Before we created the index and looked up the data, we used the default word segmentation device. The word segmentation effect is not ideal. We will divide the text field into Chinese characters one by one, and then segment the searched sentences when searching. Therefore, we need a more intelligent ik word segmentation device.
1.1. Install ik plug-ins online (slower)
Download address: https://github.com/medcl/elasticsearch-analysis-ik/releases
Select the corresponding version. Here, select version 7.12.1.
# Enter the inside of the container docker exec -it elasticsearch /bin/bash # Download and install online ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip #sign out exit #Restart container docker restart elasticsearch
1.2. Install ik plug-ins offline
1) View data volume directory
To install the plug-in, you need to know the location of the plugins directory of elasticsearch. I used the data volume to mount, so you need to view the data volume directory of elasticsearch through the following command:
docker volume inspect es-plugins
Display results:
[
{
"CreatedAt": "2022-05-06T10:06:34+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]
Description the plugins directory is mounted to: / var / lib / docker / volumes / es plugins/_ Data in this directory.
2) Decompress the installation package of word splitter
We need to unzip the installation package downloaded in advance by ik word splitter and rename it ik
3) Upload to the plug-in data volume of the es container
That is, / var / lib / docker / volumes / es plugins/_ data:
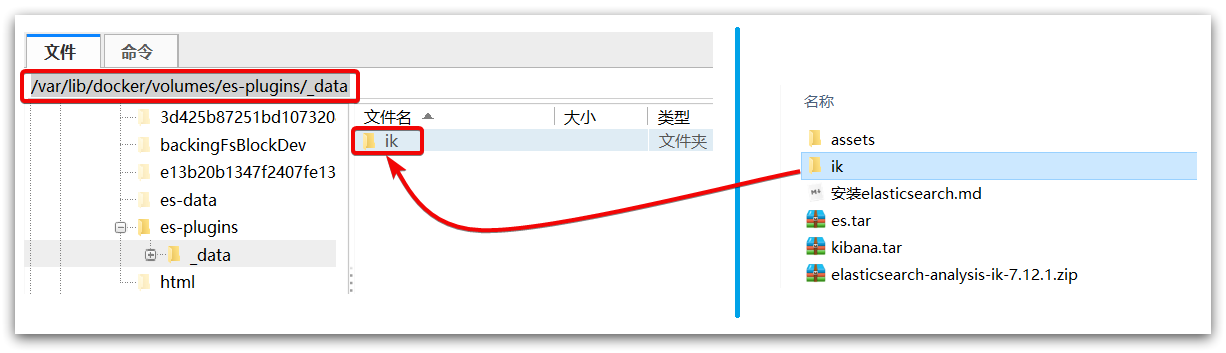
4) Restart container
# 4. Restart container docker restart es
# View es log docker logs -f es
# The IK word splitter contains two modes: ik_smart: Minimum segmentation ik_max_word: Thinnest segmentation
1.3 extended word dictionary
With the development of the Internet, "word making movement" is becoming more and more frequent. Many new words have appeared, which do not exist in the original vocabulary list. For example, some network words.
Therefore, our vocabulary also needs to be constantly updated. IK word splitter provides the function of expanding vocabulary.
1) Open the IK word splitter config Directory:
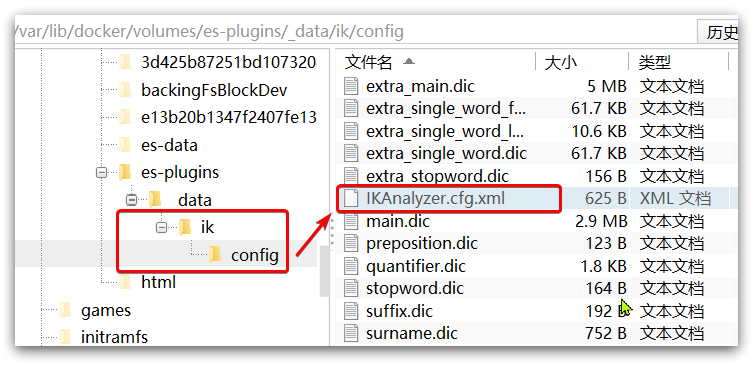
2) At ikanalyzer cfg. XML configuration file content addition:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer Extended configuration</comment>
<!--Users can configure their own extended dictionary here *** Add extended dictionary-->
<entry key="ext_dict">ext.dic</entry>
</properties>
3) Create a new ext.dic. You can copy a configuration file under the config directory for modification
awesome
4) Restart elasticsearch
docker restart es # View log docker logs -f elasticsearch
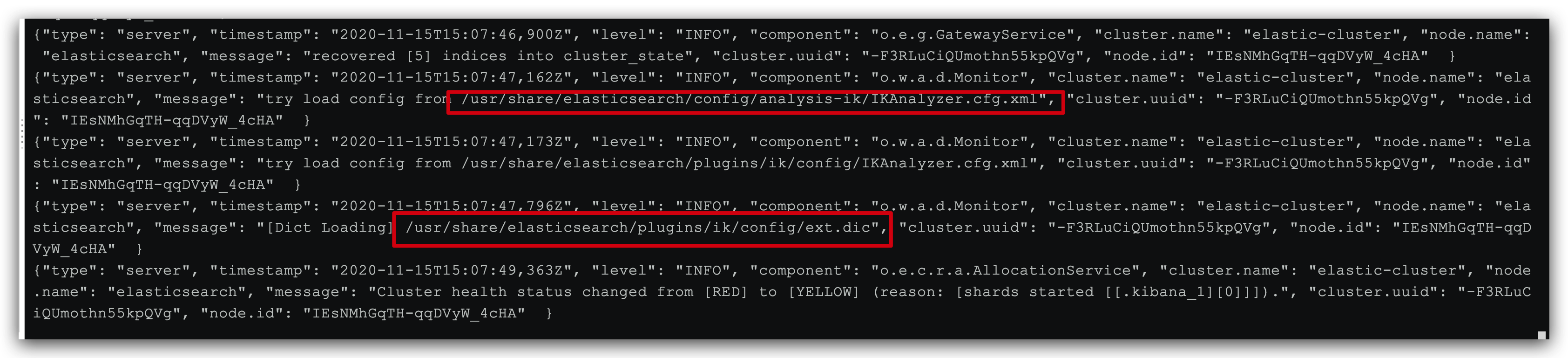
The ext.dic configuration file has been successfully loaded in the log
Note that the encoding of the current file must be in UTF-8 format. It is strictly prohibited to edit it with Windows Notepad
1.4 Dictionary of stop words
In Internet projects, the transmission speed between networks is very fast, so many languages are not allowed to be transmitted on the network, such as sensitive words such as politics, so we should also ignore the current words when searching.
The IK word splitter also provides a powerful stop word function, allowing us to directly ignore the contents of the current stop vocabulary when indexing.
1)IKAnalyzer.cfg.xml configuration file content addition:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer Extended configuration</comment>
<!--Users can configure their own extended dictionary here-->
<entry key="ext_dict">ext.dic</entry>
<!--Users can configure their own extended stop word dictionary here *** Add stop word dictionary-->
<entry key="ext_stopwords">stopword.dic</entry>
</properties>
2) In stopword DIC add stop word
# Add stop words here
3) Restart elasticsearch
# Restart service docker restart elasticsearch docker restart kibana # View log docker logs -f elasticsearch
Stopword.com has been successfully loaded in the log DIC configuration file
Note that the encoding of the current file must be in UTF-8 format