Purpose of interprocess communication
- Data transfer: one process needs to send its data to another process.
- Resource sharing: multiple processes share the same resources.
- Notification event: a process needs to send a message to another process or group of processes to notify it (them) of an event (such as notifying the parent process when the process terminates).
- Process control: some processes want to fully control the execution of another process (such as Debug process). At this time, the control process wants to be able to intercept all traps and exceptions of another process and know its state changes in time.
Interprocess communication development
- The Conduit
- System V interprocess communication
- POSIX interprocess communication
Interprocess communication classification
The Conduit
- Anonymous pipe
- name pipes
System V IPC
- System V message queue
- System V shared memory
- System V semaphore
POSIX IPC
- Message queue
- Shared memory
- Semaphore
- mutex
- Conditional variable
- Read write lock
We mainly study anonymous pipes, named pipes, shared memory and other contents later.
The Conduit
preface
We talked about the purpose, development and classification of inter process communication. Now let's talk about the first development, pipeline.
What is a pipe?
Pipeline in reality: in daily life, we can understand that it is a pipeline for transporting resources. As for transportation resources, it can be water, oil, natural gas, etc.
Pipeline in Linux: we call a data flow that links one process to another process "pipeline". Pipeline is the loneliest and oldest way of inter process communication in UNIX.
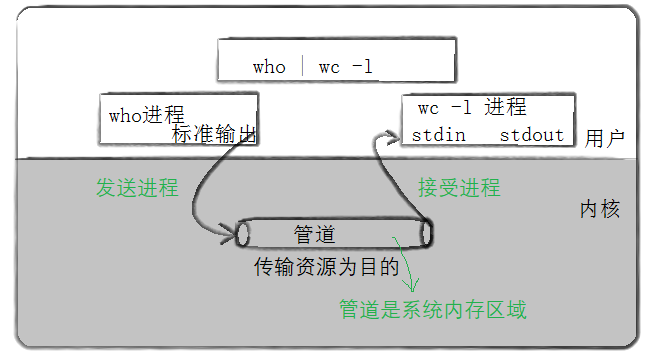
The essence of interprocess communication: let different processes see the same system resource (this system resource is the system memory provided by the system in some way).
Some way determines the difference of communication strategy. So how does the system communicate? Keep looking down.
Anonymous Pipe
Function prototype
#include <unistd.h> function:Create an anonymous pipe prototype int pipe(int fd[2]); parameter fd: File descriptor array,among fd[0]Indicates the reading end, fd[1]Indicates the write end Return value:0 is returned for success and error code is returned for failure
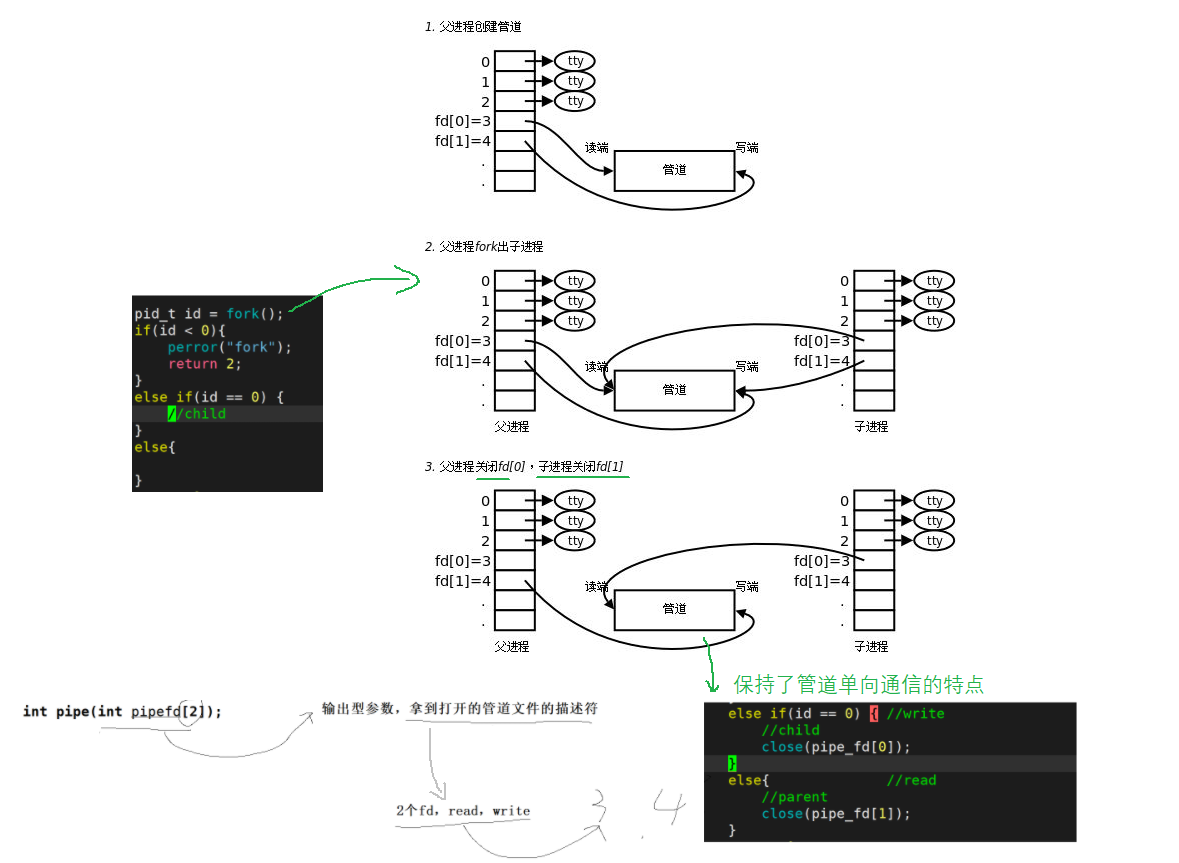
Previously, we learned basic IO and knew the essence of file descriptor. First, we stood in the perspective of file descriptor and deeply understood the pipeline.
