
(1) The significance of interface automation test and the idea of separation of front and back ends
Advantages and disadvantages of interface automation test:
advantage:
1. Test reusability.
2. The maintenance cost is lower than that of UI automation.
Why? UI Higher automated maintenance costs? Because the front page changes too fast, and UI Automation is time-consuming (for example, it takes time to wait for page elements to load, add waiting time, locate elements, operate elements, and simulate page actions) Why is the cost of interface automation low? Because the interface is relatively stable, the response time of the interface is basically seconds and milliseconds, and the speed is fast. Moreover, the interface automation itself can also do some related operations and whole process operations (such as registration) --> Sign in --> Modify personal information).
3. Easy to return.
4. You can run more and more cumbersome tests. An obvious benefit of automation is that more tests can be run in less time.
Advantages 1, 3 and 4 are interface automation and UI Advantages of automation.
Disadvantages:
1. It cannot completely replace manual testing. (automation can never replace manual testing, but only improve testing efficiency)
2. Manual testing finds more defects than automated testing, and automated testing is not easy to find new bugs.
Difference between GET request and POST request:
1. Generally, the GET request is to obtain data from the background server for the display of the front-end page (for example, see the list page), and the POST request is to transmit data to the server (login, registration, uploading files, publishing articles). When to use GET and when to use POST depends on development. Whether POST request or GET request is used, data addition, deletion, modification and query can be completed. Different request methods are more an agreement.
2. The request parameters of the GET request are spliced behind the url and can only be transmitted in the form of text. The request parameters will be displayed in the address bar. The data length is limited by the length of the url, and the amount of data transmitted is small (about 4KB, which will vary from browser to browser). The request parameters of the POST request are placed in the request body, and the amount of data transmitted is large (8M by default), There is no requirement for data length. GET requests can be accessed directly in the browser, while POST requests can only be completed with tools (such as postman and jmeter).
Fast GET request speed and low security; POST requests are generally used in situations with high security requirements such as login. The requests will not be cached or retained in the browser's history.
Previously: get Query; post newly added; put Editing; delete delete Now? get Query; post newly added + edit + delete Or: pure post Walk the world
Front and rear end separation
Development mode
The old way:
- Product Manager / Leader / customer puts forward requirements (puts forward written requirements)
- Make design drawings for UI
- Front end engineers make html pages (pages that users can see)
- The back-end engineer sets the html page into a jsp page (the front and back ends are strongly dependent, and the back-end must wait until the front-end html page is ready to set the jsp. If the html changes, it will be very troublesome and the development efficiency is low)
- There is a problem with the integration
- Front end rework
- Back end rework
- Secondary integration
- Successful integration
- deliver
New ways:
- Product Manager / Leader / customer puts forward requirements (puts forward written requirements)
- Make design drawings for UI
- Agreed interface & Data & parameters at front and back end
- Front and back end parallel development (without strong dependence, front and back end parallel development can be used. If the requirements change, as long as the interface & parameters remain unchanged, there is no need to modify the code on both sides, and the development efficiency is high)
- Front and rear integration
- Front page adjustment
- Successful integration
- deliver
🤑 Open the browser developer tool through F12 to capture packets. The returned data is in json format, that is, the front and back ends are separated. When returning, the html page is not separated from the front and back ends.
Concept of microservice:
Divide large modules into small modules. Reduce the coupling degree of code, so as to reduce the impact between modules. Originally, a jar package contains all modules. Changing one module may affect other modules. Now it is to break one module into one jar package. The interaction between modules is through the interface. If there is a problem with which module, you only need to modify the jar package of that module to avoid errors in other modules caused by modifying the code of one module.
