Integrated learning
To be exact, ensemble learning is not a real machine learning algorithm, at least it does not introduce any new learning algorithm in essence. The overall idea of ensemble learning is to complete the final task through multiple basic (weak) learners. Just as it used to be a single challenge between an algorithm and a problem, now it is a group fight between multiple algorithms (repeated or non repeated). It is academically called ensemble learning or multi classifier system.
Ensemble learning can be roughly divided into three learning methods
-
Bagging
-
Boosting
-
Stacking
Here we are divided into three parts. First, we introduce the idea of Bagging algorithm and its examples. Later, we will introduce Boosting and Stacking respectively
Bagging
Now let's imagine a simple classification problem. In the past, when we used KNN, DT, SVM and other algorithms for prediction, only one base learner was generated. Our final decision results will also depend entirely on the learner. Now we take the method of putting back the samples for 10 times of algorithm learning, so do we get 10 different base learners? No matter how we use so many basic learners in the future, we can get them first.
from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.model_selection import train_test_split,GridSearchCV import matplotlib.pyplot as plt import numpy as np import pandas as pd from math import floor
# Get the data. The data here follow the Titanic data. You can download the data from the link in this article
# https://blog.csdn.net/qq_40725653/article/details/117922390?spm=1001.2014.3001.5501
dataset = pd.read_csv(r"E:\Jupyter\Pytorch\ML_Algorithm\Decision_tree\titanic\train.csv")
dataset = dataset.drop(columns=['Name','SibSp','Parch','Ticket','Fare','Cabin','Embarked'])
# Simple data processing to obtain features and labels
features = dataset.iloc[:,-3:]
target = dataset.loc[:,["Survived"]]
# Missing value processing, filled with average value
for line in features.columns:
if np.any(features[line].isnull())==True:
features[line].fillna(value=floor(round(features[line].mean(),1)),inplace=True)
from sklearn.feature_extraction import DictVectorizer
# Data segmentation
x_train,x_test,y_train,y_test = train_test_split(features,target,test_size=0.2,random_state=1)
# Characteristic Engineering
transfer = DictVectorizer(sparse=False)
x_train = transfer.fit_transform(x_train.to_dict(orient="records"))
x_test = transfer.fit_transform(x_test.to_dict(orient="records"))
# Set up the model, ten times cross validation
cif = BaggingClassifier(base_estimator=DecisionTreeClassifier(),bootstrap=False,bootstrap_features=True,random_state=2)
# You can change the basic algorithm here
#cif = BaggingClassifier(base_estimator=SVC(),bootstrap=False,bootstrap_features=True,random_state=2)
params = {'n_estimators':[10,50,100,150,200]}
cif = GridSearchCV(estimator=cif,param_grid=params,cv=10)
# train
y_train = np.array(y_train).ravel()
y_test = np.array(y_test).ravel()
cif.fit(x_train,y_train)
# forecast
y_pred = cif.predict(x_test)
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test,y_pred))
Voting
Through the above methods, we can generate a variety of basic models. Let's assume that DT, RF and SVM have been generated for the same classification problem. Then there will be three output results, but we only need one label in the end. How can we fit multiple outputs to finally generate a label? Combination strategy
Combined with strategy 1: average method, for numerical output tasks such as regression type, the most common strategy is to use simple average method
1: Simple average method
H
(
x
)
=
1
T
∑
i
=
1
T
h
i
(
x
)
H(x)=\dfrac{1}{T}\sum_{i=1}^Thi(x)
H(x)=T1∑i=1Thi(x)
2: Weighted average method
H
(
x
)
=
∑
i
=
1
T
w
i
h
i
(
x
)
H(x)=\sum_{i=1}^Tw_ih_i(x)
H(x)=∑i=1Twihi(x)
among
w
i
w_i
wi # is a single learner
h
i
h_i
The weight of hi is usually required
w
i
≥
0
,
∑
i
=
1
T
=
1
w_i≥0,\sum_{i=1}^T=1
wi ≥ 0, Σ i=1T = 1, where the weight is generally learned from the training data. There is a similar mechanism in the voting law, which will be explained in detail in boosting
Combined with strategy 2: voting method, for the classification problem, predict a tag from the category tag set through a certain voting method as the output of the category.
In bagging algorithm, the way of equal voting is adopted. That is, each generated learner is given the same weight, each base learner casts a vote with equal weight, and finally determines the category according to the total result. There are two common combined voting methods: hard voting and soft voting.