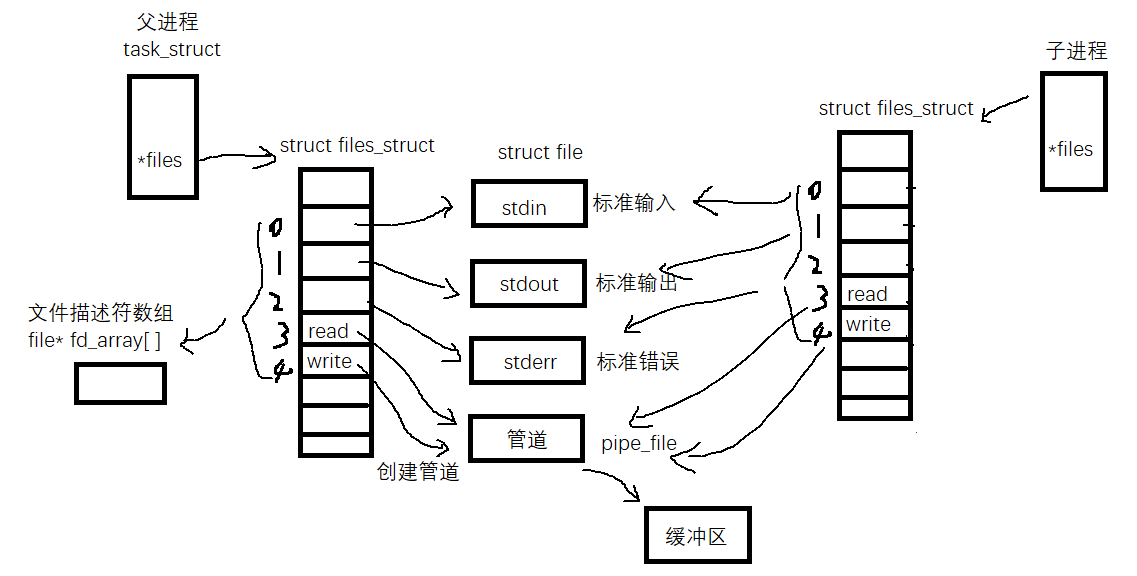
- We can see that both 3 and 4 point to the pipeline. The file descriptor 3 reads the pipeline and the file descriptor 4 writes the pipeline. From the side, we can know that the pipeline is also a file.
- We can see that the parent-child process is communicating, so the anonymous pipeline can only be used for blood related processes to communicate between processes (common to father and son). After the parent process fork s out the child process, let two different processes see the same system resource (system memory area).
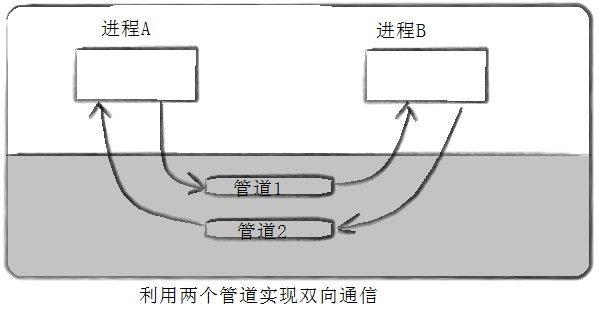
- The pipeline can only conduct one-way data communication. (parent process writes, child process reads, or parent process reads, child process writes) if you want two-way data communication, you can only create multiple pipelines.
Here, we can see that after creating a pipe file descriptor array, we get file descriptors 3 and 4;
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
File descriptor array
int pipe_fds[2];
//Creation failed
if(pipe(pipe_fds) == -1)
{
perror("pipe fail");
return -1;
}
Get descriptor file
printf("%d, %d\n",pipe_fds[0],pipe_fds[1]);
return 0;
}
The obtained corresponding file descriptor, 3 corresponds to read and 4 corresponds to write.

So, look at the pipeline, just like looking at the document! The use of pipes is consistent with that of files, which caters to the "Linux everything is a file idea"
Next, we can start the communication between processes, fork out a child process, the parent process reads and the child process writes.
#include <stdio.h>
#include <sys/types.h>
#include <string.h>
#include <stdlib.h>
#include <fcntl.h>
int main()
{
int pipe_fds[2] = { 0 };
//Creation failed
if(pipe(pipe_fds) == -1)
{
perror("pipe fail\n");
return 1;
}
//Print corresponding file descriptor
printf("%d, %d\n",pipe_fds[0],pipe_fds[1]);
pid_t id = fork();//Create child process
//fork failed
if(id < 0)
{
perror("fork fail\n");
return 2;
}
else if(id == 0)
{
close(pipe_fds[0]);//Turn off reading to ensure one-way communication
const char *msg = "I am a child!!!";
//We write data five times
int count = 5;
while(count--)
{
write(pipe_fds[1], msg, strlen(msg));//strlen(msg) does not require + 1
sleep(1);
}
close(pipe_fds[1]);//After sending, it needs to be closed
exit(0); //Subprocess task completed, exit
}
else
{
close(pipe_fds[1]);
char buffer[64];
while(1)
{
buffer[0] = 0; //Initialize to 0 first
ssize_t s = read(pipe_fds[0], buffer, sizeof(buffer) - 1);//Note that this is the byte size
//In C language, the last digit is' 0 '
if(s > 0)
{
buffer[s] = 0;//The last digit is 0
printf("parent get message from child : %s\n", buffer);
}
else if(s == 0)
{
printf("child is quit!!!\n");;
break;
}
else
{
break;
}
}
//You need to wait, or you don't know the process of becoming a zombie
int status = 0;
//Wait for the child process to exit
if(waitpid(id, &status, 0) > 0)
{
printf("child is quit success\n");
}
//No need to read off
close(pipe_fds[0]);
}
return 0;
}
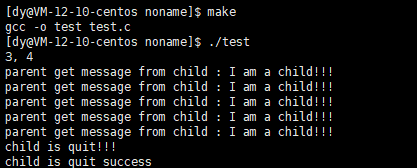
From the results here, we can see that the parent process has been waiting for the child process and reading the data written by the child process. Here, the pipeline is implemented. One process writes and one process reads and sees the same resource.
Let's take a look at the picture below to deepen our understanding!!!
Here are a few questions
- Why did you open the read / write function corresponding to the file descriptor?