(2) Explanation of Python requests framework
Establishment of interface automation requests environment
Interface automation core library: requests
How to install the requests Library:
Method 1:
Command line installation, open cmd or terminal, and enter the following command:
pip install requests -i https://pypi.douban.com/simple/
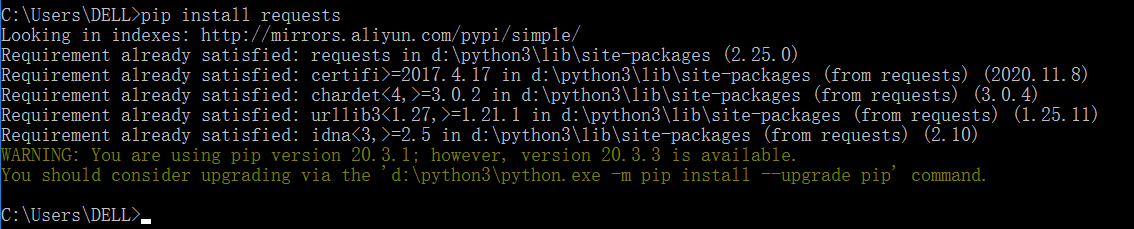
Method 2:
Install in pycharm, settings -- > Project -- > project interpreter -- > click the "+" sign -- > enter the request to install
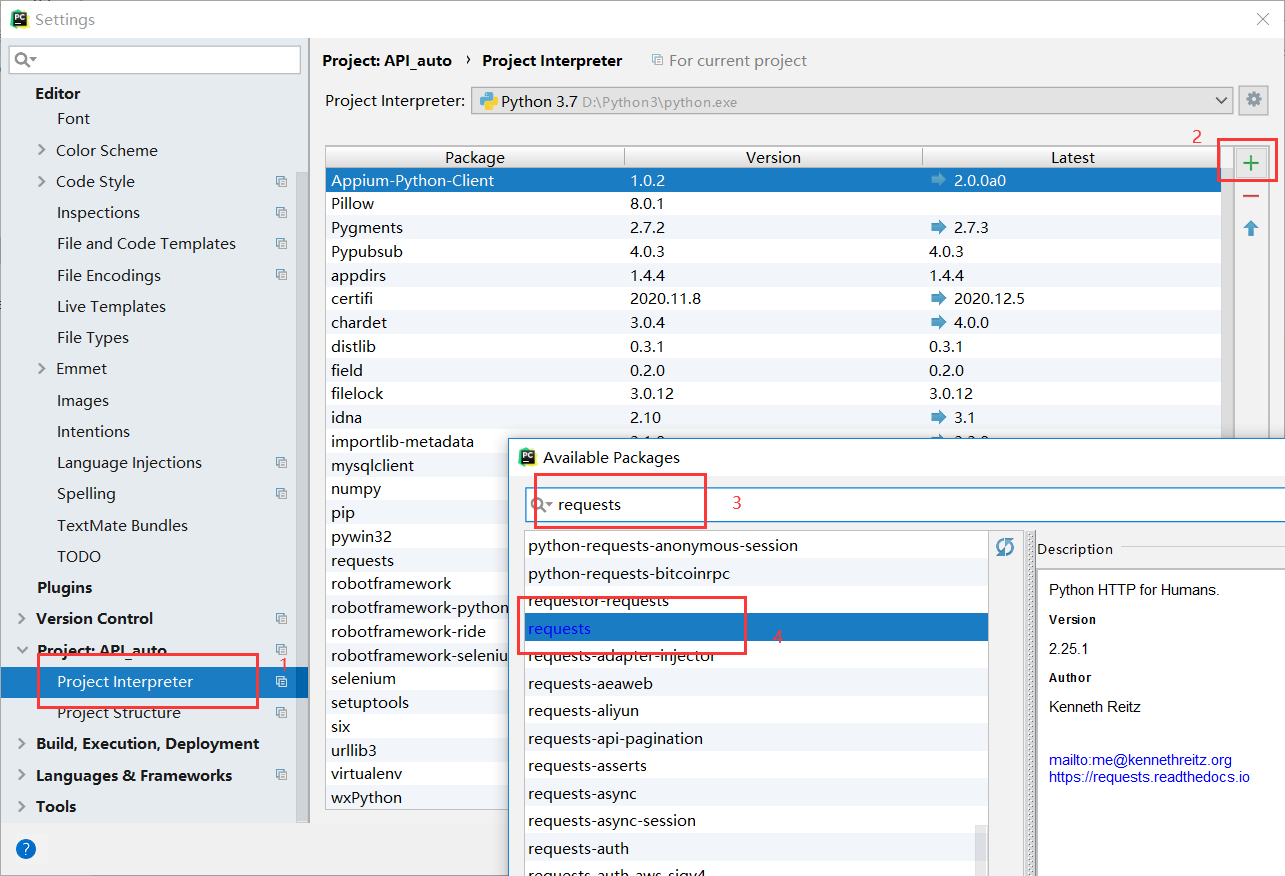
Is the test environment ok
import requests
url_toutiao = "https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=10&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768"
# Mode 1:
# result_toutiao = requests.get(url_toutiao)
# Mode 2:
result_toutiao = requests.get(url=url_toutiao)
# Mode 3:
# result_toutiao = requests.get(
# "https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=1&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768")
# print(result_toutiao.json())
# print(type(result_toutiao.json())) # <class 'dict'>
result = result_toutiao.json()
print(result)
expect_result = "Brilliance golden cup car flower after flower"
actual_result = result["data"][0]["comment"]["user_name"]
print(actual_result)
if expect_result == actual_result:
print("pass!")
