Intelligent target detection 18 -- Keras builds FasterRCNN target detection platform
- Learn foreword
- What is FasterRCNN target detection algorithm
- Source download
- Fast RCNN implementation ideas
- 1, Forecast part
- 1. Introduction to backbone network
- 2. Get Proposal box
- 3. Decoding of Proposal box
- 4. Utilize the Proposal box (RoiPoolingConv)
- 5. Draw on the original drawing
- 6. Overall execution process
- 2, Training part
- Training your own fast RCNN model
Learn foreword
Recently, I'm interested in instance segmentation, but the instance segmentation MaskRCNN is based on FasterRCNN. I've learned a lot of one stage target detection algorithms before, but I'm not interested in FasterRCNN. This time, I'll learn FasterRCNN.
What is FasterRCNN target detection algorithm
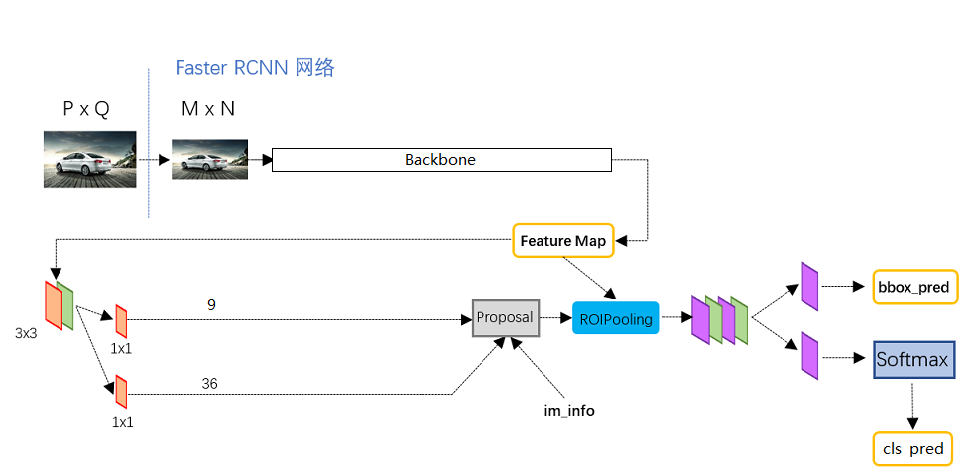
Fast RCNN is a very effective target detection algorithm. Although it is an earlier paper, it is still the basis of many target detection algorithms.
Fast RCNN as a two stage algorithm, compared with one stage algorithm, two stage algorithm is more complex and slower, but the detection accuracy will be higher.
In fact, it is also true that fast-rcnn has a very good detection effect, but the detection speed and training speed need to be improved.
Source download
https://github.com/bubbliiiing/faster-rcnn-keras
You can order a star if you like.
Fast RCNN implementation ideas
1, Forecast part
1. Introduction to backbone network
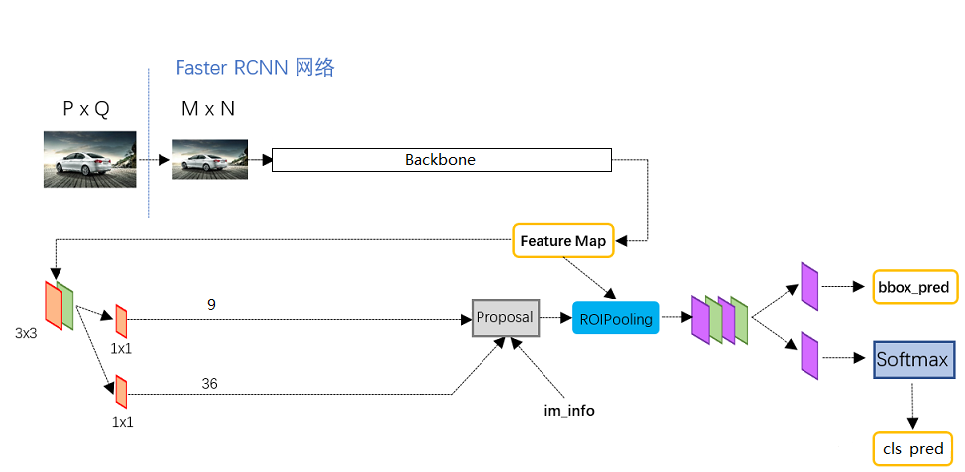
Fast RCNN can use a variety of backbone feature extraction networks, commonly used VGG, Resnet, Xception, etc., this paper uses Resnet network, you can see another blog about Resnet https://blog.csdn.net/weixin_44791964/article/details/102790260.