A: if you do not open the read / write rw, the files obtained by the child process must be opened in the same way as the parent process and cannot communicate (for example, they can only read or write). It is more flexible to open read / write (the parent process can read / write, and the child process can read / write).
- Why do I have to turn off the corresponding read / write?
A: the parent process reads and the child process writes. If the corresponding read / write is not closed, misoperations will occur. For example, the parent process writes and the child process writes.
Properties of anonymous pipes
- If there is no message in the pipeline, what is the parent process (Reader) doing?
A: wait, wait for the data inside the pipeline to be ready (sub process write).
- If the writing end in the pipeline is full, continue to write, can you write?
A: of course not. You need to wait until there is free space inside the pipeline (read by the parent process).
The parent process reads and the child process writes, which reflects the process synchronization.
characteristic:
- The pipeline has its own synchronization mechanism
- The pipeline is one-way communication
- Pipes are byte stream oriented (read or write as bytes)
- The pipeline can only ensure that the process with blood relationship can communicate. It is often used for father and son
- The pipeline can ensure a certain degree of atomicity of data reading (simultaneous reading / writing)
- The pipeline is also a file. As the process exits, the pipeline will also be closed, and the life cycle will change with the process
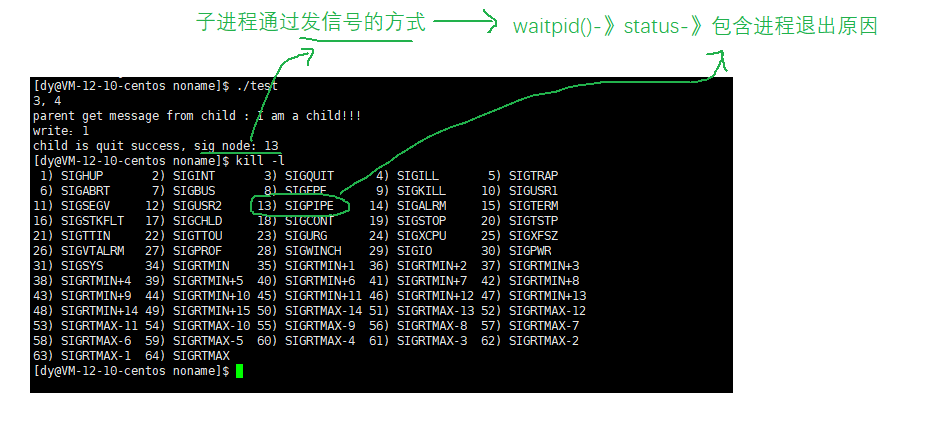
Let's take a look. What happens if we keep writing, don't read or close it?
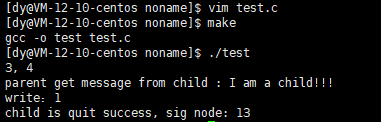
Reading and closing, of course, is always writing data. It is meaningless to write all the time. In essence, it is a waste of system resources. The write process will be immediately terminated by the OS.
Keep writing. Let's see how long it can be written, that is, how big the pipeline is?

We can see here that 4368 is not written, about 4KB of content
Linux also specifies 4 bytes, which can be viewed through the man command

To sum up, we talked about two aspects of pipeline reading and writing.
To sum up:
| read end | write end | result |
|---|---|---|
| No reading | write | write blocking |
| read | Don't write | read blocking |
| Do not read & close | write | write is killed by SIGPIPE sent by OS |
| read | Do not write & close | read reads' 0 'and the file ends |
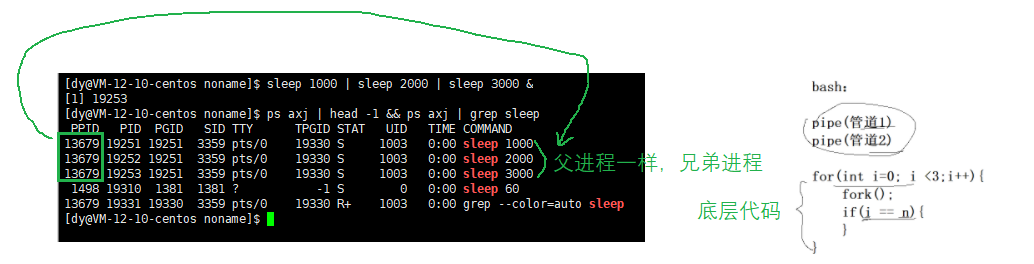
We can do a small experiment, sleep can also create anonymous pipes
[dy@VM-12-10-centos noname]$ sleep 1000 | sleep 2000 | sleep 3000 & [1] 19253 Here you can see the parent process of the three processes pid They are the same, so they are brother processes, which conforms to the characteristics of anonymous pipes [dy@VM-12-10-centos noname]$ ps axj | head -1 && ps axj | grep sleep PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND 13679 19251 19251 3359 pts/0 19330 S 1003 0:00 sleep 1000 13679 19252 19251 3359 pts/0 19330 S 1003 0:00 sleep 2000 13679 19253 19251 3359 pts/0 19330 S 1003 0:00 sleep 3000 1498 19310 1381 1381 ? -1 S 0 0:00 sleep 60 13679 19331 19330 3359 pts/0 19330 R+ 1003 0:00 grep --color=auto sleep
The underlying for loop creates three sleep
name pipes
- One limitation of pipeline application is that it can only communicate between processes with a common ancestor (kinship).
- If we want to exchange data between unrelated processes, we can do this by using FIFO files, which are often called named pipes.
- Named pipes are a special type of file
Principle:
- Create a file, let process 1 open the file, process 2 open the file, and use the file under the same path
- Of course, the created file cannot be an ordinary file on the disk, but a pipeline file. The pipeline file does not exist on the disk. Process 1 reads and process 2 writes. At this time, the pipeline file exists in memory and the corresponding data needs to be taken from the corresponding buffer
Creation of named pipes
- Named pipes can be created from the command line by using the following command:
mkfifo myfifo
We created how to view the contents of this pipeline file? Let's write a command to write the data and view the file
Continuous write command: while :; do echo "hello bit"; sleep 1; done > myfifo View command: cat myfifo

The command here realizes the simple communication between the two processes
- Named pipes can also be created from the program. The related functions are:
int mkfifo(const char *filename,mode_t mode);
To create a named pipe:
int main(int argc, char *argv[])
{
mkfifo("p2", 0644);//Corresponding name and authority
return 0;
}
The difference between anonymous pipes and named pipes
- Anonymous pipes are created and opened by the pipe function.