else:
print("failed!")
Response timeout
import requests
# V tribe: http: / / [server ip]:8081/index.html
# Article list
url_v_article = "http://[server ip]:8081/article/all“
v_headers = {
"Cookie": "studentUserName=ctt01; Hm_lvt_cd8218cd51f800ed2b73e5751cb3f4f9=1609742724,1609762306,1609841170,1609860946; adminUserName=admin; JSESSIONID=9D1FF19F333C5E25DBA60769E9F5248E"}
article_params = {"state": 1, # -1: All articles 1: Published 0: recycle bin 2: draft box
"page": 1, # Show page 1
"count": 6, # 6 per page
"keywords": "" # Keywords included
}
keywords = ["Big orange cat", "Running man", "tooth"]
for keyword in keywords:
article_params["keywords"] = keyword
# headers and params are of indefinite length and pass parameters according to the defined dictionary
# Timeout timeout in seconds
# By setting the timeout, tell the requests how long to stop waiting for a response
result = requests.get(url_v_article, headers=v_headers, params=article_params, timeout=30)
print(result.json())
JSON,URL,text,encoding,status_code,encoding,cookies
print(result.json()) # The response results are printed out in json print(result.url) # Print url address print(result.text) # Print the contents of the server response in text format print(result.status_code) # Response status code print(result.encoding) # Coding format print(result.cookies) # cookie
JSON (JavaScript object notation) is a lightweight data exchange format. It is based on ECMAScript (js specification formulated by the European Computer Association) It uses a text format completely independent of the programming language to store and represent data. The concise and clear hierarchical structure makes JSON an ideal data exchange language. It is easy for people to read and write, easy for machine parsing and generation, and effectively improves the efficiency of network transmission.
JSON format is equivalent to dictionary type in Python.
JSON formatting: http://www.bejson.com/jsonviewernew/
url online encoding conversion: https://www.w3cschool.cn/tools/index?name=urlencode_decode
(3) Automatic implementation of get, post, put and delete requests
GET request mode
import requests
url_toutiao = "https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=10&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768"
# Mode 1:
# result_toutiao = requests.get(url_toutiao)
# Mode 2:
result_toutiao = requests.get(url=url_toutiao)
# Mode 3:
# result_toutiao = requests.get(
# "https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=1&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768")
# print(result_toutiao.json())
# print(type(result_toutiao.json())) # <class 'dict'>
result = result_toutiao.json()
print(result)
expect_result = "Brilliance golden cup car flower after flower"
actual_result = result["data"][0]["comment"]["user_name"]
print(actual_result)
if expect_result == actual_result:
print("pass!")
else:
print("failed!")
Operation results:
{'message': 'success', 'err_no': 0, 'data': [{'comment': {'id': 6914864825282215951, 'id_str': '6914864825282215951', 'text': 'There are many people working abroad in Gaocheng. Focus on checking Gaocheng district!', 'content_rich_span': '{"links":[]}', 'user_id': 940799526971408, 'user_name': 'Brilliance golden cup car flower after flower',}, 'post_count': 0, 'stick_toast': 1, 'stable': True}
Brilliance golden cup car flower after flower
pass!