FasterRcnn does not fix the size of the input image, but generally fixes the short side of the input image to 600. For example, if you enter a 1200x1800 image, it will resize the image to 600x900 without distortion.
ResNet50 has two basic blocks, named Conv Block and Identity Block. The input and output dimensions of Conv Block are different, so they can't be connected in series continuously. Their function is to change the dimensions of the network. The input and output dimensions of Identity Block are the same, which can be connected in series to deepen the network.
The structure of Conv Block is as follows: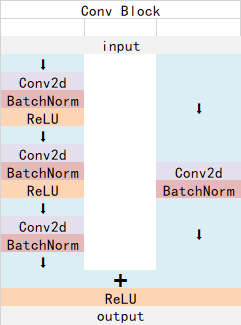
The structure of Identity Block is as follows:
Both are residual network structures.
Faster RCNN's backbone feature extraction network only contains the content compressed four times in length and width, and the content after the fifth compression is used in ROI. That is to say, the network layer used by fast-rcnn in the backbone feature extraction network is as shown in the figure.
Take the input picture of 600x600 as an example, the shape changes as follows:
The output of the last layer is the common feature layer.
Implementation code:
def identity_block(input_tensor, kernel_size, filters, stage, block): filters1, filters2, filters3 = filters conv_name_base = 'res' + str(stage) + block + '_branch' bn_name_base = 'bn' + str(stage) + block + '_branch' x = Conv2D(filters1, (1, 1), name=conv_name_base + '2a')(input_tensor) x = BatchNormalization(name=bn_name_base + '2a')(x) x = Activation('relu')(x) x = Conv2D(filters2, kernel_size,padding='same', name=conv_name_base + '2b')(x) x = BatchNormalization(name=bn_name_base + '2b')(x) x = Activation('relu')(x) x = Conv2D(filters3, (1, 1), name=conv_name_base + '2c')(x) x = BatchNormalization(name=bn_name_base + '2c')(x) x = layers.add([x, input_tensor]) x = Activation('relu')(x) return x def conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2, 2)): filters1, filters2, filters3 = filters conv_name_base = 'res' + str(stage) + block + '_branch' bn_name_base = 'bn' + str(stage) + block + '_branch' x = Conv2D(filters1, (1, 1), strides=strides, name=conv_name_base + '2a')(input_tensor) x = BatchNormalization(name=bn_name_base + '2a')(x) x = Activation('relu')(x) x = Conv2D(filters2, kernel_size, padding='same', name=conv_name_base + '2b')(x) x = BatchNormalization(name=bn_name_base + '2b')(x) x = Activation('relu')(x) x = Conv2D(filters3, (1, 1), name=conv_name_base + '2c')(x) x = BatchNormalization(name=bn_name_base + '2c')(x) shortcut = Conv2D(filters3, (1, 1), strides=strides, name=conv_name_base + '1')(input_tensor) shortcut = BatchNormalization(name=bn_name_base + '1')(shortcut) x = layers.add([x, shortcut]) x = Activation('relu')(x) return x def ResNet50(inputs): img_input = inputs x = ZeroPadding2D((3, 3))(img_input) x = Conv2D(64, (7, 7), strides=(2, 2), name='conv1')(x) x = BatchNormalization(name='bn_conv1')(x) x = Activation('relu')(x) x = MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x) x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1)) x = identity_block(x, 3, [64, 64, 256], stage=2, block='b') x = identity_block(x, 3, [64, 64, 256], stage=2, block='c') x = conv_block(x, 3, [128, 128, 512], stage=3, block='a') x = identity_block(x, 3, [128, 128, 512], stage=3, block='b') x = identity_block(x, 3, [128, 128, 512], stage=3, block='c') x = identity_block(x, 3, [128, 128, 512], stage=3, block='d') x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f') return x
2. Get Proposal box
The common feature layer obtained in the image is Feature Map, which has two applications, one is used in combination with ROIPooling, the other is to carry out a 3 x 3 convolution, a 9-channel 1 x 1 convolution, and a 36 channel 1 x 1 convolution.
In fast RCNN, num ﹣ priors, that is, the number of priori boxes is 9, so the results of two 1x1 convolutions are actually:
9 x 4 convolution is used to predict the change of every prior box on every grid point in the common feature layer. (why is the change? This is because the prediction results of fast RCNN need to be combined with the prior frame to get the prediction frame. The prediction results are the change of the prior frame.)
9 x 1 convolution is used to predict whether objects are contained in each prediction frame of each grid point on the common feature layer.
When the shape of the image we input is 600x600x3, the shape of the common feature layer is 38x38x1024, which is equivalent to dividing the input image into 38x38 grids, and then there are 9 prior boxes in each grid. These prior boxes have different sizes and are dense on the image.