- The named pipe is created by the mkfifo function and opened with open
- The only difference between FIFO (named pipe) and pipe (anonymous pipe) is that they are created and opened in different ways, but once these works are completed, they have the same semantics.
Opening rules for named pipes
If the current open operation is to open FIFO for reading
- O_NONBLOCK disable: blocks the FIFO until a corresponding process opens it for writing
- O_NONBLOCK enable: returns success immediately
If the current open operation is to open FIFO for writing
- O_NONBLOCK disable: blocks until a corresponding process opens the FIFO for reading
- O_NONBLOCK enable: immediately return failure with error code ENXIO
Using named pipes to realize server client communication
server.c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define FIFO "./fifo"
int main()
{
int ret = mkfifo(FIFO, 0644);//Directory, permissions
if(ret < 0)
{
perror("mkfifo fail");
return 1;
}
//After the pipeline is created, the file operation will follow
int fd = open(FIFO, O_RDONLY);
if(fd < 0)
{
perror("open fail");
return 2;
}
char buffer[128];
while(1)
{
printf("Server# ");
fflush(stdout);//In the buffer, forced refresh is required
buffer[0] = 0;//initialization
ssize_t s = read(fd, buffer, sizeof(buffer) - 1);
if(s > 0)
{
buffer[s] = 0;//Last position '0'
printf("Client#: %s\n",buffer);
}
else if(s == 0)
{
printf("client quit!!!\n");//Termination
break;
}
else
{
break;
}
}
close(fd);//Open remember to close
return 0;
}
client.c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define FIFO "./fifo"
#include <string.h>
int main()
{
//The pipeline file has been created in the server, so there is no need to create it here
int fd = open(FIFO, O_WRONLY);
if(fd < 0)
{
perror("open fail");
return 2;
}
char buffer[128];
while(1)
{
printf("Please Enter# ");
fflush(stdout);//In the buffer, forced refresh is required
buffer[0] = 0;//initialization
//The last bit is' 0 ', which is the essence of C language, regardless of the terminator of the file
ssize_t s = read(0, buffer, sizeof(buffer) - 1);//At this time, the data is read from the input stream
if(s > 0)
{
buffer[s] = 0;//Last position '0'
write(fd, buffer, strlen(buffer));
}
else if(s == 0)
{
printf("client quit!!!\n");//Termination
break;
}
else
{
break;
}
}
close(fd);//Open remember to close
return 0;
}
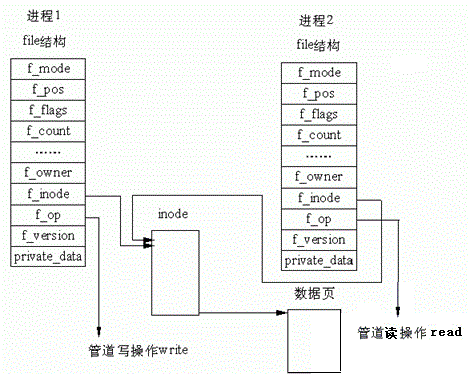
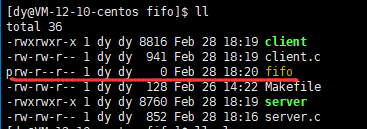
We can see that the client process writes and the server process reads. This is to complete the creation of the named pipe through the program. In fact, it is good to create a pipeline file. The following content is the opening, reading and writing operations in basic IO.

In the exception, we can clearly see that the size of the pipeline file is 0, which fully proves that the pipeline file does not exist on the disk, but the memory area of the system.
system V shared memory
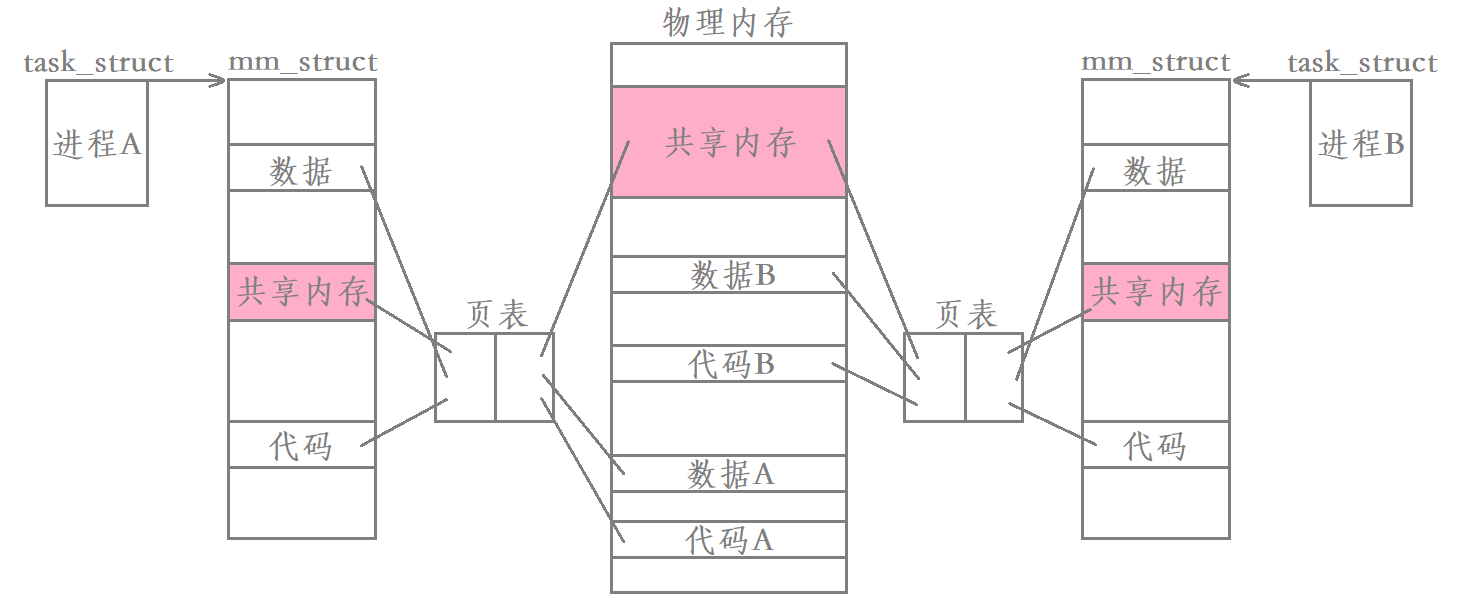
Shared memory is the fastest form of IPC. Once such memory is mapped to the address space of the processes sharing it, the data transfer between these processes no longer involves the kernel. In other words, processes no longer transfer each other's data by executing system calls into the kernel.