POST request mode
import requests
url_v_login = "http://[server ip]:8081/login“
# Define parameters, dictionary format
payload = {'username': 'sang', 'password': '123'}
# Content-Type: application/json --> json
# Content-Type: application/x-www-form-urlencoded --> data
result = requests.post(url_v_login, data=payload)
# Convert the returned result to json format
result_json = result.json()
print(result_json) # {'status':' success', 'MSG': 'login succeeded'}
# Get requestscookeiejar
result_cookie = result.cookies
print(result_cookie, type(result_cookie)) # RequestsCookieJar
# Convert requestscookeiejar to dictionary format
result_cookie_dic = requests.utils.dict_from_cookiejar(result_cookie)
print(result_cookie_dic) # {'JSESSIONID': 'D042C5FE4CFF337806D545B0001E7197'}
# Get SESSION
final_cookie = "JSESSIONID=" + result_cookie_dic["JSESSIONID"] # SJSESSIONID=D042C5FE4CFF337806D545B0001E7197
print(final_cookie)
PUT request mode
# V tribe_ Edit column
# Please refer to the following for details of how to define the request header and automatically obtain cookie s
headers = {"Cookie": "VBlog(self.requests).get_cookie()"}
new_now_time = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time()))
new_category_name = "Update column" + new_now_time
payload = {"id": 2010, "cateName": new_category_name}
self.requests.put("http://[server ip]:8081/admin/category/", headers=headers, data=payload)
DELETE request mode
# Delete column
result = self.requests.delete("http://[server ip]:8081/admin/category / "+" 2010 ", headers=headers)
print(result.json()) # {'status':' success', 'MSG': 'deletion succeeded!'}
self.assertEqual("Delete succeeded!", result.json()["msg"])
(4) cookie handling in interface automation testing
Manually pass in the value of the cookie (capture the packet through the browser F12 each time, and then copy the cookie in the request header)
import requests
# V tribe query column
url_v_category = "http://[server ip]:8081/admin/category/all“
# Custom request header
# If you want to add an HTTP header to the request, simply pass a dictionary to the headers parameter
v_headers = {
"cookie": "studentUserName=ctt01; Hm_lvt_cd8218cd51f800ed2b73e5751cb3f4f9=1609742724,1609762306,1609841170,1609860946; adminUserName=admin; JSESSIONID=9D1FF19F333C5E25DBA60769E9F5248E"}
result = requests.get(url_v_category, headers=v_headers)
# Print the response result in json format
print(result.json())
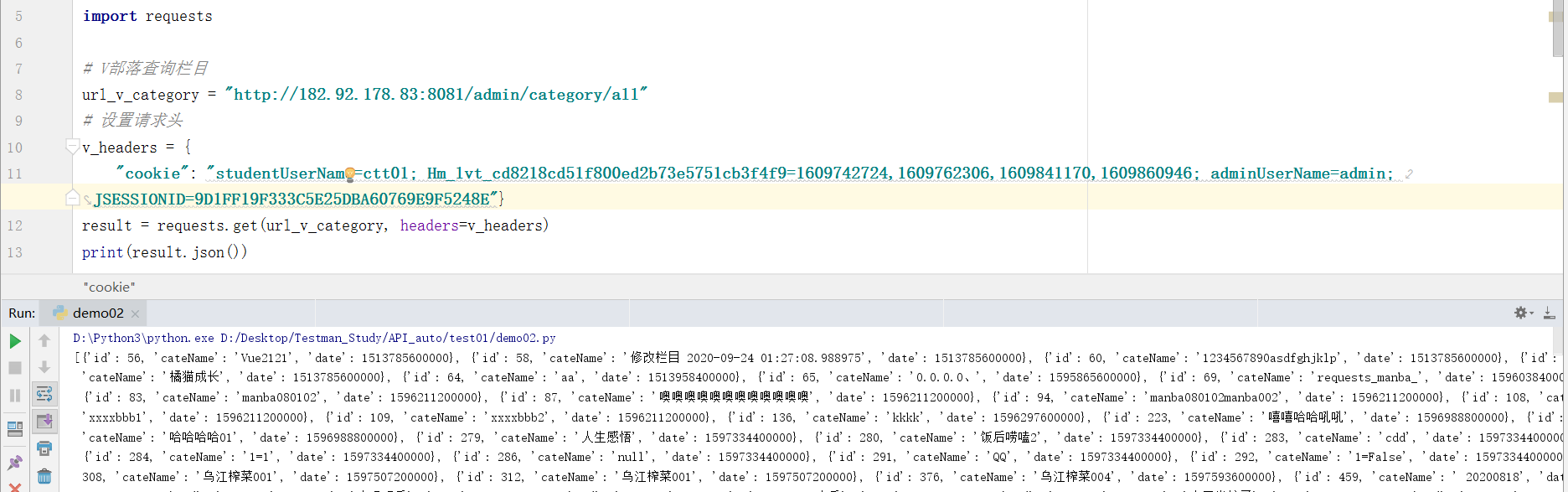
Automatic cookie acquisition
import requests
url_v_login = "http://[server ip]:8081/login“
# Define parameters, dictionary format
payload = {'username': 'sang', 'password': '123'}
# Content-Type: application/json --> json
# Content-Type: application/x-www-form-urlencoded --> data
result = requests.post(url_v_login, data=payload)