The result of 9 x 4 convolution will adjust these prior frames to get a new frame.
The convolution of 9 x 1 will determine whether the new frame obtained above contains an object.
Here we can get some useful frames, which will use 9 x 1 convolution to determine whether there is an object.
This position is only a rough box acquisition, that is, a suggestion box. Then we will continue to look for things in the suggestion box.
The implementation code is:
def get_rpn(base_layers, num_anchors): x = Conv2D(512, (3, 3), padding='same', activation='relu', kernel_initializer='normal', name='rpn_conv1')(base_layers) x_class = Conv2D(num_anchors, (1, 1), activation='sigmoid', kernel_initializer='uniform', name='rpn_out_class')(x) x_regr = Conv2D(num_anchors * 4, (1, 1), activation='linear', kernel_initializer='zero', name='rpn_out_regress')(x) x_class = Reshape((-1,1),name="classification")(x_class) x_regr = Reshape((-1,4),name="regression")(x_regr) return [x_class, x_regr, base_layers]
3. Decoding of Proposal box
In the second step, we get the prediction results of 38x38x9 priori boxes. The forecast results consist of two parts.
9 x 4 convolution is used to predict the change of every prior box on every grid point in the common feature layer. * *
9 x 1 convolution is used to predict whether objects are contained in each prediction frame of each grid point on the common feature layer.
It is equivalent to dividing the whole image into 38x38 grids, and then establishing 9 prior boxes from each grid center, a total of 38x38x9, 12996 prior boxes.
When the input image shape s are different, the number of prior boxes will also change.
Although a priori box can represent the location information and size information of a certain box, it is limited and cannot represent any situation, so it needs to be adjusted.
9 in 9 x 4 represents the number of prior boxes contained in this grid point, and 4 represents the adjustment of the center and length and width of the box.
The implementation code is as follows:
def decode_boxes(self, mbox_loc, mbox_priorbox):
# Get the width and height of a priori box
prior_width = mbox_priorbox[:, 2] - mbox_priorbox[:, 0]
prior_height = mbox_priorbox[:, 3] - mbox_priorbox[:, 1]
# Get the center point of the prior box
prior_center_x = 0.5 * (mbox_priorbox[:, 2] + mbox_priorbox[:, 0])
prior_center_y = 0.5 * (mbox_priorbox[:, 3] + mbox_priorbox[:, 1])
# Deviation of xy axis of real frame from the center of prior frame
decode_bbox_center_x = mbox_loc[:, 0] * prior_width / 4
decode_bbox_center_x += prior_center_x
decode_bbox_center_y = mbox_loc[:, 1] * prior_height / 4
decode_bbox_center_y += prior_center_y
# The width and height of real frame
decode_bbox_width = np.exp(mbox_loc[:, 2] / 4)
decode_bbox_width *= prior_width
decode_bbox_height = np.exp(mbox_loc[:, 3] /4)
decode_bbox_height *= prior_height
# Get the upper left and lower right corner of the real box
decode_bbox_xmin = decode_bbox_center_x - 0.5 * decode_bbox_width
decode_bbox_ymin = decode_bbox_center_y - 0.5 * decode_bbox_height
decode_bbox_xmax = decode_bbox_center_x + 0.5 * decode_bbox_width
decode_bbox_ymax = decode_bbox_center_y + 0.5 * decode_bbox_height
# The upper left and lower right corners of the real box are stacked
decode_bbox = np.concatenate((decode_bbox_xmin[:, None],
decode_bbox_ymin[:, None],
decode_bbox_xmax[:, None],
decode_bbox_ymax[:, None]), axis=-1)
# Prevent exceeding 0 and 1
decode_bbox = np.minimum(np.maximum(decode_bbox, 0.0), 1.0)
return decode_bbox
def detection_out(self, predictions, mbox_priorbox, num_classes, keep_top_k=300,
confidence_threshold=0.5):
# Results of network prediction
# Confidence level
mbox_conf = predictions[0]
mbox_loc = predictions[1]
# Prior frame
mbox_priorbox = mbox_priorbox
results = []
# Process each picture
for i in range(len(mbox_loc)):
results.append([])
decode_bbox = self.decode_boxes(mbox_loc[i], mbox_priorbox)
for c in range(num_classes):
c_confs = mbox_conf[i, :, c]
c_confs_m = c_confs > confidence_threshold
if len(c_confs[c_confs_m]) > 0:
# Take out the box with the score higher than the confidence_threshold
boxes_to_process = decode_bbox[c_confs_m]
confs_to_process = c_confs[c_confs_m]
# Non maximum suppression of iou
feed_dict = {self.boxes: boxes_to_process,
self.scores: confs_to_process}
idx = self.sess.run(self.nms, feed_dict=feed_dict)
# Take out the content with better effect in non maximum inhibition
good_boxes = boxes_to_process[idx]
confs = confs_to_process[idx][:, None]
