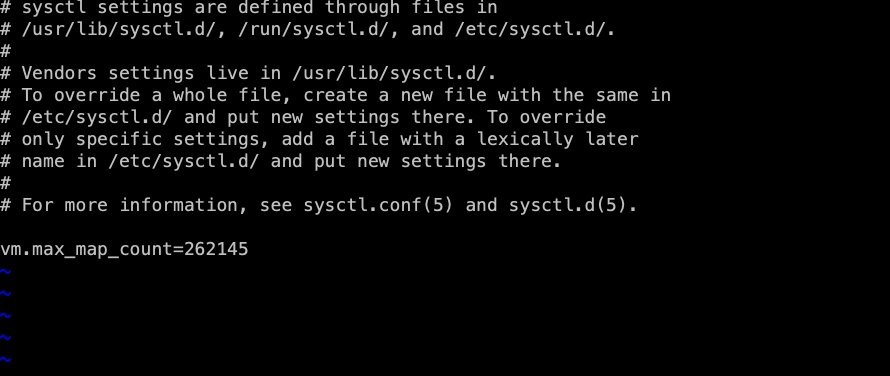
Modify / etc/sysctl.conf
# Add the following content to the file # The number of Vmas (virtual memory areas) that a process can own. The default value is 65536 vm.max_map_count=655360
Reload
sysctl -p
execute
su esuser # Enter $ES_HOME/bin cd /usr/local/elasticsearch-7.4.2/bin # Background start es ./elasticsearch -d

Test whether the startup is normal
Access virtual machine ip + port 9200. The display is normal as shown in the figure

Out of Service
# Find es service ps -ef |grep elastic # Kill es process kill -9 xxx(Process number)

2.2 installing rpm package
The download address is the same as above, and select rpm package
rpm -ivh elasticsearch-7.6.2.rpm
Modify profile
# Add the following configuration # Modify current node name cluster.name: elasticsearch # Modify cluster name node.name: node-1 # Modify data storage address path.data=/usr/local/elasticsearch-7.4.2/data # Modify log data storage address path.log=usr/local/elasticsearch-7.4.2/log # Modify ip allowed access address network.host: 0.0.0.0 # Modify access port http.port: 9200 # Cluster initialization node cluster.initial_master_nodes: ["node-1"]
Modify file owner
chown elasticsearch:elasticsearch -R /usr/local/elasticsearch-7.4.2/
Start elasticsearch
systemctl start elasticsearc
View es startup status
systemctl status elasticsearch
If the startup failure error message is not easily observed from the system service, you can also start es through the installation path first
/usr/share/elasticsearch/bin/elasticsearch
2.3 Linux Cluster build
It is basically the same as the stand-alone version, but the configuration file is slightly different
#Cluster name cluster.name: cluster-es #Node name. The name of each node cannot be duplicate. node.name: node-1 #ip address. The address of each node cannot be repeated network.host: node107 #Is it qualified to master node.master: true node.data: true http.port: 9200 # The head plug-in needs to open these two configurations http.cors.allow-origin: "*" http.cors.enabled: true http.max_content_length: 200mb #The configuration added after es7.x is required to elect master cluster.initial when initializing a new cluster_ master_ nodes: ["node-1"] #New configuration after es7.x, node discovery discovery.seed_hosts: ["node107:9300","node108:9300","node109:9300"] gateway.recover_after_nodes: 2 network.tcp.keep_alive: true network.tcp.no_delay: true transport.tcp.compress: true #The number of data tasks started simultaneously in the cluster is 2 by default cluster.routing.allocation.cluster_concurrent_rebalance: 16 #The number of concurrent recovery threads when adding or deleting nodes and load balancing. The default is 4 cluster.routing.allocation.node_concurrent_recoveries: 16 #When initializing data recovery, the number of concurrent recovery threads is 4 cluster.routing.allocation.node by default_ initial_ primaries_ recoveries: 16
Status indicates whether the current cluster is working normally in general. The three colors have the following meanings
| colour | meaning |
|---|---|
| green | All primary and replica partitions work normally |
| yellow | All primary shards are running normally, but not all replica shards are running normally |
| red | The main partition does not operate normally |