# Convert the returned result to json format
result_json = result.json()
print(result_json) # {'status':' success', 'MSG': 'login succeeded'}
# Get requestscookeiejar
result_cookie = result.cookies
print(result_cookie, type(result_cookie)) # RequestsCookieJar
# Convert requestscookeiejar to dictionary format
result_cookie_dic = requests.utils.dict_from_cookiejar(result_cookie)
print(result_cookie_dic) # {'JSESSIONID': 'D042C5FE4CFF337806D545B0001E7197'}
# Get SESSION
final_cookie = "JSESSIONID=" + result_cookie_dic["JSESSIONID"] # SJSESSIONID=D042C5FE4CFF337806D545B0001E7197
print(final_cookie)
Batch fetch cookie script
import requests
def get_cookie(username, password):
"""Students log in through the examination system to obtain a single cookie"""
url_login = "http://[server ip]:8088/api/user/login“
payload = {"userName": username, "password": password, "remember": False}
result = requests.post(url_login, json=payload)
# result_json = result.json()
# print(result_json)
# Get requestscookeiejar
result_cookie = result.cookies
# print(result_cookie, type(result_cookie)) # RequestsCookieJar
# Convert requestscookeiejar to dictionary format
result_cookie_dic = requests.utils.dict_from_cookiejar(result_cookie)
# print(result_cookie_dic) # {'SESSION': 'YzFkM2IzN2QtZWY1OC00Nzc4LTgyOWYtNjg5OGRiZDZlM2E4'}
# Get SESSION
final_cookie = "SESSION=" + result_cookie_dic["SESSION"] # SESSION=Mzc2...
return final_cookie
from test01.demo04_student_login import get_cookie
import os
def get_batch_cookies():
"""Batch acquisition cookie"""
# Empty the contents of the cookie.csv file before obtaining the cookie
# with open(r"D:\Desktop\Testman_Study\API_auto\file\cookies.csv", "w") as cookies_info:
# cookies_info.write("")
# Or delete the file
os.remove(r"D:\Desktop\Testman_Study\API_auto\file\cookies.csv")
# Read csv file
with open(r"D:\Desktop\Testman_Study\API_auto\file\register.csv", "r") as user_info:
for user in user_info:
user_list = user.strip().split(",")
# Call the method to obtain a single cookie and pass in the registered user name and password
cookies = get_cookie(user_list[0], user_list[1])
# Append cookie to file
with open(r"D:\Desktop\Testman_Study\API_auto\file\cookies.csv", "a") as cookies_info:
cookies_info.write(cookies + "\n")
# Call method
get_batch_cookies()
register.csv(The premise is that these accounts and passwords have been registered and can be logged in directly) poopoo001,123456,1 poopoo002,123457,2 poopoo003,123458,3 poopoo004,123459,4 ......
cookies.csv SESSION=ZmE3YmU4ZDctNDExZS00MDdhLWE0YjEtMjAyZjQxOTMxYmUx SESSION=YjdkNTZhNTUtNGFmMi00MjVkLWEyNjctOTNiMmRmOTY1YTdm SESSION=ZTJmMTYzMWEtZjUzOS00NTlhLWI0OWQtMzBmN2RkYmU4YmRi SESSION=YTM0ZGRhOTctZjk5Ni00OWZhLTg1YTItZjUyMTMwZGE2MjVi ......