Principle: shared memory allows different processes to see the same resource. The way is to apply for a memory space in the physical memory, and then establish a mapping between this memory space and each process's respective page table, and then open up a space in the virtual address space and fill the virtual address into the corresponding position of each page table, Make the correspondence between the virtual address and the physical address established. So far, these processes will see the same physical memory, which is called shared memory.
Shared memory data structure
There may be a large number of processes communicating in the system, so there may be a large number of shared memory in the system, so the operating system must manage it. Therefore, in addition to opening up space in the memory, the system must maintain relevant kernel data structures for the shared memory.
The data structure of shared memory is as follows:
struct shmid_ds {
struct ipc_perm shm_perm; /* operation perms */
int shm_segsz; /* size of segment (bytes) */
__kernel_time_t shm_atime; /* last attach time */
__kernel_time_t shm_dtime; /* last detach time */
__kernel_time_t shm_ctime; /* last change time */
__kernel_ipc_pid_t shm_cpid; /* pid of creator */
__kernel_ipc_pid_t shm_lpid; /* pid of last operator */
unsigned short shm_nattch; /* no. of current attaches */
unsigned short shm_unused; /* compatibility */
void *shm_unused2; /* ditto - used by DIPC */
void *shm_unused3; /* unused */
};
When we apply for a piece of shared memory, in order to enable the process to realize communication to see the same shared memory, each shared memory is applied with a key value, which is used to identify the uniqueness of the shared memory in the system.
You can see that the first member of the shared memory data structure above is shm_perm,shm_ Perm is an IPC_ Structure variables of perm type. The key value of each shared memory is stored in shm_perm is a structural variable, in which ipc_perm structure is defined as follows:
struct ipc_perm{
__kernel_key_t key;
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode;
unsigned short seq;
};
Establishment and release of shared memory
The establishment of shared memory roughly includes the following two processes:
- Apply for shared memory space in physical memory.
- Connect the applied shared memory to the address space, that is, establish a mapping relationship.
The release of shared memory roughly includes the following two processes:
- Disassociate the shared memory from the address space, that is, cancel the mapping relationship.
- Free the shared memory space, that is, return the physical memory to the system.
Shared memory creation
shmget function
Function: used to create shared memory prototype int shmget(key_t key, size_t size, int shmflg); parameter key:Name of this shared memory segment size:Shared memory size shmflg:It consists of nine permission flags. Their usage is the same as that used when creating files mode The pattern flags are the same Return value: successfully returns a non negative integer, that is, the identification code of the shared memory segment; Failure Return-1
We call something with the ability to calibrate certain resources a handle, and the return value of the shmget function here is actually the handle of the shared memory. This handle can identify the shared memory in the user layer. After the shared memory is created, we need to use this handle to carry out various operations on the specified shared memory when we use the related interfaces of the shared memory later.
The first parameter key passed into shmget function needs to be obtained by ftok function
The prototype of ftok function is as follows:
key_t ftok(const char *pathname, int proj_id);
The ftok function is used to combine an existing pathname with an integer identifier proj_id is converted into a key value, called IPC key value. When using shmget function to obtain shared memory, this key value will be filled into the data structure maintaining shared memory. Note that the file specified by pathname must exist and be accessible.
be careful:
- Using the ftok function to generate key values may cause conflicts. In this case, you can modify the parameters passed into the ftok function.
- When using the ftok function to obtain the key value, all processes that need to communicate need to use the same path name and integer identifier to generate the same key value, and then find the same shared resource.
The third parameter shmflg of shmget function is passed in. There are two common combinations:
| Combination mode | effect |
|---|---|
| IPC_CREAT | If there is no shared memory with the same key value in the kernel, create a new shared memory and return the handle of the shared memory; If such shared memory exists, the handle of the shared memory is returned directly |
| IPC_CREAT IPC_EXCL | If there is no shared memory with the same key value in the kernel, create a new shared memory and return the handle of the shared memory; If such shared memory exists, an error is returned |
- Use combination IPC_CREAT will certainly get a handle to the shared memory, but it is unable to confirm whether the shared memory is a new shared memory.
- Use combination IPC_CREAT | IPC_EXCL, the handle of the shared memory will be obtained only when the shmget function call is successful, and the shared memory must be a new shared memory.