# Stack the label, confidence and box position.
labels = c * np.ones((len(idx), 1))
c_pred = np.concatenate((labels, confs, good_boxes),
axis=1)
# Add to result
results[-1].extend(c_pred)
if len(results[-1]) > 0:
# Sort by confidence
results[-1] = np.array(results[-1])
argsort = np.argsort(results[-1][:, 1])[::-1]
results[-1] = results[-1][argsort]
# Select the most reliable keep top k
results[-1] = results[-1][:keep_top_k]
# In all the prediction results, we get the box with high confidence
# In addition, the location of the real box (prediction box) is obtained by using the prediction results of prior box and fast RCNN
return results
4. Utilize the Proposal box (RoiPoolingConv)
Let's have a holistic understanding of the suggestion box:
In fact, the suggestion box is a preliminary screening of which area of the image has objects.
Through the backbone feature extraction network, we can get a common feature layer. When the input picture is 600x600x3, its shape is 38x38x1024, and then the suggestion box will intercept the common feature layer.
In fact, the 38x38 in the common feature layer corresponds to the 38x38 areas in the picture, and each point in the 38x38 corresponds to the concentration of all features in this area.
The suggestion box will intercept these 38x38 areas, that is to say, there are targets in these areas, and then resize the intercepted results to the size of 14x14x1024.
The default number of suggestion boxes per input is 32.
Then, the original fifth Resnet compression is performed for each suggestion box. After compression, an average pool is made, and then a Flatten is made. Finally, a full connection of num classes and (Num classes-1) X4 full connection are made respectively.
The full connection of num classes is used to classify the final obtained boxes, (Num classes-1) X4 full connection is used to adjust the corresponding suggestion boxes, so - 1 does not include the boxes identified as background.
Through these operations, we can get the adjustment of all suggestion boxes and the categories of objects in the box after the adjustment of this suggestion box.
In fact, the suggestion box obtained in the previous step is the prior box of ROI.
The process and shape changes of using the Proposal box are shown in the figure:
The result after the adjustment of suggestion box is the final prediction result, which can be drawn on the graph.
class RoiPoolingConv(Layer): def __init__(self, pool_size, num_rois, **kwargs): self.dim_ordering = K.image_dim_ordering() assert self.dim_ordering in {'tf', 'th'}, 'dim_ordering must be in {tf, th}' self.pool_size = pool_size self.num_rois = num_rois super(RoiPoolingConv, self).__init__(**kwargs) def build(self, input_shape): self.nb_channels = input_shape[0][3] def compute_output_shape(self, input_shape): return None, self.num_rois, self.pool_size, self.pool_size, self.nb_channels def call(self, x, mask=None): assert(len(x) == 2) img = x[0] rois = x[1] outputs = [] for roi_idx in range(self.num_rois): x = rois[0, roi_idx, 0] y = rois[0, roi_idx, 1] w = rois[0, roi_idx, 2] h = rois[0, roi_idx, 3] x = K.cast(x, 'int32') y = K.cast(y, 'int32') w = K.cast(w, 'int32') h = K.cast(h, 'int32') rs = tf.image.resize_images(img[:, y:y+h, x:x+w, :], (self.pool_size, self.pool_size)) outputs.append(rs) final_output = K.concatenate(outputs, axis=0) final_output = K.reshape(final_output, (1, self.num_rois, self.pool_size, self.pool_size, self.nb_channels)) final_output = K.permute_dimensions(final_output, (0, 1, 2, 3, 4)) return final_output def identity_block_td(input_tensor, kernel_size, filters, stage, block, trainable=True): nb_filter1, nb_filter2, nb_filter3 = filters if K.image_dim_ordering() == 'tf': bn_axis = 3 else: bn_axis = 1 conv_name_base = 'res' + str(stage) + block + '_branch' bn_name_base = 'bn' + str(stage) + block + '_branch' x = TimeDistributed(Conv2D(nb_filter1, (1, 1), trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '2a')(input_tensor) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2a')(x) x = Activation('relu')(x) x = TimeDistributed(Conv2D(nb_filter2, (kernel_size, kernel_size), trainable=trainable, kernel_initializer='normal',padding='same'), name=conv_name_base + '2b')(x) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2b')(x) x = Activation('relu')(x) x = TimeDistributed(Conv2D(nb_filter3, (1, 1), trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '2c')(x) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2c')(x) x = Add()([x, input_tensor]) x = Activation('relu')(x) return x def conv_block_td(input_tensor, kernel_size, filters, stage, block, input_shape, strides=(2, 2), trainable=True): nb_filter1, nb_filter2, nb_filter3 = filters if K.image_dim_ordering() == 'tf': bn_axis = 3 else: bn_axis = 1 conv_name_base = 'res' + str(stage) + block + '_branch' bn_name_base = 'bn' + str(stage) + block + '_branch' x = TimeDistributed(Conv2D(nb_filter1, (1, 1), strides=strides, trainable=trainable, kernel_initializer='normal'), input_shape=input_shape, name=conv_name_base + '2a')(input_tensor) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2a')(x) x = Activation('relu')(x) x = TimeDistributed(Conv2D(nb_filter2, (kernel_size, kernel_size), padding='same', trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '2b')(x) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2b')(x) x = Activation('relu')(x) x = TimeDistributed(Conv2D(nb_filter3, (1, 1), kernel_initializer='normal'), name=conv_name_base + '2c', trainable=trainable)(x) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2c')(x) shortcut = TimeDistributed(Conv2D(nb_filter3, (1, 1), strides=strides, trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '1')(input_tensor) shortcut = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '1')(shortcut) x = Add()([x, shortcut]) x = Activation('relu')(x) return x def classifier_layers(x, input_shape, trainable=False): x = conv_block_td(x, 3, [512, 512, 2048], stage=5, block='a', input_shape=input_shape, strides=(2, 2), trainable=trainable) x = identity_block_td(x, 3, [512, 512, 2048], stage=5, block='b', trainable=trainable) x = identity_block_td(x, 3, [512, 512, 2048], stage=5, block='c', trainable=trainable) x = TimeDistributed(AveragePooling2D((7, 7)), name='avg_pool')(x) return x def get_classifier(base_layers, input_rois, num_rois, nb_classes=21, trainable=False): pooling_regions = 14 input_shape = (num_rois, 14, 14, 1024) out_roi_pool = RoiPoolingConv(pooling_regions, num_rois)([base_layers, input_rois]) out = classifier_layers(out_roi_pool, input_shape=input_shape, trainable=True) out = TimeDistributed(Flatten())(out) out_class = TimeDistributed(Dense(nb_classes, activation='softmax', kernel_initializer='zero'), name='dense_class_{}'.format(nb_classes))(out) out_regr = TimeDistributed(Dense(4 * (nb_classes-1), activation='linear', kernel_initializer='zero'), name='dense_regress_{}'.format(nb_classes))(out) return [out_class, out_regr]
5. Draw on the original drawing
At the end of the fourth step, we can get the position of the prediction box on the original image after we carry on the suggestion box again, and these prediction boxes are all filtered. These filtered boxes can be drawn directly on the picture to get the results.
6. Overall execution process
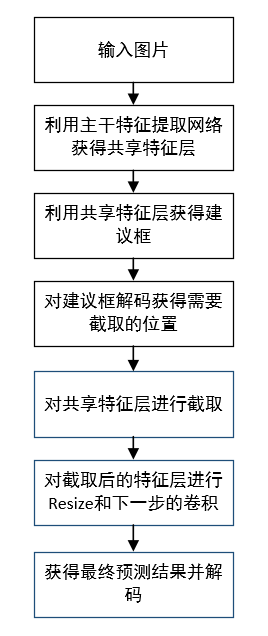
Some tip s:
1. It includes two decoding processes.
2. Make a rough selection first and then fine tuning.
3. The result of the first decoding of the proposed frame is to intercept the feature map of the shared feature layer.
2, Training part
The training process of faster RCNN is the same as its prediction process, which is divided into two parts. First, we need to train the network of suggestion frame, and then train the network of prediction results using ROI.
1. Training of suggestion box network
If the common feature layer wants to get the prediction result of the suggestion box, it needs to do a 3 x 3 convolution again, then a 9-channel 1 x 1 convolution and a 36 channel 1 x 1 convolution.
In fast RCNN, num ﹣ priors, that is, the number of priori boxes is 9, so the results of two 1x1 convolutions are actually:
9 x 4 convolution is used to predict the change of every prior box on every grid point in the common feature layer. (why is the change? This is because the prediction results of fast RCNN need to be combined with the prior frame to get the prediction frame. The prediction results are the change of the prior frame.)
9 x 1 convolution is used to predict whether objects are contained in each prediction frame of each grid point on the common feature layer.