(5) Processing of different types of request parameters
import requests
# Article list
url_v_article = "http://[server ip]:8081/article/all“
v_headers = {
"Cookie": "studentUserName=ctt01; Hm_lvt_cd8218cd51f800ed2b73e5751cb3f4f9=1609742724,1609762306,1609841170,1609860946; adminUserName=admin; JSESSIONID=9D1FF19F333C5E25DBA60769E9F5248E"}
# Customize the url parameters, define a dictionary, split the parameters, and then pass the dictionary to the params variable
article_params = {"state": 1, # -1: All articles 1: Published 0: recycle bin 2: draft box
"page": 1, # Show page 1
"count": 6, # 6 per page
"keywords": "" # Keywords included
}
keywords = ["Big orange cat", "Running man", "tooth"]
for keyword in keywords:
article_params["keywords"] = keyword
# headers and params are of indefinite length and pass parameters according to the defined dictionary
result = requests.get(url_v_article, headers=v_headers, params=article_params)
print(result.json())
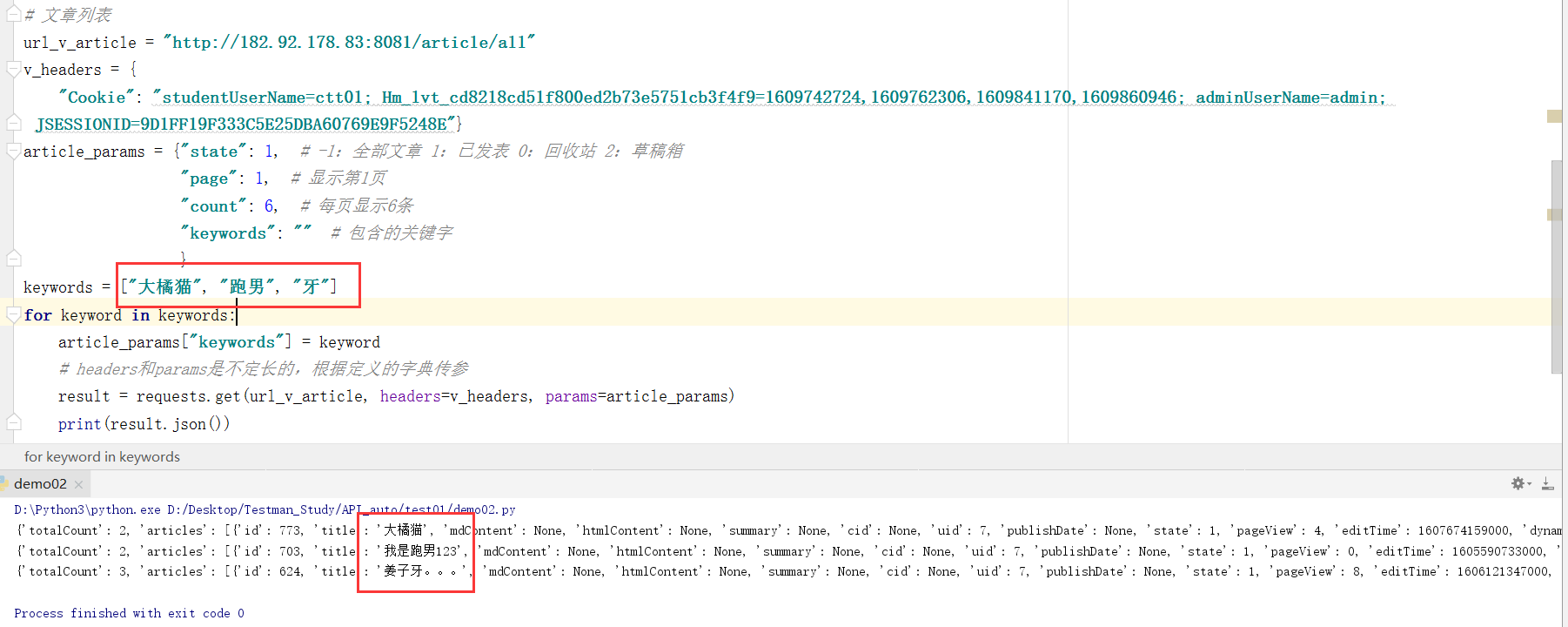
(6) Combined with Python+Requests+Unittest framework for interface automation test
unittest framework:

if name == 'main':
if name == 'main' means:
- When the. py file is run directly, the code block under if name == 'main' will be run;
- When the. py file is imported as a module, the code block under if name == 'main' is not run.