Now we can use shmget and ftok functions to create a piece of shared memory. The code and the screenshot are as follows:
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#define PATHNAME "./tmp" / / path
#define PROJ_ID 0x6666
int main()
{
key_t k = ftok(PATHNAME, PROJ_ID);
if(k < 0)
{
perror("ftok");
return 1;
}
int shmid = shmget(k, 4096, IPC_CREAT);
if(shmid < 0)
{
perror("shmget");
return 2;
}
printf("key:%x\n", k);
printf("shmid:%d\n",shmid);
return 0;
}
Value corresponding to handle and key
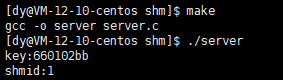
At this point, we can view the shared memory segment through the command ipcs -m

So far, we have completed the creation of shared memory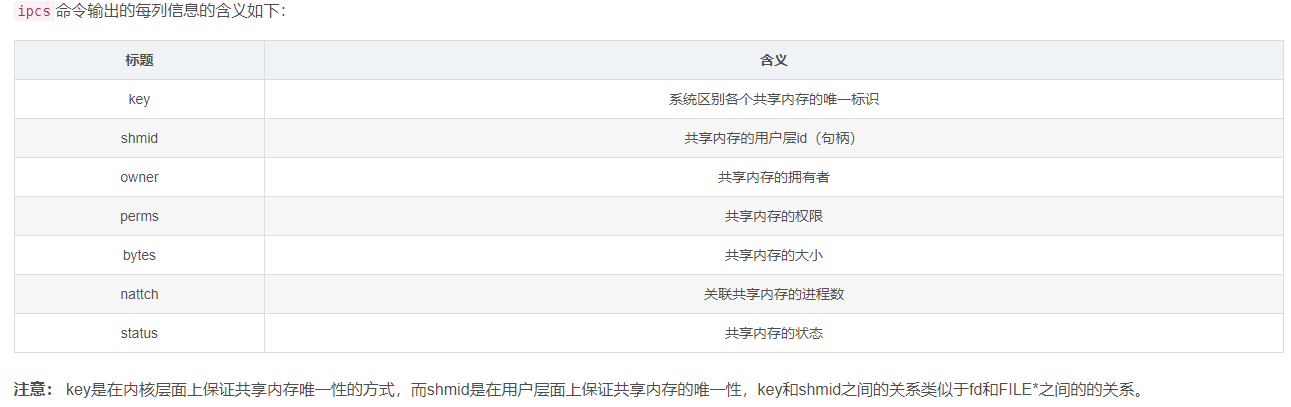
Deletion of shared memory
Through the experiment of creating shared memory above, it can be found that after our process runs, the applied shared memory still exists and has not been released by the operating system. In fact, the life cycle of the pipeline follows the process, while the life cycle of the shared memory follows the kernel. That is to say, although the process has exited, the shared memory once created will not be released with the exit of the process.
This shows that if the process does not actively delete the created shared memory, the shared memory will exist until it is shut down and restarted (this is true for system V IPC). At the same time, it also shows that IPC resources are provided and maintained by the kernel.
At this point, if we want to release the shared memory we have created, there are two ways. One is to release shared memory by command, and the other is to release the function of releasing shared memory after the process communication is finished. The two is to release the shared memory.
- We can use the ipcrm -m shmid command to release the shared memory resource of the specified id.
ipcrm -m 1

- We can also release shared memory resources through programs
shmctl function
Function: used to control shared memory prototype int shmctl(int shmid, int cmd, struct shmid_ds *buf); parameter shmid:from shmget Shared memory identification code returned cmd:Action to be taken (there are three values) buf:Point to a data structure that holds the mode state and access rights of shared memory Return value: 0 is returned successfully; Failure Return-1
Action taken cmd

You can check through the following command or directly query ipcs -m twice
while :; do ipcs -m;echo "###################################";sleep 1;done
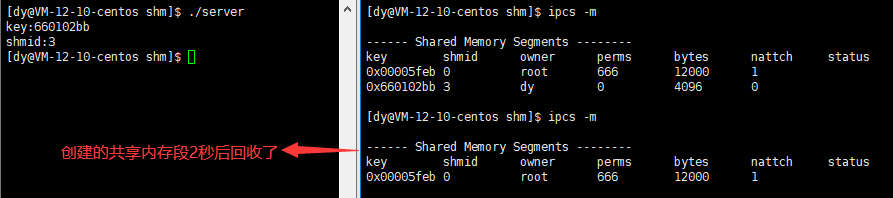
Association of shared memory
Connect the shared memory to the process address space and use the shmat function:
Function: connect the shared memory segment to the process address space prototype void *shmat(int shmid, const void *shmaddr, int shmflg); parameter shmid: Shared memory ID shmaddr:Specify the address of the connection shmflg:Its two possible values are SHM_RND and SHM_RDONLY Return value: successfully return a pointer (return the starting address mapped from the shared memory to the process address space), pointing to the first section of the shared memory; Failure Return-1
- explain:
shmaddr by NULL,The core automatically selects an address shmaddr Not for NULL And shmflg nothing SHM_RND Mark, then shmaddr Is the connection address. shmaddr Not for NULL And shmflg Set SHM_RND Mark, the address of the connection will be automatically adjusted downward to SHMLBA An integer multiple of. Formula: shmaddr - (shmaddr % SHMLBA) shmflg=SHM_RDONLY,Indicates that the connection operation is used for read-only shared memory

Next, we use the shmat function to correlate the shared memory.
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "./tmp" / / path
#define PROJ_ID 0x6666
int main()
{
key_t k = ftok(PATHNAME, PROJ_ID);
if(k < 0)
{
perror("ftok");
return 1;
}
int shmid = shmget(k, 4096, IPC_CREAT);
if(shmid < 0)
{
perror("shmget");
return 2;
}
printf("key:%x\n", k);
printf("shmid:%d\n",shmid);
printf("attach begin\n");
sleep(2);
char* m = shmat(shmid, NULL, 0);
if(m == (void*)-1)
{
perror("shmat");
return 3;
}
printf("attach end\n");
sleep(2);
shmctl(shmid, IPC_RMID, NULL);
return 0;
}
After the code runs, it is found that the association fails. The main reason is that when we use the shmget function to create the shared memory, we do not have permission to set the created shared memory, so the default permission of the created shared memory is 0, that is, there is no permission, so the server process has no permission to associate the shared memory.