That is to say, the result predicted by faster RCNN suggestion box network is not the real position of suggestion box on the picture, which needs to be decoded to get the real position.
In training, we need to calculate the loss function, which is relative to the prediction result of fast RCNN recommendation box network. We need to input the picture into the network of the current fast RCNN suggestion box to get the result of the suggestion box; at the same time, we need to code, which is to transform the location information format of the real box into the format information of the prediction result of the fast RCNN suggestion box.
In other words, we need to find the prior box corresponding to each real box of each picture used for training, and find out what the prediction result of our suggestion box should be if we want to get such a real box.
The process of obtaining the real frame from the prediction result of the recommendation frame is called decoding, and the process of obtaining the prediction result of the recommendation frame from the real frame is the process of encoding.
So we just need to reverse the decoding process is the encoding process.
The implementation code is as follows:
def encode_box(self, box, return_iou=True): iou = self.iou(box) encoded_box = np.zeros((self.num_priors, 4 + return_iou)) # Find each real box, a priori box with a higher degree of coincidence assign_mask = iou > self.overlap_threshold if not assign_mask.any(): assign_mask[iou.argmax()] = True if return_iou: encoded_box[:, -1][assign_mask] = iou[assign_mask] # Find the corresponding prior box assigned_priors = self.priors[assign_mask] # Reverse coding, converting the real box to the format of Retinanet prediction results # Calculate the center, length and width of the real frame first box_center = 0.5 * (box[:2] + box[2:]) box_wh = box[2:] - box[:2] # Then calculate the center, length and width of the prior frame with high coincidence assigned_priors_center = 0.5 * (assigned_priors[:, :2] + assigned_priors[:, 2:4]) assigned_priors_wh = (assigned_priors[:, 2:4] - assigned_priors[:, :2]) # Reverse computing the prediction result of ssd encoded_box[:, :2][assign_mask] = box_center - assigned_priors_center encoded_box[:, :2][assign_mask] /= assigned_priors_wh encoded_box[:, :2][assign_mask] *= 4 encoded_box[:, 2:4][assign_mask] = np.log(box_wh / assigned_priors_wh) encoded_box[:, 2:4][assign_mask] *= 4 return encoded_box.ravel()
Using the above code, we can get all the larger prior boxes of iou corresponding to the real box, and calculate the prediction results of all the larger prior boxes of iou corresponding to the real box.
However, because there may be multiple real frames in the original image, it is possible that the same prior frame will have a high degree of coincidence with multiple real frames. We only take the one with the highest degree of coincidence with the real frame.
Therefore, we also need to go through a filter to filter out the largest real box of the prediction results of all the larger prior boxes of iou corresponding to the real box obtained by the above code.
Through assign boxes, we can get the prediction result of the input image.
The implementation code is as follows:
def iou(self, box): # Calculate the iou of each real box and all prior boxes # Judge the coincidence of real box and prior box inter_upleft = np.maximum(self.priors[:, :2], box[:2]) inter_botright = np.minimum(self.priors[:, 2:4], box[2:]) inter_wh = inter_botright - inter_upleft inter_wh = np.maximum(inter_wh, 0) inter = inter_wh[:, 0] * inter_wh[:, 1] # Area of real frame area_true = (box[2] - box[0]) * (box[3] - box[1]) # Area of prior box area_gt = (self.priors[:, 2] - self.priors[:, 0])*(self.priors[:, 3] - self.priors[:, 1]) # Calculate iou union = area_true + area_gt - inter iou = inter / union return iou def encode_box(self, box, return_iou=True): iou = self.iou(box) encoded_box = np.zeros((self.num_priors, 4 + return_iou)) # Find each real box, a priori box with a higher degree of coincidence assign_mask = iou > self.overlap_threshold if not assign_mask.any(): assign_mask[iou.argmax()] = True if return_iou: encoded_box[:, -1][assign_mask] = iou[assign_mask] # Find