1: Hard voting, who gets the most votes belongs to which category
2: For soft voting, first there must be probability output, and finally calculate the weight * prediction probability of all learners to obtain the probability predicted for each category. In the end, which category has a large probability output belongs to which category. Equivalent to a posteriori probability
P
(
c
i
∣
x
)
P(c_i|x)
P(ci∣x)(
c
i
c_i
ci: prediction category, x: sample).
# The previous import should also be used
from sklearn.metrics import plot_roc_curve
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# Generative decision tree, SVM, random forest learner
tree = DecisionTreeClassifier(criterion="gini",max_depth=3,random_state=1)
tree.fit(train_set,train_target)
forest = RandomForestClassifier(n_estimators=100,criterion="gini",max_depth=3,random_state=2)
forest.fit(train_set,train_target)
svc = SVC(C=1.0,kernel="rbf",degree=3,random_state=3,probability=True)
svc.fit(train_set,train_target)
from sklearn.ensemble import VotingClassifier
# Generate a voting classifier, and use the keyword parameter voting = 'soft' /'hard 'to control soft and hard voting
vote = VotingClassifier(estimators=[('dt',tree),('rf',forest),('svc',svc)],voting="soft")
vote.fit(train_set,train_target)
clf = [tree,forest,svc,vote]
for model in clf:
model.fit(train_set,train_target)
y_pred = model.predict(test_set)
score = accuracy_score(test_target,y_pred)
print(model.__class__.__name__,score)
# Draw their roc curve by the way
ax = plt.gca()
ax.grid(linestyle="dashed",alpha=0.6)
svc_display = plot_roc_curve(tree,test_set,test_target,ax=ax,color="red")
forest_display = plot_roc_curve(forest,test_set,test_target,ax=ax)
tree_display = plot_roc_curve(tree,test_set,test_target,ax=ax)
plt.show()
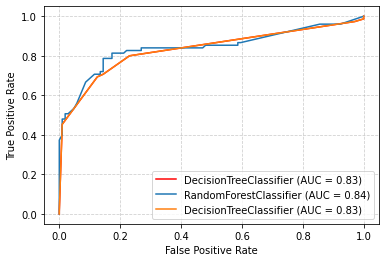
Note: there must be probability estimation to enable soft voting. Our common decision tree, random forest, will calculate probability, and SVM Classification depends on distance, so We need to start probability=True(Enable probability estimation)
Random Forest (Bagging deformation)
Random forest is an extended deformation algorithm of Bagging. It takes the decision tree as the base learner and introduces random attribute selection (k features are selected from m features each time) in the training process of the decision tree, so as to construct different decision trees. Finally, it depends on multiple decision trees to form a forest to predict the final result.
# Same as the previous code import package
# Get the data. The data here follow the Titanic data. You can download the data from the link in this article
# https://blog.csdn.net/qq_40725653/article/details/117922390?spm=1001.2014.3001.5501
dataset = pd.read_csv(r"E:\Jupyter\Pytorch\ML_Algorithm\Decision_tree\titanic\train.csv")
dataset = dataset.drop(columns=['Name','SibSp','Parch','Ticket','Fare','Cabin','Embarked'])
# Simple data processing to obtain features and labels
features = dataset.iloc[:,-3:]
target = dataset.loc[:,["Survived"]]
# Missing value processing, filled with average value
for line in features.columns:
if np.any(features[line].isnull())==True:
features[line].fillna(value=floor(round(features[line].mean(),1)),inplace=True)
from sklearn.feature_extraction import DictVectorizer
# Data segmentation
x_train,x_test,y_train,y_test = train_test_split(features,target,test_size=0.2,random_state=1)
# Characteristic Engineering
transfer = DictVectorizer(sparse=False)
x_train = transfer.fit_transform(x_train.to_dict(orient="records"))
x_test = transfer.fit_transform(x_test.to_dict(orient="records"))
estimator = RandomForestClassifier(max_features="auto")
param_grid = {"n_estimators":[10,30,50,80,100,120,150,100],"max_depth":[2,4,6,8]}
estimator = GridSearchCV(estimator,param_grid=param_grid,cv=10)
# Training model
estimator.fit(train_set,train_target)
# Model evaluation
score = estimator.score(test_set,test_target)
estimator.best_estimator_
Bagging summary
1: Sample data or features for learning 2: Average voting right of learner 3: In parallel learning, there is no strong dependence among learners 4: Bagging It is mainly used to reduce variance and over fitting to improve the generalization performance of the model