When using the shmget function to create shared memory, we should set the permission after shared memory creation at its third parameter. The permission setting rules are the same as those for setting file permissions
int shmid = shmget(k, SIZE, IPC_CREAT | IPC_EXCL | 0666);//Create shared memory with permission 0666
At this point, we can see that the number of processes associated with the shared memory is + 1, and the permission is 666
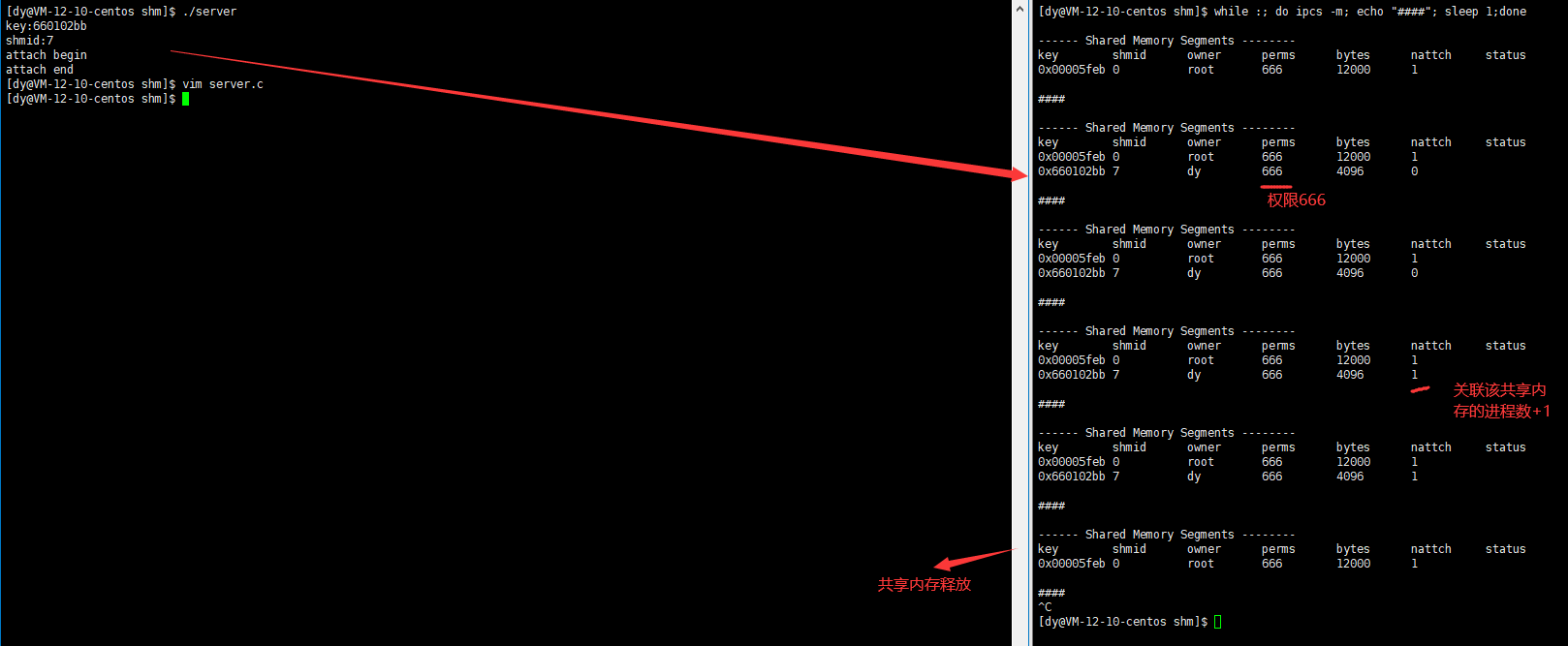
Disassociate shared memory
To disassociate the shared memory from the process address space, you need to use the shmdt function
Function: separate the shared memory segment from the current process prototype int shmdt(const void *shmaddr); parameter shmaddr: from shmat The returned pointer (the starting address of the associated shared memory, that is, the call shmat Function.) Return value: 0 is returned successfully; Failure Return-1 Note: separating the shared memory segment from the current process does not mean deleting the shared memory segment
Note: separating the shared memory segment from the current process does not mean deleting the shared memory, but cancels the connection between the current process and the shared memory
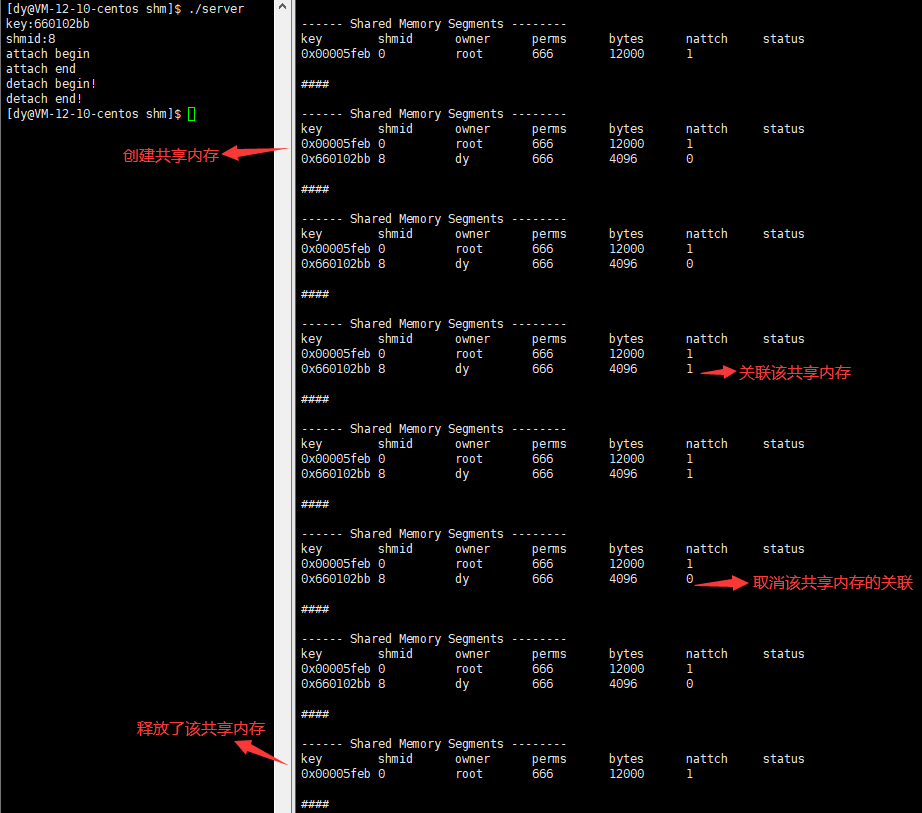
Using shared memory to realize server client communication
We already know how to create, associate, detach and release shared memory. Next, we continue to use the client / server mode for inter process communication. Let's first see how these two processes can be associated with shared memory.