(7) Advanced assertions in interface automation testing
Closed loop assertion (add -- > query -- > Modify -- > query -- > delete -- > query)
def test_article(self):
# ① V tribe_ New article
now_time = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time()))
title = "Cai Tuotuo" + now_time
payload = {"id": -1, "title": title, "mdContent": "Article content", "state": 1, "htmlContent": "<p>Article content</p>",
"dynamicTags": "", "cid": 62}
headers = {"Cookie": VBlog(self.requests).get_cookie()}
result = self.requests.post("http://[server ip]:8081/article/", headers=headers, data=payload)
# ② Query article
url_v_article = "http://[server ip]:8081/article/all“
article_params = {"state": 1, # -1: All articles 1: Published 0: recycle bin 2: draft box
"page": 1, # Show page 1
"count": 6, # 6 per page
"keywords": title # Included keyword title
}
result = requests.get(url_v_article, headers=headers, params=article_params, timeout=30)
print(result.json()) # The response results are printed out in json
ls = result.json()["articles"]
act = 123
# If the new article is found, it indicates that the new article is successful
for l in range(0, len(ls)):
if ls[l]["title"] == title:
act = "ok"
article_id = ls[l]["id"]
self.assertEqual("ok", act)
# ③ Edit article
now_time = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time()))
title = "Modify article" + now_time
payload = {"id": article_id, "title": title, "mdContent": "Modification content", "state": 1, "htmlContent": "<p>Modification content</p>",
"dynamicTags": "", "cid": 62}
headers = {"Cookie": VBlog(self.requests).get_cookie()}
self.requests.post("http://[server ip]:8081/article/", headers=headers, data=payload)
# After editing, query the article
url_v_article = "http://[server ip]:8081/article/all“
article_params = {"state": 1, # -1: All articles 1: Published 0: recycle bin 2: draft box
"page": 1, # Show page 1
"count": 6, # 6 per page
"keywords": title # Included keyword title
}
result = requests.get(url_v_article, headers=headers, params=article_params, timeout=30)
print(result.json()) # The response results are printed out in json
ls = result.json()["articles"]
act = 123
# If the revised article is found, it indicates that the editing is successful
for l in range(0, len(ls)):
if ls[l]["title"] == title:
act = "ok"
article_id = ls[l]["id"]
self.assertEqual("ok", act)
# ④ View Article Details
article_id = str(article_id)
result = self.requests.get("http://[server IP]: 8081 / article / "+ article_id, headers = headers)
print(result.json())
if result.json()["title"] == title:
act = "ok"
self.assertEqual(act, "ok")
# ⑤ Delete article
payload = {'aids': article_id, 'state': 1}
