preface
In the previous article, we learned about the construction of apache druid and how to quickly import external data sources into apache druid for data analysis and use
In this article, we will talk about how apache druid can be used in a real project based on a simple application scenario
Business scenario
As shown below, it is a very common data analysis business. Generally speaking, many real-time or quasi real-time data (understood here as external data sources) need to be transferred through kafka, that is, sent to kafka,
apache druid provides the function of importing external data sources. It can receive data from the topic specified by kafka, and then support data analysis. After importing kafka data into apache druid, it can read the data through the program (background application) and read the data from kafka according to the actual business needs for logical processing
Finally, after the application processes the data, it writes to the library or outputs it as the data displayed on the large screen
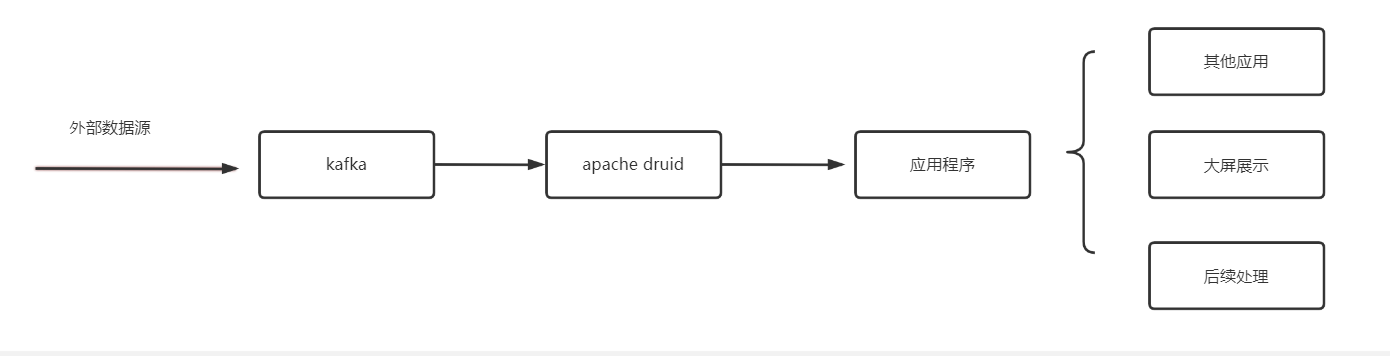
On this basis, this process can be applied to many related scenarios. For example, the source data is the processing result from the big data engine, or the result obtained by the python program crawler
Let's give a complete demonstration of this process from operation to code implementation
Pre preparation
- zookeeper and kafka built in docker or linux environment, and create a topic in advance
- Start apache druid service
Do kafaka's data test to verify that topic can send and receive messages normally


1. apache druid console connection kafka
loada data select kafka
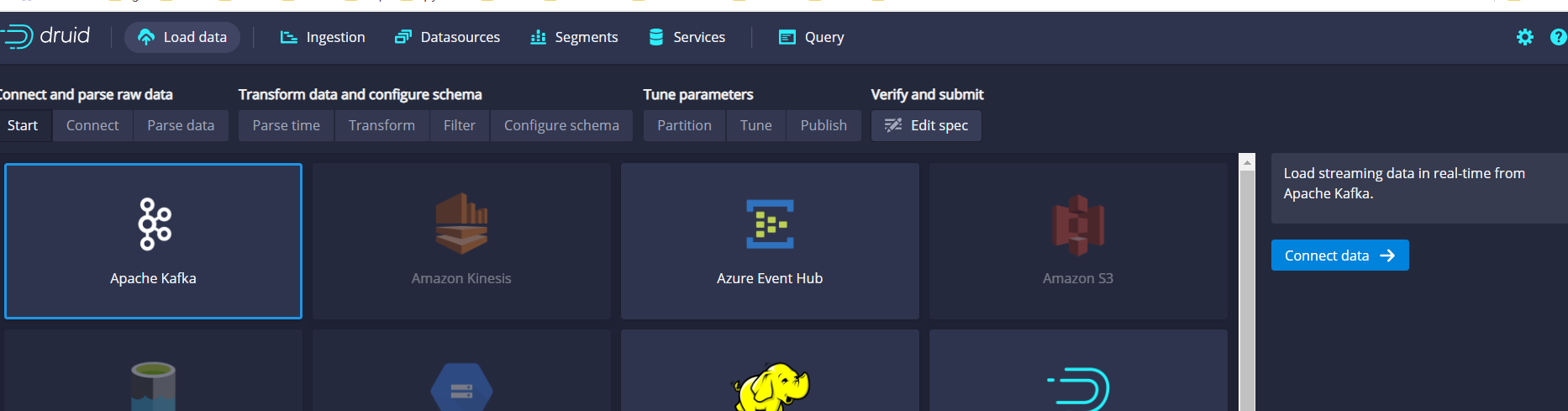
Just fill in kafka's connection information