the corresponding prior box assigned_priors = self.priors[assign_mask] # Reverse coding, converting the real box to the format of Retinanet prediction results # Calculate the center, length and width of the real frame first box_center = 0.5 * (box[:2] + box[2:]) box_wh = box[2:] - box[:2] # Then calculate the center, length and width of the prior frame with high coincidence assigned_priors_center = 0.5 * (assigned_priors[:, :2] + assigned_priors[:, 2:4]) assigned_priors_wh = (assigned_priors[:, 2:4] - assigned_priors[:, :2]) # Reverse computing the prediction result of ssd encoded_box[:, :2][assign_mask] = box_center - assigned_priors_center encoded_box[:, :2][assign_mask] /= assigned_priors_wh encoded_box[:, :2][assign_mask] *= 4 encoded_box[:, 2:4][assign_mask] = np.log(box_wh / assigned_priors_wh) encoded_box[:, 2:4][assign_mask] *= 4 return encoded_box.ravel() def ignore_box(self, box): iou = self.iou(box) ignored_box = np.zeros((self.num_priors, 1)) # Find each real box, a priori box with a higher degree of coincidence assign_mask = (iou > self.ignore_threshold)&(iou<self.overlap_threshold) if not assign_mask.any(): assign_mask[iou.argmax()] = True ignored_box[:, 0][assign_mask] = iou[assign_mask] return ignored_box.ravel() def assign_boxes(self, boxes, anchors): self.num_priors = len(anchors) self.priors = anchors assignment = np.zeros((self.num_priors, 4 + 1)) assignment[:, 4] = 0.0 if len(boxes) == 0: return assignment # iou calculation for each real frame ingored_boxes = np.apply_along_axis(self.ignore_box, 1, boxes[:, :4]) # Take the prior box with the largest coincidence degree, and obtain the index of the prior box ingored_boxes = ingored_boxes.reshape(-1, self.num_priors, 1) # (num_priors) ignore_iou = ingored_boxes[:, :, 0].max(axis=0) # (num_priors) ignore_iou_mask = ignore_iou > 0 assignment[:, 4][ignore_iou_mask] = -1 # (n, num_priors, 5) encoded_boxes = np.apply_along_axis(self.encode_box, 1, boxes[:, :4]) # The encoded value of each real frame, and iou # (n, num_priors) encoded_boxes = encoded_boxes.reshape(-1, self.num_priors, 5) # Take the prior box with the largest coincidence degree, and obtain the index of the prior box # (num_priors) best_iou = encoded_boxes[:, :, -1].max(axis=0) # (num_priors) best_iou_idx = encoded_boxes[:, :, -1].argmax(axis=0) # (num_priors) best_iou_mask = best_iou > 0 # Which real box does a priori box belong to best_iou_idx = best_iou_idx[best_iou_mask] assign_num = len(best_iou_idx) # The prediction results of the prior box with the largest coincidence # Which prior boxes have real boxes encoded_boxes = encoded_boxes[:, best_iou_mask, :] assignment[:, :4][best_iou_mask] = encoded_boxes[best_iou_idx,np.arange(assign_num),:4] # 4 represents the probability of background, which is 0 assignment[:, 4][best_iou_mask] = 1 # Through assign boxes, we can get the prediction result of the input image return assignment
focal ignores some priori boxes with relatively high but not very high coincidence degree, and generally ignores the priori boxes with coincidence degree between 0.3-0.7.
2. Training of Roi network
The suggestion box network can be trained in the previous step. The suggestion box network will provide some suggestions on the location. In the ROI network part, it will intercept the suggestion box according to a certain degree and obtain the corresponding prediction results. In fact, it is the suggestion box in the previous step as the prior frame of the ROI network.
Therefore, we need to calculate the coincidence degree of all suggestion boxes and real boxes, and filter them. If the coincidence degree of a real box and suggestion box is greater than 0.5, the suggestion box is considered as a positive sample. If the coincidence degree is less than 0.5 and greater than 0.1, the suggestion box is considered as a negative sample
So we can code the real frame, which is relative to the suggestion frame, that is, when we have these suggestion frames, what kind of prediction results our ROI prediction network needs to have in order to adjust these suggestion frames to the real frame.
We put 32 suggestion boxes into each training, and pay attention to the balance of positive and negative samples.