result = self.requests.put("http://[server ip]:8081/article/dustbin", headers=headers, data=payload)
print(result.json())
act = result.json()["msg"]
self.assertEqual(act, "Delete succeeded!")
(8) Generate visual HTML test report through HTMLTestRunner.py
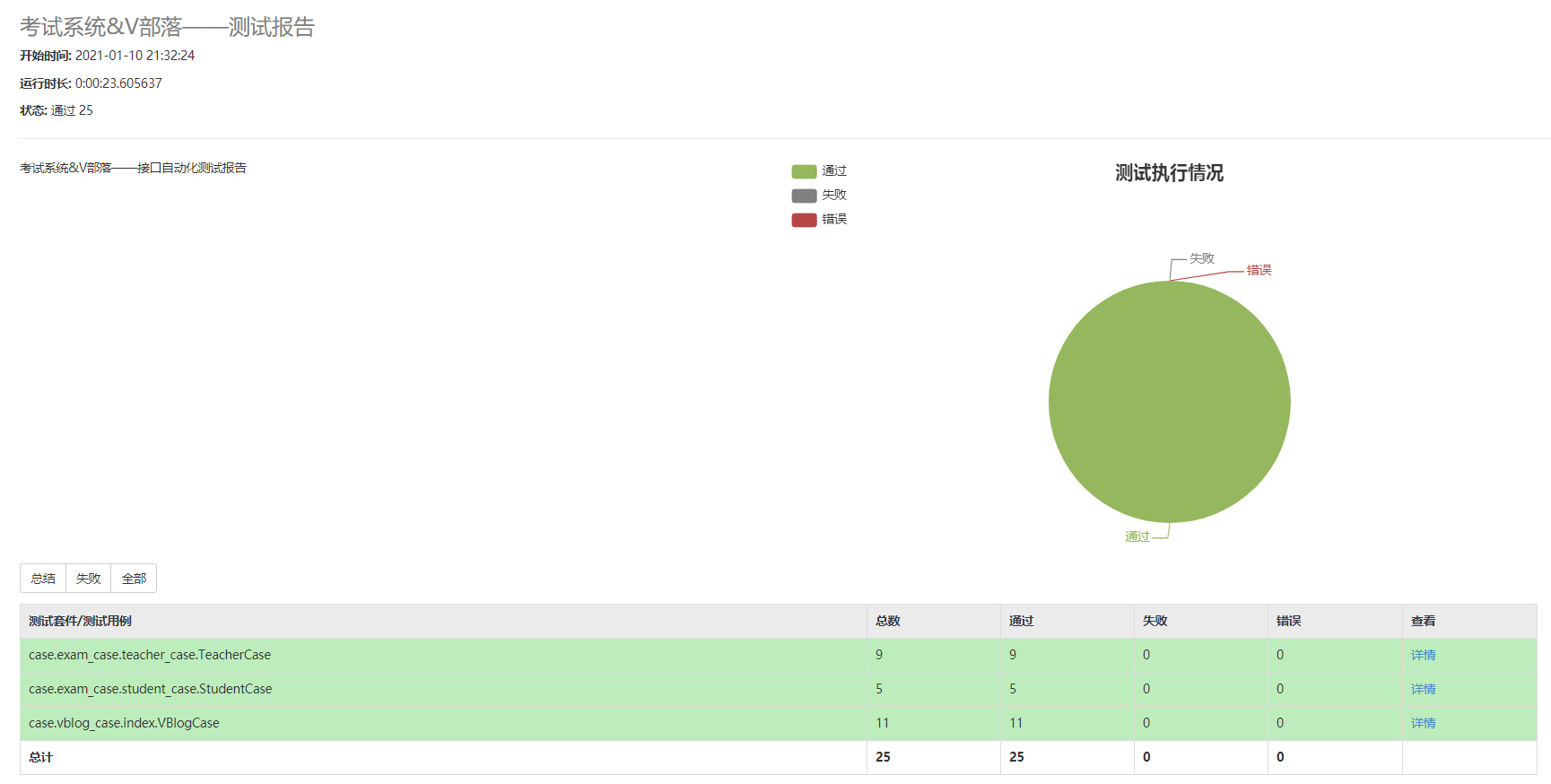
HTMLTestRunner.py Baidu online disk link:
from reports import HTMLTestRunner
from case.exam_case.teacher_case import TeacherCase
import unittest
import os
import time
# Create test suite
suite = unittest.TestSuite()
# Add test cases and execute them according to the addition order
# Add a single test case
# suite.addTest(TeacherCase("test_001_admin_login"))
# Add multiple test cases
suite.addTests([TeacherCase("test_001_admin_login"),
TeacherCase("test_002_insert_paper"),
TeacherCase("test_003_select_paper"),
])
# Define the storage path of the test report
path = r"D:\Desktop\Testman_Study\unittest_exam_system\reports"
# Determine whether the path exists
if not os.path.exists(path):
# If not, create one
os.makedirs(path)
else:
pass
# Define a timestamp for test report naming
now_time = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime(time.time()))
reports_path = path + "\\" + now_time + "(exam_report).html"
reports_title = u"Examination system&V Tribe - Test Report"
desc = u"Examination system&V Interface automation test report"
# Binary write
fp = open(reports_path, "wb")
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=reports_title, description=desc)
# function
runner.run(suite)
postman,JMeter,requests Summary:
- postman: interface function test
- JMeter: interface performance test
- requests: interface automation
- 🐵 Common features of the three: they can complete interface function test.

Finally, it can be in the official account: the sad spicy bar! Get a 216 page interview document of Software Test Engineer for free. And the corresponding video learning tutorials for free!, It includes basic knowledge, Linux essentials, Shell, Internet program principles, Mysql database, special topics of packet capture tools, interface test tools, test advanced Python programming, Web automation test, APP automation test, interface automation test, advanced continuous test integration, test architecture, development test framework, performance test, security test, etc.
If my blog is helpful to you and you like my blog content, please click "like", "comment" and "collect" for three times! Friends who like software testing can join our testing technology exchange group: 914172719 (there are various software testing resources and technical discussions)
Haowen recommendation
What kind of person is suitable for software testing?