Then wait all the way next for parsing. After parsing, check whether the following custom library name appears on the left through the query at the top
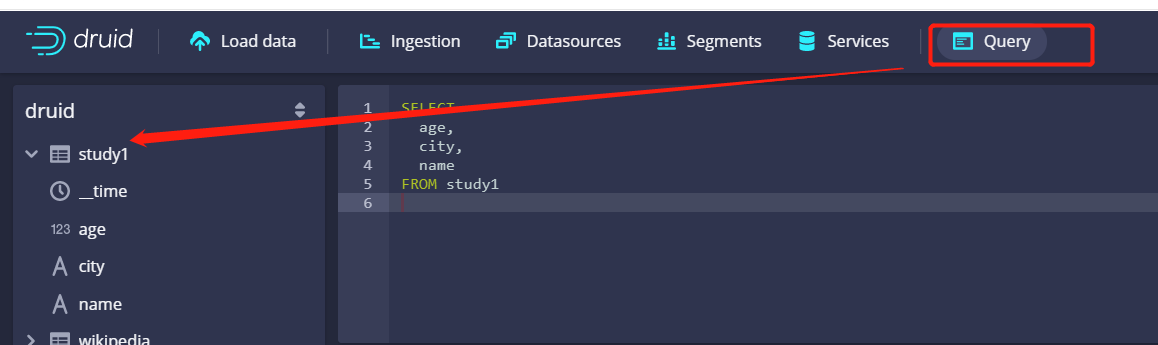
The above means that the data in a topic in kafka can be parsed into the apache druid library, and then the imported data can be managed and analyzed through apache druid
We might as well use sql to query. We can see that the data we just tested are displayed

2. Write a program to push messages to kafka regularly
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
public class KfkaTest {
public static void main(String[] args) {
AtomicLong atomicLong = new AtomicLong(1);
Runnable runnable = new Runnable() {
public void run() {
//Push messages to kafka regularly
long l = atomicLong.incrementAndGet();
pushMessage(l);
}
};
ScheduledExecutorService service = Executors
.newSingleThreadScheduledExecutor();
// The second parameter is the delay time of the first execution, and the third parameter is the interval time of timed execution
service.scheduleAtFixedRate(runnable, 10, 1, TimeUnit.SECONDS);
}
public static void pushMessage(long num) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "IP:9092");
properties.put("acks", "all");
properties.put("retries", "3");
properties.put("batch.size", "16384");
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
//Serialization of key and value
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//Construct producer object
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
ObjectMapper objectMapper = new ObjectMapper();
Map<String, Object> map = new HashMap<>();
map.put("name", "gaoliang:" + num);
map.put("age", 19);
map.put("city", "Shenzhen");
String val = null;
try {
val = objectMapper.writeValueAsString(map);
System.out.println(val);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
producer.send(new ProducerRecord<>("study1", "congge ", val));
//Close connection resource
producer.close();
}
}
3. Read the data of apache druid through the program
On this point, the method is very flexible. What is the processing of the read data? It depends on the specific needs of the business. For example, can the latest data read be returned to the page for display directly through the interface? Or do you store the data after logical processing? Or do you give it to other services for further use? Generally speaking, after reading, there are many application scenarios written to the library and displayed
Let's demonstrate how to read apache druid data in the program, which must be of concern to everyone
Add the following dependencies directly to the pom file
<dependency>
<groupId>org.apache.calcite.avatica</groupId>
<artifactId>avatica-core</artifactId>
<version>1.15.0</version>
</dependency>
apache druid officially provides the connection method for querying data through jdbc. The following is the code directly
import org.apache.calcite.avatica.AvaticaConnection;
import org.apache.calcite.avatica.AvaticaStatement;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Properties;
public class DruidTest {
private static final String DRUID_URL = "jdbc:avatica:remote:url=http://IP:8888/druid/v2/sql/avatica/";
private static ThreadLocal<AvaticaConnection> threadLocal = new ThreadLocal<>();
/**
* open a connection
* @param
* @return
* @throws SQLException
*/
public static AvaticaConnection connection() throws SQLException {
Properties properties = new Properties();
AvaticaConnection connection = (AvaticaConnection) DriverManager.getConnection(DRUID_URL, properties);
threadLocal.set(connection);
return connection;
}
/**
* Close connection
* @throws SQLException
*/
public static void closeConnection() throws SQLException{
System.out.println("Close thread:"+threadLocal.get());
AvaticaConnection conn = threadLocal.get();
if(conn != null){
conn.close();
threadLocal.remove();
}
}
/**
* According to sql query results
* @param
* @param sql
* @return
* @throws SQLException
*/
public static ResultSet executeQuery (String sql) throws SQLException{
AvaticaStatement statement = connection().createStatement();
ResultSet resultSet = statement.executeQuery(sql);
return resultSet;
}
public static void main(String[] args) {
try {
String sql = "SELECT * FROM \"study1\" limit 10";
for (int i = 0; i < 5; i++) {
ResultSet resultSet = executeQuery(sql);
System.out.println("Start connection"+i + "; Connection thread:"+threadLocal.get());
while(resultSet.next()){
String name = resultSet.getString("name");
System.out.println(name + " ; "+ name);
}
closeConnection();
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
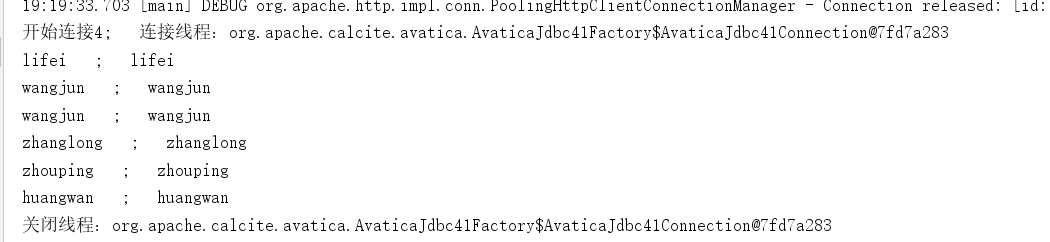
At this time, you might as well push another message to kafka's topic of study1

Query on the interface and you can see that the data has come

Run the program again, and it can also be read successfully

Above, a simple business scenario of how to use java programs to connect kafka and apache druid is described through the program and console. This article is relatively simple and does not involve the integration of specific functional levels. It is mainly to pave the way for further in-depth use of apache druid. I hope it will be useful to the students!