Through the command, we can see that the shared memory can be associated
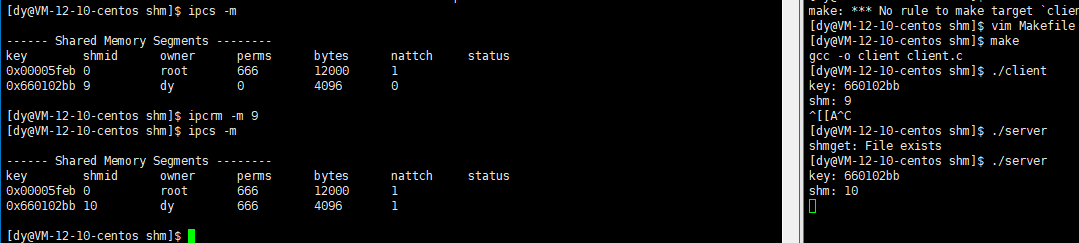
comm.h
#include <stdio.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "./tmp" / / pathname
#define PROJ_ID 0x6666 / / integer identifier
#define SIZE 4096 / / size of shared memory
server.c
#include "comm.h"
int main()
{
key_t key = ftok(PATHNAME, PROJ_ID); //Get key value
if (key < 0){
perror("ftok");
return 1;
}
int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL | 0666); //Create new shared memory
if (shm < 0){
perror("shmget");
return 2;
}
printf("key: %x\n", key); //Print key value
printf("shm: %d\n", shm); //Print shared memory user layer id
char* mem = shmat(shm, NULL, 0); //Associated shared memory
int i = 0;
while (i < 26){
printf("%s\n",mem);
++i;
sleep(1);
}
shmdt(mem); //Shared memory disassociation
shmctl(shm, IPC_RMID, NULL); //Free shared memory
return 0;
}
client.c
#include "comm.h"
int main()
{
key_t key = ftok(PATHNAME, PROJ_ID); //Get the same key value as the server process
if (key < 0){
perror("ftok");
return 1;
}
int shm = shmget(key, SIZE, IPC_CREAT); //Get the user layer id of the shared memory created by the server process
if (shm < 0){
perror("shmget");
return 2;
}
printf("key: %x\n", key); //Print key value
printf("shm: %d\n", shm); //Print shared memory user layer id
char* mem = shmat(shm, NULL, 0); //Associated shared memory
int i = 0;
while (i < 26 ){
mem[i] = 'A' + i;
i++;
mem[i] = 0;
sleep(1);
}
shmdt(mem); //Shared memory disassociation
return 0;
}
We continuously get data through shared memory segment, client write and server read. The results are as follows:

So far, we have completed the communication between the client and the server.
Comparison between shared memory and pipeline
After the shared memory is created, the system call interface is not required for communication, while after the pipeline is created, the system interfaces such as read and write are still required for communication. In fact, shared memory is the fastest way of communication among all processes.
The Conduit:
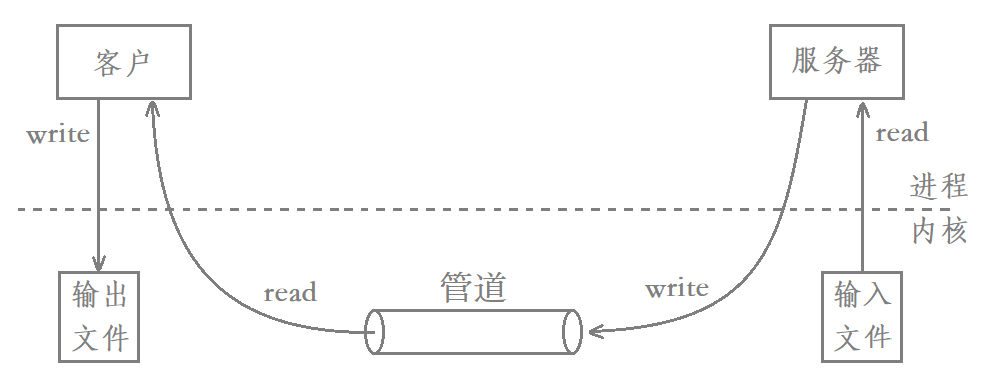
It can be seen from this figure that using pipeline communication to transfer a file from one process to another requires four copy operations:
- The server copies the information from the input file to the temporary buffer of the server.
- Copy the information of the server temporary buffer to the pipeline.
- The client copies the information from the pipeline to the client's buffer.
- Copy the information of the client temporary buffer to the output file.
Shared memory:
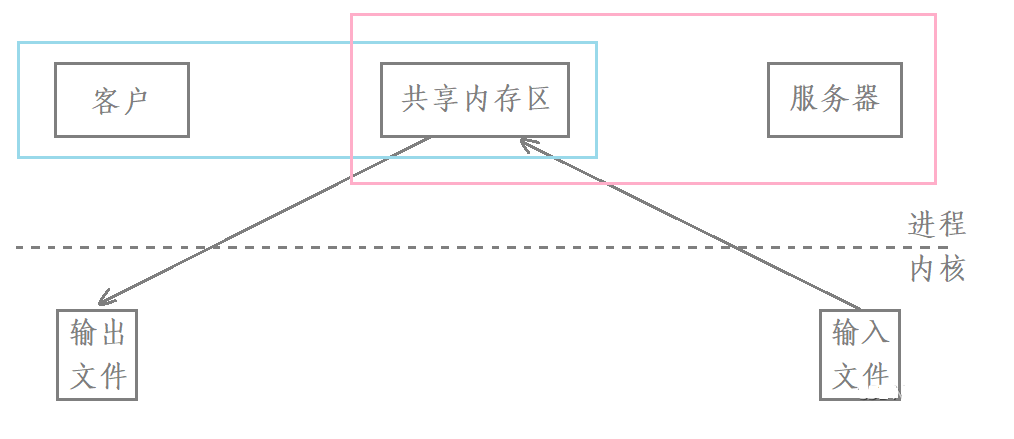
It can be seen from this figure that using shared memory for communication, it only needs two copies to transfer a file from one process to another:
- From input file to shared memory.
- From shared memory to output file.
Therefore, shared memory is the fastest communication mode among all interprocess communication modes, because it requires the least number of copies.
However, shared memory also has disadvantages. We know that the pipeline has its own synchronization and mutual exclusion mechanism, but shared memory does not provide any protection mechanism, including synchronization and mutual exclusion.