Flume introduction
1. Flume
1. flume is a distributed, reliable and highly available system for massive log collection, aggregation and transmission. Support customization of various data senders in the log system for data collection; At the same time, flume provides the ability to simply process data and write to various data recipients (such as text, HDFS, Hbase, etc.)
2. The data flow of Flume runs through events. Event is the basic data unit of Flume. It carries log data (in byte array form) and header information. These events are generated by the Source outside the Agent. When the Source captures the event, it will perform specific formatting, and then the Source will push the event into (single or multiple) channels. You can think of a Channel as a buffer that will hold events until sink processes them. Sink is responsible for persisting logs or pushing events to another Source.
2. Flume architecture
The core of flume is the agent. Flume takes agent as the smallest independent operation unit. An agent is a JVM. It is a complete data collection tool with three core components: source, channel and sink. Through these components, events can flow from one place to another, as shown in the following figure.
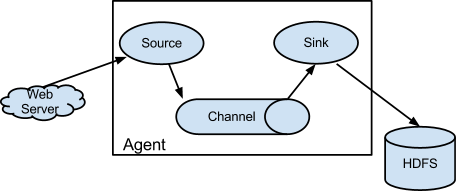
3. Flume assembly
Client: client production data, running in an independent thread.
Event: a data unit consisting of a message header and a message body. (Events can be log records, avro objects, etc.)
Flow: the abstraction of Event migration from the source point to the destination point.
Agent: an independent Flume process, including components Source, Channel and Sink. (the agent uses the JVM to run Flume. Each machine runs an agent, but it can contain multiple sources and sinks in an agent.)
Source: data collection component. (source collects data from the Client and passes it to the Channel)
Channel: a temporary storage of transit events, which saves the events passed by the Source component. (the channel connects sources and sinks, which is a bit like a queue.)
Sink: read and remove the Event from the Channel and pass the Event to the next Agent (if any) in the FlowPipeline (sink collects data from the Channel and runs in a separate thread.)
Flume installation
1. Upload to the virtual machine and unzip it
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /usr/local/soft/
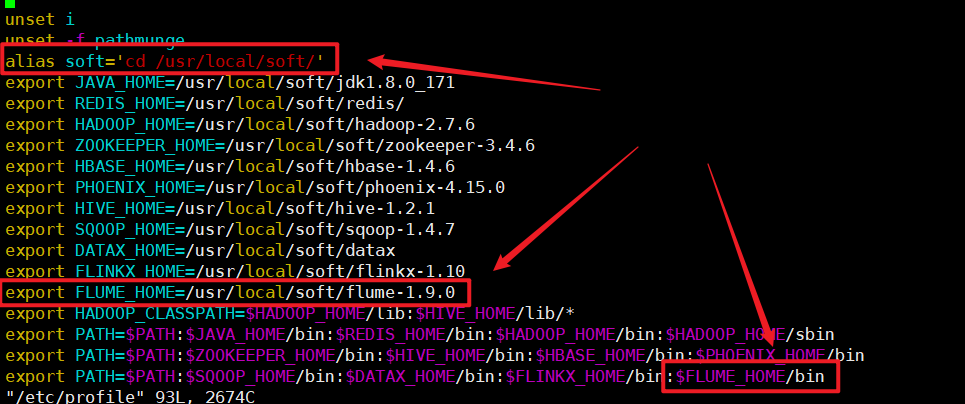
Add the following command to the environment variable to quickly switch to / usr/local/soft using soft
alias soft='cd /usr/local/soft/'
2. Rename and configure environment variables
mv apache-flume-1.9.0-bin/ flume-1.9.0 vim /etc/profile source /etc/profile
3. View flume version
flume-ng version
[root@master soft]# flume-ng version Flume 1.9.0 Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git Revision: d4fcab4f501d41597bc616921329a4339f73585e Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018 From source with checksum 35db629a3bda49d23e9b3690c80737f9
4. Test flume
-
Monitor a directory and print the data
- configuration file
# First, name the agent a1 # Name the source channel sink respectively a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Configure source, channel and sink respectively # Configure source # Specify the type of source as spooldir to listen for changes in files in a directory # Because each component may have the same attribute name, when configuring each component # You need to add the name of the agent sources. Name of the component Attribute = attribute value a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /root/data/ a1.sources.r1.fileSuffix = .ok a1.sources.r1.fileHeader = true # Configure an interceptor for the souces r1 and name it i1 a1.sources.r1.interceptors = i1 # Setting the interceptor i1's type to timestamp inserts the data processing time into the event header in milliseconds # a1.sources.r1.interceptors.i1.type = timestamp # Set the interceptor i1's type to regex_ The filter filters the data based on regular expressions a1.sources.r1.interceptors.i1.type = regex_filter # Configure regular expressions a1.sources.r1.interceptors.i1.regex = \\d{3,6} # excludeEvents = true indicates the filter to be matched and the release not matched a1.sources.r1.interceptors.i1.excludeEvents = true # Configure sink # Using logger as the sink component, you can print the collected data directly to the console a1.sinks.k1.type = logger # Configure channel # Setting the type of channel to memory means that the event is cached in memory a1.channels.c1.type = memory # assemble # Specify the channels property of sources as c1 a1.sources.r1.channels = c1 # Specify the channel attribute of sinks as c1 a1.sinks.k1.channel = c1- Start agent
flume-ng agent -n a1 -f ./spoolingtest.conf -Dflume.root.logger=DEBUG,console
- New / root/data directory
mkdir /root/data
- Create a new file in the / root/data / directory, enter the content, and observe the log printed by the flume process
# Feel free to add some content to a.txt vim /root/data/a.txt
Use of Flume
-
spoolingToHDFS.conf
- configuration file
# A means to name the agent a # Name the source component r1 a.sources = r1 # Name the sink component k1 a.sinks = k1 # Name the channel component c1 a.channels = c1 #Specifies the properties of spooldir a.sources.r1.type = spooldir a.sources.r1.spoolDir = /root/data a.sources.r1.fileHeader = true a.sources.r1.interceptors = i1 a.sources.r1.interceptors.i1.type = timestamp #Specifies the type of sink a.sinks.k1.type = hdfs a.sinks.k1.hdfs.path = /flume/data/dir1 # Specify file name prefix a.sinks.k1.hdfs.filePrefix = student # Specifies how much data is written once. Unit: bytes a.sinks.k1.hdfs.rollSize = 102400 # Specify how many files to write once a.sinks.k1.hdfs.rollCount = 1000 # Specify the file type as what the stream comes from and what the output is a.sinks.k1.hdfs.fileType = DataStream # Specifies that the file output format is text a.sinks.k1.hdfs.writeFormat = text # Specify file name suffix a.sinks.k1.hdfs.fileSuffix = .txt #Specify channel a.channels.c1.type = memory a.channels.c1.capacity = 1000 # Indicates how much data sink will fetch from the channel each time a.channels.c1.transactionCapacity = 100 # assemble a.sources.r1.channels = c1 a.sinks.k1.channel = c1
- Prepare data in the / root/data / directory
The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!