The implementation code is as follows:
# Code def calc_iou(R, config, all_boxes, width, height, num_classes): # print(all_boxes) bboxes = all_boxes[:,:4] gta = np.zeros((len(bboxes), 4)) for bbox_num, bbox in enumerate(bboxes): gta[bbox_num, 0] = int(round(bbox[0]*width/config.rpn_stride)) gta[bbox_num, 1] = int(round(bbox[1]*height/config.rpn_stride)) gta[bbox_num, 2] = int(round(bbox[2]*width/config.rpn_stride)) gta[bbox_num, 3] = int(round(bbox[3]*height/config.rpn_stride)) x_roi = [] y_class_num = [] y_class_regr_coords = [] y_class_regr_label = [] IoUs = [] # print(gta) for ix in range(R.shape[0]): x1 = R[ix, 0]*width/config.rpn_stride y1 = R[ix, 1]*height/config.rpn_stride x2 = R[ix, 2]*width/config.rpn_stride y2 = R[ix, 3]*height/config.rpn_stride x1 = int(round(x1)) y1 = int(round(y1)) x2 = int(round(x2)) y2 = int(round(y2)) # print([x1, y1, x2, y2]) best_iou = 0.0 best_bbox = -1 for bbox_num in range(len(bboxes)): curr_iou = iou([gta[bbox_num, 0], gta[bbox_num, 1], gta[bbox_num, 2], gta[bbox_num, 3]], [x1, y1, x2, y2]) if curr_iou > best_iou: best_iou = curr_iou best_bbox = bbox_num # print(best_iou) if best_iou < config.classifier_min_overlap: continue else: w = x2 - x1 h = y2 - y1 x_roi.append([x1, y1, w, h]) IoUs.append(best_iou) if config.classifier_min_overlap <= best_iou < config.classifier_max_overlap: label = -1 elif config.classifier_max_overlap <= best_iou: label = int(all_boxes[best_bbox,-1]) cxg = (gta[best_bbox, 0] + gta[best_bbox, 2]) / 2.0 cyg = (gta[best_bbox, 1] + gta[best_bbox, 3]) / 2.0 cx = x1 + w / 2.0 cy = y1 + h / 2.0 tx = (cxg - cx) / float(w) ty = (cyg - cy) / float(h) tw = np.log((gta[best_bbox, 2] - gta[best_bbox, 0]) / float(w)) th = np.log((gta[best_bbox, 3] - gta[best_bbox, 1]) / float(h)) else: print('roi = {}'.format(best_iou)) raise RuntimeError # print(label) class_label = num_classes * [0] class_label[label] = 1 y_class_num.append(copy.deepcopy(class_label)) coords = [0] * 4 * (num_classes - 1) labels = [0] * 4 * (num_classes - 1) if label != -1: label_pos = 4 * label sx, sy, sw, sh = config.classifier_regr_std coords[label_pos:4+label_pos] = [sx*tx, sy*ty, sw*tw, sh*th] labels[label_pos:4+label_pos] = [1, 1, 1, 1] y_class_regr_coords.append(copy.deepcopy(coords)) y_class_regr_label.append(copy.deepcopy(labels)) else: y_class_regr_coords.append(copy.deepcopy(coords)) y_class_regr_label.append(copy.deepcopy(labels)) if len(x_roi) == 0: return None, None, None, None X = np.array(x_roi) # print(X) Y1 = np.array(y_class_num) Y2 = np.concatenate([np.array(y_class_regr_label),np.array(y_class_regr_coords)],axis=1) return np.expand_dims(X, axis=0), np.expand_dims(Y1, axis=0), np.expand_dims(Y2, axis=0), IoUs # Positive and negative sample balance X2, Y1, Y2, IouS = calc_iou(R, config, boxes[0], width, height, NUM_CLASSES) if X2 is None: rpn_accuracy_rpn_monitor.append(0) rpn_accuracy_for_epoch.append(0) continue neg_samples = np.where(Y1[0, :, -1] == 1) pos_samples = np.where(Y1[0, :, -1] == 0) if len(neg_samples) > 0: neg_samples = neg_samples[0] else: neg_samples = [] if len(pos_samples) > 0: pos_samples = pos_samples[0] else: pos_samples = [] rpn_accuracy_rpn_monitor.append(len(pos_samples)) rpn_accuracy_for_epoch.append((len(pos_samples))) if len(neg_samples)==0: continue if len(pos_samples) < config.num_rois//2: selected_pos_samples = pos_samples.tolist() else: selected_pos_samples = np.random.choice(pos_samples, config.num_rois//2, replace=False).tolist() try: selected_neg_samples = np.random.choice(neg_samples, config.num_rois - len(selected_pos_samples), replace=False).tolist() except: selected_neg_samples = np.random.choice(neg_samples, config.num_rois - len(selected_pos_samples), replace=True).tolist() sel_samples = selected_pos_samples + selected_neg_samples loss_class = model_classifier.train_on_batch([X, X2[:, sel_samples, :]], [Y1[:, sel_samples, :], Y2[:, sel_samples, :]])
Training your own fast RCNN model
The overall folder structure of fast-rcnn is as follows:
This paper uses VOC format for training.
Before training, put the label file in the Annotation under voc207 folder under VOCdevkit folder.
Before training, put the picture file in JPEGImages under VOC2007 folder under VOCdevkit folder.
Before training, the corresponding txt is generated by using voc2faster-rcnn.py file.
Then run voc_annotation.py under the root directory. Before running, you need to change the classes to your own.
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
The corresponding 2007 ﹣ train.txt will be generated, and each line corresponds to the position of its picture and its real box.
Before training, you need to modify the VOC classes.txt file in the model data. You need to change the classes to your own.
Run train.py to start training.