- Start agent
flume-ng agent -n a -f ./spoolingToHDFS.conf -Dflume.root.logger=DEBUG,console
-
hbaseLogToHDFS
- configuration file
# A means to name the agent a # Name the source component r1 a.sources = r1 # Name the sink component k1 a.sinks = k1 # Name the channel component c1 a.channels = c1 #Specify the properties of exec a.sources.r1.type = exec a.sources.r1.command = tail -f /usr/local/soft/hbase-1.4.6/logs/hbase-root-master-master.log #Specifies the type of sink a.sinks.k1.type = hdfs a.sinks.k1.hdfs.path = /flume/data/dir2 # Specify file name prefix a.sinks.k1.hdfs.filePrefix = hbaselog # Specifies how much data is written once. Unit: bytes a.sinks.k1.hdfs.rollSize = 102400 # Specify how many files to write once a.sinks.k1.hdfs.rollCount = 1000 # Specify the file type as what the stream comes from and what the output is a.sinks.k1.hdfs.fileType = DataStream # Specifies that the file output format is text a.sinks.k1.hdfs.writeFormat = text # Specify file name suffix a.sinks.k1.hdfs.fileSuffix = .txt #Specify channel a.channels.c1.type = memory a.channels.c1.capacity = 1000 # Indicates how much data sink will fetch from the channel each time a.channels.c1.transactionCapacity = 100 # assemble a.sources.r1.channels = c1 a.sinks.k1.channel = c1
-
hbaselogToHBase
- Create log table in hbase
create 'log','cf1'
- configuration file
# A means to name the agent a # Name the source component r1 a.sources = r1 # Name the sink component k1 a.sinks = k1 # Name the channel component c1 a.channels = c1 #Specify the properties of exec a.sources.r1.type = exec a.sources.r1.command = cat /usr/local/soft/hbase-1.4.6/logs/hbase-root-master-master.log #Specifies the type of sink a.sinks.k1.type = hbase a.sinks.k1.table = log a.sinks.k1.columnFamily = cf1 #Specify channel a.channels.c1.type = memory a.channels.c1.capacity = 100000 # Indicates how much data sink will fetch from the channel each time a.channels.c1.transactionCapacity = 100 # assemble a.sources.r1.channels = c1 a.sinks.k1.channel = c1
-
netcatLogger
Listening telnet port
- Installing telnet
yum install telnet
- configuration file
# A means to name the agent a # Name the source component r1 a.sources = r1 # Name the sink component k1 a.sinks = k1 # Name the channel component c1 a.channels = c1 #Specify the properties of netcat a.sources.r1.type = netcat a.sources.r1.bind = 0.0.0.0 a.sources.r1.port = 8888 #Specifies the type of sink a.sinks.k1.type = logger #Specify channel a.channels.c1.type = memory a.channels.c1.capacity = 1000 # Indicates how much data sink will fetch from the channel each time a.channels.c1.transactionCapacity = 100 # assemble a.sources.r1.channels = c1 a.sinks.k1.channel = c1
-
start-up
-
Start the agent first
flume-ng agent -n a -f ./netcatToLogger.conf -Dflume.root.logger=DEBUG,console
- Starting telnet
telnet master 8888
-
httpToLogger
- configuration file
# A means to name the agent a # Name the source component r1 a.sources = r1 # Name the sink component k1 a.sinks = k1 # Name the channel component c1 a.channels = c1 #Specifies the properties of http a.sources.r1.type = http a.sources.r1.port = 6666 #Specifies the type of sink a.sinks.k1.type = logger #Specify channel a.channels.c1.type = memory a.channels.c1.capacity = 1000 # Indicates how much data sink will fetch from the channel each time a.channels.c1.transactionCapacity = 100 # assemble a.sources.r1.channels = c1 a.sinks.k1.channel = c1
-
start-up
-
Start the agent first
flume-ng agent -n a -f ./httpToLogger.conf -Dflume.root.logger=DEBUG,console
- Then use curl to initiate an http request
http://master:6666